Linuxソースコード読書会##
その昔、あるところにLinuxのソースコードを読む読書会があり、ある期間出席したことがあった。その時は担当のメモリバディシステム部分を、良く分からないながらも紹介したことがあった。それからン十年たち、とうとうLinus本人が参加するまでになったとか。感無量である。
それはともかく、ハードウェア屋としては、あまり分からないLinuxソースを読むよりも、最近ブームのオープンハードのソースを読むのはどうだろうかと考えた。最近はRISC-Vがホットなので、早速読んでいくことにしたい。
RISC-V##
説明はwikipediaに譲る。https://ja.wikipedia.org/wiki/RISC-V
ただし、こんなことを言っては身も蓋も無いが、技術的にはあまりISAに興味が無いのだ。その理由は、実はISAはなんでも良いため。厳密にはなんでも良くはないが、大雑把には、高級言語とマイクロアーキテクチャの間を埋めるビットパターンであり、ISAの違いはいわば命令デコーダが変わるだけ、というとちょっと言いすぎかな?ニュース記事にはRISC-Vの発明者云々と書いてあったが、ISAを発明というのは大げさでまあ開発者だろう。
一方で、ISAは政治的経済的には大変重要であり、その理由は、大多数の人々を巻き込むからである。それはコンピュータアーキテクチャ(ISA)が経済的な理由から一つに収斂する性質があるため。バイナリ互換は技術的にではなく経済的な側面から大変重要な観点と考える。その意味では、ISAの選択基準は「何でも良いが、メジャーである(あるいは、将来なる)こと」。RISC-Vは後者となることが期待される。
読書対象##
読む対象はRISC-Vと決めたところで、対象物はいろいろとあるが何が良いだろうか。あまり複雑なものは読むのに苦労するし、一方で、あまりにも簡単な5段パイプラインのシングルイシューRISCマイクロアーキテクチャだと、既に開発したことがあるためつまらない。それこそ某RISCとRISC-Vでは命令デコーダが違うだけになってしまう、ということで、適度な複雑性を兼ね備え、かつ未完成のものを探したところ、候補としてRIDECORE(RIsc-v Dynamic Execution CORE)を見つけた。教育目的もあり、Verilogで10,000行無いらしい。
どうやら割り込みを実装していないのでOSが動作しないようだ。自分の目標としては自作のプロセッサでLinuxをブートさせることがあるので、RIDECOREをベースに割り込み等を実装することを検討してみたい。特権命令等の実装も必要かもしれないが、フィージビリティは読み進めて行くうちに判明するはず。
自作プロセッサ##
ここで「自作」を定義しておきたい。もちろんスクラッチから何も参考にせず全て記述すれば、自作に間違いは無い。一方で、Linux KernelはLinusが全て書いたかと言えば、そうではない。それどころかカーネル以外を含めれば、例えばデスクトップで使われているLinuxシステムからみるとLinusの書いた部分は1パーセントを超えるだろうか?
自作の定義に戻ると、しかしながらLinusは少なくともKernelの、コミットされるべきソースコードには目を通してGo/NoGoを決定していると思われる。これに倣えば、自分でコーディングしようが他人がしようが、自分が理解してコミットすればソースコードを自ら打ち込まなくても自作と言えると考える。
RIDECORE##
RIDECOREのソースはGithubで公開されている。https://github.com/ridecore
ここに書かれているとおり、RV32I ISAを持つアウトオブオーダ6段パイプラインのマイクロアーキテクチャとなっている。
RIDECORE's microarchitecture is based on "Modern Processor Design: Fundamentals of Superscalar Processors" (https://www.waveland.com/browse.php?t=624&r=d|259). Thus, we recommend users to read this book and our document (doc/ridecore_document.pdf) before using RIDECORE.
とあるため、早速原書を取り寄せてみた。昔購入した「スーパスカラ・プロセッサ」(マイクジョンソン著)という本を取り出して眺めてみたが、Tomasuloアルゴリズムは今も変わらないものの、内容がやや古いように思われたため、原著を取り寄せ中。
RIDECOREマイクロアーキテクチャ##
以下はRIDECOREのマイクロアーキテクチャ図。
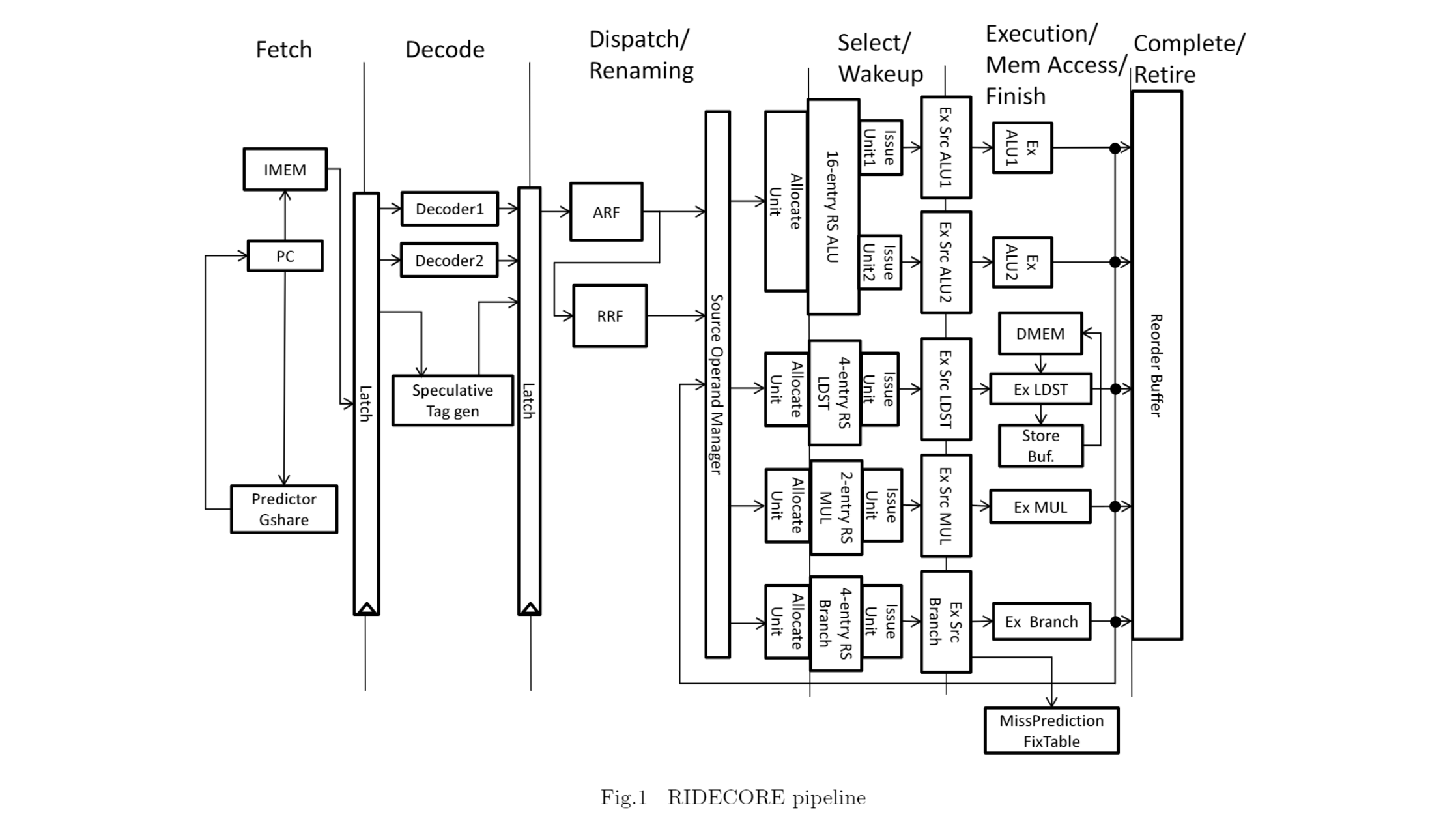
(上記GitHub内ドキュメントより引用)
Fetch, Decode, Dispatch/Renaming, Select/Wakeup, Execution, Retireの6段パイプラインとなっている。頭の中にはごく普通のRISCの5段パイプラインのマイクロアーキテクチャが存在するため、付加的な加速器であるところの、分岐予測器、投機タグ、レジスタリネーミング、リザベーションステーション、リオーダバッファ等に興味があることから、それら「加速器」(本稿の用語)について中心に読んでいくことにする。基本のパイプラインは必要に応じて読むようにしたい。
パイプラインステージ毎に回路が並んでいたら良かったのだが、さすがにVivadoが描いた図だとそこまで対応していない。
分岐予測とは##
Fetchステージの加速器である分岐予測器を取り上げる。分岐予測の仕組みは、分岐が2度連続して起こった場合は次も分岐だろうという予測をもとに、分岐元アドレスや分岐先アドレスをBTB(Branch Target Buffer)に記録しておき、分岐命令アドレスによりそれを検索し、分岐と予測された場合は分岐結果をあらかじめ投機実行しておき、はずれたらパイプラインを無効化するもの。
Gshare Predictor(分岐予測器)##
マイクロアーキテクチャ図(Fig.1)にもあるGshare Predictorを早速読むことにする。分岐予測をWikipediaで調べると、2レベル適応型分岐予測器と広域履歴を組み合わせてGshare分岐予測器と呼ぶとのこと。
広域的に共有される履歴バッファとパターン履歴テーブルを持つ2レベル適応型分岐予測機構で、広域履歴と分岐命令のPCをXORして使用する場合を "gshare" 予測器 と呼び、それらを連結して使用する場合を "gselect" 予測器と呼ぶ。広域分岐予測は、AMDのマイクロプロセッサ、インテルの Pentium M、Core、Core 2 で採用されている。
ところが、Gshare Predictorとはなんぞやと調べたところ、それよりも良い加速器があるとの論文を見つけた。http://www.arch.cs.titech.ac.jp/~kise/SimAlpha/doc/uec-is-2003-02.pdf
Gshare予測器に限らず、有限のエントリには競合が起きる。分岐の予測結果は分岐実行(taken)か非実行(not taken)かしかないため、結果に応じて格納先を2つの分岐予測バッファに分ければ競合しても結果が反転しにくい。これをsgshareとかbimodeとか言うようである。
ともかくRIDECOREにはGshare分岐予測器が設けられている。FPGA等で実際に動くようになったらsgshare予測器に交換しても面白いかな。このあたりの改変可能な点がオープンハードプロセッサ+FGPAの醍醐味ではなかろうか。部品から設計できるので、(部品を組み合わせるだけの)プラモデルよりもよっぽど面白いのでは。
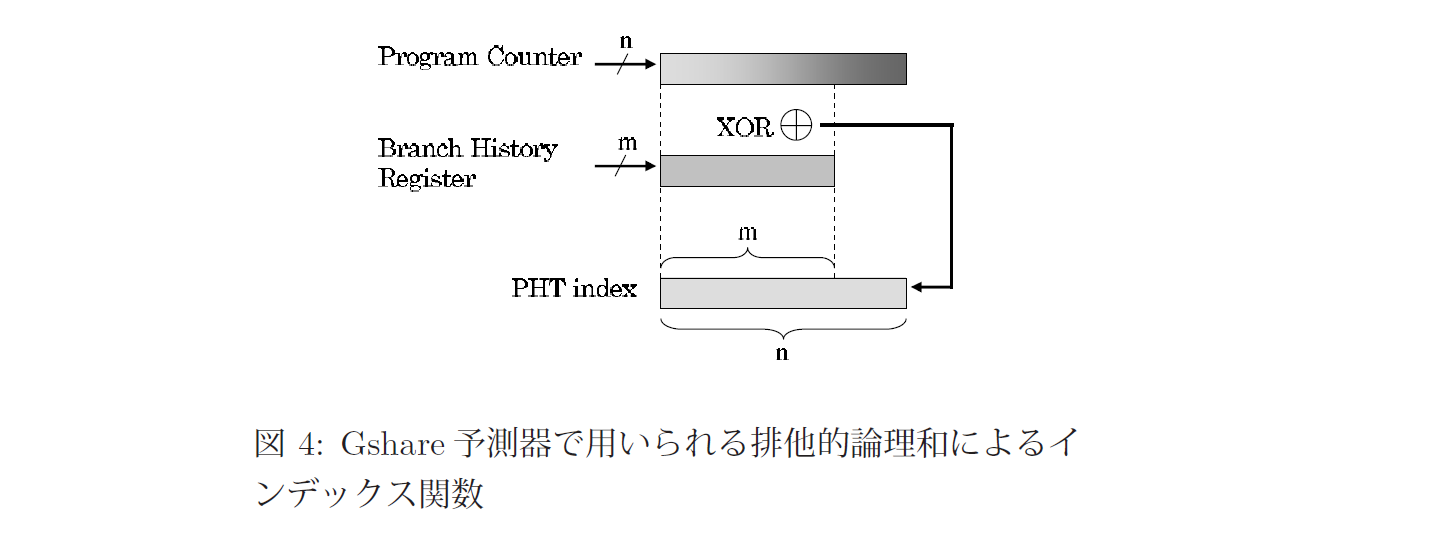
(上記論文より引用)
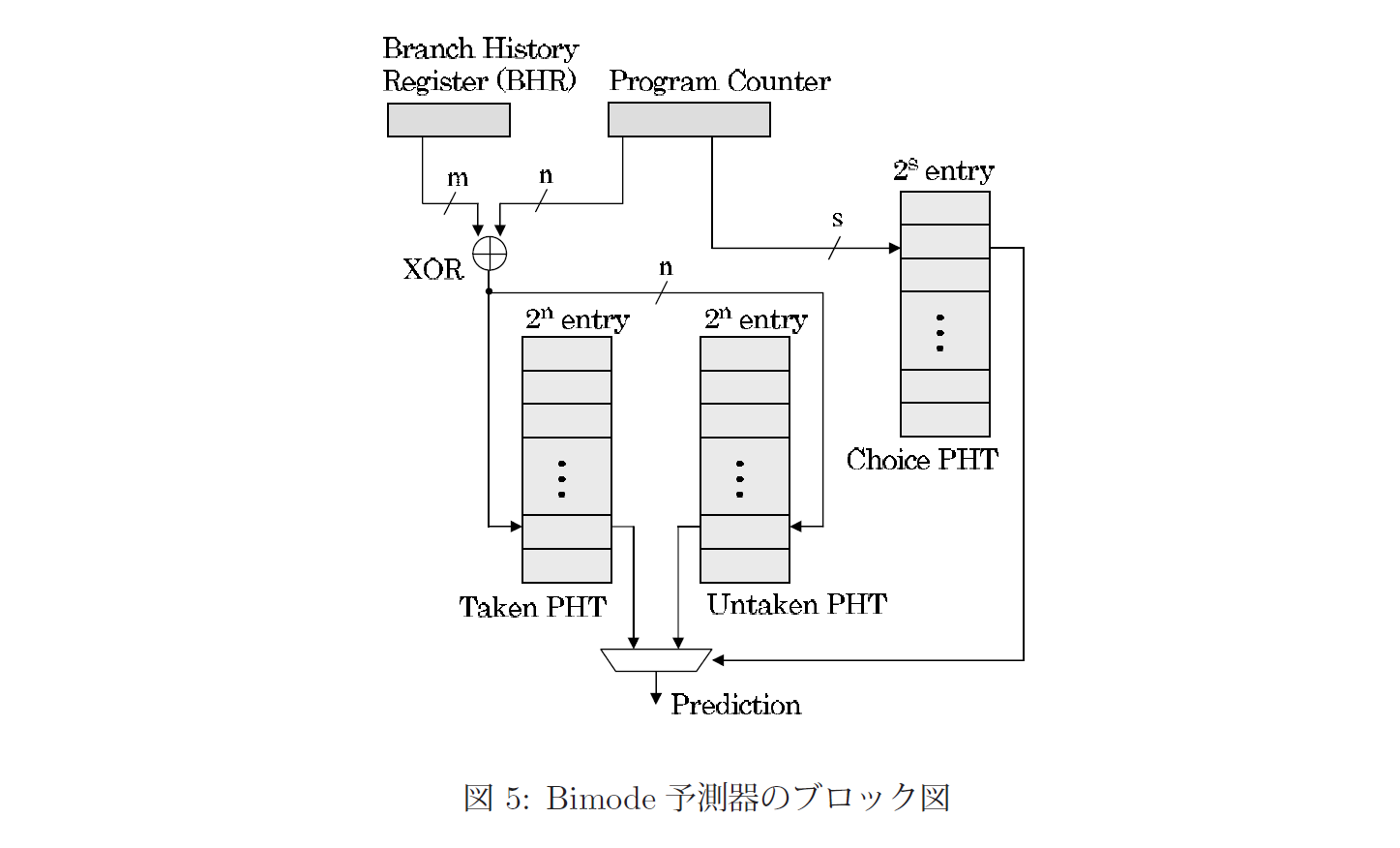
(上記論文より引用)
図のように、Bimode予測器は、分岐結果に基づいて分岐側PHTと非分岐側PHTに分けていることがわかる。
というところで、読むところまでたどり着かなかったので、読むのは次回に。