はじめに
この記事は競技プログラミングを始めたばかりの人に伝えたいことアドベントカレンダー8日目の記事です。
0. 作成したもの
以下のgithubページにて公開しております。
https://github.com/moffuu/atcoder-useful-tools
1. 概要
※以下のツールはlinux上での利用を想定しています。
今回、コマンドラインから実行するだけで、簡単にソースコードを保存できるツールを開発しました。
1.checker.py
コンテスト番号(ex; agc055), ユーザーの名前(ex; chokudai)を引数に取り、該当する提出のうち、ACした問題の問題番号および問題名を出力します。
2.getter.py
コンテスト番号, ユーザーの名前, 問題番号(ex; a)を引数に取り、該当するコードを出力します。一度に取得できるコードは一つまでです。
2. 使い方
この二つのツールを組み合わせることで、提出されたコードを簡単に手元に保存することができます。(ここではchokudaiさんのagc055、それのA問題のコードを対象とします)
1.取得したい問題が存在するかを確認します。以下のコマンドを実行します。
python3 checker.py agc055 chokudai //コンテスト名・問題番号は半角で入力してください
すると以下のような結果が出力されました。
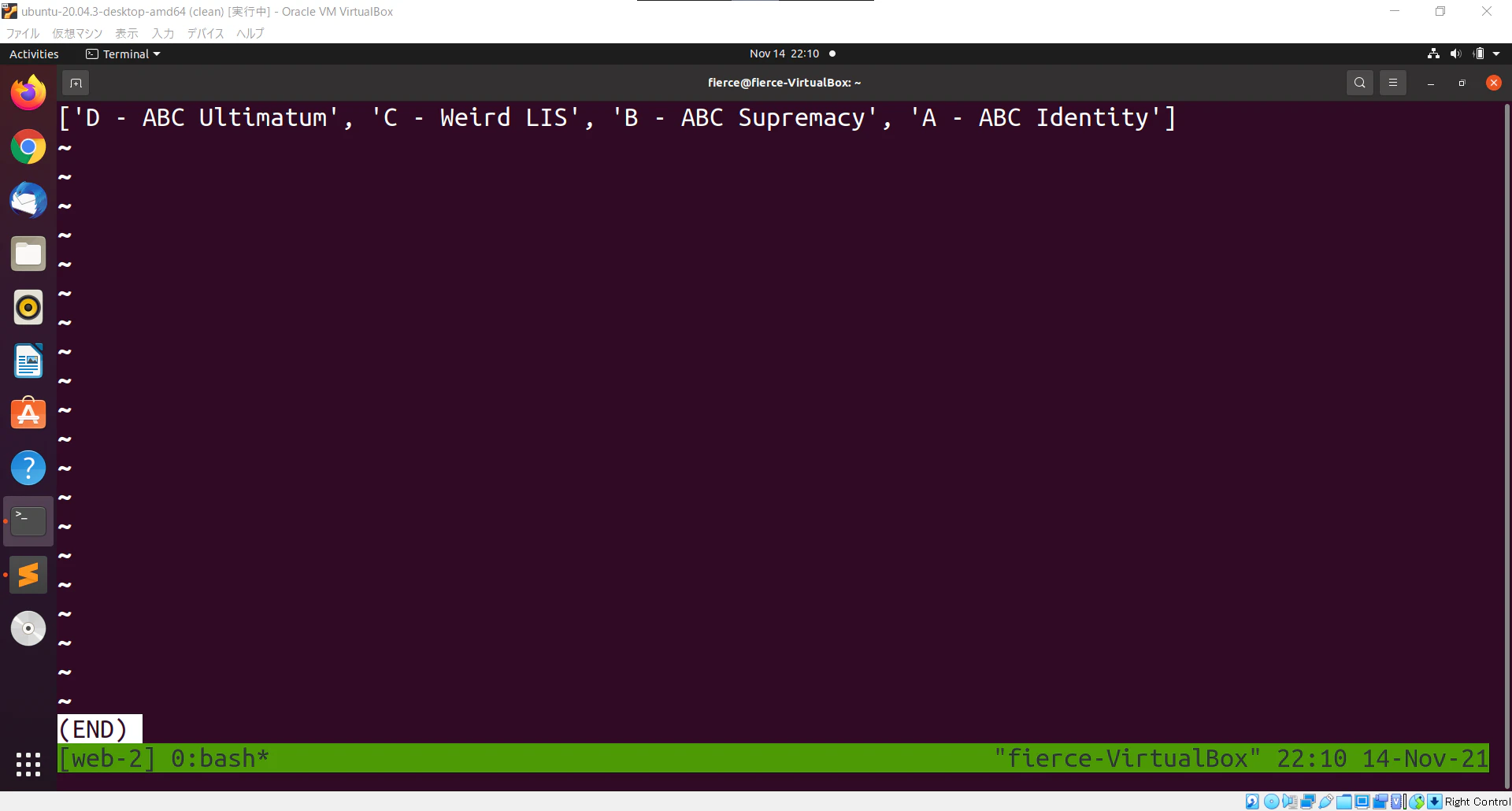
2.該当するコードの存在が確認できたので、以下のコマンドにて該当するコードを取得します。(ここでは、a.cppという名前で保存しています)
python3 getter.py agc055 chokudai a > a.cpp
vimで確認します。
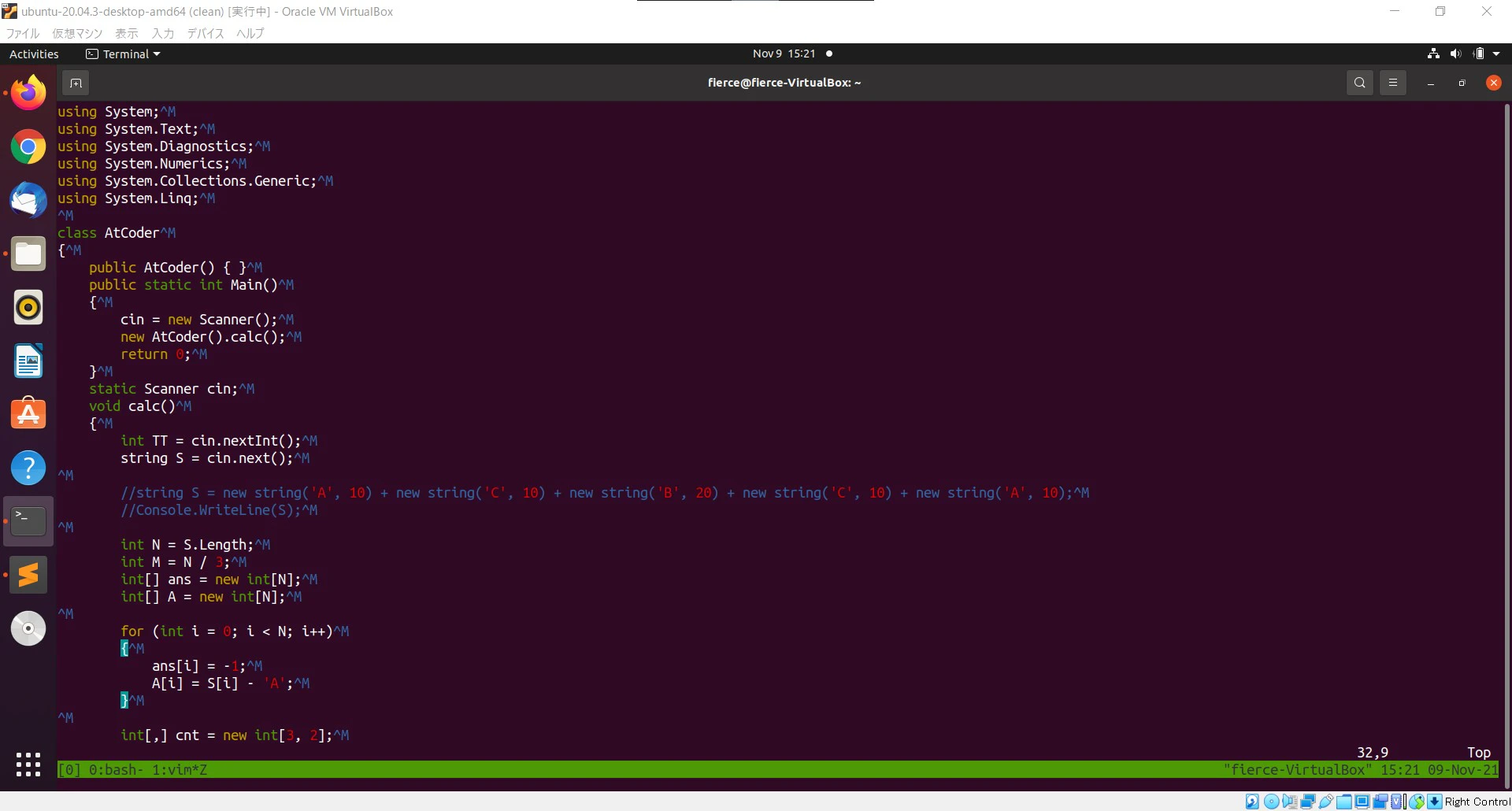
きちんと保存できているのが確認できました。
3. インストール
beautifulsoup4, requestsというモジュールが必要となるので、以下のコマンドにてインストールを行います。
pip install beautifulsoup4 requests
以下のコマンドでカレントディレクトリにリポジトリを保存します。
git clone https://github.com/moffuu/atcoder-useful-tools.git
作成されたディレクトリに移動します。
cd atcoder-useful-tools.git
お好きな場所にcpコマンド等で移動されてください。
一例ですが私は~/work/atcoderにおいています。
4. 動機
プログラミングを学習する上で、他の人のソースコードを読むのはとても参考になります。しかし、他の人の提出したコードをatcoderで見るためには、少々煩雑な操作を毎回行う必要があります。それでは時間がとられてしまってしょうがないので、コマンドラインから実行できるようなツールを作成することを決めました。
実際に一から実装する経験が極めて乏しいといった事情もあり、まず最低限動くもの、かつ実用に耐えられるものの作成を最優先としました。
5. 制作過程
ここから先は実際に自分がどのように作成していったかを解説していきます。
今回作成したのはごく簡単なツールであるので簡単に理解できるかと思いますが、逆に経験のある人にとっては少々物足りないものになってしまっているかもしれません。ご了承ください。
1. checker.py
0. 設計
まず、設計を行います。
以下の質問を埋めていく形で、どのようなツールをどうやって作成するかイメージを固めていきます。
-
やりたいことは何か?
→ あるユーザーがどの問題をACしたか調べたい -
どのような方法で?
→ 特定のurlのHTMLソースを読み込み、必要な部分のみを抽出する -
入力、出力はどのようなものを想定しているか?
入力: python3 checker.py "contest" "username"
出力: ACした問題番号が表示される
以上より、入力されたコンテスト名、ユーザー名を入力として該当する情報を出力するツールを作成すればよいことがわかります。
また、調べた結果このようにHTMLソースから特定の情報のみを抽出する技術をウェブスクレイピングということが分かりました。
1. 実装
スクレイピングするためには、抜きだしたい部分のhtmlやcssタグの情報が必要となるようなので、まず簡易的な分析を行っていきたいと思います。
ここでは、提出されたコードの内、正解した問題のみを出力したいので、以下のように設定します。

すると以下のようなurlが生成されるので、これをベースにすればよさそうです。
https://atcoder.jp/contests/agc055/submissions?f.Task=&f.LanguageName=&f.Status=AC&f.User=chokudai
それでは、以下の記事のソースコードを利用して簡易的な分析を行っていきます。
import requests
from bs4 import BeautifulSoup
# Webページを取得して解析する
load_url = "https://atcoder.jp/contests/agc055/submissions?f.Task=&f.LanguageName=&f.Status=AC&f.User=chokudai"
html = requests.get(load_url)
soup = BeautifulSoup(html.content, "html.parser")
# HTML全体を表示する
print(soup.prettify())
出力結果
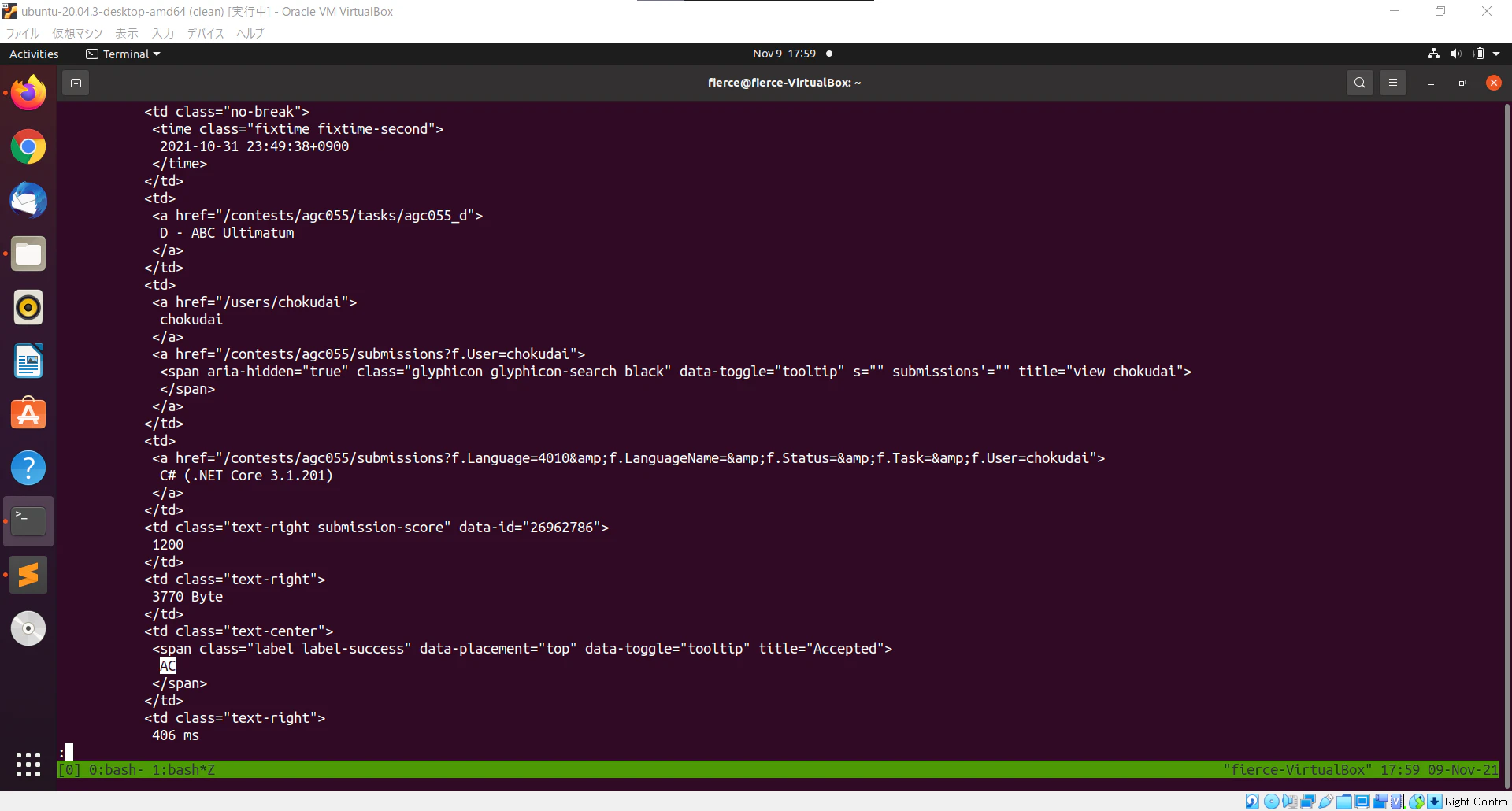
少しわかりにくいですが、以上の結果から提出結果はtdタグの部分に含まれることが分かりました。そこでtdタグの部分のみを出力するようにsoup.select()を使います。
import requests, html
from bs4 import BeautifulSoup
url = "https://atcoder.jp/contests/agc055/submissions?f.Task=&f.LanguageName=&f.Status=AC&f.User=chokudai"
html = requests.get(url)
soup = BeautifulSoup(html.content, "html.parser")
for tag in soup.select('td'):
print(tag)
出力結果
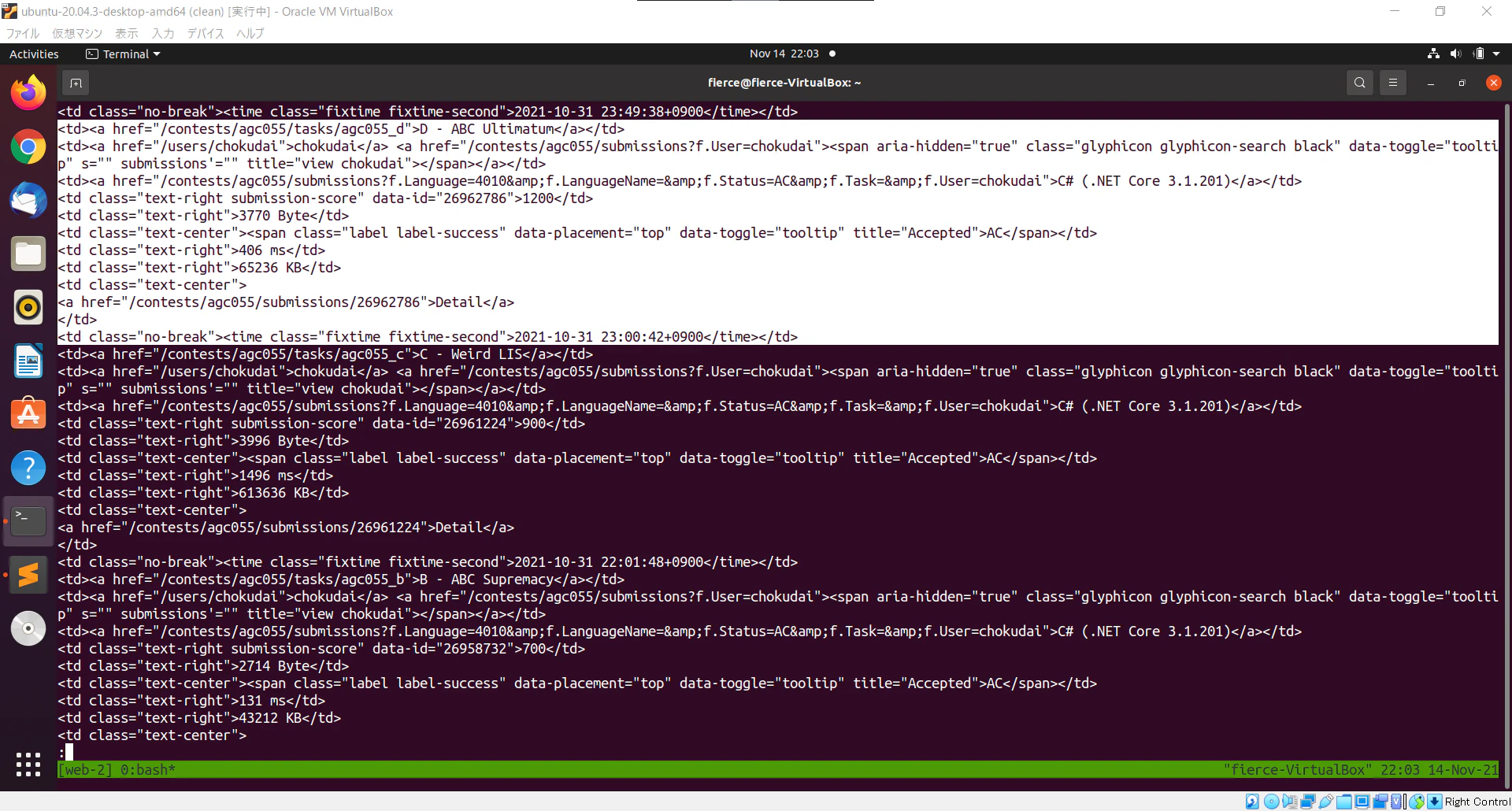
実行した結果から、2行目を始点として10行飛ばしで出力すれば良いことがわかりました。
また、このままでは読みにくいため、可読部分のみを取得するようにします。
以下の記事からソースコードを引用しています。
import requests, html
from bs4 import BeautifulSoup
url = "https://atcoder.jp/contests/agc055/submissions?f.Task=&f.LanguageName=&f.Status=AC&f.User=chokudai"
html = requests.get(url)
soup = BeautifulSoup(html.content, "html.parser")
X = []
for tag in soup.select('td')[1::10]:
problemid = tag.text
X.append(problemid)
print(X)
最後に入力部分をシステムモジュールを用いて実装していきます。
最終的に完成したのがこちらになります。
import requests, html, sys
from bs4 import BeautifulSoup
url = "https://atcoder.jp/contests/" + sys.argv[1] + "/submissions?f.Status=AC&f.User=" + sys.argv[2]
html = requests.get(url)
soup = BeautifulSoup(html.content, "html.parser")
X = []
for tag in soup.select('td')[1::10]:
problemid = tag.text
X.append(problemid)
print(X)
出力結果
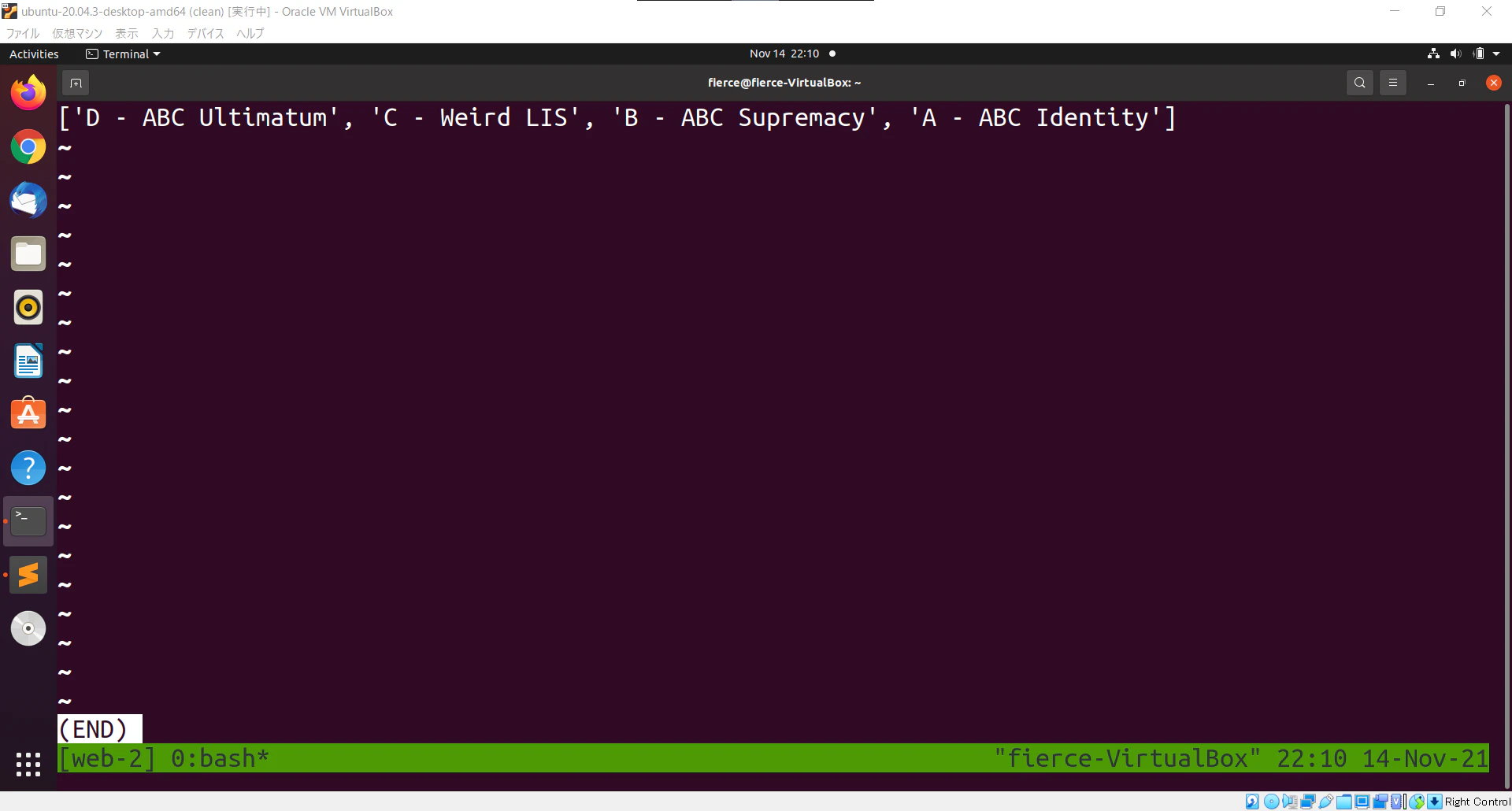
いい感じですね。
それでは、次にソースコードの取得を行うツールを作成していきます。
2. getter.py
1. 設計
-
やりたいことは何か?
指定した入力をもとに、手元にコードを保存したい -
どのような方法で?
ファイルの保存は>(リダイレクト)を使えばよいので、
HTMLソースからソースコードのみを取得し、結果を出力するようなものを作ればよい -
入力や出力はどのようなものを想定(期待)しているか?
入力: python3 getter.py "contest_name" "user_name" "mondaibangou"
出力: 該当する提出のソースコードが画面に出力される
以上の機能を実行するためには
1.指定した問題のリンクの習得
2.リンク先からソースコードの部分のみを習得
というように段階的に処理するよう実装すればよさそうですね。
3. 実装
1. リンクの習得
まず、最初の部分である問題のリンクを取得する部分を実装します。
ここでは、問題文のリンク先がどの部分に配置されているのか特定するためにリンクをすべて出力します
上記の記事を参考に作成していきます。
import requests, html
from bs4 import BeautifulSoup
url = "https://atcoder.jp/contests/agc055/submissions?f.Task=&f.LanguageName=&f.Status=AC&f.User=chokudai"
html = requests.get(url)
soup = BeautifulSoup(html.content, "html.parser")
x = []
links = soup.find_all('a')
for link in links:
x.append(link.get('href'))
print(link.get('href'))
出力結果
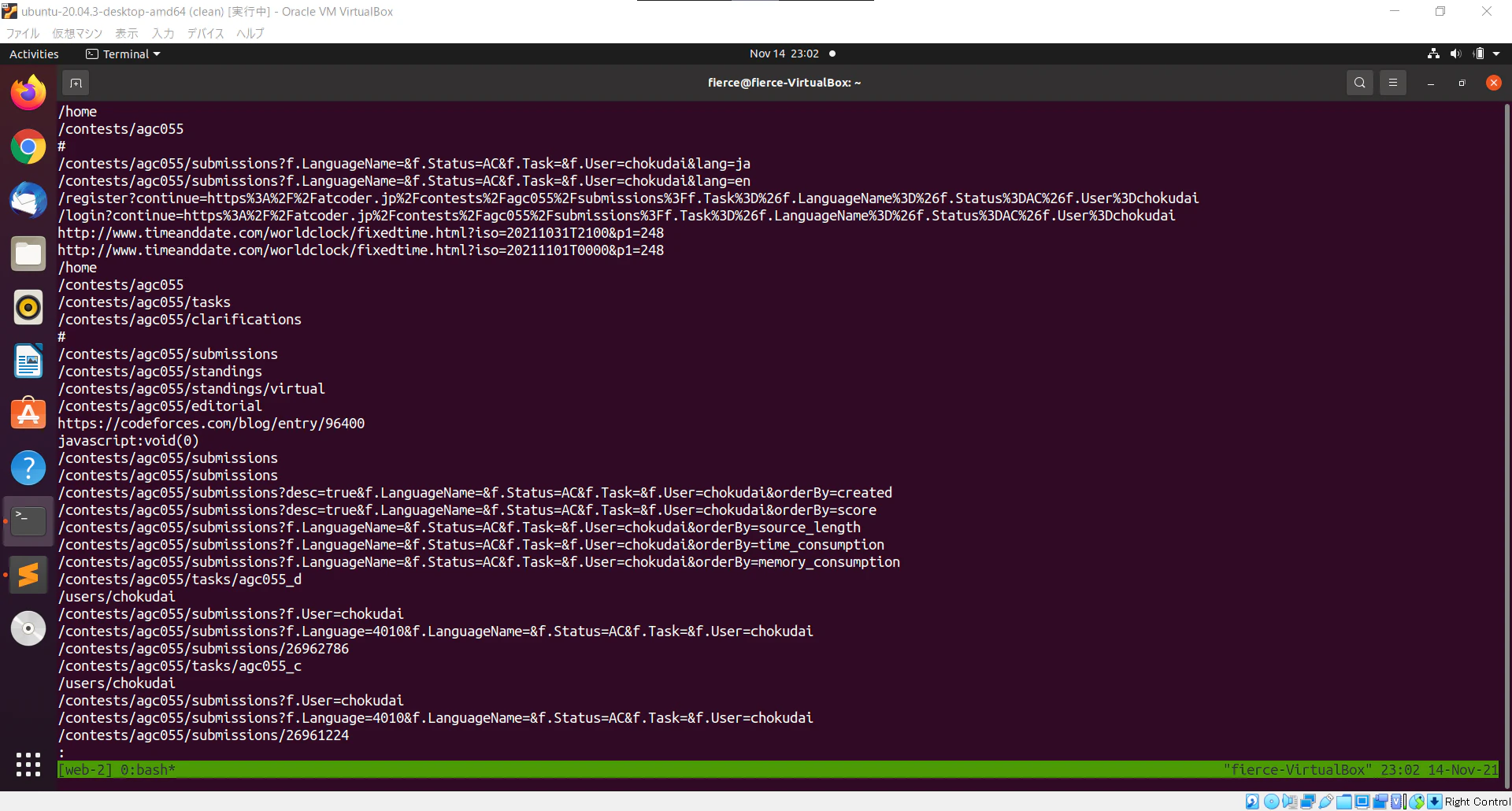
リンク先の一覧が取得できました。
ここからさらに条件を満たすリンクを取得する必要がありますが、少し実装が大変なので、先にソースコードの取得する部分を作成した後で実装する方向で作っていこうと思います。
それでは、リンク先からソースコードの部分だけを取得する部分の実装を行っていきます。
2. ソースコードの取得
それではコードを取得する部分を作成していきます。
chokudaiさんの提出した 以下のリンクから取得することを目標とします。
https://atcoder.jp/contests/agc055/submissions/26957745
先ほどと同じようにソースコードが埋められている場所を特定すると、今度はpreタグに挟まれていることがわかりました。
ソースコードの取得のみを目的としているので、stringを使います。
import requests, html
from bs4 import BeautifulSoup
req = "https://atcoder.jp/contests/agc055/submissions/26957745"
html = requests.get(req)
soup = BeautifulSoup(html.content, "html.parser")
print(soup.pre.string)
実行してみます。

いいですね、ちゃんとソースコードの部分のみが出力されています。
3. 条件分岐
さて、先ほどは 簡略化のためにリンクを固定していましたが、入力に従ってリンクの取得先を変更しなければなりません。
ここまではほとんど参考資料からのコピペでどうにかなっていましたが、ここばかりはどうにもならないので気合で作っていきます。
まずは、分岐の条件を決定するため、取得したリンクの分析を行っていきます。

出力結果から、
・一回目の出現を無視して、部分文字列に'task'が含まれているか?
・また、指定した文字(問題番号)が文字列の末尾と一致するか?
を条件にすればよさそうですね。
ここでは、リンクが問題番号の4行後に来ていることに着目すれば上手いことリンク先が取得できそうです。
簡易にテストを行うために、ここでは'a'が入力されることを前提としています。
それでは頑張って作っていきます。
import requests, html
from bs4 import BeautifulSoup
url = "https://atcoder.jp/contests/agc055/submissions?f.Task=&f.LanguageName=&f.Status=AC&f.User=chokudai"
html = requests.get(url)
soup = BeautifulSoup(html.content, "html.parser")
x = []
links = soup.find_all('a')
for link in links:
x.append(link.get('href'))
url = []
count = 0
for i, j in enumerate(x):
string = str(j)
if('task' in string):
count = count + 1
if(count >= 2 and 'a' == string[-1::]):
url = str(x[i+4])
print(url)
break
動かしてみます。

出力結果
/contests/agc055/submissions/26957745
ちゃんと提出先のリンクが取得できていますね。
では、1で作成したソースの習得を行う部分と合体させます。
import requests, html
from bs4 import BeautifulSoup
url = "https://atcoder.jp/contests/agc055/submissions?f.Task=&f.LanguageName=&f.Status=AC&f.User=chokudai"
html = requests.get(url)
soup = BeautifulSoup(html.content, "html.parser")
x = []
links = soup.find_all('a')
for link in links:
x.append(link.get('href'))
url = []
count = 0
for i, j in enumerate(x):
string = str(j)
if('task' in string):
count = count + 1
if(count >= 2 and 'a' == string[-1::]):
url = str(x[i+4])
break
req = "https://atcoder.jp" + url
html = requests.get(req)
soup = BeautifulSoup(html.content, "html.parser")
print(soup.pre.string)
動かしてみます

良かった...ちゃんと動きましたね。
それでは、checker.pyと同じ要領で入力の部分も作成していきます。
最終的に完成したのがこちらとなります。
import requests, html, sys
from bs4 import BeautifulSoup
url = "https://atcoder.jp/contests/" + sys.argv[1] + "/submissions?f.Status=AC&f.User=" + sys.argv[2]
html = requests.get(url)
soup = BeautifulSoup(html.content, "html.parser")
x = []
links = soup.find_all('a')
for link in links:
x.append(link.get('href'))
url = []
count = 0
for i, j in enumerate(x):
string = str(j)
if('task' in string):
count = count + 1
if(count >= 2 and str(sys.argv[3]) == string[-1::]):
url = str(x[i+4])
break
req = "https://atcoder.jp" + url
html = requests.get(req)
soup = BeautifulSoup(html.content, "html.parser")
print(soup.pre.string)
完成!
6. 感想
自分でプログラムを組むのは無謀ではないかと考えていたのですが、やりたいことを分解して自身が実装したい機能を明確化できれば、案外調べればどうにかなるとわかりました。情報を公開してくれる先人の方々に感謝したいです。
また、プログラミングで何を作るといった経験は今回が初めてで、苦労した点も多々ありましたが、やはり自分で何か物を作るというのはとても楽しいですね。もっと技術をつけて作れるものの幅を広げていきたいです。
7. 課題点
一方課題点としては、バージョン管理の拙さがあげられます。

上記は『わかばちゃんと学ぶbit使い方入門』からの引用ですが、私のディレクトリもこのようになってしまい、管理が凡雑になってしまい能率・モチベーションの低下につながってしまいました。次に何か作る時には事前にgitなどのバージョン管理システムについて学習しておきたいです。
また、今回作成したツールはほとんどの部分が公開されているコードをつなぎ合わせた張りぼてのようなものなので、自分で作ったとはあまりいいがたいところがありますし、言語の仕様に関する知識の欠如から原因不明のエラーにも悩まされました。そのため一度体系的にプログラミングを学習しなおしておきたいですね。
8. 参考文献
作成の上で大変参考になりました、この場を借りて感謝申し上げます。
【保存版】Python BeautifulSoupの基礎と使い方