さだまさし 名詞-固有名詞-人名-一般
さだまさしの、主に詩の歌詞を対象に、簡単な品詞分解と、それを基にした簡単な分析を行ってみた、というのがこの記事の内容です。
個人的な最終的なゴールは、さだまさし風の歌詞を自動生成する bot (さだロボ) を作る事になりますが、その過程を週一でディアゴスティーニ的に(サダゴスティーニとかは節度のある大人なので言わない)書いていければと思います。
ついでに、その道すがら、ちょっとした解析・分析結果なども書いていきます。
道具の用意
解析するにあたっていくつか道具が必要なので、最初に、使用したツール群について簡単にお話します。
kuromoji
KuromojiはJavaで書かれているオープンソースの日本語形態素解析エンジンです。
Java で形態素解析を行いたい場合、昔は「Sen」などを使うことが多かったですが、atilika 社が OSS として kuromoji を公開してからは Lucene や Solr などでも対応していることもあって kuromoji を使うことが多くなりました。ということでこちらを。
ちなみに個人的には Java に対するこだわりはあまりなかったのですが、うっかり "kuromojiで" と書いてしまったので今回は Java でいきます。
シンプルに kuromoji を Java プログラムから使いたいだけの場合は、 maven などに以下のような定義を追加すれば OK です。
<repositories>
<repository>
<id>Atilika Open Source repository</id>
<url>http://www.atilika.org/nexus/content/repositories/atilika</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.atilika.kuromoji</groupId>
<artifactId>kuromoji</artifactId>
<version>0.7.7</version>
<type>jar</type>
<scope>compile</scope>
</dependency>
</dependencies>
mecab-ipadic-NEologd
基本的には kuromoji に内包されている標準辞書を用いますが、一部ケースで日本語辞書に overlast さんが作った mecab-ipadic-NEologd を使ってみます。こちらは新語流行語などのメンテナンスが定期的に行われている ipadic 互換の辞書です。
こちらの辞書を kuromoji で取り込もうとした場合いろいろと手順が必要になるので、今回の分析では予め kuromoji と mecab-ipadic-NEologd のインテグレーションが行われてパッケージ済みの elasticsearch-analysis-kuromoji-neologd を使わせていただきます。
elasticsearch-analysis-kuromoji-neologd
elasticsearch-analysis-kuromoji-neologd を Java プログラムから使いたい場合は、こちらも maven などで以下のように記述すれば OK です。
<dependencies>
<dependency>
<groupId>org.codelibs</groupId>
<artifactId>elasticsearch-analysis-kuromoji-neologd</artifactId>
<version>2.0.0</version>
</dependency>
</dependencies>
elasticsearch-analysis-kuromoji-neologd のサンプルコード
String src = "さだまさし";
try (JapaneseTokenizer tokenizer = new JapaneseTokenizer(null, false, JapaneseTokenizer.DEFAULT_MODE)) {
tokenizer.setReader(new StringReader(src));
CharTermAttribute term = tokenizer.addAttribute(CharTermAttribute.class);
PartOfSpeechAttribute partOfSpeech = tokenizer.addAttribute(PartOfSpeechAttribute.class);
tokenizer.reset();
while (tokenizer.incrementToken()) {
System.out.println(term.toString() + "\t" + partOfSpeech.getPartOfSpeech());
}
}
さだまさし 名詞-固有名詞-人名-一般
上記ではCharTermAttribute と PartOfSpeechAttribute を指定していますが、他にも必要な Attribute を指定することで任意で取得できる情報を追加できます。
コーパス?
さだまさしの歌詞を解析対象とするため、さだまさしの歌詞の電子データが必要です。
今回はこちら( http://www.cai-insect.jp/sada/ )のサイトの HTML を手元にダウンロードし、スクレイピングしたうえで ETL 処理を行いました。
著作権の観点もあるので、これらはプログラムも含め私的使用に留め、完全非公開です。なかには処理のミスなどで解析結果に多少悪影響を与えてるケースもあるかもしれませんが、そこは甘受してください。
品詞分解結果
という感じで、結果は以下です。それぞれの語ごとに数え上げて、その出現頻度についても出しています。
の 助詞,連体化,*,* 5763
に 助詞,格助詞,一般,* 4395
て 助詞,接続助詞,*,* 3890
た 助動詞,*,*,* 2998
は 助詞,係助詞,*,* 2954
を 助詞,格助詞,一般,* 2951
が 助詞,格助詞,一般,* 2532
で 助詞,格助詞,一般,* 1744
も 助詞,係助詞,*,* 1555
と 助詞,格助詞,一般,* 1546
.....
品詞ごとの頻度は以下。
名詞,一般,*,* 17666
動詞,自立,*,* 14480
助詞,格助詞,一般,* 11535
助動詞,*,*,* 8897
助詞,接続助詞,*,* 5542
助詞,連体化,*,* 5166
助詞,係助詞,*,* 4669
名詞,代名詞,一般,* 4508
形容詞,自立,*,* 2786
動詞,非自立,*,* 2598
.....
さだまさしの歌に多く出現する人を表す名詞
上記の結果だけだとあんまりなので、結果をもとに、ちょっと分析をしてみました。
手始めに、「私」「あなた」など、人を表す言葉のうち、多く出現するものは何かをしらべてみました
なお、歌の特性上、同じようなフレーズを何度も繰り返す事が多く見られるので、一つの歌に出現した単語はその歌の中で何度も出現したとしても「1回」でカウントするようにしています。
僕 名詞-代名詞-一般 206
君 名詞-代名詞-一般 195
あなた 名詞-固有名詞-一般 179
私 名詞-固有名詞-一般 117
自分 名詞-一般 99
みんな 名詞-代名詞-一般 52
ひとり 名詞-一般 48
お前 名詞-代名詞-一般 33
ふたり 名詞-一般 28
友達 名詞-一般 27
これだけだと「へー...」という感想しか出てこないので、もう少し調べてみます。
年代ごとに特徴があるか
歌の歌詞に手作業で(辛い)作成年代をアノテーションし、その上で上述の単語の年代ごとの出現頻度を数えてみました。年代の横のカッコ内の数字は、その時のさだまさしのおおよその年齢です。
| word | 1970年(20代) | 1980年(30代) | 1990年(40代) | 2000年(50代) | 2010年(60代) |
|---|---|---|---|---|---|
| 僕 | 49 | 64 | 57 | 22 | 14 |
| 君 | 39 | 45 | 62 | 32 | 18 |
| あなた | 33 | 44 | 52 | 38 | 12 |
| 私 | 24 | 29 | 37 | 18 | 10 |
| 自分 | 13 | 34 | 16 | 23 | 13 |
| みんな | 5 | 19 | 14 | 10 | 4 |
| ひとり | 14 | 16 | 13 | 5 | 0 |
| お前 | 4 | 14 | 10 | 5 | 0 |
| ふたり | 8 | 4 | 9 | 7 | 0 |
| 友達 | 7 | 10 | 9 | 2 | 0 |
さだまさし≒暗い というステレオタイプを持たれている人も多いと思いますが、孤独の象徴でもある「ひとり」という単語は、2010年代以降の作品では使われてないようです(最後に使われたのは「いのちの理由(2009年)」)。この辺に何かしらの意図があるのか偶然なのかは私ではよく分かりませんが、定量的に見るとそういう傾向が見えてきます。
ついでに、どの程度意味があるか分かりませんが、TF-IDF の値も算出してみて、グラフにプロットしてみました。
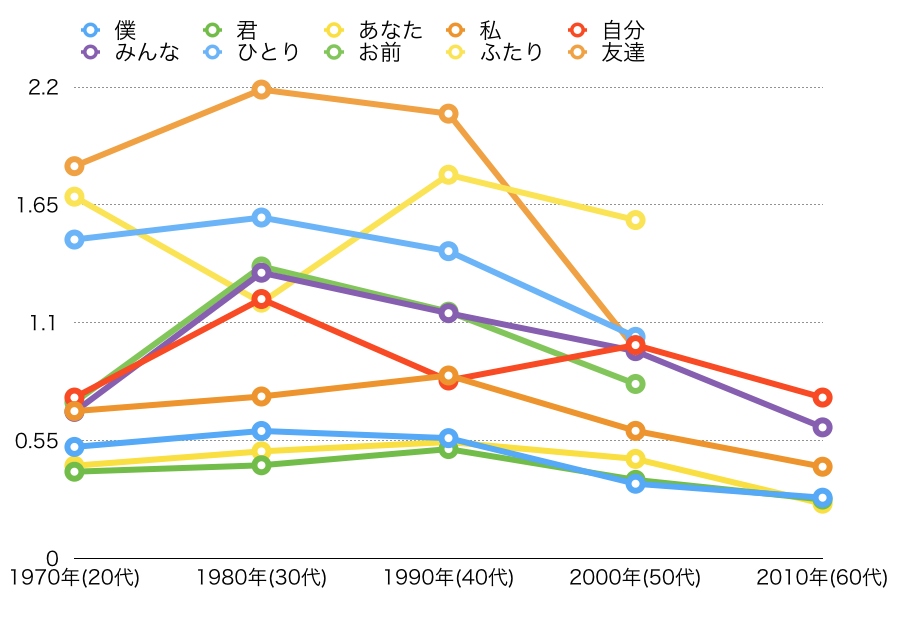
各年代でまんべんなく使われている単語もありますが、たとえば「友達」や「お前」という言葉は比較的若いころ(~40代)に使われる傾向があり、「あなた」や「自分」という言葉は40代以降から使われだされているという傾向が見えてきます。そういった傾向の変化は、実際の詩作の方向性の変化を表している、のかもしれません。
「あなた」の使われ方
一例として「あなた」の使われ方について。
以下は定量的なというより個人の主観ですが、ここ数年の老成した作品群ではかなり印象的に「あなた」という言葉が使われているように思います。
言葉のの対象は、具体的に目の前に居る個人ではなく、遠くはなれた誰か、遠い場所に旅立ってしまった誰か、遠い記憶の中の誰か、そんなあまり個人を特定しない遠い存在に呼びかける時に「あなた」という語が使われている傾向が感じられます。
(「片恋(2009年)」「あなたへ(2012年)」「ラストレター(2015年)」「風の宮(2015年)」など)
共起関係に特徴があるか
歌詞の世界観、語感を統一するために、「僕」と書いたら「君」と書きたくなりますし、「私」「わたし」と書いたら「あなた」と書きたくなります。「俺」と書いたら「お前」と書きたくなります。(そうでない人もいるかもしれませんが、一応...)
さだまさしの歌詞は「正しい日本語」と称されることもありますが、一般的によく使われている用法に基本的には沿い、音の響きを重視するあまりに変な言葉遣いになるような崩し方はしない傾向が、直感的には感じられます。
ということで、その調査の一端として、自然な組み合わせと思われる上記の組み合わせがどの程度存在しているかを知るために、語の共起分析をしてみました。
僕 - 君 137
僕 - あなた 40
僕 - お前 11
私 - あなた 83
わたし - あなた 9
私 - 君 13
わたし - 君 2
私 - お前 5
俺 - お前 13
俺 - 君 4
俺 - あなた 3
ということで、概ね上記の直感に即した結果になっていました。
一方で「私 - 君」や「俺 - あなた」というように若干直感に反している結果もあり、実際に歌詞を覗いてみました。
「極光」のケース
例えば「極光(1982年)」という歌に上記のパターンが出現しています。
こちらはオーロラに魅せられたカメラマンの実話を基にしたお話ですが、歌中に男女の登場人物がおり、それぞれ男性側が「俺」「君」、女性側が「私」「あなた」と、男女それぞれ発話者ごとに呼び方が統一されています。
発話者の特定までした上で共起関係を解析出来ればよかったのですがそれは大変なので行いませんが、定性的な観点で眺めると直感に反しているケースは基本的には発話者が両性いてそれが混じっているケースが多いようです。
ということで、少ない文字数の中で、登場人物の様を的確に過不足なく表現するために、自身や相手の呼び方にも多くの配慮が歌詞の中では見られました。
「お前」と「酒」
さだまさしにおいて「お前」という言葉は、「関白宣言(1979年)」のようなコミックソングの中で面白おかしく男女関係を表す時や、肉親(弟や妹)など親しい相手に対して呼びかける時に使われる事が多いです(「案山子(1978年)」など)
ちなみに、これはほぼ全曲を聴いてきた僕の直感なのですが、「お前」と語られた時に、「酒」が歌中に登場するケースが多いなという印象があったので、共起分析をしてみました。
| word | count | percentage |
|---|---|---|
| 僕 - 酒 | 7 | 2.9% |
| 私 - 酒 | 4 | 3.4% |
| あなた - 酒 | 4 | 2.2% |
| お前 - 酒 | 4 | 12.1% |
| 君 - 酒 | 3 | 2.1% |
| 俺 - 酒 | 3 | 14.8% |
思ったよりもサンプル数は少ないのですが、ナイーブに考えると「俺」や「お前」など若干粗野な印象を受ける語が使われている時に、親しい間柄の空気感を演出する道具として「酒」が用いられるケースが多いように見受けられます。
具体例としては、
- 「昔物語(1981年)」
- 「寒北斗(1984年)」
- 「時代はずれ(1988年)」
- 「勧酒 -さけをすすむ-(2009年)」
などです。
という感じで、ナイーブな分析でもいろいろ興味深いことがわかってくるのですが、僕が興味が有ることばかり解析し過ぎるとこの記事を見られている方をどんどん取り残していってる感があるので、この辺で自重します。
(リクエストがあれば続編書きます)
歌に登場する地名
さだまさしはコンサートで各地を訪れており、もともと旅好きというお話も聞きますし、そのこともあってか日本各地に訪れ、その地を歌の題材にしています。
とはいえ私も定量的に解析したことが無かったので、歌の中で、どのような地名が出てくるのか調べました。
以下は、品詞的に「地域」と判断された語のリストです。なお、このデータについては、解析時に歌の歌詞だけでなくタイトルも含めています。
東京:9
長崎:6
日本:4
南山手:3
押上:2
祇園:2
フランス:2
広島:2
寺町:2
稲佐:2
信濃:2
上海:2
ニッポン:2
ビクトリア:2
アラスカ:2
バグダッド:2
秋篠:2
ロシア:1
六斗:1
ユーコン:1
荒川:1
上野:1
オレゴン:1
津軽:1
眉山:1
香港:1
梓川:1
峨眉山:1
横浜:1
キリマンジャロ:1
平城山:1
福間:1
ナイロビ:1
ヒロシマ:1
四谷:1
揚子江:1
奈良:1
西の京:1
水無瀬:1
実籾:1
晴海:1
雲仙:1
ヨルダン:1
加茂河原:1
甲子園:1
京都:1
チリ:1
木屋:1
練馬:1
パリ:1
雲南:1
アメリカ:1
銀座:1
銅座:1
愛宕:1
飛鳥:1
マゼラン:1
真珠湾:1
武蔵小金井:1
仏蘭西:1
化野:1
みちのく:1
ホンコン:1
東山:1
バミューダ:1
ベルリン:1
春日山:1
木根:1
南京:1
観世音寺:1
ニューヨーク:1
長野:1
五条:1
四条:1
新宿:1
鎌倉:1
銀閣寺:1
松本:1
エルサレム:1
鳴滝:1
平安京:1
心斎橋:1
カサブランカ:1
地中海:1
秋田:1
北斗:1
軽井沢:1
赤坂:1
富士:1
ホノルル:1
天津:1
ナガサキ:1
上九一色:1
吉野川:1
立山:1
ナイル:1
チグリス:1
倶知安:1
安曇:1
湯島:1
用賀:1
海老名:1
浅草:1
吉野:1
幼少期を過ごした長崎(2位)と、中学生からバイオリンの修行のため上京したという理由もあってか東京(1位)を含む歌が多いようですね。
また「南山手」「寺町」「稲佐」「蛍茶屋」などの、他府県に住んでいる人間には馴染みのないあまり一般的でない地名なども多く見られるのが特徴です(ちなみに、左記は長崎市にある地名です)
ざっくりとしたまとめとしては、東京(特に東東京)、長崎(長崎市)、長野(信州)など、以前さだまさしが居を構えたとされる場所、そして京都、奈良などの古都が歌中に取り上げられる事が多い事がわかります。
これらを地図にプロットしてみようかとも思ったのですが**「さだまさしの歌詞に登場する場所ヒートマップ(仮)」**というテーマでアドベントカレンダーを書かれる予定の方がいる模様なので、私の方では自重します。
「北の国から」の形態素解析
最後に、歌詞が無い歌で有名な「北の国から(1982年)」のテーマを、強引に形態素解析してみたらどうなるか試してみます。ネタです。
「北の国から」には歌詞カードに スキャット と書いてあるのみで実際は歌詞は明記されていません。なので、野々村議員の会見全文書き起こしよろしく、音をなんとなく書き起こしてみたものを使用します。辞書は mecab-ipadic-NEologd を辞書として使用します。
アーアー 名詞-一般
アアアア 感動詞
アーアー 名詞-一般
アアー 名詞-一般
アアアア 感動詞
アー 名詞-一般
ンンー 名詞-固有名詞-一般
ンンンン 名詞-一般
ンーンン 名詞-一般
......
ネタとしても中途半端なオチになりました。お粗末さまでした。
次回
次回は、単語単位ではなく、もう少し対象を広げて歌のフレーズについて解析してみたいと思います。