背景と課題
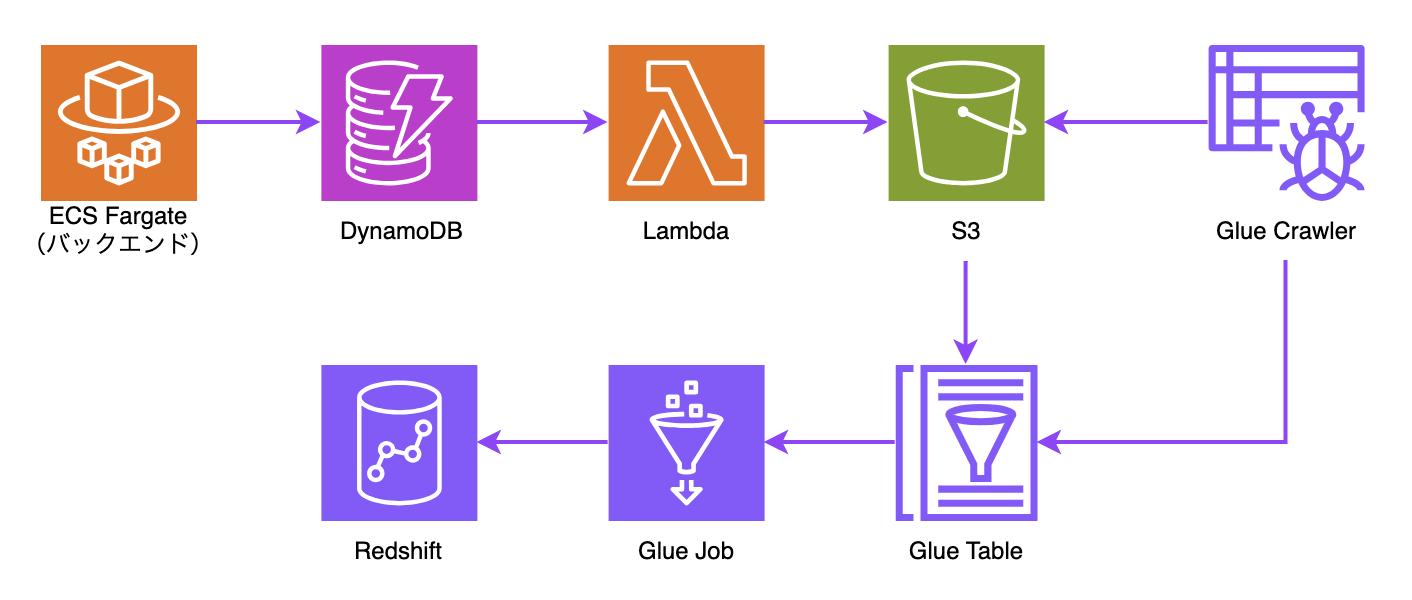
上記の構成図は、バックエンドのデータがDynamoDBに保存され、それをS3へエクスポートし、Glue TableからRedshiftまでのETLフローを示しています。
Glue Crawler(以後クローラー)は、JSONフィールドを自動的に解析し、その構造に基づいて適切なデータ型(struct型やarray型)に変換します。しかし、この自動変換において以下のような問題が発生します。
スキーマの不一致
- JSONの構造が動的に変化する場合、Glueスキーマに影響が発生
- クローラー実行のたびにスキーマ定義が不安定になる
解決方法
この問題を解決するために、JSONフィールドを強制的にstring型として固定します。
これにより、JSONの構造が変化した場合でも、Glueのスキーマは変更されず、安定したデータ処理が実現できます。
期待される効果
JSONフィールドをstring型として扱うことで、以下の効果が得られます
スキーマ変更の防止
- JSONの構造が変化してもGlueスキーマへの影響を防止
- クローラー実行時のスキーマ変更を回避
- 後続のETL処理(例:GlueからRedshiftへのデータロード)時のエラーを防止
まとめ
JSONデータの型をstring型に固定することで、動的に変化するJSONデータ構造に対してもGlueスキーマを安定的に保つことができます。
これにより、後続のETL処理を含むデータ分析基盤全体の安定運用が実現できます。