ElasticStack には X-Pack Monitoring という監視ツールが標準でついてきますが、今回はあえて別のツールを用いて監視を行ってみます。
X-Pack Monitoring を使用しない理由のひとつとして、すでに他の Monitoring Tool を採用していて、情報は採用済みのツールに集約したい、といったケースがあると思います。
現場によって状況は様々でしょうが、ここでは一例として以下のツールを用いた監視について記載します。
- Prometheus
- Datadog
Prometheus
prometheus には様々な 3rd party の Exporter が提供されていますが、ElasticSearch 向けにも以下の Exporter が提供されているようです。
- https://github.com/justwatchcom/elasticsearch_exporter
- https://github.com/vvanholl/elasticsearch-prometheus-exporter
- https://github.com/braedon/prometheus-es-exporter
ここでは star が最も多くついている elasticsearch_exporter を使用します。
設定(run on docker)
再現しやすいように docker で prometheus と elastic_exporter を起動してみます。
global:
scrape_interval: 15s
evaluation_interval: 15s
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets:
- 'localhost:9090'
- job_name: 'elasticsearch'
static_configs:
- targets:
- 'elasticsearch_exporter:9108'
version: '3'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- 9090:9090
links:
- elasticsearch_exporter:elasticsearch_exporter
elasticsearch_exporter:
image: justwatch/elasticsearch_exporter:1.0.1
command:
- '-es.uri=<elastic search url>'
- '-es.all=true'
restart: always
ports:
- 9108:9108
画面
上記設定を行って起動すると、Prometheus 上でメトリクスの確認が行えるようになります。
実際には Grafana などのグラフ作成ツールの方がグラフやダッシュボードの作成は行いやすいので、Grafana と連携してグラフやダッシュボードを作成してメトリクスを確認することが多いかなと思います。Grafana Labs を覗くと、以下のようなダッシュボードが公開されていたりします。
https://grafana.com/dashboards/878
監視項目
elasticsearch_exporter は、README にもあるように以下の API を呼び出して値の取得を行っているようです。
- /_nodes/stats
- /_all/_stats
Prometheus 内で扱われる Metrics 一覧については以下 README の内容を参照ください。
https://github.com/justwatchcom/elasticsearch_exporter#metrics
elasticsearch_exporter は上記の用に ElasticSearch が提供している API を介してメトリクスを収集していますが、ElasticSearch が動作している環境に Exporter が設置できるようであれば node_exporter や jmx_exporter を導入して、システムメトリクスをより詳細に取得することができます。
また、簡易 synthetics 的に HTTP 経由で ElasticSearch サーバーの死活監視を行う場合は、Prometheus では blackbox_exporter を使用します。こちらも必要に応じて追加します。
Datadog
Monitoring SaaS 界で人気のある Datadog も、標準で ElasticSearch 対応のプラグインが提供されています。
https://docs.datadoghq.com/integrations/elasticsearch/
設定
Datadog のエージェントプログラム (dd-agent) をインストールすると、標準で /etc/dd-agent/conf.d/elastic.yaml.example に以下のような ElasticSearch プラグインの雛形が設置されていますので、有効にする場合は elastic.yaml にリネームした上で設定を加えていきます。
設定後再起動すると、dd-agent に設定内容が反映されます。
instances:
- url: https://<elasticsearch host>:<elasticsearch port>/
username: <elasticsearch username>
password: <elasticsearch password>
cluster_stats: true
pshard_stats: true
pending_task_stats: true
tags:
- ‘hoge:fuga’
画面
上記のような形で Datadog agent を設定して起動すると、Datadog の Metrics Exproler でメトリクスが取得できていることを確認できます。
また、Datadog は ElasticSearch の標準のダッシュボードが用意されていて、そちらを用いることでわかりやすく ElasticSearch のサーバーの状態を可視化することが可能になっています。
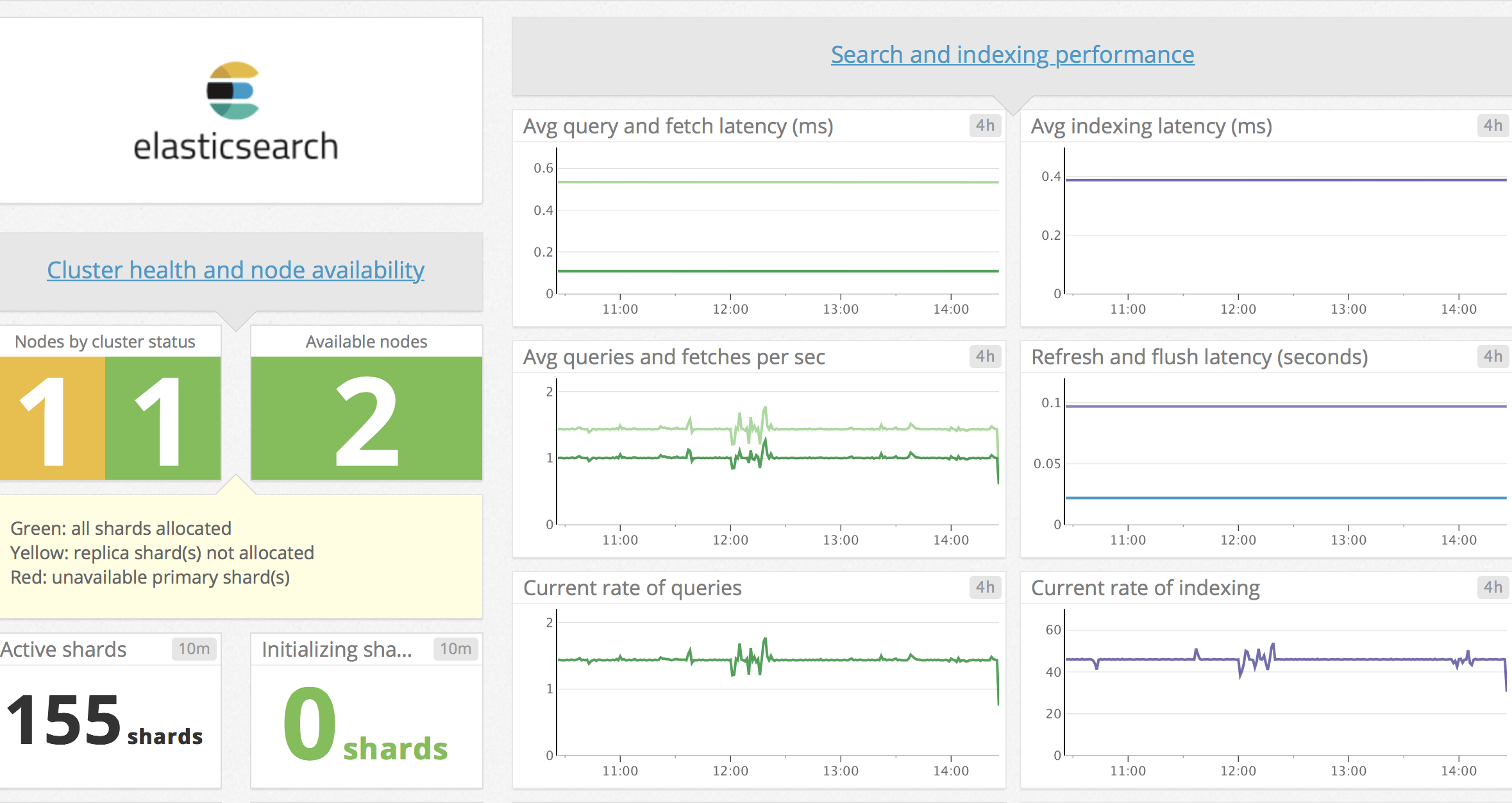
監視項目
elasticsearch プラグインのソースを読む限り、datadog plugin の中では以下のような ElasticSearch の Endpoint を呼び出して値を取得しているようです。
- /_nodes/stats
- /_cluster/health
- /_cluster/pending_tasks
- /_cluster/nodes/stats
elasticsearch プラグインで取得する Metrics 一覧については以下を参照ください。
https://docs.datadoghq.com/ja/integrations/elasticsearch/#metrics
Datadog についても Prometheus と同様 ElasticSearch Plugin は API 経由で値を取得していますが、ElasticSearch のサーバー上に Datadog の Agent が設置可能であればより詳細のシステムメトリクスを取得することが可能になります。
また、ElasticSearch の死活監視については、Datadog プラグインで死活監視用のプラグインが標準で備わっているので、これらを用います。
- http_check
- tcp_check
さらにメトリクスを追加する
上記のような内容でも十分に ElasticSearch のメトリクスが収集できているようにも思えますが、ElasticSearch は /_cat/ API を使用することにより更に詳細な情報の取得もできますので、それらの情報も Prometheus や Datadog に取り込みたいところです。
/_nodes/stats などでもある程度網羅的に情報が取得できますが、個々のノードやインデックスの細かい情報を取得したい時には、どうしても cat API の情報が必要となってきます。
https://www.elastic.co/guide/en/elasticsearch/reference/current/cat.html
新たにメトリクスを追加する場合、Exporter やプラグインを作成して拡張する必要があります。
以下では例として、特定の cat API からデータを取得してその結果を datadog に送信する処理について記載します。
/_cat/thead_pool
thread_pool の空き状況を見ることでリソースの余剰具合を判断するために取得します。
ElasticSearch ではそれぞれの thread_pool について
- active
- queue
- rejected
の三種のステータスが表示されるので、search operation など特に注視しておきたい thread_pool についてメトリクスを取得しグラフを作成して日々 thread_pool の詰まりが発生していないか注視をしています。
以下は python を用いた擬似コード的なもので、API に接続し、パースした上で、監視対象の thread_pool について Datadog にメトリクスを送信する、という処理を表現しています。
result = requests.get('https://' + host + '/_cat/thread_pool', auth=HTTPBasicAuth(username, password))
if result.status_code == 200:
for line in result.text.split('\n'):
params = line.split()
node_name = params[0]
thread_pool_name = params[1]
active = params[2]
queue = params[3]
rejected = params[4]
if thread_pool_name in thread_pools:
send_metric_to_datadog('elasticsearch.thread_pool.' + thread_pool_name + ".active", float(active), host, tags)
send_metric_to_datadog('elasticsearch.thread_pool.' + thread_pool_name + ".queue", float(queue), host, tags)
send_metric_to_datadog('elasticsearch.thread_pool.' + thread_pool_name + ".rejected", float(rejected), host, tags)
/_cat/nodes
ElasticSearch クラスターの各ノードの情報詳細を取得します。datadog などを直接ホストコンピュータにインストールできる環境では当該処理は不要かもしれませんが、そうではない環境下において CPU や Load Average、メモリ、ディスクの情報などが取得できるのは便利なので使用します。
/_cat/nodes?v&h=id,ip,port,v,m といった形で値が必要な項目をカンマ区切りで複数渡せるようになっているので、必要な情報リストを設定ファイル等で渡して取得するようにしています。
url = 'https://' + host + '/_cat/nodes?v&h=' + ','.join(headers).replace('\n','')
result = requests.get(url, auth=HTTPBasicAuth(username, password))
if result.status_code == 200:
column_names = []
for line in result.text.split('\n'):
if len(column_names) == 0:
column_names = line.split()
continue;
params = line.split()
node_ip = params[0]
node_name = params[1]
for i in range(2, len(column_names)):
column_name = column_names[i]
param = params[i]
tags = dd_tags[:]
tags.append('node_ip:' + node_ip)
tags.append('node_name:' + node_name)
send_metric_to_datadog('elasticsearch.nodes.' + column_name, float(param), host, tags)
/_cat/indices
ElasticSearch のインデックスの中に含まれているドキュメントの数や、インデックスのデータサイズなどを取得するために使用します。
主にドキュメント数やサイズの急増・急減などアノマリー的な事象に気づくために使用しています。
url = 'https://' + host + '/_cat/indices/*?v&h=index,health,docs.count,store.size'
result = requests.get(url, auth=HTTPBasicAuth(username, password))
if result.status_code == 200:
column_names = []
for line in result.text.split('\n'):
if len(column_names) == 0:
column_names = line.split()
continue;
params = line.split()
index_name = params[0]
for i in range(1, len(column_names)):
column_name = column_names[i]
param = params[i]
tags = dd_tags[:]
tags.append('index_name:' + index_name)
send_metric_to_datadog('elasticsearch.indices.' + column_name, float(param), host, tags)
まとめにかえて
ElasticSearch では X-Pack Monitoring で監視をするのが王道な気はしますが、様々な諸事情で他の監視ツールを使う必要が出てくることもあります。
ElasticSearch は各種メトリクスを取得するための API が充実しているため、上に挙げたような 3rd Party ツールでも ElasticSearch に予め対応しているツールもサービスも多いですし、独自で拡張する余地も残されています。
ということで簡単な監視周りのお話でした。Happy Elastic Life!