はじめに
こんにちは、未経験からエンジニア転職を目指しているものです。
エンジニア転職を目指す際、ふと「未経験とプロのエンジニアの違いってなんだ?」と思ったことはないでしょうか?私もそのうちの1人です。もちろん明らかに違うこと自体はわかっているのですが具体的に言語化ができていませんでした。
なるべく入社前後のギャップを埋めたいと感じていた当時の私は実務を体験をすることによってそのギャップを少しでも埋めることができ、入社後の成長スピードを高めることが出来るのではないかと考えていました。
そんなある日、ご縁があり実務を体験させていただく機会がありましたので、実務をする中で感じたこと、思ったこと、実際の実務内容を体験記として書き記しておきたいと思います。
同じような疑問を抱いている方の少しでも参考になれたら幸いです。
9/26日追記
実務内容詳細興味ないよって人は最後ら辺だけ読むのが良いかもしれません笑
9/27日作成
補足記事作成しましたので良ければご覧いただけますと幸いです!
9/25日一般公開からわずか4日で10,000回以上も見ていただけるなんて思っても見ませんでした。
沢山の方にご覧いただき感謝の気持ちで一杯です。これからも記事作りに励みます。
こんな人に読んで欲しい
・未経験からエンジニアを目指している方
・実務案件って実際どんな事やるの?と疑問に思っている方
・実務と未経験のポートフォリオとの違いってなんなの?と思っている方
・企業のデータ分析ってどうやってやってるの?と疑問に思っている方
案件の経緯
今回の実務案件はクライアントが運用している自社サービスのモニタリング体制が現状構築できておらず、気軽にデータ分析ができていないためデータ分析体制を構築してほしいとの事。
クライアントから与えられた情報は以下
- 案件内容
- データのモニタリング体制を整える
- 実装期間:1ヶ月半
- 課題
- データを気軽にモニタリングできない
- 定期的なモニタリングができていない
現状のモニタリング体制図
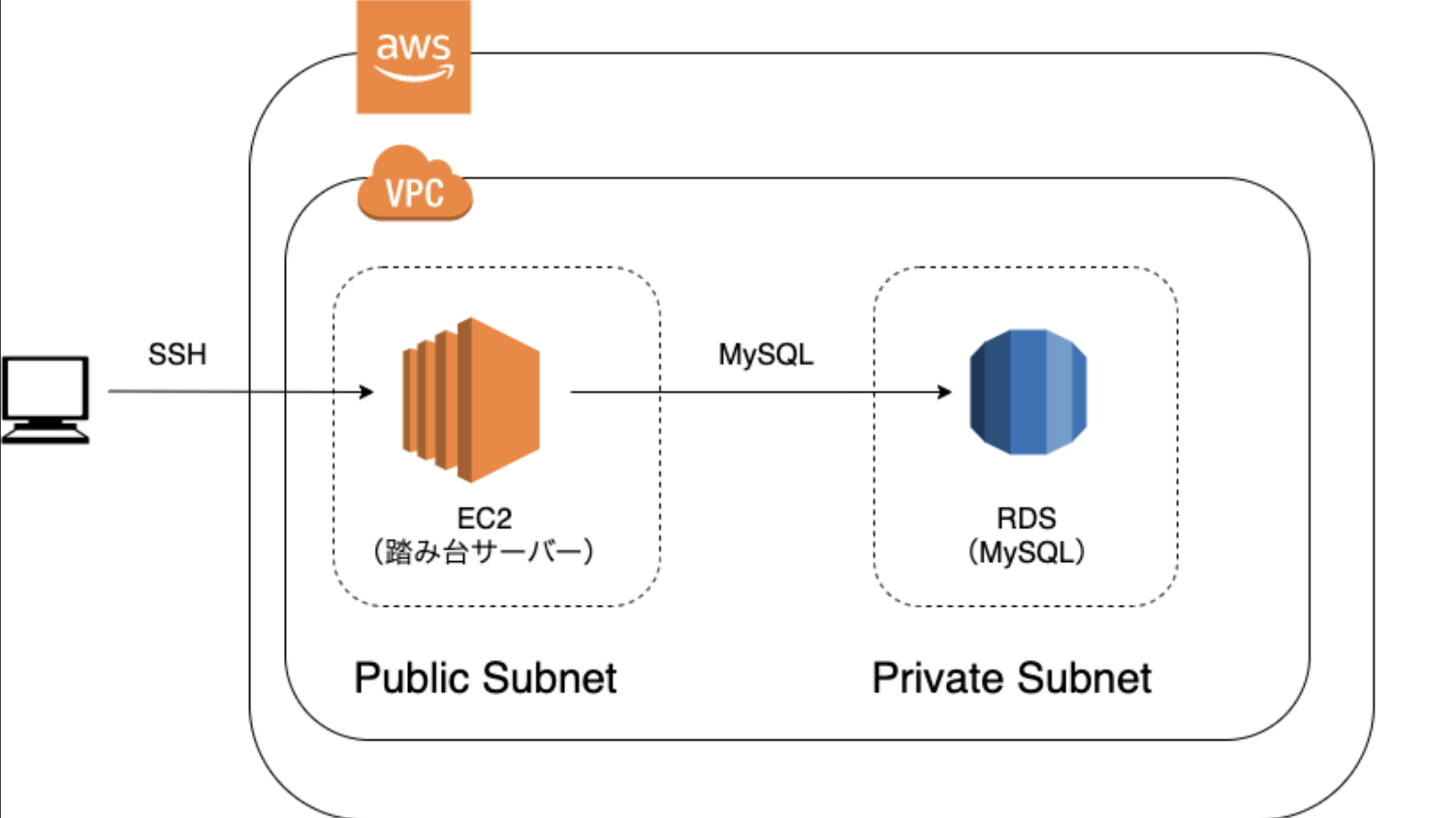
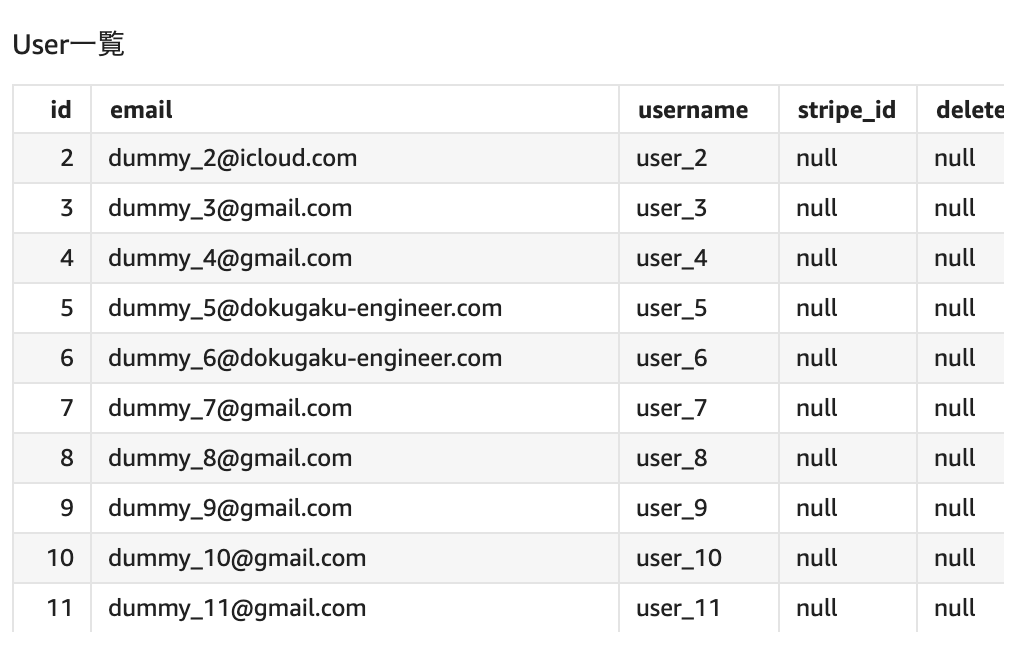
EC2を踏み台サーバーとしてしてMySQLにログインし、MySQL内でSQLコマンドを打ってデータ分析をしている状況。EC2へSSH接続をしてからMySQLへ段階を踏んでログインする必要があるため手軽にモニタリングができない。また、ユーザーに関わる情報を数値化して定期的にモニタリングすることができていない。
最終的な構成
インフラ構成図
説明は後ほど
要件定義
このような課題を解決するためにまずはクライアントと要件定義(要求を考慮し、システムとして必要な要件をまとめること)のすり合わせを行なった。
その前に要求分析(相手の要望を抽出し分析すること)を行なったが今回は割愛する。
要件定義は以下のようになった。
- 要件定義:機能要件
- データベースに直接アクセスできる
- SQLを自由に叩ける
- モニタリング指標の各項目が数字として表示される
- モニタリング指標の各項目がグラフ化して見ることができる
- モニタリング指標の各項目を自由に変更できる
- ユーザー管理機能(アクセス権限の設定)
- 要件定義:非機能要件
- 個人情報は閲覧できない
- 読み込み専用にする
- 本番DBに負荷がかからない
- インターフェイスはデザイン崩れしない
- 画面は3秒以内に表示できるようにする
- 指定されたユーザーのみ、ユーザー管理を自由に行えるようにする
- 死活監視:モニタリングサービスが落ちたら検知できる
- エラー監視:エラーが発生したら検知できる
これらを満たすソリューションを考え構築することになった。
また、運用コスト上限は5000円/月と指定された。
ガントチャート作成
実装に入る前にタスクを洗い出し、ガントチャートを作成した。

一部抜粋
意識したこと
・タスクの細分化
いかにタスクをばらすことが出来るかを意識し作成。
実務を進めていく中でタスクが増えたり、タスクを更に細分化出来ることがあるので
都度修正することに努めた結果、最終的にタスク数が92個となった。
・バッファを意識した作成
実務では想定外の詰まりが多々あると予想していたので各実装フェーズ毎にバッファを2日間設けるようにした。これにより実装が詰まって進捗が遅れても修正できるように設計している。
実装フェーズ
要件定義実装準備が完了したらいよいよ実装フェーズに突入。
- 実装で大変だった事
- 本番DBへ負荷がかからないことを考慮した上で個人情報流出を防ぐためにマスキング処理をどうやって行うのか。
- データを取ってきてマスキングし、可視化するまでの一連の流れをどう定期的に自動化するか
これらの対策は後半に記述。
1〜2週目 技術選定、初期実装フェーズ
技術選定
そもそもどうやってモニタリング体制を整えたら良いのかわけわかめ状態。
自分で作成するのか元からあるツールを使用するのか。
自身で調べたり、知り合いのエンジニアに通常企業ではどのようにデータのモニタリング体制を構築するかヒアリングをしたところBIツールなるものを使うのが良さそうとの結論に至った。
BIツールもなにそれ美味しいの状態だったので調べた結果を書き留めておきたいと思う。
BIツール
「BIツール」とは、「ビジネス・インテリジェンスツール」のことで、企業が持つさまざまなデータを分析・見える化し、ビジネスの意思決定に役立てるデータ分析ツールの事。
まあ言ってしまえばデータ分析に特化したWEBアプリケーションサイトのような物。
BIツールは有料から無料の物までさまざまあり、備わっている機能も変わってくる。
BIツール検討比較表
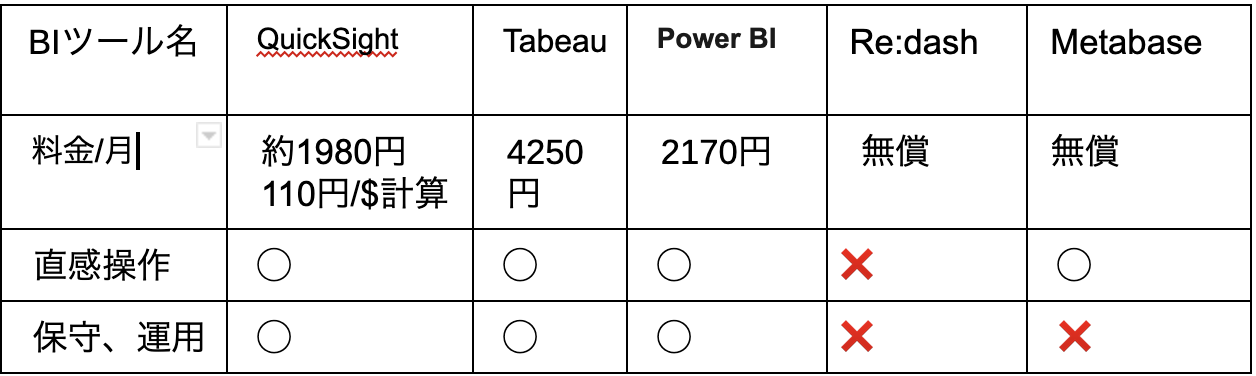
今回は以下の観点で比較検討を行なった。
- 比較観点
- 料金コスト(全体コストが5000円なので2000円以内が望ましい)
- 直感操作(外部委託予定であるため直感操作性も重視する必要がある)
- 保守、運用(オンプレミス型のBIツールだと保守、運用が必要になるのでクラウドBIが望ましい)
比較の結果今回AWS QuickSightを選定することにした。
他ツールの不採用理由は以下
Tableau
→予算オーバー
Power BI
→Mac対応不可
Re:dash
→データ分析を行う為にはSQL文しか使用できず、GUIで直感的な操作ができない為
Metabase
→オンプレミス(自社構築、運用が必要)のため、環境構築、サーバー運用が必要なので不採用。
AWS QuickSight特徴
ここで上記での優位性以外にもAWS QuickSightを採用したメリットがあるので記述していきたいと思う。
###1. 多彩なグラフ作成、ドラック&ドロップでの直感操作
Amazon QuickSight Gallery https://aws.amazon.com/jp/quicksight/gallery/ より
可視化できるグラフの種類が豊富かつSQL文に不慣れな方でもGUI操作で容易にグラフを作成できる。クライアントの意向で今後データの分析のみ外部委託を行う予定でかつそこまでエンジニア歴が長くない方が担当する可能性もあるとの事だったので操作性に関しては考慮している。
###2. MLインサイト機能
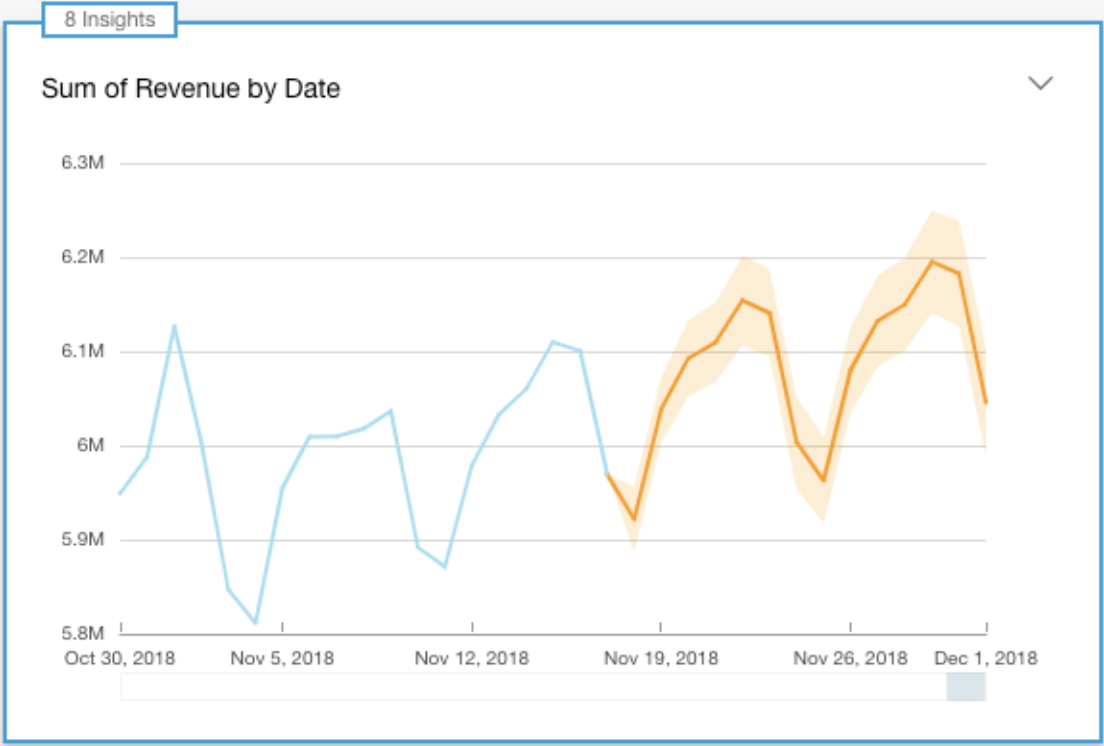
DevelopersIO https://dev.classmethod.jp/articles/amazon-quicksight-announces-general-availability-of-ml-insights/ より
- MLインサイトは機械学習を活用した機能となっており主に以下の機能がある
- データのトレンド予測を行ってくれるので今後の推移が予想できる
- 異常値を検出してくれるのでサイト運用上の問題点を洗い出しできる
3.多様なデータソースに対応
AWSサービスなだけあってRDS、S3、Athena等AWSの様々なデータソースにアクセス可能
今回データソースがRDSなので接続が容易にでき、クライアント側の構築の手間を減らすことができる。
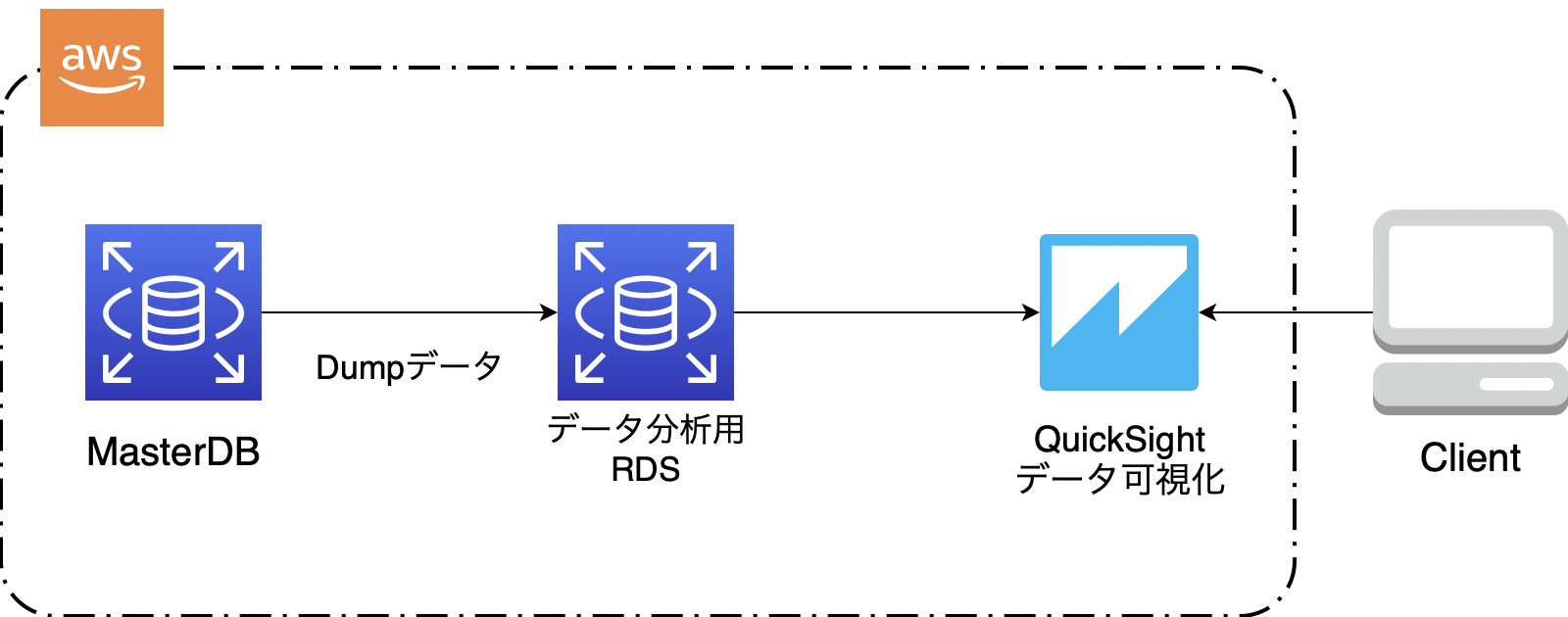
初期実装
まずはBIツールの操作性を確認するため本番サービスのRDSからDumpデータ(データを他のDBへ移行するためのデータ)を取ってきて構築したRDS(MySQL)に流し込み本番環境に見立てたRDSを構築。BIツールとRDSを直接連携し本番データの可視化を行なった。
初期実装構成図
本番データ可視化
本番データの可視化はできている模様。
機能要件であるモニタリング指標の数値化、グラフ化、項目を自由に変更できる、アクセス権限周り等要件を満たしていることが確認できた。ここまでの流れとしては悪くなかったと思う。
あとはマスキング処理を施せば大枠は完成と思っていたのだが、、、。
問題はここから。
3〜4週目 マスキング処理
今後データ分析は外部委託を検討しており、個人情報流出を防ぐため事前にマスキング処理を施したデータを分析できるようにしてほしいというのが今回の重要なポイントの一つ。
そこで次のような構成でマスキングを行う事にした。

①本番DBのスナップショットからマスキング用のRDSを作成
②マスキング処理を施した後Dumpデータ(データを他のDBへ移行するためのデータ)を抽出
③予め作成しておいたデータ分析用のRDSへDumpデータを流し込み復元
④Dumpデータを取り終わったマスキング用RDSは都度削除する事によってデータ分析者の個人情報閲覧を防ぐ
この一連の流れをEC2上でシェルスクリプトを作成
シェルスクリプトファイルをcronにより定期実行設定を構築した。
ここまで構築した上で一度クライアントにレビューをいただける機会を設けていただいた。
そこである問題に直面することに。
-
 「これってSQLクエリ打つ時毎回パスワードとか入れなきゃいけないんですか?」
「これってSQLクエリ打つ時毎回パスワードとか入れなきゃいけないんですか?」
確かに言われてみればQuickSightからRDSへ接続しSQL文を打つ際に毎回ユーザー名とパスワードを入れなければならない。これがSQLクエリを気軽かつ自由に叩きたいクライアント側としては非常にネックな部分であった。
5〜6週目 構成図再構築、怒涛の追い込み
最終的に課題になっていたのは
SQL文を気軽かつ自由に打てる環境を整えることであった。
課題を考慮した結果、AWS Athenaを採用することにした。
それに伴いAthenaを介すことでQuickSightでデータを可視化することが出来るので、わざわざコストが嵩む分析用のRDSを建てる必要も無いと感じ、S3にマスキングデータを蓄積するよう変更した。
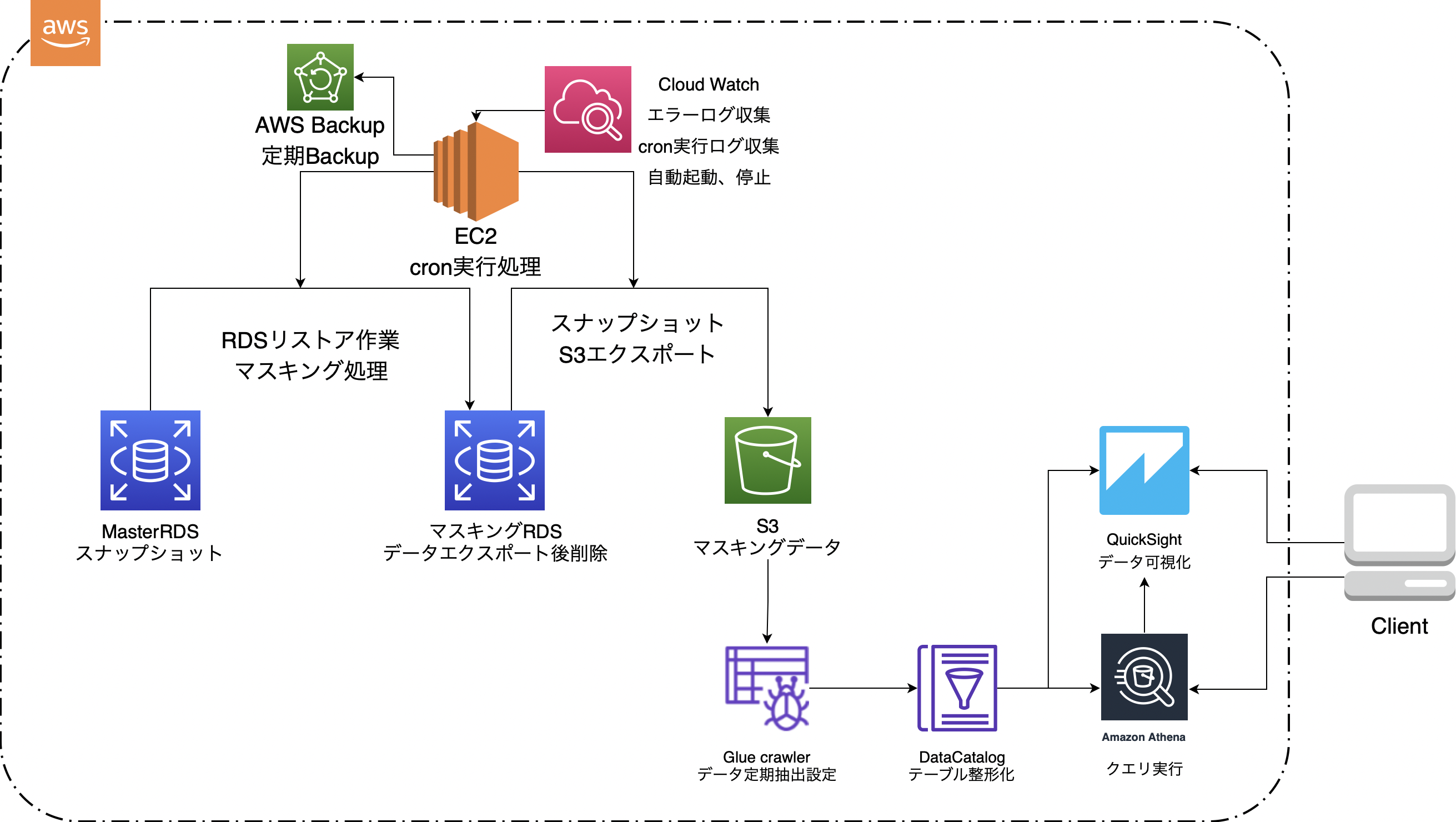
上記を考慮し最終的に冒頭にも記載したインフラ構成図に落ち着いた。
・本番DBからデータを取ってきてマスキングし、可視化するまでの一連の流れ
①MasterDBの自動スナップショットからマスキング用RDSの作成
②マスキングRDSにマスキング処理、
③スナップショットを取得
④取得したスナップショットをS3にエクスポート
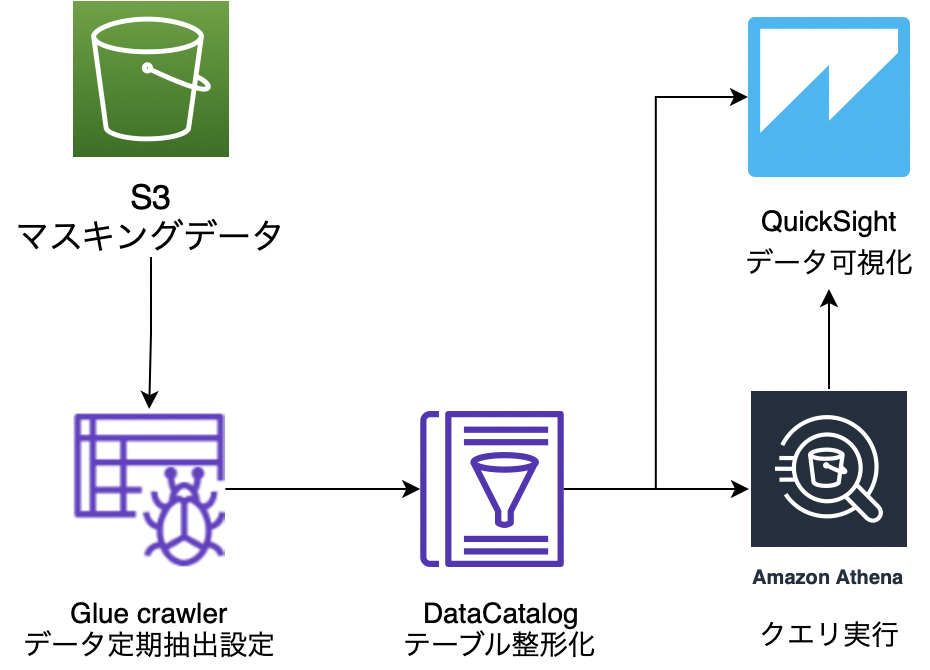
⑤S3データをGLue Crawlerを使用しデータ整形化しDataCatalogにメタデータとして保存
⑥Athenaでクエリ実行、クエリ結果テーブル作成
⑦QuickSightにて可視化
クエリを打たずに単純な可視化であれば、Athenaを介さずDataCatalogをQuickSight直接参照できる。
・一連の流れを自動化する方法
①〜④まではcronにて定期実行
⑤はCrawlerの定期実行処理設定にて定期実行
⑦は一度作成したデータの更新処理設定をQuickSight内で設定可能。定期的に同じデータ分析を確認したい場合、日時で最新のデータに更新して閲覧することが可能。
※9/27日作成
ここら辺の実行の流れの詳細は以下記事にまとめています!
ここでGlueと言うAWSの新しいサービスが出てくる。
自分自身も初めて使用するサービスなのでAWS Glueの概要をまとめていきたいと思う。
AWS Glueってなんぞ?
AWS Glueはデータの抽出や変換、ロードを簡単に行える完全マネージド型サービスのこと。サーバーレスのため自分自身で管理、運用する事必要がない。
様々なGlueの機能の中で今回使用した機能は次の2つ。
-
Glue Crawler
-
データ抽出GlueのDataCatalogにメタデータを作成するプログラムのこと。
-
DataCatalog
-
メタデータを管理するリポジトリ機能のこと。GlueCrawlerを使用しDataCatalogを作成する事によってデータを分析しやすいように整形。
データカタログはメタデータ(データのスキーマ情報(データのカラム名やデータ型))を保持しており、データそのものはデータ元に残っている。あくまでもデータの情報のみ保持しているという感じ。
よってデータ自体がDataCatalogあるように見えるが、データ本体はS3にあるのでS3のデータを削除すると当然Athenaで参照できていたDataCatalogデータも見る事ができなくなる。
使い方としてはAthenaで分析する際にS3からデータを持ってくる。AthenaとS3で直接連携しデータ分析することもできるが、その際にS3にあるデータがどのようなデータであるのかが分からないのでカラム名やデータ型などを一つ一つAthena指定していく必要があり、かなり手間が増える。
そこでGlue Crawlerで分析してカタログを作成する事によりテーブルを自動整形しデータ分析をできる状態にしてくれるのである。DataCatalogはCrawlerで解析したメタデータを管理すると言うイメージ。
最終提出
想定外の詰まりが多々あったがなんとか納品することができた。
Athenaクエリ結果例
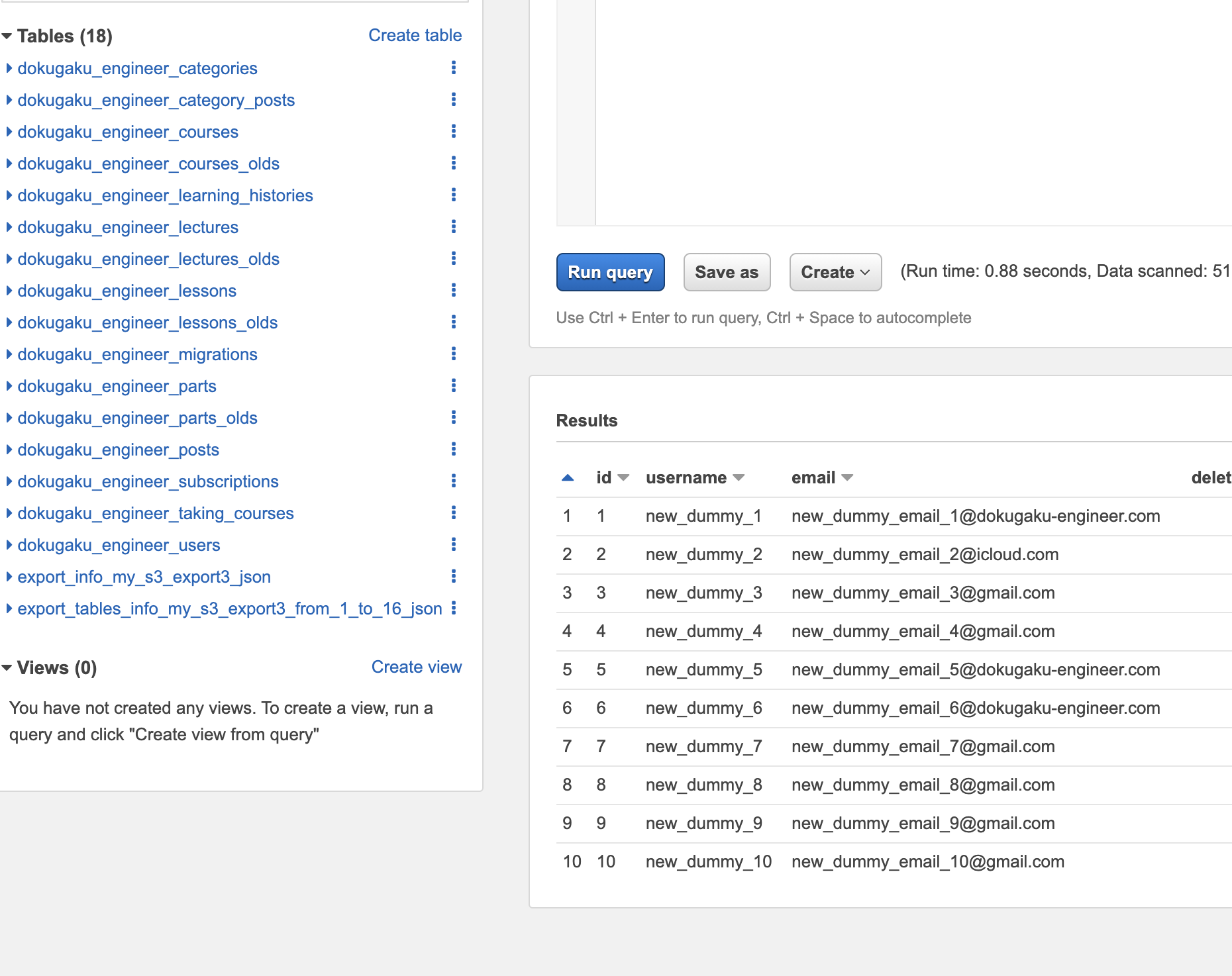
うん、マスキング処理、SQLクエリを実行できている
クライアント側から提示いただいた3つのSQL文を実行し、クエリ実行時間を計測。
結果はクライアント側の許容範囲内で了承をいただいた。
データの可視化
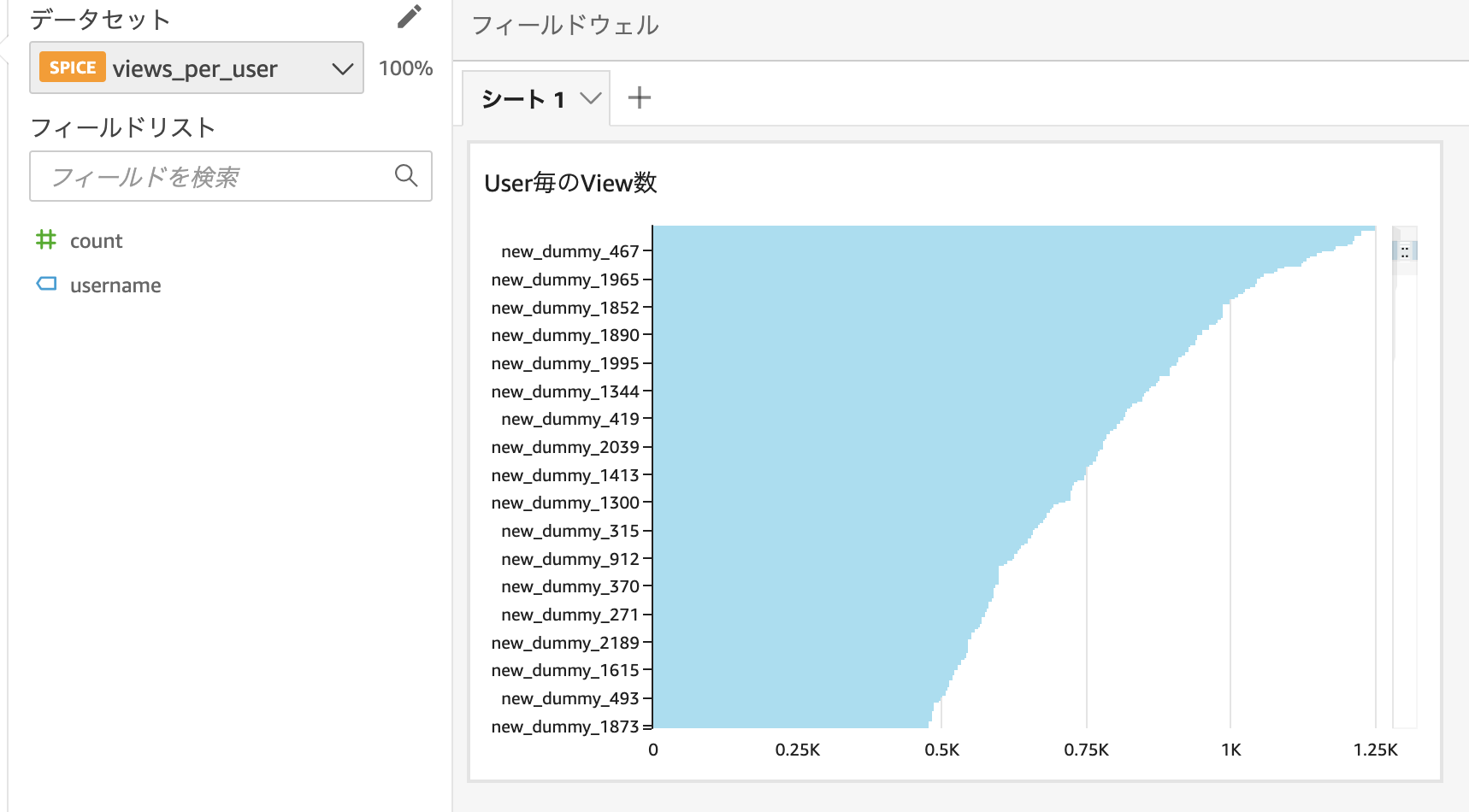
Athenaのクエリ結果も無事可視化できました。
マスキング処理も問題なく反映されています。
一回データセットを作成してしまえばQuickSightに自動保存され定期的(今回は日時)に同じデータ分析を最新の更新データで閲覧することが可能。なんて便利なんでしょう。
概算運用コスト
続いて概算の月額コストを記載
| サービス名 | 月額料金 | 説明 |
|---|---|---|
| AWS QuickSight | 18$ | GCP Cloud SQL(HDD) |
| RDS | 1.8$ | マスキング用RDS、一日2時間稼働 |
| RDS | 7.2$ | RDS S3エクスポート料金 一回辺り0.012/GB×20GB |
| EC2 | 1.87$ | cron定期実行処理用EC2、一日3時間稼働計算 |
| Glue | 1.87$ | Crawler処理一回辺り、0.88/1hour÷6(1回の起動時間10分) |
| 合計 | 33.27$ |
5000円/月という予算上限額を超えずに済んだ。
体験して分かった未経験が作る制作物と実務案件との違い
もちろんコードの記述量等目に見える物は天と地ほどの差があると思うが今回は考え方の違いにフォーカスして感じたことを記載していきたいと思う。
当たり前のことかもしれないがこれって本当に実運用を考えて作成できているか?と言う視点を極限まで考える必要が実務にはあると改めて感じることができた。
ユーザーの操作性、サーバーが落ちた時の対応、アップデート方法、データ蓄積に対してスケールアウト対応を考慮できている構造になっているか、テスト自動化、セキュリティ等言い出したらキリが無い。
こういった今だけでなく数年先まで見据えた運用ができるようなソリューションを考え提案し、納品できるかが実務案件には求められる。
また自分で作る制作物とは違い納期、いわゆる納品のデットラインは必ずと言っていいほどある。納期は何がなんでも最優先。
納期に間に合わせる範囲でのベストなソリューションを考える必要がある。
ソリューションのクオリティと納期のバランスを考えるのが非常に難しかった。
実務において感じたこと
実務を通じて今後役に立ちそうだなと感じたことを追記したいと思います。
①この課題解決に「そもそもコード書く必要ある?」と実装前に疑ってかかる
最初この案件を聞いた時、自分でデータ分析サイトを作成するのかななんて思ってました。
もちろん可能性としては出来るかとは思います。
ですが今回の納期までの期間の短さ、また運用コスト、要件を満たしているツールが既にあるのであればわざわざコードを書いて作らずそれを使用するべきなんですよね。
未経験だとなんでも自分自身で作り上げたいみたいな考えに陥りがちなのでその考えを改めて持つことができたのは良かったと思います。
②デメリットに目を向ける
ソリューションを考える際に、メリットにばかり目がいきがちであると痛感しました。
これでやりたい実装ができる!!と思うとすぐにそのソリューションを採用したくなってしまいます。
そのせいでデメリットをあまり考慮しないが上に実装を進めていく中で要件を満たせない状態に陥り、ソリューションを再考しなければならなくなったことが何度もありました。
今後はソリューションを検討する際、デメリットファーストで考えていきたいと感じております。
あとがき
今回上流から下流工程までの一連の流れを未経験のうちに経験できたのは自分の中で非常に良い経験でした。
かといってプロのエンジニアとの差は実際にプロのエンジニアの方と関わった上でまだ歴然であると感じております。
しかし今回の経験は今後のエンジニア人生において直接でなくても確実に役に立つとも感じております。
この経験を糧に就職活動に臨みたいと思います。
最後までご覧いただき本当にありがとうございました!!
この記事が少しでも良かったと思っていただけましたらLGTMポチッとしていただけますと幸いです。