この記事に書かれていること
- Seleniumの
execute_scriptが最高だよという熱い思い。 - PythonやSeleniumが不慣れでも
execute_script+JavaScriptで大体いけるのではという提案。
この記事の対象
- Webスクレイピングに興味がある人
- JavaScriptが書ける人
- Pythonはよくわからないけど環境構築までなら頑張れそうかなという人
- 私の同僚
※ 普段からWebスクレイピングをされていたり、すでにPythonをバリバリ使ってる人にはあまり収穫はないと思います。
本題に入る前にスクレイピングについておさらい
WebスクレイピングとはWebサイトから情報を抽出する技術のことです。
テキストや画像を取得したり、ブラウザを操作してファイルをダウンロードするなど実装次第でいろんなことができます。
スクレイピング自体は様々な言語で可能ですが、私はPythonを使っています。
基礎文法がシンプルで学びやすく、スクレイピングに関するライブラリが豊富だからです。
環境構築は選択肢が多くややこしいですが私はAnacondaで入れています。
・pythonの環境構築戦争にイラストで終止符をどうやら打てない
・Anaconda で Python 環境をインストールする
そしてスクレイピングする上でWebサイトについて理解しなければいけないことがあります。
Webサイトはざっくり「静的ページ」と「動的ページ」で分けることができます。
静的ページと動的ページ
静的ページ
静的ページはいつどこでアクセスしても毎回同じものが表示されるページのことです。
もっと言うと取得したい情報がHTMLでベタ書きされているページです。
<!DOCTYPE html>
<html lang="ja" dir="ltr">
<head>
<meta charset="utf-8">
<title>静的ページ</title>
</head>
<body>
<h1>静的ページとは</h1>
<p>このように取得したい情報がベタ書きされているページです。</p>
</body>
</html>
動的ページ
動的ページとはアクセスしたときの状況に応じて異なる内容が表示されるWebページのことです。
もっと言うとアクセスしないと何が表示されるかわからないページです。
<!DOCTYPE html>
<html lang="ja" dir="ltr">
<head>
<meta charset="utf-8">
<title>動的ページ</title>
</head>
<body>
<h1>動的ページとは</h1>
</body>
<script>
window.onload = () => {
let ele = document.createElement('p');
ele.textContent = 'このページが開かれたタイミングで生成されます。';
let body = document.querySelector('body');
body.appendChild(ele);
}
</script>
</html>
静的/動的 それぞれの一般的なスクレイピング方法
静的ページのスクレイピング
静的ページをスクレイピングする場合は一般的にBeautiful Soupが利用されます。
HTMLをまるごと解析するので、ベタ書きされている情報は大体取得できます。
逆に動的ページはスクレイピングできません。
例えば上で例に出した動的ページの場合、HTMLでベタ書きされている<h1>は取得できますが、
<p>は取得できません。HTMLに無いからです。
動的ページのスクレイピング
動的ページをスクレイピングする場合は一般的にSeleniumが利用されます。
自動でブラウザを起動し、実際にそのページにアクセスして必要な情報を取得します。
要するに**「アクセスしないと取得できないならアクセスすればいいじゃない」**という発想です。
ちなみにSeleniumは静的ページも当然にスクレイピングできますが、
実際にブラウザを開いたりするのでBeautiful Soupよりも時間がかかります。
ただ本題につながってくる話なのでもう一度言いますが、
Seleniumは静的/動的関係なくどちらでも使えます。
本題 : なぜ 「JavaScript でいけるじゃん」 と思ったのか
それを語るにはまずSeleniumの基本的な書き方について説明する必要があります。
例としてYahoo ニュースのサイトをSeleniumを使って開いてみます。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://news.yahoo.co.jp/')
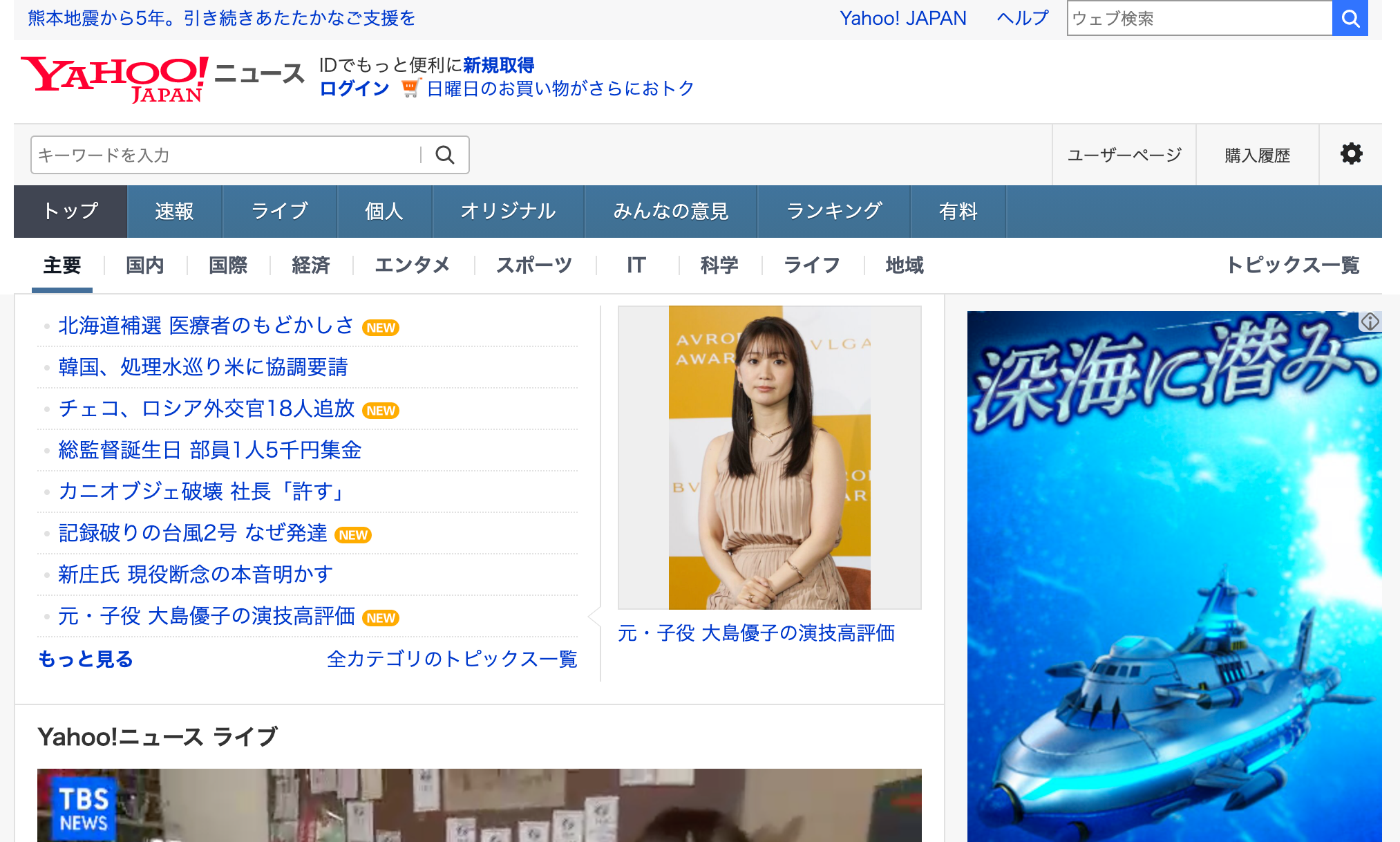
たった4行でYahooニュースを開けました。
開くサイトを変えたい場合はdriver.getの引数を変えるだけです。
次に見出しのテキストを取得してみたいと思います。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://news.yahoo.co.jp/')
headlines = driver.find_elements_by_css_selector('#uamods-topics > div > div > div > ul a')
for headline in headlines:
print(headline.text)
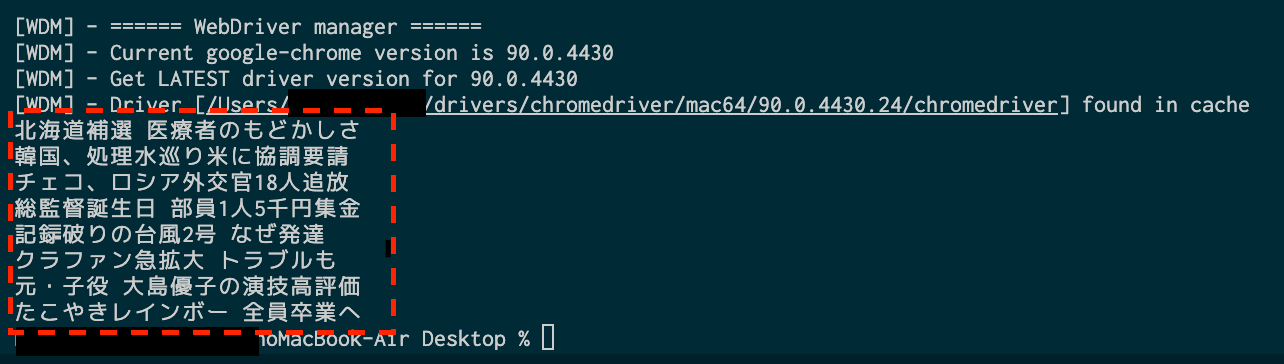
取得できました。
まずdriver.find_elements_by_css_selectorで取得したいCSSセレクタを指定しています。
普段JavaScriptを書いている人であれば親しみやすいメソッドだと思います。
for headline in headlines:がPythonのfor文です。
for [仮引数] in [引数]:という書き方をします。
printはJavaScriptでいうconsole.logみたいなものです。
まとめると
driver.find_elements_by_css_selectorで取得した要素の一覧をforで回して
printでテキストをコンソール画面に表示させる。という流れです。
今回は driver.find_elements_by_css_selector を利用しましたが、
他にもSeleniumには便利なメソッドが豊富に用意されています。
ただ、ここまで読んで思った人もいるかもしれません。
「なんだよ!JavaScriptを書ければ良いって言っといて、結局Pythonの話じゃないか!」
大丈夫です。ここからです。
万能メソッド : execute_script
execute_script とは
してほしい処理をJavaScriptで自由に書けるメソッドです。
例えば先ほどの処理をexecute_scriptで置き換えて書いてみます。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://news.yahoo.co.jp/')
driver.execute_script('''
let headlines = document.querySelectorAll('#uamods-topics > div > div > div > ul a');
headlines.forEach(headline => {
console.log(headline.textContent)
});
''')
どうでしょう 書いているのは思いっきりJavaScriptです!
pythonファイルにJavaScriptを書いています!
エディタからは文字列として認識されるのでシンタックスハイライトが効かないのですが、
書いているのは間違いなくJavaScriptです。
では実行してみます。
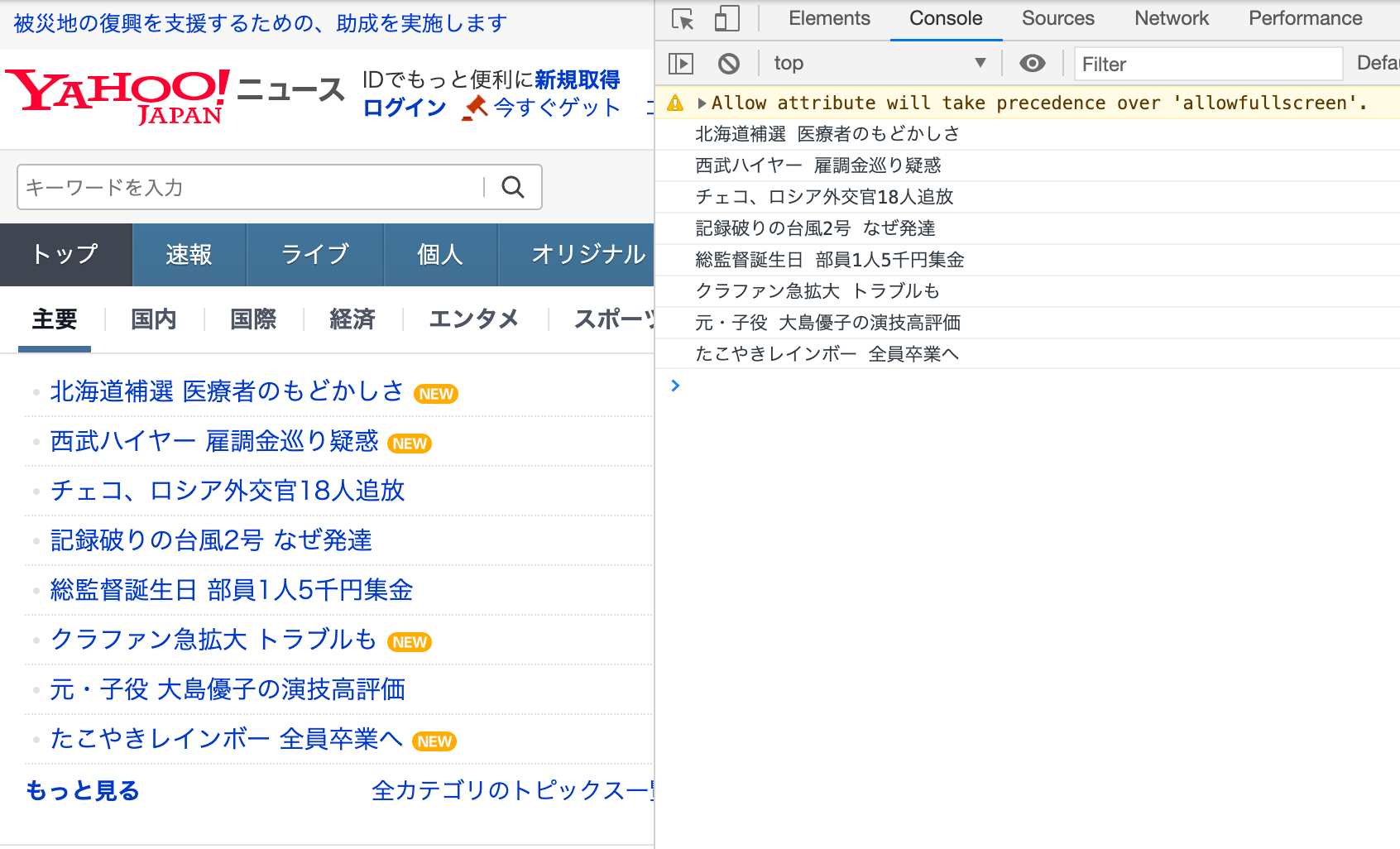
デベロッパーツールでConsoleを開いてみると、ちゃんと見出しの一覧が表示されています!
JavaScriptのコードが実行されました!
return で値を渡す - 配列
上の例ではconsole.logでそのまま表示させましたが
returnでPython側に値を渡すこともできます。
ということで次はreturnでPythonに値を渡した後にPythonでprintしてみます。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://news.yahoo.co.jp/')
headlines = driver.execute_script('''
let headlines = [...document.querySelectorAll('#uamods-topics > div > div > div > ul a')].map(a => a.textContent);
return headlines;
''')
for headline in headlines:
print(headline)
プリントできました!
このようにJavaScriptで作成した配列は、Pythonでも同じく配列として扱えます。
return で値を渡す - オブジェクト(連想配列)
配列だけでなくJavaScriptで作成したオブジェクト(連想配列)もreturnでPythonに渡せます。
※ ちなみにPythonでは連想配列を "辞書型" と呼びます。
ではJavaScriptを使ってYahooニューストップのナビバーから
テキストとリンク先を取得し、それをオブジェクトにまとめてreturnしてみたいと思います。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://news.yahoo.co.jp/')
# JavaScriptでナビバーのaタグからhrefとtextContentを取得しオブジェクトにしてreturn
categories = driver.execute_script('''
let categories = {};
let elements = document.querySelectorAll('#snavi > ul.sc-uJMKN.gXWNbF.yjnHeader_sub_cat a');
elements.forEach(ele => {
categories[ele.textContent] = ele.href;
});
return categories;
''')
# 辞書型のfor文。.items()を付けることで仮引数にkey,valueを分けて持てる。
for text, link in categories.items():
print(text, link)
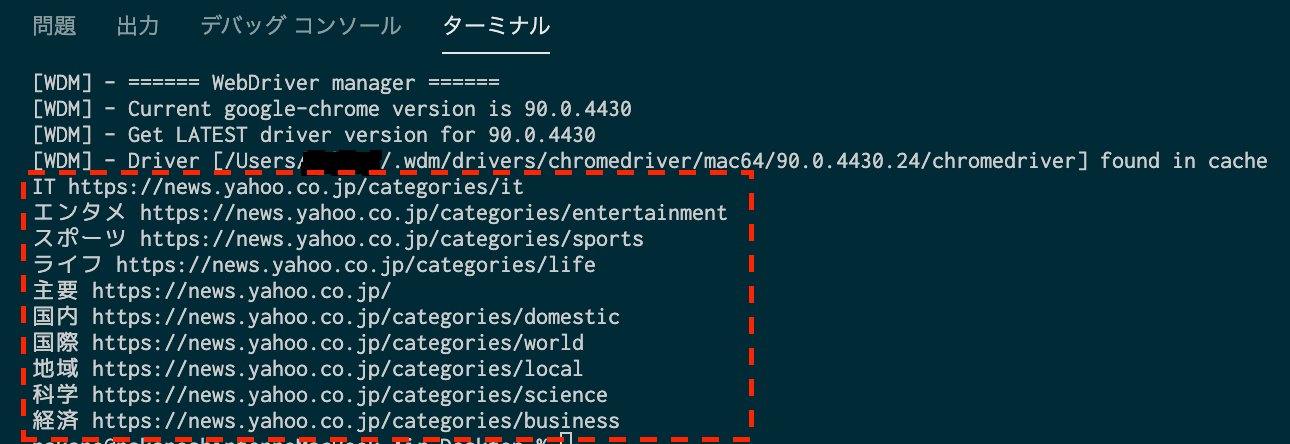
JavaScriptで作成したオブジェクトをPythonでプリントできました。
せっかくなのでそれぞれのリンク先からニュースの見出しを取得してみたいと思います。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://news.yahoo.co.jp/')
categories = driver.execute_script('''
let categories = {};
let elements = document.querySelectorAll('#snavi > ul.sc-uJMKN.gXWNbF.yjnHeader_sub_cat a');
elements.forEach(ele => {
categories[ele.textContent] = ele.href;
});
return categories;
''')
for text, link in categories.items():
# それぞれのリンク先を順番に開く
driver.get(link)
headlines = driver.execute_script('''
let headlines = [...document.querySelectorAll('#uamods-topics > div > div > div > ul a')].map(a => a.textContent);
return headlines;
''')
for headline in headlines:
print(text, headline)
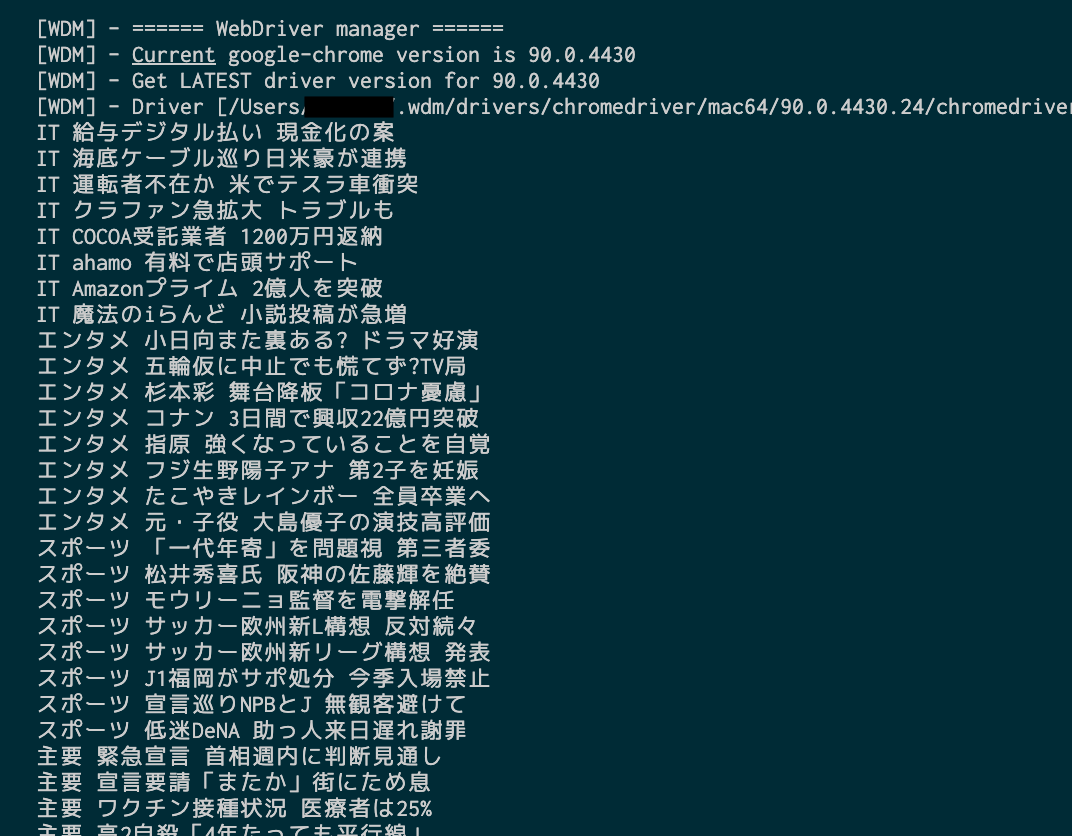
それぞれのリンク先からニュースの見出しを取得できました。
せっかくなので csv に書き出す
Python側でcsvに書き出す用の関数を用意して、あとはprintと入れ替えるだけです。
(ここもJavaScriptで書くのもアリかもと一瞬よぎりましたが逆にしんどくなりそうでやめました笑)
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
import csv
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://news.yahoo.co.jp/')
categories = driver.execute_script('''
let categories = {};
let elements = document.querySelectorAll('#snavi > ul.sc-uJMKN.gXWNbF.yjnHeader_sub_cat a');
elements.forEach(ele => {
categories[ele.textContent] = ele.href;
});
return categories;
''')
# csv に書き出す用の関数
def export_to_csv(category, headline):
with open('scraping.csv', 'a', encoding='utf-8_sig', newline='') as f:
writer = csv.writer(f)
writer.writerow([category, headline])
for text, link in categories.items():
driver.get(link)
headlines = driver.execute_script('''
let headlines = [...document.querySelectorAll('#uamods-topics > div > div > div > ul a')].map(a => a.textContent);
return headlines;
''')
for headline in headlines:
export_to_csv(text, headline)
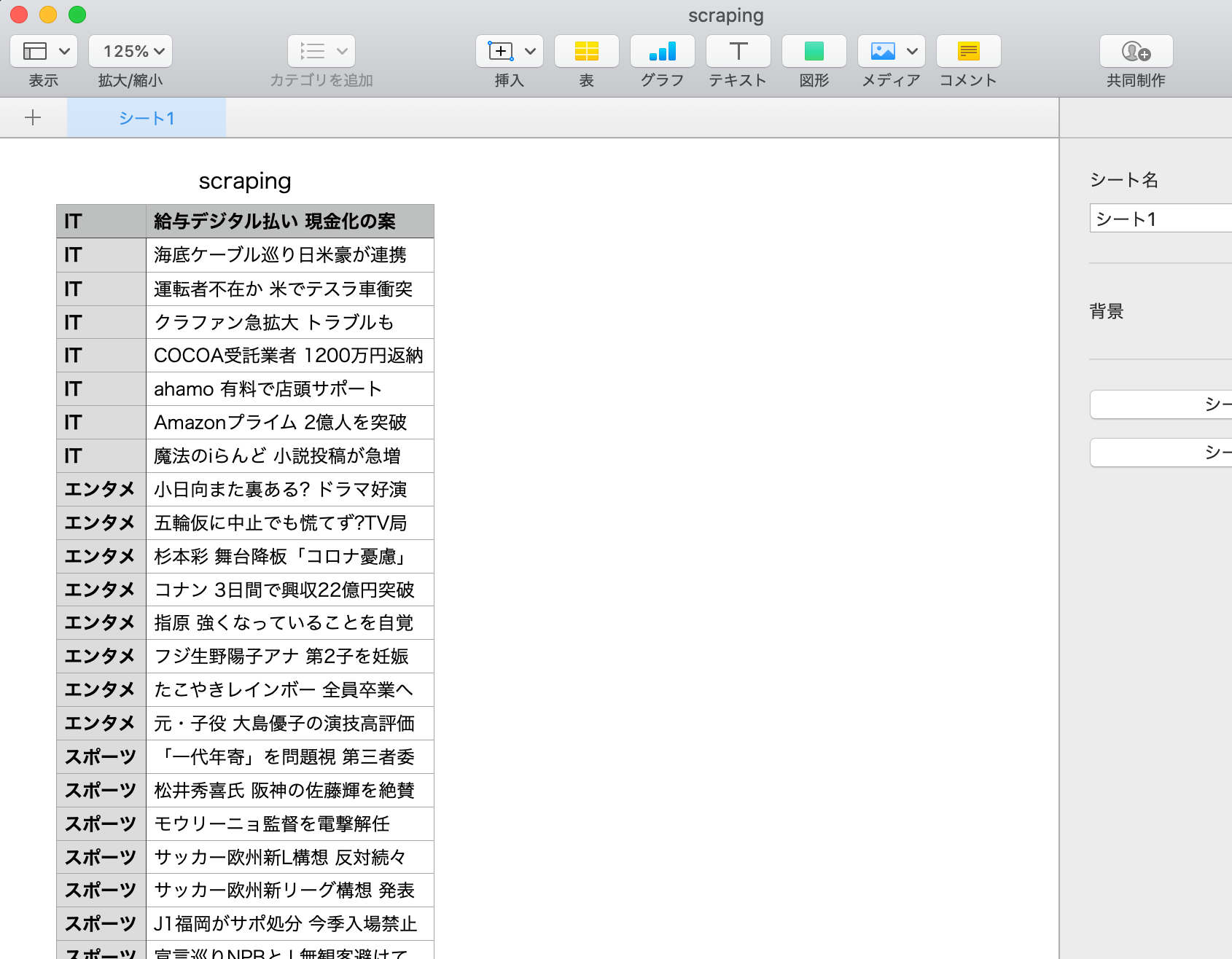
csvに書き出せました。
json に書き出す
取得したデータを最終的にどのような形に加工するかって様々あると思いますが、
必要なデータが決まっていて、かつjsonにさえ書き出せれば後からどうにでもなると思っています。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
import json
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://news.yahoo.co.jp/')
categories = driver.execute_script('''
let categories = {};
let elements = document.querySelectorAll('#snavi > ul.sc-uJMKN.gXWNbF.yjnHeader_sub_cat a');
elements.forEach(ele => {
categories[ele.textContent] = ele.href;
});
return categories;
''')
obj_list = []
for text, link in categories.items():
driver.get(link)
headlines = driver.execute_script('''
let headlines = [...document.querySelectorAll('#uamods-topics > div > div > div > ul a')].map(a => a.textContent);
return headlines;
''')
# 一つ一つ連想配列を作ってobj_listに追加
obj_list.append({text: headlines})
# obj_listをjsonに変換
with open('scraping.json', 'a', encoding='utf-8') as f:
json.dump(obj_list, f, ensure_ascii=False)
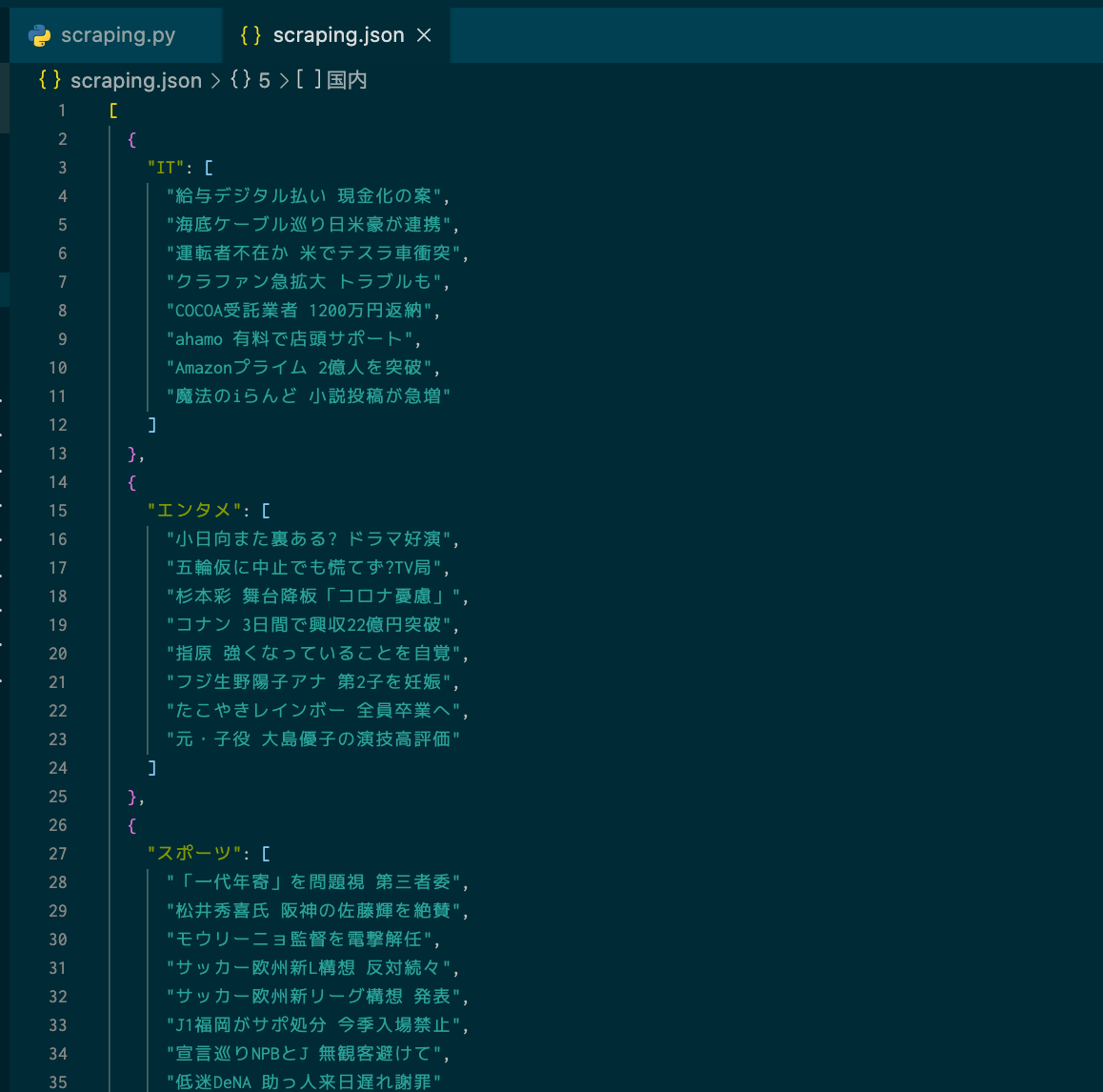
jsonに書き出せました。
要件が複雑であればあるほど威力を発揮する execute_script
seleniumには豊富なメソッドが用意されていることは先に記した通りですが、
逆に言うと用意されたメソッドでやりくりする必要があるということです。
実際、ちょっと複雑な条件分岐を求められただけで途端に難易度があがります。
例えばこのような条件があるとします。
Aの値がTrueの場合、Aの兄弟要素であるBを評価し、Trueであればその兄弟要素であるCを返す
用意されたメソッドでやれないことはないですが、ちょっとめんどくさいです。
なにより「うーん、どうやって取ろうかなー」と考える時間がもったいなく感じてしまいます。
ただ普段からJavaScriptを書いている人であれば深く考えずともイメージがつくはずです。
条件分岐は execute_script 内で完結させる
例としてプロ野球のサイトを用意しました。
過去10年で3割30本100打点を達成した選手を取得してみたいと思います。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
results_list = []
for year in range(2010, 2021):
driver.get('https://npb.jp/bis/{}/stats/bat_c.html'.format(year))
this_year_results = driver.execute_script('''
// バッターの打率の一覧を取得
let batters = document.querySelectorAll('tr.ststats > td:nth-child(4)');
let resultsList = [];
batters.forEach((battar) => {
// 打率が3割以上か判定
if (Number(battar.textContent) < 0.3) {
return;
}
// 本塁打が30本以上か判定
if (Number(battar.parentNode.childNodes[11].textContent) < 30) {
return;
}
// 打点が100以上か判定
if (Number(battar.parentNode.childNodes[13].textContent) < 100) {
return;
}
let year = location.pathname.replace(/[^0-9]/g, '');
let name = battar.parentNode.childNodes[1].textContent.replace(/ /g,' ');;
let ba = Number(battar.textContent).toFixed(3);
let hr = Number(battar.parentNode.childNodes[11].textContent);
let rbi = Number(battar.parentNode.childNodes[13].textContent);
let results = [year, name, ba, hr, rbi];
resultsList.push(results);
});
return resultsList;
''')
results_list.extend(this_year_results)
for results in results_list:
print(results)
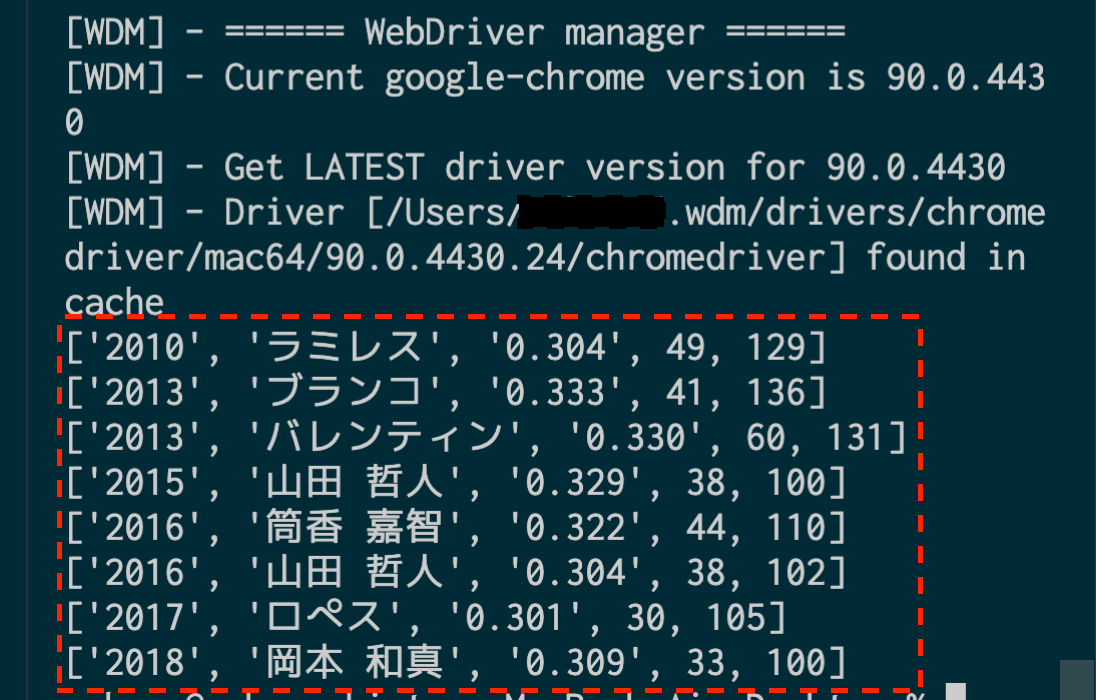
取得できました。
このように execute_script を使うことによって、条件分岐が必要な場合でも
難しいことを考えずにJavaScriptで事足りるのです。
スクレイピングだけでなく自動化ツールも作れる
JavaScriptが書けるということは
click()でクリックをしたり
.checked = trueでチェックボックスにチェックを入れたり
.value = 'hoge'で値を入れたりなど、
自由にDOM操作ができるということであり、
つまりそれは複数のページを横断的に決まった処理を走らせる自動化ツールを作成できるということです。
もちろんこれはPython+Seleniumだけで実現できるのですが、
上で例に出したような条件分岐が入る場合はJavaScriptのほうが簡単に書けると思います。
(私自身JavaScriptのほうが慣れてるだけっていう可能性も否めないですが汗)
まとめ
「Webスクレイピングをしてみたいな」という人で、すでにJavaScriptを書ける場合、
execute_script + JavaScript で大体いけるのではというお話でした。
冷静に考えればブラウザを操作するわけですから、JavaScriptが一番やりやすいに決まってるわけです。
別途Pythonの環境構築やライブラリのインストール方法、ちょっとしたfor文などの使い方などを覚える必要はありますが、すでにJavaScriptを書けている人であればそこまで難しいものではないと思います。
ちょっとWebスクレイピングに興味あるなと考えている方の参考になれば幸いです。
補足:
■ 記事紹介: この記事では触れていませんが読んでおいた方が良い内容です。
・Webスクレイピングの注意事項一覧
・Seleniumで待機処理するお話
・Selenium WebDriverderでプロセス終了させメモリ枯渇を防ぐ方法
■ 内容について
今回のJavaScriptでいいじゃんっていうお話はあくまでスクレイピングに限った話であり、
例えばデータフレームを取得してグラフ化して分析どうこうなどの話に発展する場合は別途Pythonの勉強が必要です。