はじめに
新型コロナウイルス感染症(COVID-19)のせいで,学校が休校となり最新情報を学校のHPで随時更新するらいいいので,自動で更新を取得,クラスLINEに通知システムを作ってみた.
環境
ubuntu19.10
Python 3.7.5
実装方法
1.学校のホームページの情報を30分に一度取得する.
2.前回取得分のデータとの差分を調べる.
3.差分があればLINE Notifyを用いてクラスLINEに通知
プログラム
1.学校のホームページの情報取得する.(TOPページと学年ごとの連絡を取得)
res = requests.get(url1)
res2 = requests.get(url2)
res.encoding = res.apparent_encoding
res2.encoding = res2.apparent_encoding
2.前回取得分のデータとの差分を調べる.
m = "\n" + link
result = list(set(list1) - set(list2))
print("raw" + str(result))
if len(result) > 30:
result = []
elif len(result) >= 30:
result = "文字数制限・゚・(。>Д<。)・゚・"
result = m + "\n" + result
elif result != []:
for s in result:
m = m + "\n" + s
result = m
3.差分があればLINE Notifyを用いてクラスLINEに通知
url = "https://notify-api.line.me/api/notify"
headers = {'Authorization': 'Bearer ' + access_token}
payload = {'message': message}
r = requests.post(url, headers=headers, params=payload,)
全体
import re
import requests
import copy
import time
import requests
import datetime
def get_data(url1, url2):
global res, res2
res = requests.get(url1)
res2 = requests.get(url2)
res.encoding = res.apparent_encoding
res2.encoding = res2.apparent_encoding
def format_text(text):
text = re.sub(r'[a-zA-Z0-9]', '', text)
text = re.sub(r'[!-/:-@[-`{-~]', '', text)
text = text.replace(' ', '')
return text
def task1():
print(datetime.datetime.now())
text = format_text(res.text)
text2 = format_text(res2.text)
global l1, l2
l1 = text.split()
l2 = text2.split()
global result, result2
result = difference(l1, l_b1, URL1)
result2 = difference(l2, l_b2, URL2)
print(result, result2)
def task2():
global l_b1, l_b2
l_b1 = copy.deepcopy(l1)
l_b2 = copy.deepcopy(l2)
def difference(list1, list2, link):
m = "\n" + link
result = list(set(list1) - set(list2))
print("raw" + str(result))
if len(result) > 30:
result = []
elif len(result) >= 30:
result = "文字数制限・゚・(。>Д<。)・゚・"
result = m + "\n" + result
elif result != []:
for s in result:
m = m + "\n" + s
result = m
return result
def line(message, access_token):
url = "https://notify-api.line.me/api/notify"
headers = {'Authorization': 'Bearer ' + access_token}
payload = {'message': message}
r = requests.post(url, headers=headers, params=payload,)
def sent(name, message, token1, token2):
if message != []:
line(message, token1)
line(message, token2)
else:
line(name + "==[]", token2)
def main():
global l_b1, l_b2, URL1, URL2
l_b1 = []
l_b2 = []
URL1 = "取得したいHPのURL"
URL2 = "取得したいHPのURL"
class_line = "クラスLINEのトークン"
admin_line = "自分のトークン"
while True:
get_data(URL1, URL2)
task1()
sent("result", result, class_line, admin_line)
sent("result2", result2, class_line, admin_line)
task2()
for i in range(6):
line("\n" + str(datetime.datetime.now()) + "\n" +
"正常に動作しています.多分..." + "\n" + str(i), admin_line)
time.sleep(300)
if __name__ == '__main__':
main()
5分に一回自分宛てに"正常に動作しています.多分..."というメッセージが届くようにしました.
正直いらない機能だと思っているのは内緒にしておきます.(笑)
文字数制限に関しては正直適当です.
追記
main()を以下のように変更し,エラー対処を行いました.
def main():
global l_b1, l_b2, URL1, URL2
l_b1 = []
l_b2 = []
URL1 = "取得したいHPのURL"
URL2 = "取得したいHPのURL"
class_line = "クラスLINEのトークン"
admin_line = "自分のトークン"
while True:
try:
get_data(URL1, URL2)
task1()
sent("result", result, class_line, admin_line)
sent("result2", result2, class_line, admin_line)
task2()
for i in range(6):
line("\n" + str(datetime.datetime.now()) + "\n" +
"正常に動作しています.多分..." + "\n" + str(i), admin_line)
time.sleep(300)
except Exception as e:
try:
line("\n" + str(e) + "error occurred", admin_line)
except Exception as e:
print(e, "error occurred")
time.sleep(30)
sent()を以下のように変更しました.
def sent(name, message, token1, token2):
try:
if message != []:
line(message, token1)
line(message, token2)
else:
line(name + "==[]", token2)
except Exception as e:
try:
line("\n" + str(e) + "error occurred",token2)
except Exception as e:
print(e, "error occurred")
difference()を以下のように変更しました
def difference(list1, list2, link):
m = "\n" + link
result = list(set(list1) - set(list2))
print("raw" + str(result))
if result != []:
for s in result:
m = m + "\n" + s
result = m
return result
最終的なプログラム
import re
import requests
import copy
import time
import requests
import datetime
def get_data(URL):
res = requests.get(URL)
res.encoding = res.apparent_encoding
return res
def format_text(text):
text = re.sub(r"[a-zA-Z0-9]", "", text)
text = re.sub(r"[!-/:-@[-`{-~]", "", text)
text = text.replace(" ", "")
return text
def task1(res, l_b, URL):
text = format_text(res.text)
list = text.split()
result = difference(list, l_b, URL)
print(result)
return result, list
def difference(list1, list2, link):
m = "\n" + link
result = list(set(list1) - set(list2))
print("raw" + str(result))
if result != []:
for s in result:
m = m + "\n" + s
result = m
return result
def line(message, access_token):
try:
url = "https://notify-api.line.me/api/notify"
headers = {"Authorization": "Bearer " + access_token}
payload = {"message": message}
r = requests.post(url, headers=headers, params=payload,)
except Exception as e:
try:
url = "https://notify-api.line.me/api/notify"
headers = {"Authorization": "Bearer " + 自分のトークン}
payload = {"message": e}
r = requests.post(url, headers=headers, params=payload,)
except:
print(e, "\nerror occurred")
def sent(name, message, token1, token2):
if message != []:
line(message, token1)
line(message, token2)
else:
line(name + "==[]", token2)
def main():
l_b1 = []
l_b2 = []
URL1 = "取得したいHPのURL"
URL2 = "取得したいHPのURL"
class_line = "クラスLINEのトークン"
admin_line = "自分のトークン"
while True:
try:
res = get_data(URL1)
res2 = get_data(URL2)
print(datetime.datetime.now())
result, l1 = task1(res, l_b1, URL1)
result2, l2 = task1(res2, l_b2, URL2)
sent("result", result, class_line, admin_line)
sent("result2", result2, class_line, admin_line)
l_b1 = copy.deepcopy(l1)
l_b2 = copy.deepcopy(l2)
for i in range(6):
line("\n" + str(datetime.datetime.now()) + "\n" +
"正常に動作しています.多分..." + "\n" + str(i), admin_line)
time.sleep(300)
except Exception as e:
line("\n" + str(e) + "\nerror occurred", admin_line)
time.sleep(30)
if __name__ == "__main__":
main()

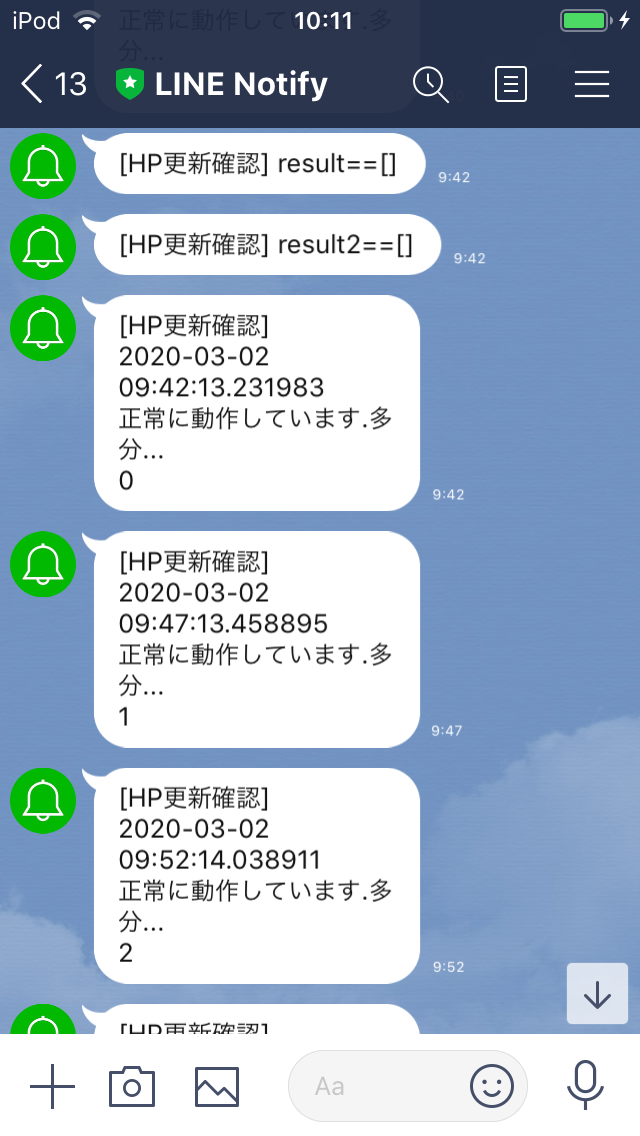 ~~学校のHPがまだ一度も更新されてないので正常に動いてるかはわからないのが辛いところ...~~
動作確認できました
~~学校のHPがまだ一度も更新されてないので正常に動いてるかはわからないのが辛いところ...~~
動作確認できました
終わりに
即席で開発したので処理は美しくはないと思いす.
もし間違いがあればご指摘ください.
英数,半角記号を削除しているため,日付などが表示されなくなってしまいます.
何か解決案がある方ぜひコメント欄へm(_ _)m