前回 ( http://qiita.com/moaikids/items/7bcdcc3648c71beb7806 )に続いて、この記事では、さだまさしの歌詞を基に N-gram コーパスを作ってみます。
ただデータを作り、それを解析するだけだと面白く無いので、今回は動くデモを作ってみました。
N-gram コーパス
N-gram とは連続した N 文字の並びの集合のことを指し、N-gram コーパスは一般的には N-gram 文字列の特定文書群などにおける発生頻度を情報として付加したものです。
世の中に公開されているものとしては「日本語ウェブコーパス 2010」が有名です。
N-gram コーパス - 日本語ウェブコーパス 2010
企業が公開したものとして、Google N-gram コーパスや Baidu の N-gram コーパスなどが有名です(現在はともに非公開?)
一般的に、形態素解析して得られた語を1単語として N-gram コーパスを作成すると**「形態素 N-gram コーパス」と称され、文字1文字ごとに区切るものを「文字 N-gram コーパス」**などと呼ばれます。
さだまさし 歌詞 形態素 N-gram コーパス
今回は、前回の記事でも紹介した kuromoji を用いて、形態素 N-gram コーパスを作成してみました。
て い た 89
の よう に 55
の 中 で 52
に なっ て 43
に なっ た 40
て くれ た 35
誰 も が 33
の 様 に 33
て 来 た 32
て き た 32
.....
| n-gram | 異なり数 | 頻度 2 以上 |
|---|---|---|
| 1-gram | 9280 | 3566 |
| 2-gram | 43574 | 8704 |
| 3-gram | 73920 | 6121 |
| 4-gram | 85760 | 2485 |
| 5-gram | 89342 | 1083 |
| 6-gram | 90694 | 720 |
| 7-gram | 91416 | 622 |
こちらを基に、分析を行っていきたいと思います。なお、すみませんがこちらの N-gram コーパスは私的使用に留めるため非公開です。
さだまさし歌詞サジェスト
N-gram コーパスを使って一番簡単に応用できるものとして、検索窓などによくあるサジェスト機能があります。
さだまさしの歌詞の写経的な行為はファンの間では日常的に行われますので、その補助ツールとして、何か文字を入力したら適切な歌詞をサジェストしてくれるような機能はあると便利です。
ということで、作ってみました。
デモサイト URL
https://sadatech.herokuapp.com/suggest
サイトに訪れていただけるとわかると思いますが、設置してあるテキスト入力欄に文字を入力すると、入力された文字と一致するさだまさしの歌詞がサジェスト表示されます。
heruku 上でこともあろうに Java のプログラムを動かしているので、 footprint が非常に遅く起動まで大変時間がかかるケースがありますが、辛抱強く待ってください...
実行例
防人の詩
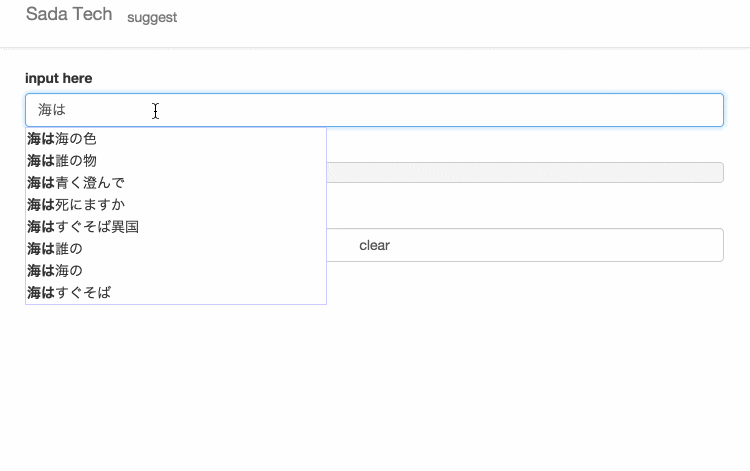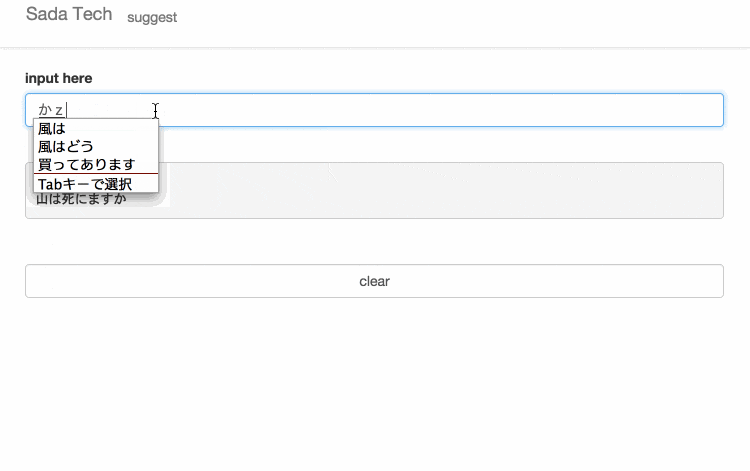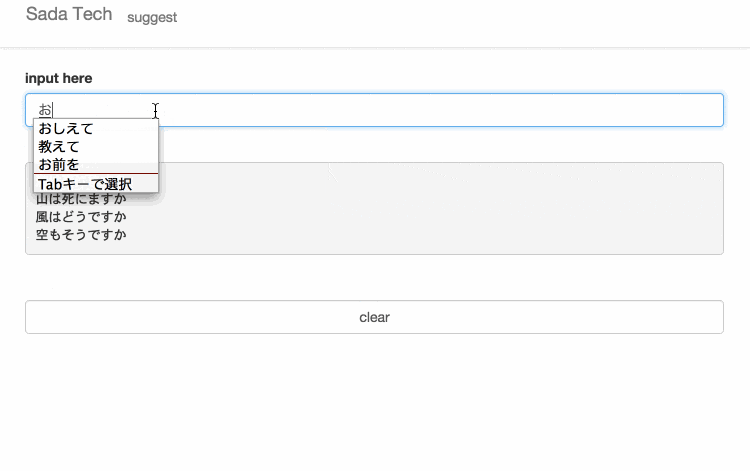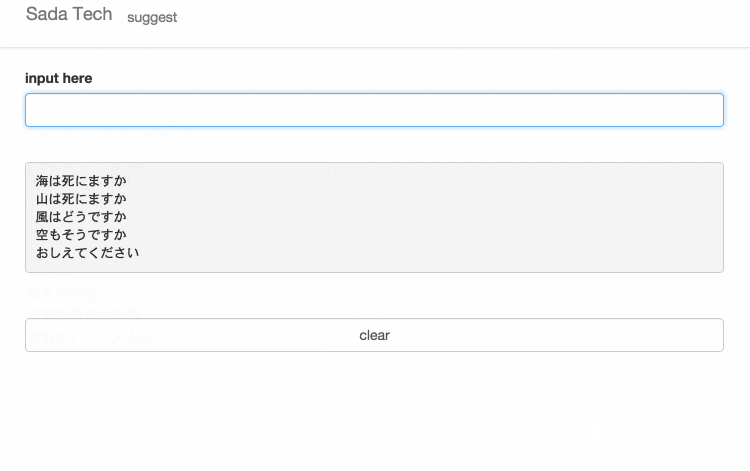
無縁坂
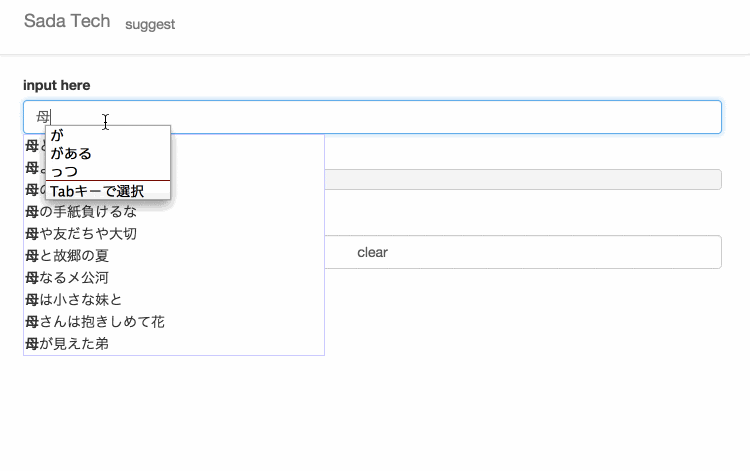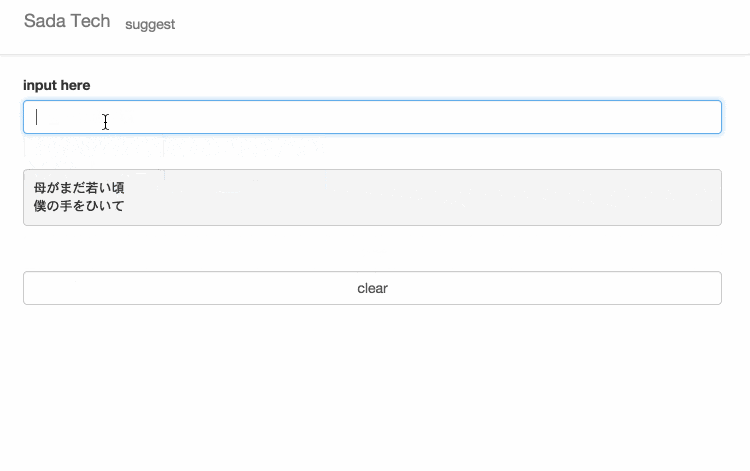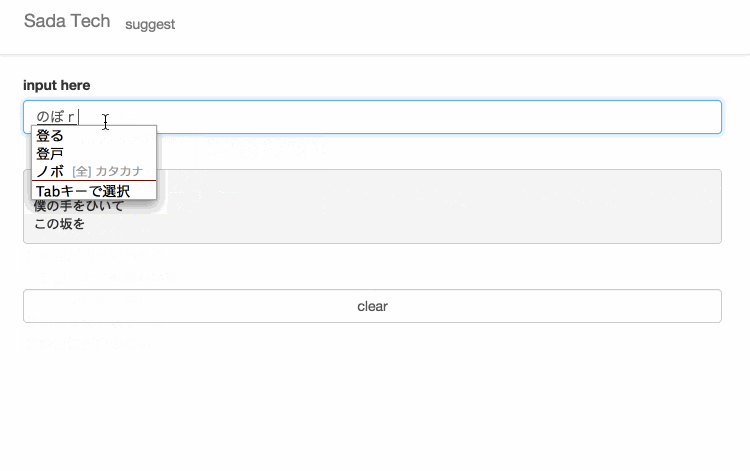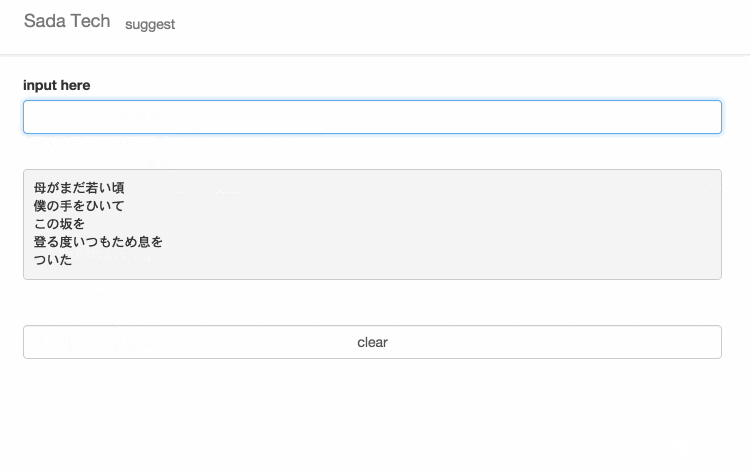
まほろば
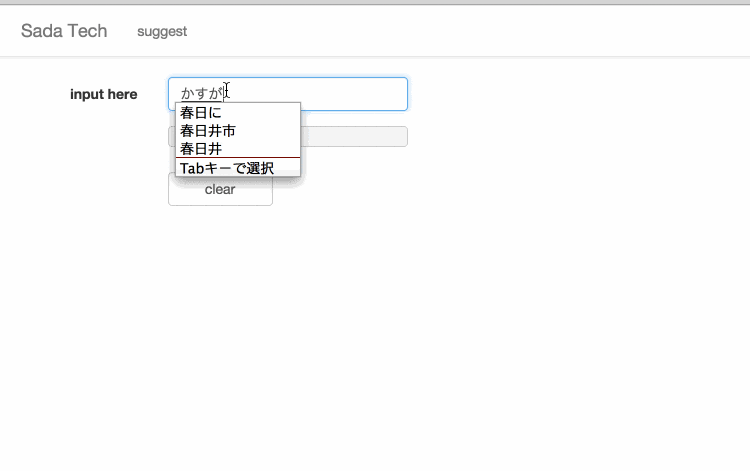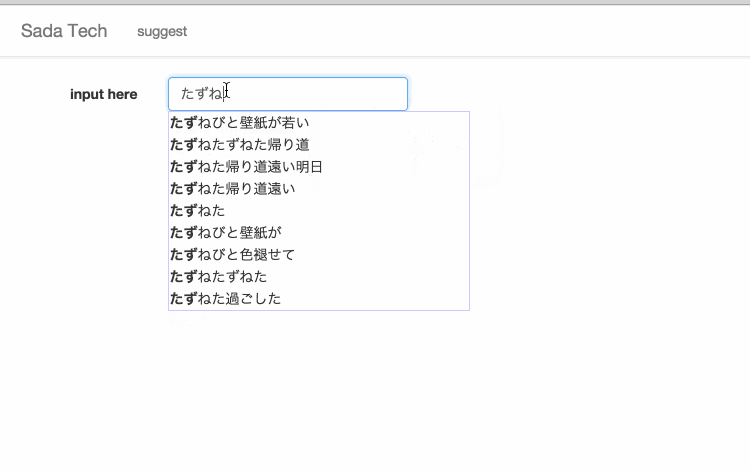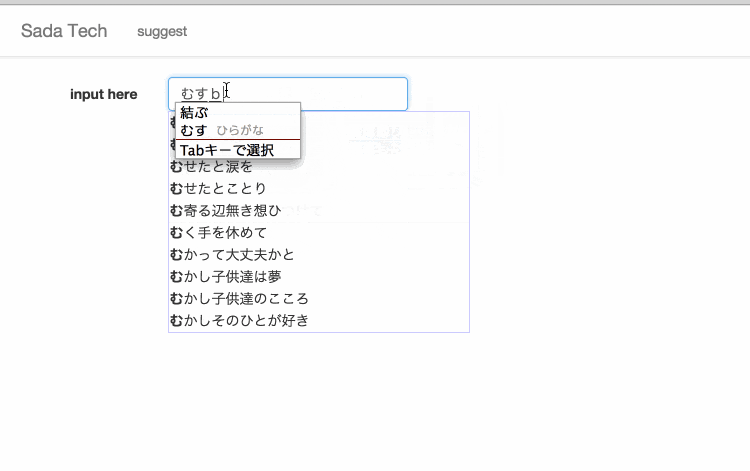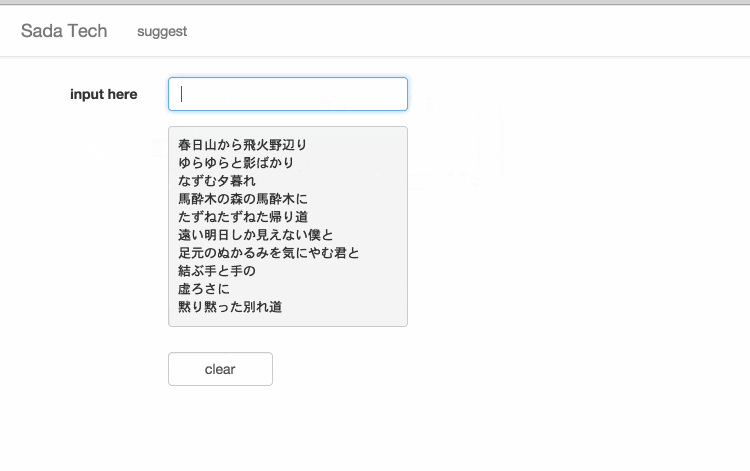
極光
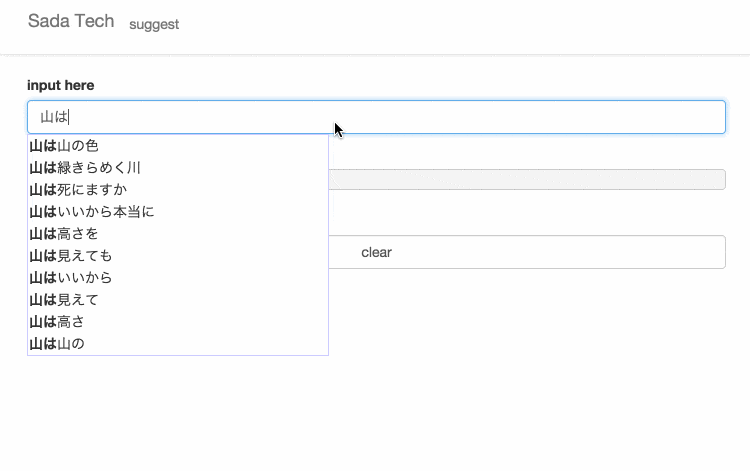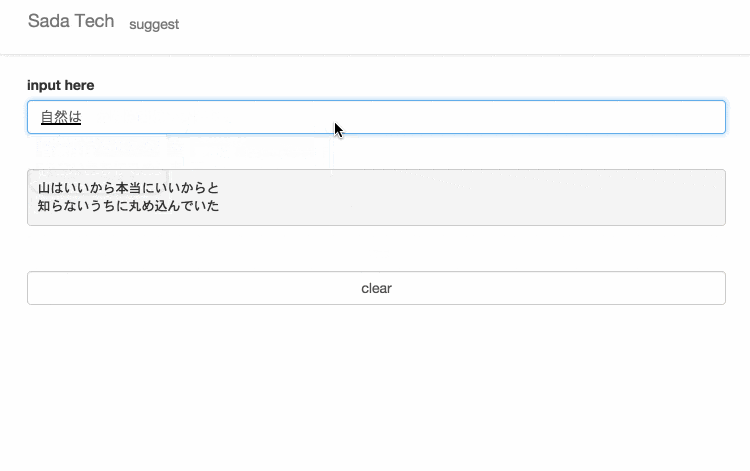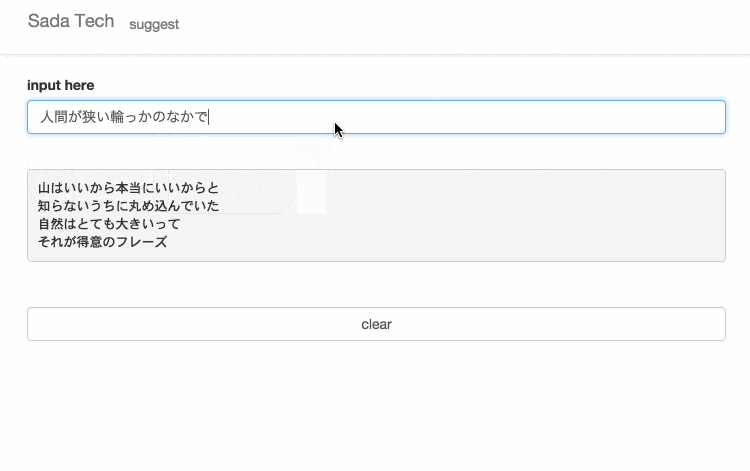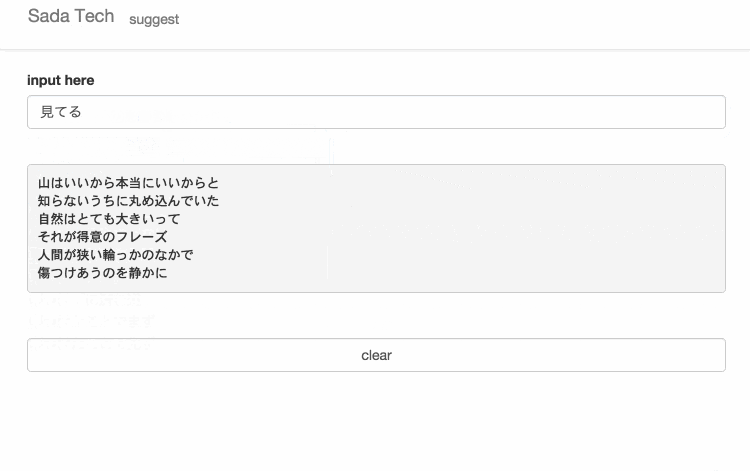
仕組み
suggest.js
サジェストの裏側の処理を Trie 木などを用いて真面目に実装しても良かったのですが、今回は JavaScript のみの世界で完結させたかったので、一番手軽に実装できそうな suggest.js を使用しました。
http://www.enjoyxstudy.com/javascript/suggest/
非常にドキュメントが丁寧にまとまっているので、使い方は作者のサイトを見るとよくわかると思います。
suggest.js が読み込むデータの用意
suggest.js では、JavaScript の配列データを読みこませることでサジェスト処理を行います。そのため、以下の様な形で配列データを用意する必要があります。
var list = ["あなたの","生きて","あなたに","なった","あなたが","なって","くれた","あなたを","静かに","あなたは","笑って","忘れない","それは","信じて",.....];
このデータの生成に、先ほど作成した N-gram コーパスを使用します。
N-gram コーパスから有効なデータの抽出
今回は JavaScript で実装するため、ある程度データサイズを絞る必要があります。
そのため、あまり本質的な対応ではないものもありますがヒューリスティックなアプローチをいくつか行い、データを減らしました。
- 対象とするデータは 2-gram ~ 5-gram のもののみ
- 先頭文字は以下の品詞のもののみを対象に
- 名詞(非自立語は除く)
- 動詞
- 形容詞
- 終端文字が文章の区切りとして中途半端なものを削除
- 「っ」が終端文字であるもの、など
- 短すぎる語は削る
- 一定のスコア(≒出現頻度)の語だけ残す
- ある程度長文のフレーズについては、edit distance (編集距離) の値を計算し、類似度が高い文章間については長い方の文章を優先し、他方は削る。同じような表現の文字列の重複をできるだけ減らすため。
- 「何処かの誰か」 と 「何処かの誰かに」 であれば後者を優先して残す
- 「いつまでもあなたの」,「いつまでもあなたを」 などと 「いつまでもあなた」 であれば前者を優先して残す
- 最長一致文字列となりやすそうな文字を出来るだけ残すために、前方一致する語が多い文字列については加点をする
- 「海は」という語は「海は死にますか」という語に前方一致するので、「海は死にますか」に加点をする。
- 前方一致探索に Trie 木を使う
- 最終的に残った単語群を、スコア(≒出現頻度)の逆順でソートし、js の配列形式として出力する
編集距離
文章間の類似度を量る一つの尺度として用いられている概念です。
一番有名なのは、Wikipedia にも項目のある「レーベンシュタイン距離」ですが、いくつか亜種含めアルゴリズムの種類があります。
Wikipedia - レーベンシュタイン距離
レーベンシュタイン距離は、異なる二文字が存在する時に、何回編集操作(文字を足す、削除する、入れ替える)を行うと同じ文字になるか、を距離として表現したアルゴリズムです。
Java の実装としては Lucene / Solr の中などに存在しています。
https://lucene.apache.org/core/4_0_0/suggest/org/apache/lucene/search/spell/LuceneLevenshteinDistance.html
Trie 木
こちらもアルゴリズムとしては非常に一般的なものです。主に文章群などについて順序付きの木として表現することにより、探索の速度を高速化するためのアプローチです。
Wikipedia - トライ木
Trie 木は世の中にびっくりするくらいの数多な実装が存在していますが、Java で言うと trie4j が様々な実装の種類も用意されており、使い勝手も良いので一番良いのではないかと思います。
https://github.com/takawitter/trie4j
maven であれば、以下のように dependency を指定するだけで使用可能になります。
<dependency>
<groupId>com.github.takawitter</groupId>
<artifactId>trie4j</artifactId>
</dependency>
結果
ということで再掲です。
https://sadatech.herokuapp.com/suggest
次回
「さだロボ」作成への道は続く
appendix.
定性的な解析は、一番最後のコーナーにしました。
さだまさしにおける恋愛観
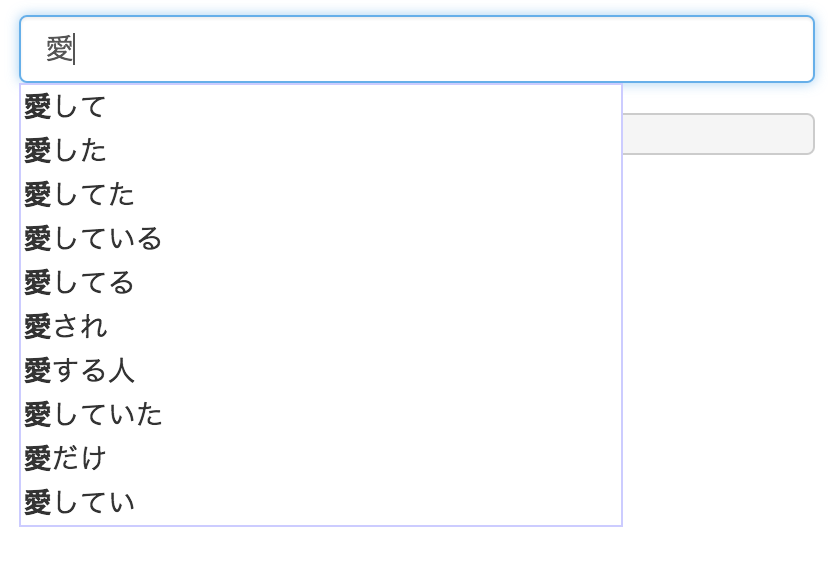
N-gram コーパスを作ると、特定の単語がどのような文脈で使われているか、類推しやすくなります。
ということで、私には不得手なテーマではありますが、恋愛関係のワードがさだまさしにおいてどのように語られているか、見ていきたいと思います。
愛
N-gram(1-gram~7-gram) コーパスの中で、「愛」から始まるフレーズを出現頻度順に抽出してみました。正確には、名詞的な用法を除きたいので、「愛し」から始まるものを抽出してみてます。
愛し 72
愛して 35
愛した 17
愛しい 11
愛してた 10
愛してる 9
愛している 8
愛し合い 6
愛してい 6
愛していた 5
愛しく 4
愛した人 4
愛し合っ 3
愛し合う 3
愛し合って 3
愛しき 3
愛しいあなた 3
愛し方 3
愛した人を 3
愛し合ってい 2
定性的な個人的な感覚なのですが、「愛した」「愛してた」「愛していた」と過去形で語られるケースが多く感じられます。
好き
同様に、「好き」で。
好き 55
好きだっ 17
好きだった 17
好きな 12
好きだ 9
好きです 4
好きだった人 4
好きだと 4
好きでし 3
好きでした 3
好きと 3
好きじゃ 2
好きじゃない 2
好きだったあの 2
好きで 2
好きか 2
好きだなんて 2
好きだから 2
好きな人 2
好きかと 2
「好きだった」「好きでした」というフレーズが気になりますね。
さだまさしは、目の前の人に対して直球で恋愛感情を伝えるより、昔の恋、昔そばにいた人、そんなものに対しての追憶として「愛」や「好き」という言葉が語られる事が多いのかも、しれません。
過去形/現在進行形で何が語られているのか
ということで、私の資質的・能力的に恋愛について語るのに限界を感じてきたので、話題を変えて、さだまさしにおいては何が「過去の追憶」として語られてる事が多いのか、調べてみました。
やりかたはナイーブで、「ていた」等、語尾に過去形表現の言葉を含むフレーズ、ならびに比較の意味で「ている」などの現在進行形の言葉を含むフレーズを抽出してみて、どんな傾向があるのか見てみます。
~てた / ~ていた
してた 15
愛してた 10
見てた 8
を見てた 7
笑ってた 6
思ってた 6
していた 6
と思ってた 5
愛していた 5
信じていた 5
見ていた 5
似ていた 5
に似ていた 5
揺れていた 4
待っていた 4
を見ていた 4
輝いてた 3
かけてた 3
れてた 3
みてた 3
~てる/~ている
ている 168
てる 164
生きている 24
生きてる 12
してる 12
暮らしてる 10
している 10
待っている 9
愛してる 9
信じてる 9
愛している 8
咲いてる 8
見てる 8
続けている 7
見ている 7
れている 7
わかってる 7
れてる 7
みつめている 6
覚えている 6
過去の追憶として
- 笑ってた
- 思ってた
- 輝いてた
現在進行形、未来へ向けた気持ち、意志としては
- 生きている
- 暮らしてる
- 待っている
という言葉が特徴的に多く使われているように見えます。
そして
- 愛する
- 信じる
という言葉はどちらでも多く使われている、という結果でした。
楽しく輝いて居た日々を過去形で追憶として語り、たとえどんな事があろうとその事を続けるという「意志」を表現するときに現在進行形のフレーズを使うことが多いのかな、と個人的には感じています。そして、たとえば「(ずっと)待っていた」みたいな、未練を感じさせるような表現は比較的少ないのかな、という事も感じます。
「暗い」と表現されることの多いさだまさしですが、非常に前向きな歌が多く、実際のところそれほど暗い、すくなくとも後ろ向きな歌というのは少ないのではないかな、と思っています。
「とてもちいさなまち」
そんな事を書いた最中、ひと目見て「暗い!!」と思う歌について書きますが、「過去形」と「現在進行形」の言葉の混ざり合いで独特の味を出している曲として一曲、「とてもちいさなまち」という歌を紹介します。この歌はマニアでも知らない人が多い歌だと思いますが。。
この歌は、町を出て行く「僕」が、町に残して来た「君」と、故郷への追憶を歌う歌です。
この歌において、「僕」は、「君」や「故郷」に対する追憶を過去形の文体で語ります(暮らした、愛した)。
そして残された「君」の描写は、現在進行形で語られています(待っている)。
残された「君」も「故郷」も、変わらない日常が続いていくわけですが、それを断ち切った「僕」の心境、後悔や追憶や自責の念、そしてそれでも前に進まなければいけないやむを得ない心境、といったものがないまぜになって表現されている、そんな歌だと思います。
(なお、この歌は、戦場に赴く兵士を表した歌だ、という説もあります。僕の中で。)
歌で人の様々な心、情景を伝えるために、どの歌にもかなりの創意工夫が感じられ、こういう解析をしてみて改めて作り手の人たちへの敬意の念が芽生えてきます。