この記事は リンク情報システム の「2021新春アドベントカレンダー TechConnect!」のリレー記事です。
TechConnect! は勝手に始めるアドベントカレンダーとして、engineer.hanzomon という勝手に作ったグループによってリレーされます。
(リンク情報システムのFacebookはこちらから)
はじめに
前回に引き続き自由な記事となります。
AIのセミナーを受講したので、復習としてscikit-learnとkerasでCNNを使って、シャドバの画像をリーダークラスで分類してみました。
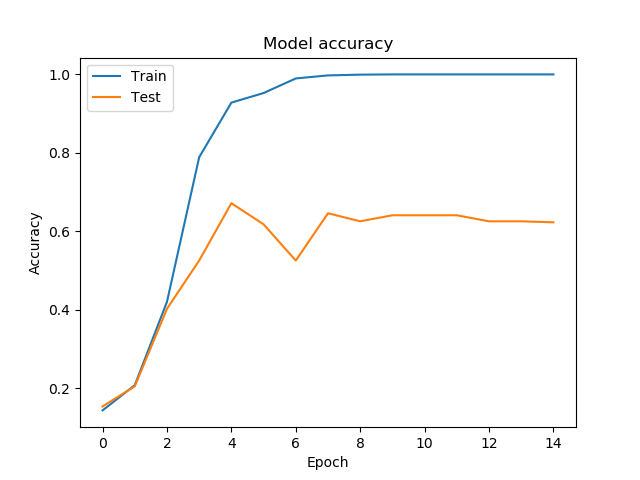
結果
なんとも言えない結果ですが、これが一番マシでした。(トレーニングデータとの一致率100%とか許されるんですかい)
Trainがトレーニングデータの一致率、Testがテストデータの一致率です。
最新弾のカードでテスト
データセットに入れていない、最新弾(十天覚醒)のカード各11枚を分類させた時の正解数はこちら
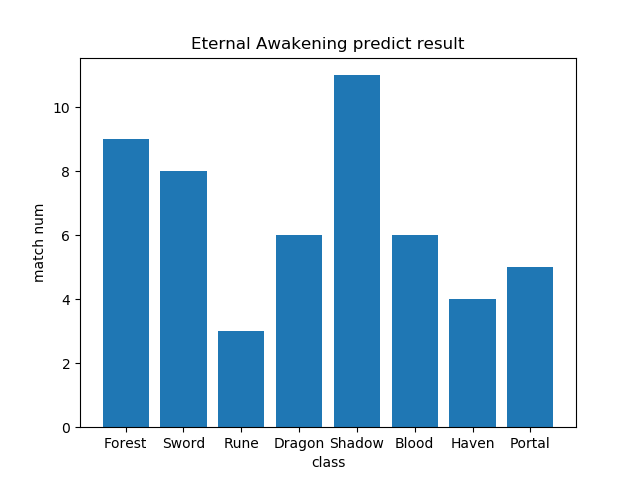
Shadow(ネクロマンサー)のカードは全部Shadowと分類できました。
反面、Rune(ウィッチ)は 3枚しか当たらず。
カード絵に特徴のあるクラスが良くできているような気がする結果となりました。
・ネクロ:ドクロとか専用のモチーフが多いところ、全体的に暗めなのが特徴的なのかも。
・ウィッチ:人間系がロイヤル/ネメシス、怪物系はネクロ/ドラゴンと混同されてるように見える。
誤答が面白い
誤答したカードを見ると、たしかに誤答したクラスのカードっぽくて面白いです。
例:Shadowと誤答したRuneのカード(エルモートの見た目はネクロっぽいな……)
https://shadowverse-portal.com/card/119321010?lang=ja
例:Swordと誤答したDragonのカード(剣持ってる人型なのでロイヤル)
https://shadowverse-portal.com/card/119411010?lang=ja
例:Runeと誤答したPortalのカード(むしろ何故ウィッチじゃなかったのか、CNNもそう仰っている)
https://shadowverse-portal.com/card/119831010?lang=ja
準備
まずシャドバのカード画像データを用意します。(今回はベーシック~ナテラ崩壊まで)
収集時は何も考えてなかったので日本語カード名がファイル名な上、リーダークラスが分かれていません。
これを、以下のように整理します。
・リーダークラス別のフォルダに格納
・XXX_クラス名にリネームする
ニュートラルカードは共通する特徴が無くて学習を邪魔しそうなので捨てます。
学習する
まずは、OpenCVを使って画像を整形します。(CNNに入れるために正方形に引き伸ばす)
from glob import glob
import cv2
import os
path = glob('./img_class/*/')
data = [] # 画像データ
label = [] # ラベル(分類)
class_num = 0 # 分類ID(8リーダーなので0-7が割り振られる)
image_size = 256 # リサイズする正方形のサイズ
for f in path:
files = os.listdir(directory)
for image in files: # Directory内の全画像を整形してリスト化する
if image.endswith(".png"):
image = cv2.imread(directory + image)
image =cv2.resize(image, (image_size, image_size))
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # なんとなくRGBにする(ライブ感)
image_rgb = image_rgb.flatten() # 平坦化
data.append(image_rgb)
label.append(class_num)
class_num += 1
これで256*256に引き伸ばされたカード画像とラベルのセットができました。
次にscikit-learnの力で、CNNに合わせて学習データを整形します。
import numpy as np
import tensorflow as tf
from tensorflow import keras
from keras.utils.np_utils import to_categorical
from sklearn.model_selection import train_test_split
# データ型を変更
data = np.array(data, dtype=np.float32)
label = np.array(label, dtype=np.float32)
# 学習データとテストデータに分割(8:2)
train_data, test_data, train_label, test_label = train_test_split(
data,label, random_state = 1, stratify = label, test_size = 0.2)
# リストを変形[データ数, 256, 256, 3(RGBのチャネル数)]
train_data = train_data.reshape((len(train_data)),image_size,image_size,3)
test_data = test_data.reshape((len(test_data)),image_size,image_size,3)
# 正規化
train_data /= 255
test_data /= 255
# ラベルデータをone-hot encoding(種別数はリーダー数の8)
train_label = to_categorical(train_label, num_classes = 8)
test_label = to_categorical(test_label, num_classes = 8)
これで学習データの準備ができました。
次にCNNをなんとなく組みます。kerasめっちゃ簡単ですごい。
from tensorflow.keras import models,layers
from tensorflow.keras import optimizers
model = models.Sequential()
model.add(layers.Conv2D(20, (5, 5), activation='relu', padding='same', input_shape=(image_size, image_size, 3)))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Conv2D(50, (5, 5), activation='relu', padding='same'))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(500, activation='relu'))
model.add(layers.Dense(500, activation='relu'))
model.add(layers.Dense(8, activation='softmax'))
model.compile(optimizer='adam',loss = 'categorical_crossentropy',metrics = ["accuracy"])
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 256, 256, 20) 1520
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 128, 128, 20) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 128, 128, 50) 25050
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 64, 64, 50) 0
_________________________________________________________________
flatten (Flatten) (None, 204800) 0
_________________________________________________________________
dense (Dense) (None, 500) 102400500
_________________________________________________________________
dense_1 (Dense) (None, 500) 250500
_________________________________________________________________
dense_2 (Dense) (None, 8) 4008
=================================================================
Total params: 102,681,578
Trainable params: 102,681,578
Non-trainable params: 0
学習します。(最初の結果の通り、一瞬でLossが0になってしまうのでEarlyStoppingが必要(1敗))
epoch = 100
batchsize = 25
# EarlyStopping
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(monitor='val_loss',
patience=10,
min_delta= 0.01,
verbose=1)
hist = model.fit(train_data, train_label, batch_size=batchsize,
epochs=epoch, verbose=2,
validation_data=(test_data, test_label),
callbacks=[early_stopping])
15~16分で終了するので、結果を保存します。あと、学習過程も出します。
from keras.models import load_model
model.save('./my_model.h5')
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
ハイパーパラメータを色々いじったり、画像サイズを変えたり、グレースケールにしてみたり、いろいろ試した結果、
学習時間が短くて、いい感じだったのが以上の手順です。
ちなみに一番ひどかった結果は画像サイズ128、グレースケールの時で、テストデータの一致率が0.2でした。
学習モデルを使って分類してみる
最新弾(2021/1/11現在)である「十天覚醒」のカードをクラス分類してみましょう。
パックを代表するお兄さんを判定してみます。(正解はSwordです。)
https://shadowverse-portal.com/card/119241020?lang=ja
# ファイルをロードして、学習時と同じサイズでリサイズ、CNN用のデータに整形します
image = cv2.imread(path)
image = cv2.resize(image, (image_size, image_size))
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image_rgb = image_rgb.flatten()
data.append(image_rgb)
data = np.array(data, dtype=np.float32)
data = data.reshape((len(data)),image_size,image_size,3)
data /= 255 # to 0-1
# モデルのロード
mymodel = keras.models.load_model('./Color_my_model.h5', compile=False)
mymodel.summary()
# モデルを使って予測
predict = mymodel.predict(data)
# 結果は、0-7で返却されるので変換して表示
base = ['Forest', 'Sword', 'Rune', 'Dragon', 'Shadow', 'Blood', 'Haven', 'Portal']
for fil, pred in zip(file_name, predict):
pred_index = np.argmax(pred)
print(str(fil)+" :" + base[pred_index])
score.append(pred_index)
Seofon.png:Sword
ちゃんと判定できてますね!!!!
(なお、全体の正答率)
終わりに
自分でデータを用意してやってみると、どんな結果が出ても興味深く、より面白いですね。
誤答もカード画像を見るとなんか納得できるのがエンタメ感あります。
次回は@hs-lisさんです。