はじめに
本記事はSeleniumで私が個人的に使うためのスニペットのまとめです。
自分が使うためのスニペット集なので内容は偏っています。また一部Seleniumとは直接関係ないものも含まれています。
Seleniumの一通りの使い方を知りたい方は、以下のような素敵な記事がありますので、そちらをご参照ください。
環境
主に以下の環境向けの情報です。他の環境では一部動作しないものがあると思います。
・macOS Catalina
・Python 3.8.3
・selenium 3.141.0
・Google Chrome 91.0.4472.19
目次(スニペット+α)
タップで展開
- とりあえず動かす
- 終了時に閉じる
- WebDriverを自動更新する
- 要素の取得・操作
- 普通のスクリーンショット取得
- ページ全体のスクリーンショット(ヘッドレスモード)
- Headlessモードで起動
- JavaScript実行
- 要素をクリックする直前・直後に何か処理をする
- Basic認証を突破する
- Chrome DevTools Protocolコマンドの実行
- 【Chrome】ページ全体のスクリーンショットを撮る
- 【Headless Chrome】WebページをPDFに保存する
- 【Chrome】ページをMHTML形式で1つのファイルに保存する
- 【Chrome】「この接続ではプライバシーが保護されません」が表示されるページにアクセスする
- 【Chrome】カスタムヘッダの付与
- ネットワーク情報を取得する
- 最新のChromeDriverのバージョンが知りたい
- 【Docker】Ubuntu 20.04にSeleniumの環境を構築
- 【Docker】CentOS 7.9にSeleniumの環境を構築
- 【Google Colab】Seleniumを使うための準備
- 【Google Colab】ノートブック上に画像を表示する
- 【Google Colab】Googleドライブをマウントする
- 【Google Colab】Googleスプレッドシートの中身を読み取る
- LINEに通知を送る
- テスト用サイト
- 開発者ツールでXPathで要素を取得する
- ドキュメント等
とりあえず動かす
$ pip install selenium
$ pip install webdriver-manager
import time
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Webdriver ManagerでChromeDriverを取得
driver = webdriver.Chrome(ChromeDriverManager().install())
# Qiitaトップページにアクセス
driver.get('https://qiita.com/')
time.sleep(5)
driver.close()
driver.quit()
終了時に閉じる
Seleniumを触っていくうちに、いつの間にかWebDriverのプロセスが増殖しがちです。
それをできるだけ防ぐためにプログラム終了時にDriverを終了させておきます。
import atexit
# プログラム終了時に実行させる関数
def tear_down():
driver.close()
driver.quit()
# 終了ハンドラの設定
atexit.register(tear_down)
Seleniumのドキュメントのサンプルコードを見ると、with構文で書かれていたので、こちらの方がスマートかもしれません。
with webdriver.Chrome(ChromeDriverManager().install()) as driver:
# Qiitaトップページにアクセス
driver.get('https://qiita.com/')
time.sleep(5)
WebDriverを自動更新する
既に上で使っていますが、Webdriver Managerを使うと、自分でブラウザのバージョンに合ったdriverを取ってきたりする手間が省けます。
Webブラウザが更新されて、driverの対応バージョンと合わずエラーになるということも防げます。
$ pip install webdriver-manager
from webdriver_manager.chrome import ChromeDriverManager
# Webdriver ManagerでChromeDriverを取得
driver = webdriver.Chrome(ChromeDriverManager().install())
参考:Python+SeleniumWebDriverではwebdriver_managerを使うといちいちdriverのexeを置き換えなくて済む
要素の取得・操作
PythonのSelenium APIドキュメントやSelenium API(逆引き)、Python + Selenium で Chrome の自動操作を一通りを参照するのがわかりやすいです。
あえて書くこともないので、ここでは、テスト自動化練習サイトの会員登録ページで使ったコードを貼り付けておきます。
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.select import Select
# フォームに会員情報を登録する関数
def register_member(email, password, username, rank, address, tel, gender, birthday, notification):
# 性別用
gender_index = {"男性": "1", "女性": "2", "その他": "9"}
if gender in gender_index:
gender_value = gender_index[gender]
else:
gender_value = "0"
# 会員種別用
rank_value = 'normal' if rank == '一般会員' else 'premium'
# 各項目の入力
driver.find_element_by_name("email").send_keys(email)
driver.find_element_by_name("password").send_keys(password)
driver.find_element_by_name("password-confirmation").send_keys(password)
driver.find_element_by_name("username").send_keys(username)
driver.find_element_by_xpath('//input[@name="rank" and @value="' + rank_value + '"]').click()
driver.find_element_by_name("address").send_keys(address)
driver.find_element_by_name("tel").send_keys(tel)
# 性別の入力
select = Select(driver.find_element_by_id("gender"))
select.select_by_value(gender_value)
# 生年月日の入力
driver.find_element_by_name("birthday").clear()
driver.find_element_by_name("birthday").send_keys(birthday)
# お知らせを受け取る場合にチェックボックスにチェック
if notification == "受け取る":
driver.find_element_by_name("notification").click()
driver.find_element_by_xpath('//button[text()="登録"]').click();
# 登録完了ページのスクリーンショットを取得
driver.save_screenshot('complete.png')
driver.find_element_by_xpath('//button[text()="ログアウト"]').click();
# テスト用の会員登録フォームに移動
driver.get('https://hotel.testplanisphere.dev/ja/signup.html')
# 会員登録
register_member("murtwiry@example.com", "fpfuo2x9", "鈴木 陽葵",
"一般会員", "北海道札幌市中央区北3条西6丁目", "09022223333",
"女性", "11/22/1995", "受け取る")
スクリーンショットを撮る
Chrome DevTools Protocolコマンドを使ったChromeでのページ全体のスクリーンショット取得は、本記事内の【Chrome】ページ全体のスクリーンショットを撮るもご参照ください。
普通のスクリーンショット取得
普通にブラウザに表示されている範囲のスクリーンショットを取得する場合は、以下のコードでできます。
import os
driver.get('https://qiita.com/')
# スクリーンショットを取得し保存
filename = os.path.join(os.path.dirname(os.path.abspath(__file__)), "screenshot.png")
driver.save_screenshot(filename)
ページ全体のスクリーンショット(ヘッドレスモード)
JavaScriptでページ全体のサイズを取得し、ウィンドウをページ全体のサイズに設定してから、スクリーンショットを撮影します。
def save_full_screenshot(driver, img_path):
width = driver.execute_script("return document.body.scrollWidth;")
height = driver.execute_script("return document.body.scrollHeight;")
driver.set_window_size(width, height)
driver.save_screenshot(img_path)
save_full_screenshot(driver, filename)
Headlessモードで起動
ChromeでHeadlessモードを利用する場合は、--headlessのオプションを使います。
環境や対象ページによって、その他にオプションが必要になることがあります。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# Headless Chromeのためのオプション
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-gpu')
with webdriver.Chrome(options=options) as driver:
driver.get('https://qiita.com/')
driver.save_screenshot('headless.png')
Headlessモードでのオプションについては、以下の記事の「発展編 ブラウザを起動しないでスクレイピング」が参考になります。
JavaScript実行
driver.execute_scriptメソッドを使います。
# Qiitaトップページにアクセス
driver.get('https://qiita.com/')
# 投稿記事のタイトル一覧を取得して表示
titles = driver.execute_script('''
var nodeList = document.querySelectorAll('article > h2 > a');
titles = Array.from(nodeList).map(a => a.textContent);
return titles;
''')
for title in titles:
print(title)
参考:JavaScriptを書ける人であれば誰でもスクレイピングはできるよっていう話
要素をクリックする直前・直後に何か処理をする
要素のクリックイベントの前後に処理を行うことができます。
その他にもいくつかイベントの前後に処理を行うことができるものが存在します。詳しくは、abstract_event_listenerのAPIドキュメントをご参照ください。
from selenium.webdriver.support.events import EventFiringWebDriver, AbstractEventListener
# イベント補足クラスを定義
class CustomListener(AbstractEventListener):
# クリック前に要素までスクロール
def before_click(self, element, driver):
driver.execute_script('arguments[0].scrollIntoView({behavior: "smooth", block: "center"});', element)
# クリック後に3秒待つ
def after_click(self, element, driver):
time.sleep(3)
base_driver = webdriver.Chrome(ChromeDriverManager().install())
driver = EventFiringWebDriver(base_driver, CustomListener())
参考:【Python】before_click/after_click・・・要素がクリックされる直前/直後の処理を実施する
Basic認証を突破する
driver.get("http://username:password@example.com")
参考:SeleniumでBasic認証有のサイトにログインする
ユーザ名が例えば、mail@example.comのようなメールアドレスの場合は、@を%40に置き換えて、以下のようにします。
driver.get("http://mail%40example.com:password@example.com")
@や#等、URLの中で特別な意味を持つ文字は、パーセントエンコーディングしてあげる必要があります。
参考:Percent-encoding (パーセントエンコーディング) | MDN Web Docs
Chrome DevTools Protocol関連
Chrome系のブラウザに限定されるかもしれませんが、ブラウザの開発者ツールにあるような機能を実行できるChrome DevTools Protocolに関するスニペットです。
Chrome DevTools Protocolコマンドの実行
driver.execute_cdp_cmd("Chrome DevTools Protocolのコマンド", "コマンドのパラメータ")
【Chrome】ページ全体のスクリーンショットを撮る
詳細記事:【Chrome】Seleniumでページ全体のスクリーンショットを撮る
import base64
def take_full_screenshot(driver, file_path):
width = driver.execute_script("return document.body.scrollWidth;")
height = driver.execute_script("return document.body.scrollHeight;")
viewport = {
"x": 0,
"y": 0,
"width": width,
"height": height,
"scale": 1
}
# Chrome Devtools Protocolコマンドを実行し、取得できるBase64形式の画像データをデコードしてファイルに保存
image_base64 = driver.execute_cdp_cmd("Page.captureScreenshot", {"clip": viewport, "captureBeyondViewport": True})
image = base64.b64decode(image_base64["data"])
with open(file_path, 'bw') as f:
f.write(image)
driver.get('https://qiita.com/')
take_full_screenshot(driver, 'screenshot.png')
【Headless Chrome】WebページをPDFに保存する
詳細記事:SeleniumとHeadless ChromeでページをPDFに保存する
import base64
def save_to_pdf(driver, file_path):
parameters = {
"printBackground": True, # 背景画像を印刷
"paperWidth": 8.27, # A4用紙の横 210mmをインチで指定
"paperHeight": 11.69, # A4用紙の縦 297mmをインチで指定
}
# Chrome Devtools Protocolコマンドを実行し、取得できるBase64形式のPDFデータをデコードしてファイルに保存
pdf_base64 = driver.execute_cdp_cmd("Page.printToPDF", parameters)
pdf = base64.b64decode(pdf_base64["data"])
with open(file_path, 'bw') as f:
f.write(pdf)
driver.get('https://qiita.com/')
save_to_pdf(driver, 'qiita.pdf')
【Chrome】ページをMHTML形式で1つのファイルに保存する
WebページをMHTML形式(Webページを1つのファイルに保存するための形式)で保存することができます。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
import time
with webdriver.Chrome(ChromeDriverManager().install()) as driver:
driver.get('https://qiita.com/')
# ページをMHTML形式で保存
mhl = driver.execute_cdp_cmd("Page.captureSnapshot", {})
time.sleep(3)
with open('qiita.mhtml', 'w') as f:
f.write(mhl["data"])
- Page.captureSnapshotメソッドを利用
-
{"code":-32000,"message":"Failed to generate MHTML"}というエラーが発生することがありました。原因はわかりませんが、time.sleep(3)をとりあえず入れて回避しています。
【Chrome】「この接続ではプライバシーが保護されません」が表示されるページにアクセスする
driver.execute_cdp_cmd("Security.setIgnoreCertificateErrors", {"ignore": True})
driver.get('https://expired.badssl.com/')
- 諸般の事情により、SSL/TLS証明書の不備があるサイトにアクセスする必要がある時に
- Security.setIgnoreCertificateErrorsを利用
- EXPERIMENTALが付与されたメソッドのため、将来利用できなくなる可能性があります
【Chrome】カスタムヘッダの付与
custom_headers = {
"X-Custom-Header1": "value1",
"X-Custom-Header2": "value2",
}
driver.execute_cdp_cmd("Network.enable", {})
driver.execute_cdp_cmd("Network.setExtraHTTPHeaders", {"headers": custom_headers})
ネットワーク情報を取得する
パフォーマンス情報内に含まれるネットワーク情報を取得できます。
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
# ネットワークに関するログを取得するための設定
capabilities = DesiredCapabilities.CHROME
capabilities['goog:loggingPrefs'] = { 'performance': 'ALL' }
driver = webdriver.Chrome(
executable_path=ChromeDriverManager().install(),
desired_capabilities=capabilities
)
driver.get('https://qiita.com/')
# ネットワーク情報のログをファイルに書き出す
with open('network.log', 'w') as f:
for entry_json in driver.get_log('performance'):
print(entry_json, file=f)
参考:【Python】Selenium側からネットワーク情報を取得する
最新のChromeDriverのバージョンが知りたい
Linux等にChromeDriverをインストールする際のTipsです。
$ CHROMEDRIVER_VERSION=`curl -sS chromedriver.storage.googleapis.com/LATEST_RELEASE`
$ echo ${CHROMEDRIVER_VERSION}
Docker関連
Seleniumの公式のDockerイメージがあるため、そちらを利用するのが良いと思いますが、ChromeやSeleniumを入れたDockerfileを作成したい場合のために記載しておきます。
【Docker】Ubuntu 20.04にSeleniumの環境を構築
FROM ubuntu:20.04
# タイムゾーンを設定
RUN ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtime
# 必要なツールとIPAフォント、Pythonをインストール
RUN apt-get update && apt-get install -y wget gnupg curl vim unzip python3 python3-pip fonts-ipafont fonts-ipaexfont
# Google Chromeをインストール
RUN wget https://dl.google.com/linux/linux_signing_key.pub \
&& apt-key add linux_signing_key.pub \
&& echo 'deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main' | tee /etc/apt/sources.list.d/google-chrome.list \
&& apt-get update \
&& apt-get install -y google-chrome-stable \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# Chrome Driverをインストール
RUN CHROMEDRIVER_VERSION=`curl -sS chromedriver.storage.googleapis.com/LATEST_RELEASE` \
&& curl -sS -o /tmp/chromedriver_linux64.zip http://chromedriver.storage.googleapis.com/$CHROMEDRIVER_VERSION/chromedriver_linux64.zip \
&& unzip /tmp/chromedriver_linux64.zip \
&& mv chromedriver /usr/local/bin/
# Seleniumをインストール
RUN pip install selenium
RUN google-chrome --version
RUN python3 -V
- イメージ作成途中でタイムゾーンの選択を求められ、止まってしまったので、
ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtimeというタイムゾーン設定を加えました。
参考:【2019年版】Ubuntu18.04 にChromeとSeleniumをインストール
【Docker】CentOS 7.9にSeleniumの環境を構築
FROM centos:7.9.2009
# Chrome用のyumリポジトリを設定
RUN echo $'[google-chrome]\n\
name=google-chrome\n\
baseurl=http://dl.google.com/linux/chrome/rpm/stable/$basearch\n\
enabled=1\n\
gpgcheck=1\n\
gpgkey=https://dl-ssl.google.com/linux/linux_signing_key.pub' > /etc/yum.repos.d/google.chrome.repo
# Google Chrome、Python 3、IPAフォントなどをインストール
RUN yum -y update \
&& yum -y install google-chrome-stable unzip python3 ipa-gothic-fonts ipa-mincho-fonts ipa-pgothic-fonts ipa-pmincho-fonts \
&& rm -rf /var/cache/yum/* \
&& yum clean all
# Chrome Driverをインストール
RUN CHROMEDRIVER_VERSION=`curl -sS chromedriver.storage.googleapis.com/LATEST_RELEASE` \
&& curl -sS -o /tmp/chromedriver_linux64.zip http://chromedriver.storage.googleapis.com/$CHROMEDRIVER_VERSION/chromedriver_linux64.zip \
&& unzip /tmp/chromedriver_linux64.zip \
&& mv chromedriver /usr/local/bin/
# Seleniumをインストール
RUN pip3 install selenium
RUN google-chrome --version
RUN python3 --version
参考:CentOS7でSelenium+Pythonを動かすまで
Google Colaboratory関連
Google Colaboratory(Google Colab)を使うと、Webブラウザ上でSeleniumを使う環境を整えることができます。
また、Googleドライブにファイルを保存したり、Googleスプレッドシートと連携することもできます。
関連記事:【Selenium】Googleスプレッドシートを読み込んで会員登録フォームに入力する
【Google Colab】Seleniumを使うための準備
ChromeDriverと日本語フォントを導入して、WebDriverを使えるようにします。
# ChromeDriver、日本語フォントの導入
!apt-get update
!apt-get install -y chromium-chromedriver fonts-ipafont fonts-ipaexfont
!ln -s /usr/lib/chromium-browser/chromedriver /usr/bin/chromedriver
!pip install selenium
from selenium import webdriver
# WebDriverを準備
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--disable-gpu')
options.add_argument('--window-size=1280,1400')
driver = webdriver.Chrome(executable_path="/usr/bin/chromedriver", options=options)
参考:Googlecolab を使って iRuby で selenium と chromium で徘徊する為に
【Google Colab】ノートブック上に画像を表示する
ヘッドレスChromeを使うため動作が見えないので、スクリーンショットを撮って見ていきます。
この時に、以下のようにすることで、ノートブック上に画像を表示することができます。
# ノートブック上に画像を表示するために導入
from IPython.display import Image, display_png
# スクリーンショット取得
driver.get('https://qiita.com/')
driver.save_screenshot('qiita.png')
# ノートブック上に表示
display_png(Image('qiita.png'))
【Google Colab】Googleドライブをマウントする
Google ColabからGoogleドライブを使うことができます。
実行すると、Googleドライブ利用の許可を求められるので、指示に従ってコードを入力します。
from google.colab import drive
# Googleドライブをマウント
drive.mount('/content/drive')
# スクリーンショットをGoogleドライブの「Colab」という事前に作成したフォルダに保存
driver.save_screenshot('/content/drive/MyDrive/Colab/screenshot.png')
【Google Colab】Googleスプレッドシートの中身を読み取る
Googleスプレッドシートにアクセスすることもできます。
from google.colab import auth
from oauth2client.client import GoogleCredentials
import gspread
# 認証処理
auth.authenticate_user()
gc = gspread.authorize(GoogleCredentials.get_application_default())
# 「url_list」という名前のスプレッドシートの先頭ワークシートをオープンして、値を読み込み
worksheet = gc.open('url_list').get_worksheet(0)
url_list = worksheet.get_all_values()
# 中身を表示
for url in url_list:
print(url)
LINEに通知を送る
直接、Seleniumと関係ありませんが、Seleniumを使ったWebサイトの死活監視等の際の通知用に。
詳細記事:SeleniumでWeb監視をしてLINEに通知する
import os
import requests
# LINE Notifyのアクセストークン
ACCESS_TOKEN = "YOUR ACCESS TOKEN"
LINE_API = "https://notify-api.line.me/api/notify"
# 結果をLINEへ送信
def notify_to_line(message, image_file_path=None):
headers = {'Authorization': 'Bearer ' + ACCESS_TOKEN}
payload = {'message': message}
files = {}
if ((image_file_path is not None) and os.path.exists(image_file_path)):
files = {'imageFile': open(image_file_path, 'rb')}
response = requests.post(LINE_API, headers=headers, params=payload, files=files)
# テキストのみ送信
notify_to_line('テストメッセージ')
# テキスト + 画像を送信
notify_to_line('スクリーンショット付きメッセージ', 'qiita.png')
その他
スニペットとは違いますが、関連する情報です。
テスト用サイト
Seleniumの検証でお世話になっているサイトです。
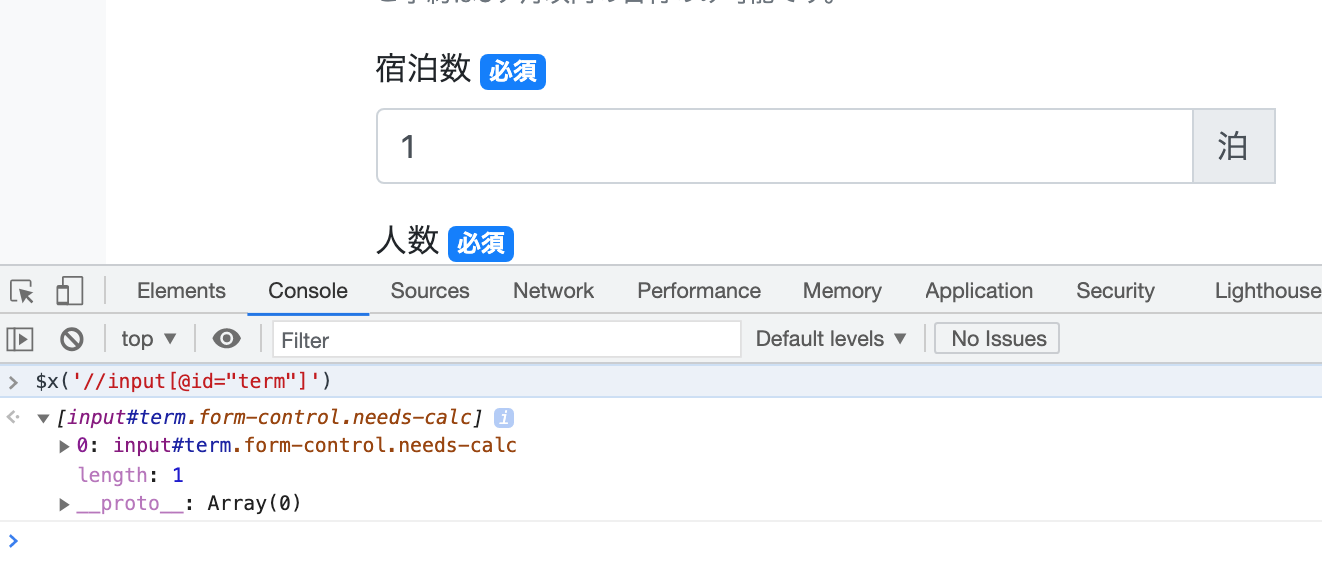
開発者ツールでXPathで要素を取得する
Chromeの開発者ツールで、XPathに対応する要素を取得することができます。
$x('//input[@id="term"]')等を開発者ツールのコンソールに入力します。
確認してみると、XPathで一つに特定できていると思っていたのが、実は該当する要素が2つ以上あったというのは、良くあることです。
ドキュメント等
- https://pypi.org/project/selenium/
- https://www.selenium.dev/documentation/en/
- selenium package API
- Selenium API(逆引き)
おわりに
Seleniumから脱線している箇所も多々ありますが、自分のためのスニペット集をまとめました。もし気が向いたら更新をしたいと思います。