やりたいこと
こんなテーブルをスクレイピングして
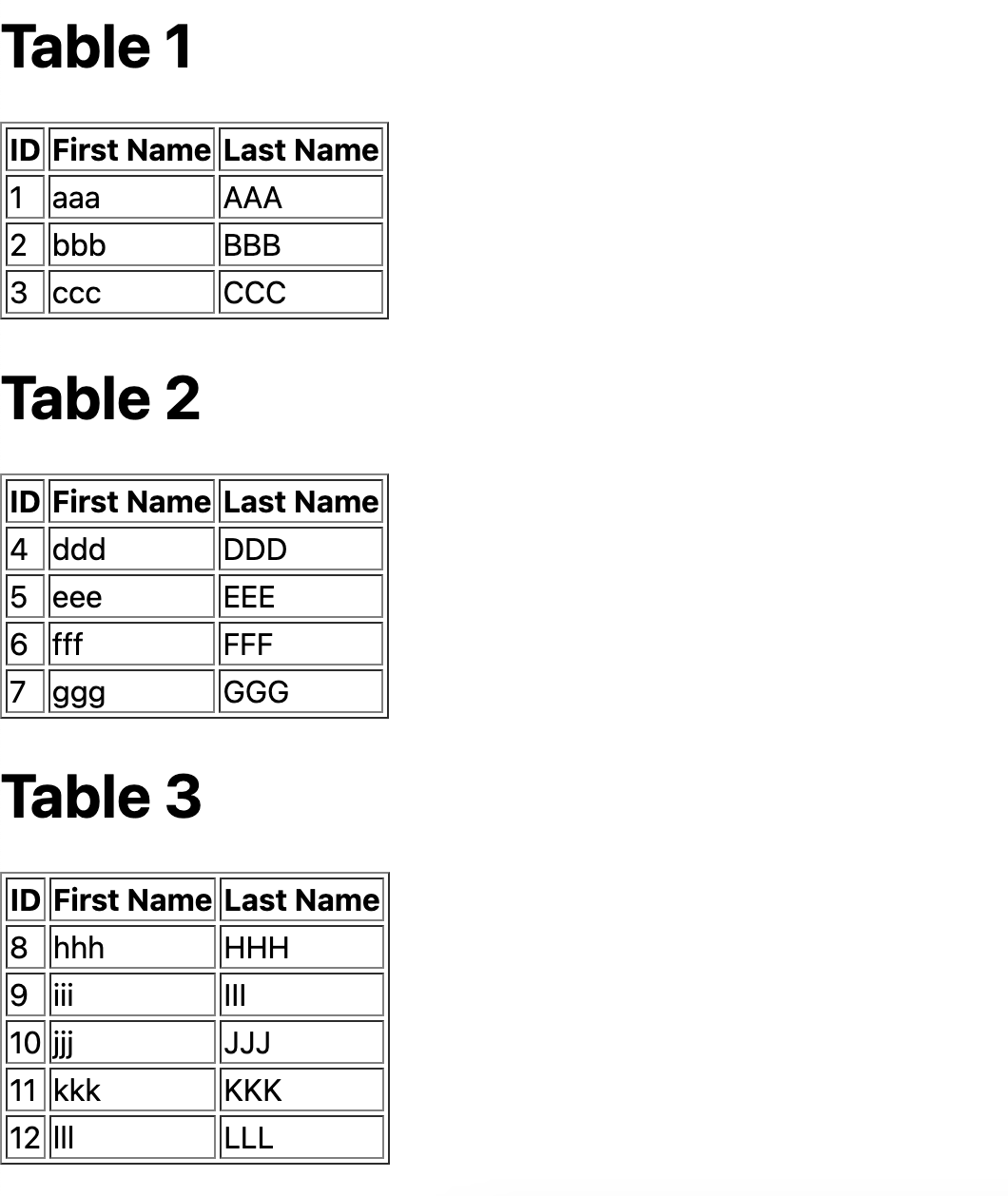
Excelでこんな感じで開きたい。
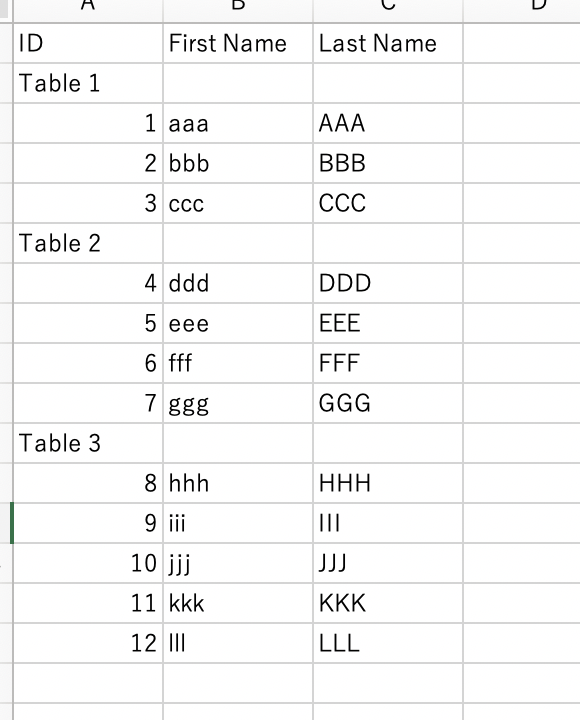
テーブルはNext.jsで作り、ローカル(http://localhost:3000)で動かしている。
index.tsx
import type { NextPage } from 'next'
const Home: NextPage = () => {
const table1 = [{ id: "1", fn: "aaa", ln: "AAA" }, { id: "2", fn: "bbb", ln: "BBB" }, { id: "3", fn: "ccc", ln: "CCC" },]
const table2 = [{ id: "4", fn: "ddd", ln: "DDD" }, { id: "5", fn: "eee", ln: "EEE" }, { id: "6", fn: "fff", ln: "FFF" }, { id: "7", fn: "ggg", ln: "GGG" },]
const table3 = [{ id: "8", fn: "hhh", ln: "HHH" }, { id: "9", fn: "iii", ln: "III" }, { id: "10", fn: "jjj", ln: "JJJ" }, { id: "11", fn: "kkk", ln: "KKK" }, { id: "12", fn: "lll", ln: "LLL" },]
return (
<div>
<h1>Table 1</h1>
<table id="table1" border={1}>
<thead><tr><th>ID</th><th>First Name</th><th>Last Name</th></tr></thead>
<tbody>
{table1.map(data => (
<tr key={data.id}><td>{data.id}</td><td>{data.fn}</td><td>{data.ln}</td></tr>
))}
</tbody>
</table>
<h1>Table 2</h1>
<table id="table2" border={1}>
<thead><tr><th>ID</th><th>First Name</th><th>Last Name</th></tr></thead>
<tbody>
{table2.map(data => (
<tr key={data.id}><td>{data.id}</td><td>{data.fn}</td><td>{data.ln}</td></tr>
))}
</tbody>
</table>
<h1>Table 3</h1>
<table id="table3" border={1}>
<thead><tr><th>ID</th><th>First Name</th><th>Last Name</th></tr></thead>
<tbody>
{table3.map(data => (
<tr key={data.id}><td>{data.id}</td><td>{data.fn}</td><td>{data.ln}</td></tr>
))}
</tbody>
</table>
</div>
)
}
export default Home
スクレイピングのライブラリはgoqueryとcollyがツートップらしい。
現時点(2023/1/3)でのGitHubのスター数は
goquery:12.1k
colly:18.6k
とのことなので、collyを使うことにした。
Goのスクレイピングライブラリ goquery と colly を試してみる
スクレイピング
まずはgo mod initとgo get collyを実施。
go mod init main
go get github.com/gocolly/colly/v2
テーブル名取得
main.goを作成して、テーブル名を取得してみる。
main.go
package main
import (
"fmt"
"github.com/gocolly/colly/v2"
)
func main() {
c := colly.NewCollector() // collyインスタンス作成
url := "http://localhost:3000" // スクレイピング対象
// テーブル名格納用
var tn [][]string
// テーブル名の取得
c.OnHTML("h1", func(e *colly.HTMLElement) { // 取得したい要素のタグを指定
v := []string{e.Text, "", ""}
tn = append(tn, v)
fmt.Println("tn", tn)
})
// リクエスト時にメッセージを出力
c.OnRequest(func(r *colly.Request) {
fmt.Println("Start Scraping. URL:", r.URL.String())
})
// スクレイピング開始
c.Visit(url)
}
go run .を実行。
実行結果
Start Scraping. URL: http://localhost:3000
tn [[Table 1 ]]
tn [[Table 1 ] [Table 2 ]]
tn [[Table 1 ] [Table 2 ] [Table 3 ]]
テーブル名が1つずつ取得される。
テーブルデータの取得
次にテーブルデータを取得する。
要素のidを指定する場合、#id名とする
例
"table#table1 > tbody" → idがtable1のtable要素配下のtbodyを取得
これをForEachで回して取得する。
td:nth-child(1) → tbody配下の1番目の要素を取得
table名ごとにswitch文でできるかと思ったが、うまくできなかった。
恐らくもっと綺麗に書く方法がある。
main.go
package main
import (
"fmt"
"github.com/gocolly/colly/v2"
)
func main() {
c := colly.NewCollector() // collyインスタンス作成
url := "http://localhost:3000" // スクレイピング対象
// テーブル名格納用
var tn [][]string
+ d := [][]string{{"ID", "First Name", "Last Name"}} // テーブルヘッドを予め確保
// テーブル名の取得
c.OnHTML("h1", func(e *colly.HTMLElement) { // 取得したい要素のタグを指定
v := []string{e.Text, "", ""}
tn = append(tn, v)
fmt.Println("tn", tn)
})
// データの取得 - テーブル1
+ c.OnHTML("table#table1 > tbody", func(h *colly.HTMLElement) {
+ d = append(d, tn[0])
+ h.ForEach("tr", func(_ int, el *colly.HTMLElement) {
+ var s []string
+ s = append(s, el.ChildText("td:nth-child(1)"), el.ChildText("td:nth-child(2)"), el.ChildText("td:nth-child(3)"))
+ d = append(d, s)
+ })
+ })
// データの取得 - テーブル2
+ c.OnHTML("table#table2 > tbody", func(h *colly.HTMLElement) {
+ d = append(d, tn[1])
+ h.ForEach("tr", func(_ int, el *colly.HTMLElement) {
+ var s []string
+ s = append(s, el.ChildText("td:nth-child(1)"), el.ChildText("td:nth-child(2)"), el.ChildText("td:nth-child(3)"))
+ d = append(d, s)
+ })
+ })
// データの取得 - テーブル3
+ c.OnHTML("table#table3 > tbody", func(h *colly.HTMLElement) {
+ d = append(d, tn[2])
+ h.ForEach("tr", func(_ int, el *colly.HTMLElement) {
+ var s []string
+ s = append(s, el.ChildText("td:nth-child(1)"), el.ChildText("td:nth-child(2)"), el.ChildText("td:nth-child(3)"))
+ d = append(d, s)
+ })
+ })
// リクエスト時にメッセージを出力
c.OnRequest(func(r *colly.Request) {
fmt.Println("Start Scraping. URL:", r.URL.String())
})
// スクレイピング開始
c.Visit(url)
+ fmt.Println("d", d)
}
go run .を実行
実行結果
Start Scraping. URL: http://localhost:3000
tn [[Table 1 ]]
tn [[Table 1 ] [Table 2 ]]
tn [[Table 1 ] [Table 2 ] [Table 3 ]]
d [[ID First Name Last Name] [Table 1 ] [1 aaa AAA] [2 bbb BBB] [3 ccc CCC] [Table 2 ] [4 ddd DDD] [5 eee EEE] [6 fff FFF] [7 ggg GGG] [Table 3 ] [8 hhh HHH] [9 iii III] [10 jjj JJJ] [11 kkk KKK] [12 lll LLL]]
これでデータの取得は完了。
CSV出力
csv出力用関数
csvExporter.go
package main
import (
"encoding/csv"
"log"
"os"
)
func csvExport(s [][]string) { // スクレイピング結果を格納したスライスを受け取る
f, err := os.OpenFile("scrape.csv", os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644)
if err != nil {
log.Fatal(err)
}
defer f.Close()
w := csv.NewWriter(f) // Writerを取得
defer w.Flush() // 最後にバッファのデータを書き込む。
for _, record := range s { // スライスを順番に取り出す。
if err := w.Write(record); err != nil {
log.Fatal(err)
}
}
if err := w.Error(); err != nil {
log.Fatal(err)
}
}
取得したcsvExport関数をmain関数内で呼び出す。
main.go
package main
import (
"fmt"
"github.com/gocolly/colly/v2"
)
func main() {
c := colly.NewCollector() // collyインスタンス作成
url := "http://localhost:3000" // スクレイピング対象
// テーブル名格納用
var tn [][]string
d := [][]string{{"ID", "First Name", "Last Name"}} // テーブルヘッドを予め確保
// テーブル名の取得
c.OnHTML("h1", func(e *colly.HTMLElement) { // 取得したい要素のタグを指定
v := []string{e.Text, "", ""}
tn = append(tn, v)
fmt.Println("tn", tn)
})
// データの取得 - テーブル1
c.OnHTML("table#table1 > tbody", func(h *colly.HTMLElement) {
d = append(d, tn[0])
h.ForEach("tr", func(_ int, el *colly.HTMLElement) {
var s []string
s = append(s, el.ChildText("td:nth-child(1)"), el.ChildText("td:nth-child(2)"), el.ChildText("td:nth-child(3)"))
d = append(d, s)
})
})
// データの取得 - テーブル2
c.OnHTML("table#table2 > tbody", func(h *colly.HTMLElement) {
d = append(d, tn[1])
h.ForEach("tr", func(_ int, el *colly.HTMLElement) {
var s []string
s = append(s, el.ChildText("td:nth-child(1)"), el.ChildText("td:nth-child(2)"), el.ChildText("td:nth-child(3)"))
d = append(d, s)
})
})
// データの取得 - テーブル3
c.OnHTML("table#table3 > tbody", func(h *colly.HTMLElement) {
d = append(d, tn[2])
h.ForEach("tr", func(_ int, el *colly.HTMLElement) {
var s []string
s = append(s, el.ChildText("td:nth-child(1)"), el.ChildText("td:nth-child(2)"), el.ChildText("td:nth-child(3)"))
d = append(d, s)
})
})
// リクエスト時にメッセージを出力
c.OnRequest(func(r *colly.Request) {
fmt.Println("Start Scraping. URL:", r.URL.String())
})
// スクレイピング開始
c.Visit(url)
fmt.Println("d", d)
// CSVに書き出す。
+ csvExport(d)
}
go run .を実行。
csvファイルが作成される。
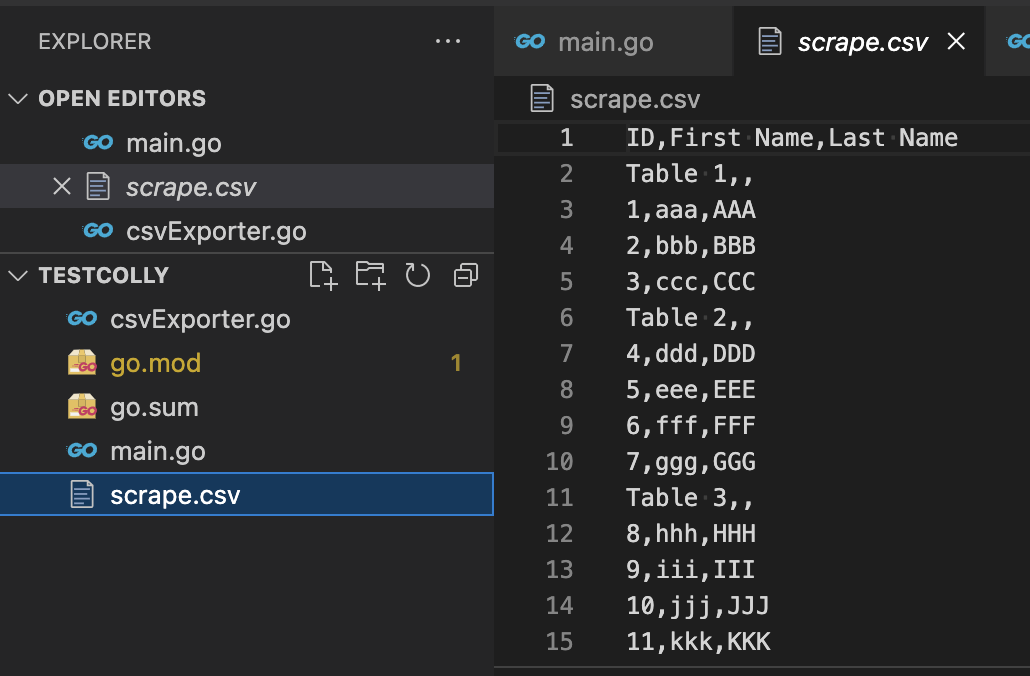
これをエクセルで開くと、最初の画像の通り表示される。
参考
・How to Scrape HTML Tables in Golang Using Colly [Quick Guide]