watsonx.dataで2種類の方法でオブジェクトストレージにテーブルを作成し、watsonx.dataに組み込まれているオープンソースのPrestoエンジンを使ってSQL文でアクセスしてみた記事です。
watsonx.dataはオープンなデータレイクハウス・アーキテクチャに基づいて構築されており、大容量のデータを安価に保存できるオブジェクトストレージにテーブルを作成したり、他のデータベースを統合することができ、それらのデータベースのデータをwatsonx.dataに組み込まれているオープンソースのPrestoエンジンを使って横断的にSQL文でアクセスできます。Prestoエンジンは、Resource Manager, Coordinator, Workerで構成され、複数のWorkerでデータ処理することができます。
テーブル形式はIcebergを採用しており、DBMSのACID特性やタイムトラベル機能等をサポートしています。パーティションは、Hidden partitioning機能によりシステムが自動で管理するのでユーザーが明示的に指定する必要はなく、さらに、Partition evolutionでデータ量に応じて、例えばdate型の列に対して日付でパーティションしていたものをある時点から月に変えるといった機能も提供されているようです。また、これらの処理はメタデータを使って行われるためテーブルの物理的なレイアウトには依存しないとのこと。
オブジェクトストレージに保存されるテーブルのデータ形式はParquetという列指向の形式でデータ分析に向いたものとなっており、効率的なデータ圧縮機能等を提供しています。テーブル作成時のwithオプションでpartitioning=array['列1', ...]を指定することで、物理的なファイルを明示的に分割することも可能で、クエリ・パフォーマンスの向上、ストレージ・コストの低減等が期待できるとのことです。ただし、Icebergを使えば上記で述べた機能があるため、物理的なレイアウトにはあまりこだわらなくてもよさそうです。
この記事の内容
- 以下の環境を作って試しました
-
IBM Cloud Pak for Data(CP4D)上にwatsonx.dataを導入
- CP4D バージョン: 4.7.3
- watsonx.data (SW版) バージョン: 1.0.3
-
IBM Cloud Pak for Data(CP4D)上にwatsonx.dataを導入
- テーブルを作成しデータを投入する方法として以下の2種類をやってみました
- csv形式のデータファイルを使ってIBM Cloud Object Storage(ICOS)にテーブルを作成し、データを投入する
- 他のデータソースからSQL文でIBM Cloud Object Storage(ICOS)にテーブルを作成して、データを投入する
- Db2に保存されているスノーフレーク・スキーマのファクト表の古いデータをICOS上に移行してみました。ファクト表を新しいデータ(Db2に保存)と古いデータ(オブジェクトストレージに保存)に分割したので、さらにVIEWで統合できると良いと思ったが、VIEWはサポートしていませんでした。分割したファクト表を結合して扱いたい場合は、代替案として、WITH句でファクト表を統合したサブクエリに名前をつけ、その名前を使ってSQL文を構成するやり方で対応するのがよさそうです。
以下、オブジェクトストレージ上にテーブルを作成した2種類の方法ついて記載しています。
- csv形式のデータファイルを使ってIBM Cloud Object Storage(ICOS)にテーブルを作成し、データを投入する
- 他のデータソースからSQL文でIBM Cloud Object Storage(ICOS)にテーブルを作成して、データを投入する
1と2共通の作業として、事前にオブジェクトストレージ(今回はICOSを使用)をwatsonx.dataに追加する必要があります。その方法について最初に記載しています。
0. IBM Cloud Object Storage(ICOS)をwatsonx.dataに追加する
この手順は以下のようになる。
0-1. IBM Cloud Object Storageののバケットとその資格情報を作成する
0-2. 作成したバケットをwatsonx.dataに追加する
0-1. IBM Cloud Object Storageのバケットとその資格情報を作成する
IBM CloudのカタログからObject Storageを選択し作成する。次に、IBM Cloudのリソースリストのストレージ配下に作成されたObject Storageを選択する。
以下のような画面が表示されるので、右側のバケットの作成ボタンをクリックする。

バケットの作成画面で、Create a Custom Bucketパネルの作成ボタンをクリックする。
以下の画面にて、固有のバケット名を入力し、回復力とロケーションとストレージ・クラスを選択して、バケットの作成ボタンをクリックする。
(ここでは、固有のバケット名をwatsonx-data-mo-icos-2023、回復力をRegional、ローケーションをjp-tok、ストレージ・クラスをSmart Tierとした)

バケットが作成されると、オブジェクトのリスト画面が表示される。上記のインスタンス / Cloud Object Storage-xxx / の Cloud Object Storage-xxxを選択し画面を切り替え、さらにサービス資格情報タブを選択し、以下の画面を表示させる。

右側の新規資格情報ボタンをクリックし、資格情報の作成パネルを表示させる。
名前を入力し、ロールをライター、HMAC資格情報を含めるをオンにセットし、追加ボタンをクリックする。

結果として以下のような資格情報が作成される。

上記の情報のうち、以下の2つの値を使用する。
"cos_hmac_keys": {
"access_key_id": "c4b81082e47a426a96843c3ce30a7f39",
"secret_access_key": "7d0087476f1aa6c8f07a2d35e7664e2ac4bb5648e914bf85"
}
また、バケットのエンドポイントURLを得るために、画面左側メニューからエンドポイントを選択する。
今回のバケットは、回復力をRegional、ロケーションをjp-tokで作成したので、以下のようにその値をセットしてURLを確認する。

上記の画面に記載されているパブリックのエンドポイントは以下となっている。
s3.jp-tok.cloud-object-storage.appdomain.cloud
0-2. 作成したバケットをwatsonx.dataに追加する
watsonx.dataのインフラストラクチャー・マネージャーの画面を表示させ、右側にあるコンポーネントの追加からバケットの追加を選択する。

今回のケースでは以下のように入力する。
| 名称 | 値 |
|---|---|
| バケット・タイプ | IBM Cloud Object Storage |
| Region | Tokyo (jp-tok) |
| バケット名 | watsonx-data-mo-icos-2023 |
| エンドポイント | https://s3.jp-tok.cloud-object-storage.appdomain.cloud |
| アクセス・キー | 資格情報のaccess_key_idの値 |
| 秘密鍵 | 資格情報のsecret_access_keyの値 |
| アクティブ化 |
今すぐアクティブ化を選択 |
| カタログ・タイプ | Apache Iceberg |
| カタログ名 | icos1 |
追加する前に画面の中程にあるTest connectionで接続をテストしてみる。
テスト接続に成功すると下図のようにSuccessfulと表示されるので、それを確認した後、今すぐ追加してアクティブ化ボタンをクリックする。

インフラストラクチャー・マネージャーに以下のように追加したICOSのバケットとカタログが表示される。
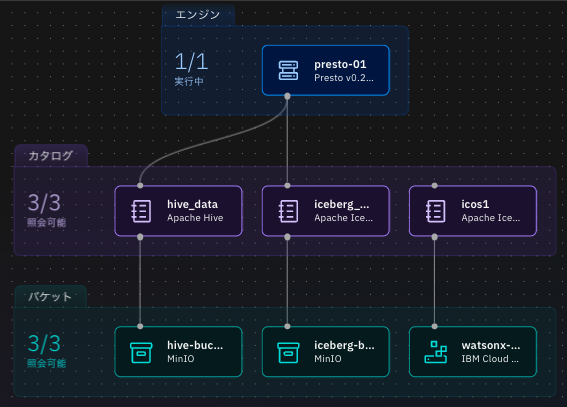
Prestoエンジンに接続するために、icos1画面上にマウス・カーソルを移動し、その上部に表示された関連付けの管理アイコンをクリックする。

関連付けの管理画面でpresto-01エンジンにチェックし、保存してエンジンを再始動するボタンをクリックする。

しばらくすると、Prestoエンジンの再起動が終了し、以下のようになる。

1. csv形式のデータファイルを使ってIBM Cloud Object Storage(ICOS)にテーブルを作成し、データを投入する
この手順は以下のようになる。
1-1. テーブルの作成とデータを投入するためのcsv形式のファイルを用意する
1-2. 作成するテーブルが所属するスキーマを作成する
1-3. 用意したファイルをwatsonx.dataに投入し、テーブルの作成とデータの投入を行う
1-1. テーブルの作成とデータを投入するためのcsv形式のファイルを用意する
csv形式のデータファイルは以下のCognos Analyticsのチュートリアルに記載されているIBM_HR_Training_2014-17.csvを使用する。このファイルをローカルPCにダウンロードしておく。
1-2. 作成するテーブルが所属するスキーマを作成する
watsonx.data画面左側のアイコン・メニューからデータ・マネージャーを選択する。
以下のような画面が表示されるので、作成を展開し、図式の作成(スキーマの作成)を選択する。
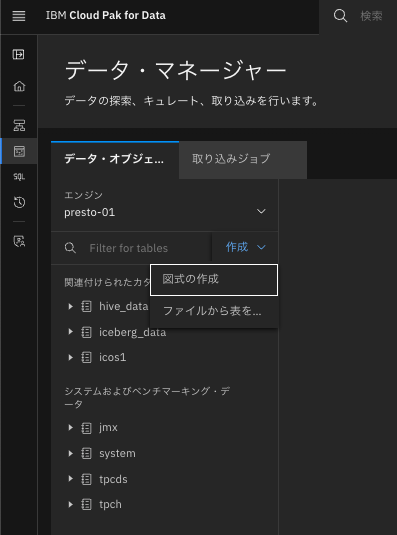
catalogでicos1を選択、スキーマの名前としてhrを入力し、作成ボタンをクリックする。

1-3. 用意したファイルをwatsonx.dataに投入し、テーブルの作成とデータの投入を行う
次に、再度作成を展開し、ファイルから表を...を選択する。
ファイルから表を作成するのソース画面が表示されるので、ここにダウンロードしたIBM_HR_Training_2014-17.csvファイルをドラッグ&ドロップする。
以下のように列ごとにデータタイプがセットされるので、データとともに問題ないか確認する。ここでデータタイプを変更することもできる。問題なければ、次へボタンをクリックする。
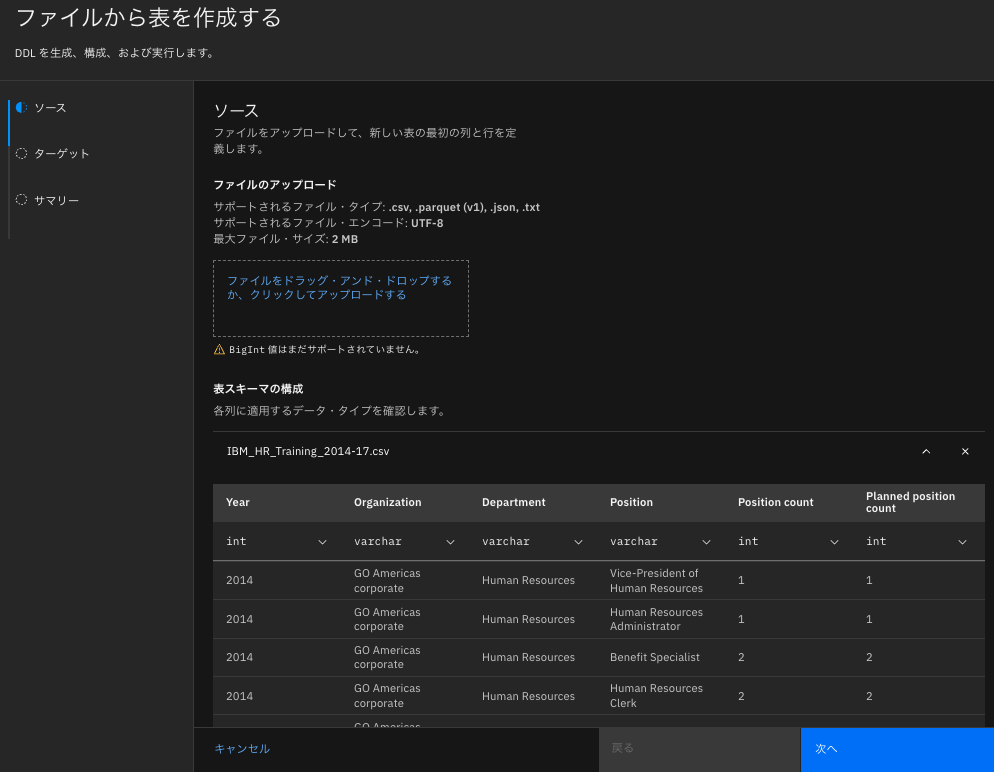
ターゲット画面で、catalogとしてicos1、スキーマとしてhrを選択、表名としてhr_trainingを入力する。テーブルの形式とデータ形式は一択しかなく、Apache IcebergとParquetが選択されている。
次へボタンをクリックする。

サマリーとして設定内容とCREATE TABLE文が表示されるので確認して作成ボタンをクリックする。

テーブルの作成&データの投入が成功すると以下のようなメッセージが表示される。
Your new table has been created.
icos1.hr.hr_training is now available in the data manager.
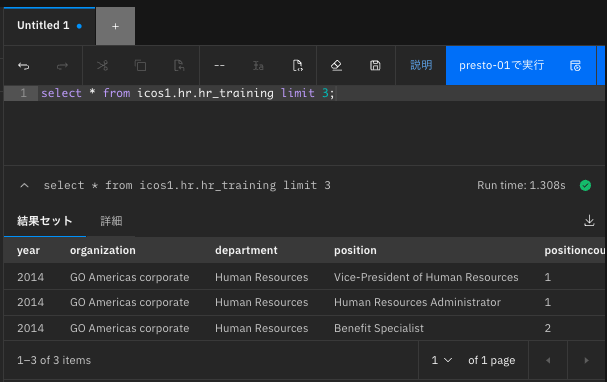
SQL文を発行して確認してみる。
watsonx.data画面左側のアイコン・メニューから紹介ワークスペース(SQL)を選択する。
Untitled 1タブの下のフィールドに以下のSQL文をセットする。
select * from icos1.hr.hr_training limit 3;
次にpresto-01で実行ボタンをクリックしてSQL文を実行する。
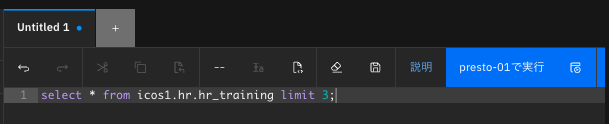
SQLが正常に実行されると、下記のように実行結果が表示される。
2. 他のデータソースからSQL文でIBM Cloud Object Storage(ICOS)にテーブルを作成して、データを投入する
この手順は以下のようになる。
2-1. 他のデータソースを確認してみる
2-2. 他のデータソースにあるテーブルをICOSにSQL文でコピーしてみる
2-3. 他のデータソースにあるファクト表の一部をICOSにSQL文でコピーしてみる
2-1. 他のデータソースを確認してみる
Db2に以下のスノーフレークスキーマが構成されている。(スキーマ名はgdq11991)
| テーブルのタイプ | テーブル名 | 行数 |
|---|---|---|
| 次元表 | sls_product_dim | 274 |
| 次元表 | sls_product_line_lookup | 5 |
| 次元表 | sls_product_brand_lookup | 28 |
| 次元表 | sls_order_method_dim | 7 |
| ファクト表 | sls_sales_fact | 446023 |
このDb2をwatsonx.dataに組み込んでみた。以下の一番右にあるのがDb2で、カタログ名はdb2とした。
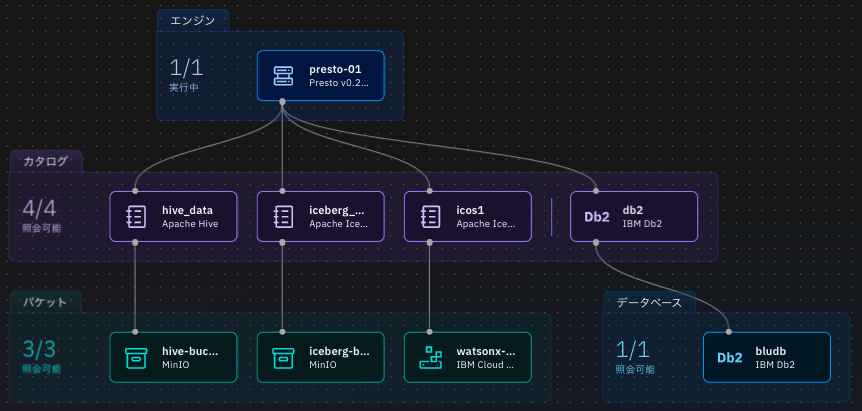
左側のアイコン・メニューから照会ワークスペース(SQL)を選択し、以下のSQL文を発行してみる。
select
pll.product_line_en as product,
pbl.product_brand_en as brand,
md.order_method_en as order_method,
sum(sf.quantity) as total
from
db2.gdq11991.sls_order_method_dim as md,
db2.gdq11991.sls_product_dim as pd,
db2.gdq11991.sls_product_line_lookup as pll,
db2.gdq11991.sls_product_brand_lookup as pbl,
db2.gdq11991.sls_sales_fact as sf
where
pd.product_key = sf.product_key
and md.order_method_key = sf.order_method_key
and pll.product_line_code = pd.product_line_code
and pbl.product_brand_code = pd.product_brand_code
group by
pll.product_line_en,
pbl.product_brand_en,
md.order_method_en
order by
product,
brand,
order_method;
結果として正常に動作し、以下の結果が得られた。

2-2. 他のデータソースにあるテーブルをICOSにSQL文でコピーしてみる
sls_product_dimテーブルをicos1カタログにコピーしてみる。そのためのスキーマ名をslsとする。
まずは、hrスキーマを作成したのと同じやり方でslsスキーマを作成する。
(1-2. 作成するテーブルが所属するスキーマを作成するを参照)
次に以下のSQL文を発行してsls_product_dimをコピーする。
create table icos1.sls.sls_product_dim
with (
format='PARQUET'
)
as select * from db2.gdq11991.sls_product_dim;
上記のSQL文を発行した後に、正しくデータがコピーされているか確認するために、そのテーブルに挿入されているレコードの数をカウントしてみた。274件で、コピー元のレコード数と一致する。

2-3. 他のデータソースにあるファクト表の一部をICOSにSQL文でコピーしてみる
ファクト表のsls_sales_factテーブルのorder_day_keyにオーダーした年月日が保存されているので、この値の古いデータをICOSに移行してみる。
まずは、保存されているデータの年を確認してみる。order_day_keyはinteger型でyyyymmdd形式で値が入っているので、以下のSQL文を発行してみる。

2004年から2007年までのデータとなっており、全体的にちょっと古いが、今回は2007年が直近のデータとしてDb2に残し、それ以外のデータをICOSに移行してみる。
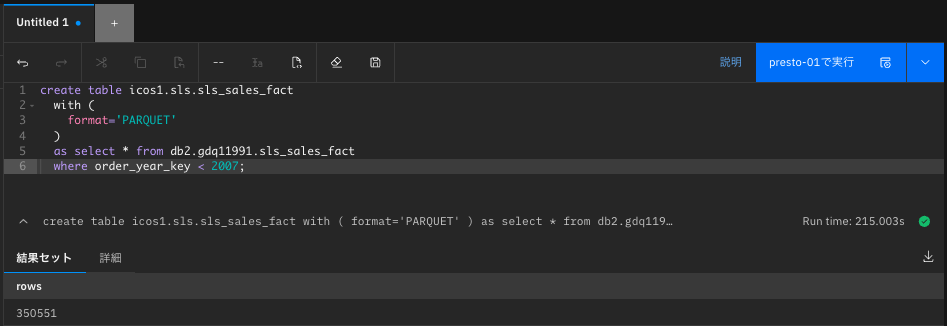
2007年より古いデータをコピーするために、以下のSQL文をwatsonx.dataに対して発行する。
create table icos1.sls.sls_sales_fact
with (
format='PARQUET'
)
as select * from db2.gdq11991.sls_sales_fact
where order_day_key/10000 < 2007;
結果として、ICOSにテーブルが作成され、350551件のレコードが挿入されている。
次に、2007年より古いデータはICOSに移行したので、Db2側のファクトテーブルから移行したデータを削除する。(この処理は、watsonx.dataからDb2に対しての更新はサポートしていなかったので、直接Db2に接続して行った)
delete from gdq11991.sls_sales_fact where order_day_key/10000 < 2007;
結果として、ICOSのテーブルに挿入されたレコード数と同じ350551件のレコードが削除された。
ファクト表が分割されたのでVIEWを作って統合しようとしたがエラーとなった。少なくとも複数のデータソース(コネクター)間のテーブルを使ったVIEWはサポートしていないようだ。
代替案として、統合したファクト表を使いたい時は、VIEWを使う代わりに、WITH句でファクト表を結合するサブクエリに名前をつけて、それを使ってみた。
以下に、VIEWの代わりにWITH句を使ったSQL文の例を述べる。
(sls_product_dimテーブルもICOSにコピーしたので、そのテーブルも使ってみる)
with sales_fact as (
select * from icos1.sls.sls_sales_fact union all
select * from db2.gdq11991.sls_sales_fact
)
select
pll.product_line_en as product,
pbl.product_brand_en as brand,
md.order_method_en as order_method,
sum(sf.quantity) as total
from
db2.gdq11991.sls_order_method_dim as md,
icos1.sls.sls_product_dim as pd,
db2.gdq11991.sls_product_line_lookup as pll,
db2.gdq11991.sls_product_brand_lookup as pbl,
sales_fact as sf
where
pd.product_key = sf.product_key
and md.order_method_key = sf.order_method_key
and pll.product_line_code = pd.product_line_code
and pbl.product_brand_code = pd.product_brand_code
group by
pll.product_line_en,
pbl.product_brand_en,
md.order_method_en
order by
product,
brand,
order_method;
上記をwatsonx.dataの照会ワークスペース(SQL)で実行してみると以下のように正常に処理された。

補足: PrestoエンジンのCoordinator/Worker数の変更方法
watsonx.data SW版をインストールすると、デフォルトでは、CoordinatorとWorkerが統合された1つのpodが起動する。以前は、これを変えるためにwxdengine/lakehouse-presto-01の定義を以下のように変更していたのですが、少し仕様が変わったようです。
- lakehouseDeploymentTypeをsingleからmultinodeに変更
- 以下の「以前の変更例」で示した値を追加
- presto_coordinator_replicasがcoordinator数
- presto_worker_replicasがworker数
# oc edit -n [namespace名] wxdengine/lakehouse-presto-01
...
lakehouseDeploymentType: multinode
presto_coordinator_replicas: 1
presto_coordinator_resources_limits_cpu: 1
presto_coordinator_resources_limits_memory: 48G
presto_coordinator_resources_requests_cpu: 1
presto_coordinator_resources_requests_memory: 48G
presto_worker_replicas: 3
presto_worker_resources_limits_cpu: 1
presto_worker_resources_limits_memory: 48G
presto_worker_resources_requests_cpu: 1
presto_worker_resources_requests_memory: 48G
...
# oc get sts -n cpd-instance | grep ibm-lh-lakehouse
ibm-lh-lakehouse-presto-01-presto 0/0 17d
ibm-lh-lakehouse-presto-01-presto-coordinator 1/1 17d
ibm-lh-lakehouse-presto-01-presto-worker 3/3 17d
現時点のCP4D 4.7.x のマニュアルによると、自動スケーリングと手動スケーリングのやり方があり、手動スケーリングでは small/medium/large/xlarge が選択できるようです。
oc patch wxdengine/lakehouse-presto-01 \
--type=merge \
-n ${PROJECT_CPD_INST_OPERANDS} \
-p '{ "spec": { "autoScaleConfig": "true", "lakehouseDeploymentType": "multinode" } }'
oc patch wxdengine/lakehouse-presto-01 \
--type=merge \
-n ${PROJECT_CPD_INST_OPERANDS} \
-p '{ "spec": { "scaleConfig": "small", "lakehouseDeploymentType": "multinode" } }'