日本語を utf-8 や shift-jis でエンコードしてバイナリを眺めてみる
# utf-8
$ echo あ | nkf -w | hexdump
0000000 e3 81 82 0a
0000004
# utf-8 BOM あり
$ echo あ | nkf -w8 | hexdump
0000000 ef bb bf e3 81 82 0a
0000007
# shift-jis
$ echo あ | nkf -s | hexdump
0000000 82 a0 0a
0000003
行末の 0a は改行コードです、つまり LF。
あ のバイト数ですが、
utf-8 だと e3 81 82 3バイトです。
shift-jis だと 82 a0 2バイトです。
愛を分解してみる
U+611B
これを utf-8 でエンコードすると 3バイトの
e6 84 9b
となる。
参考. https://elite-lane.com/difference-between-unicode-and-utf-8-and-utf-16-and-utf-32/
文字化けを再現してみる
「ようこそ」という文字列を Shift JIS でエンコードして保存してみます。それを hexdump で見ると以下のようになっています。
ようこそ
mac のターミナルで以下のような感じに見えます。
$ hexdump welcome_shift_jis.txt
0000000 82 e6 82 a4 82 b1 82 bb 0a
0000009
$ cat welcome_shift_jis.txt
�悤����
文字化けが発生しています。
ここで「悤」に注目してみます。
Shift JIS でエンコードされたバイナリは、行末の改行( 0a ) を除くと
82 e6 82 a4 82 b1 82 bb
です。そしてこれを、utf-8 で解釈すると、
e6 82 a4
この部分が以下にヒットします。
https://www.compart.com/en/unicode/U+60A4
Unicode Character “悤” (U+60A4)
UTF-8 Encoding: 0xE6 0x82 0xA4
Ruby の File.open のエンコードの挙動
>> File.open('test1', 'w:utf-8'){|f| f.write('ようこそ'.encode('cp932'))} #=> 12
>> cat 'test1' #=> "ようこそ"
>> File.open('test1', 'w'){|f| f.write('ようこそ'.encode('cp932'))} #=> 8
>> cat 'test1' #=> "\x82悤\x82\xB1\x82\xBB"
ext_enc(外部エンコーディング)が指定されている場合、読み込まれた文字列にはこのエンコーディングが指定され、出力する文字列はそのエンコーディングに変換されます。
Mac の Excel で開いて文字化けするか見てみる。
律儀に以下のパターンで csv ファイルを作ってみました。
$ tree .
.
├── utf16_BE_with_bom.csv
├── utf16_BE_without_bom.csv
├── utf16_LE_with_bom.csv
├── utf16_LE_without_bom.csv
├── utf8_with_bom.csv
└── utf8_without_bom.csv
たとえば、以下のような感じでファイルは作っています。
cf. https://kazmax.zpp.jp/cmd/n/nkf.1.html
$ echo ようこそ | nkf -w16L0 > utf16_LE_without_bom.csv
結果はこうなりました。
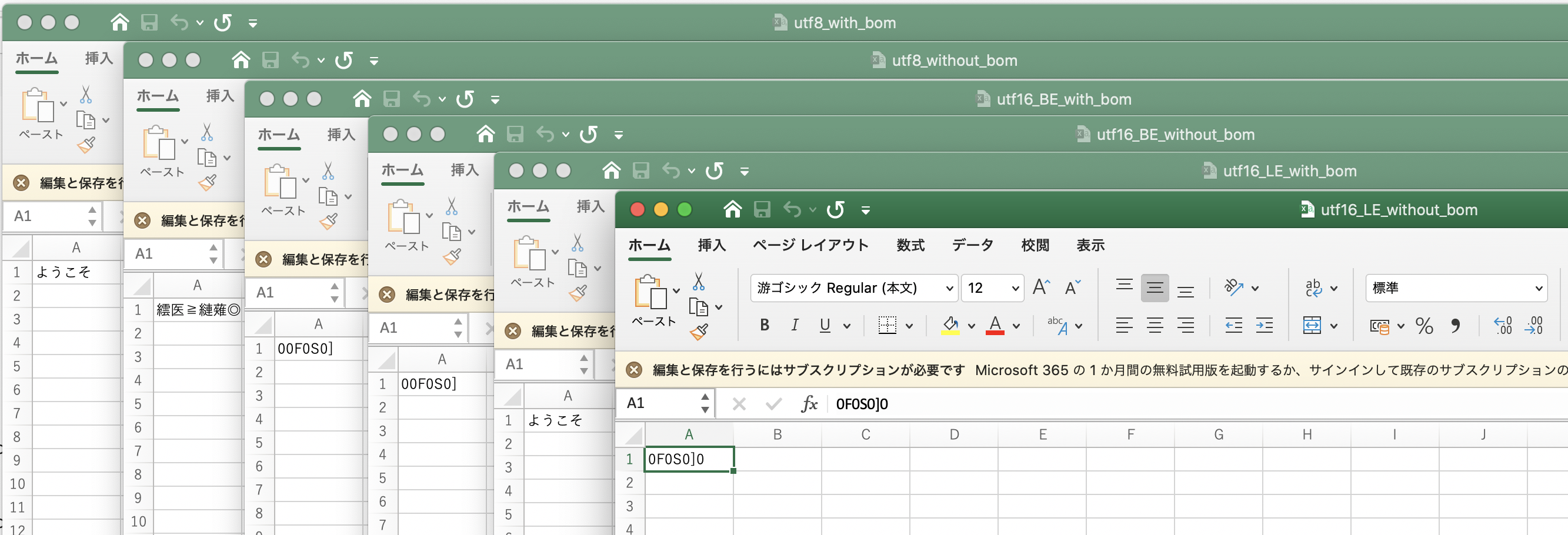
- UTF-8 BOM 有り
- UTF-16 LE BOM 有り
この 2パターンは文字化けせずに表示されました。
それぞれの hexdump はこちら
bash-3.2$ ls -1 | while read line; do echo $line; hexdump $line; echo -e '\n'; done
utf16_BE_with_bom.csv
0000000 fe ff 30 88 30 46 30 53 30 5d 00 0a
000000c
utf16_BE_without_bom.csv
0000000 30 88 30 46 30 53 30 5d 00 0a
000000a
utf16_LE_with_bom.csv
0000000 ff fe 88 30 46 30 53 30 5d 30 0a 00
000000c
utf16_LE_without_bom.csv
0000000 88 30 46 30 53 30 5d 30 0a 00
000000a
utf8_with_bom.csv
0000000 ef bb bf e3 82 88 e3 81 86 e3 81 93 e3 81 9d 0a
0000010
utf8_without_bom.csv
0000000 e3 82 88 e3 81 86 e3 81 93 e3 81 9d 0a
000000d
fish も書いておこう。
$ ls | while read file; echo $file; hexdump $file; echo \n; end
バイナリを眺める
$ echo あ > a.txt
~/Desktop
$ cat a.txt
あ
~/Desktop
$ hexdump a.txt
0000000 e3 81 82 0a
0000004
~/Desktop
$ xxd a.txt
00000000: e381 820a ....
~/Desktop
$ xxd -b a.txt
00000000: 11100011 10000001 10000010 00001010
参考リンクやおまけ
https://itsakura.com/it-unicode-utf
https://elite-lane.com/difference-between-unicode-and-utf-8-and-utf-16-and-utf-32/
UTF-16は、「0xD842」と「0xDFB7」の2つになっています。2バイト*2で4バイト使用しています。上位サロゲートと下位サロゲートといいます。
UTF-8は、「F0 A0 AE B7」です。4バイト使用しています。
ちなみにデータベース「MySQL」のUTF-8 mb4は、4バイトに対応しているUTF-8のことです。
そーだったんだ。
サロゲートペアについては上の参考リンクで理解できます。
0x というのは16進数表記という意味。