はじめに
私の記事
は今なお多くの方からいいねをいただいているロングセラー。
だが、Pillowの新バージョンではここで使っている一部の関数が廃止され動かなくなってしまう。
そこで来るべき新バージョンに対応した改良版をお届けする。(もちろん現在の最新バージョン9.5.0でも可)
偉そうに書いてはみたが、今回の知見は最初の記事にコメントしてくださったこーのいけさんがすでに2年前に示しているというのが正直なところ。
ソース
最後に示します。
新旧関数の勉強
ImageDraw.textsize(text, font)【廃止予定】
(width, height)でテキストのサイズを取得する。
そのサイズを持つ四角形がどこにあるのかという情報はないので、 ImageDraw.text() のxyを基準として使う。
今思うとそれでは不十分なのだが、廃止される関数だからもうどうでもいいや。
さらに、何らかのバグにより正しいサイズが取れていない。
以前の我が関数では高さを修正していたが、実はフォントによっては幅方向も正しくなかったりする。今回のフォントはAngel Tears(のトライアル版)。

この部分のソースコード
from PIL import Image, ImageDraw, ImageFont
WHITE = (255,255,255)
RED = (255,0,0)
BLUE = (0,0,255)
font = "ANGELTEARS-trial.ttf" # ANGEL TEARS trial
size = 100
fontPIL = ImageFont.truetype(font=font, size=size)
x, y = 20, 20
text = "Black\nJack"
imgPIL = Image.new("RGB", (200, 200), WHITE)
draw = ImageDraw.Draw(imgPIL)
draw.text(xy=(x,y), text=text, fill=BLUE, font=fontPIL)
draw.ellipse(xy=[(x-3,y-3), (x+3,y+3)], outline=RED)
w, h = draw.textsize(text, fontPIL)
draw.rectangle([(x,y), (x+w,y+h)], outline=RED)
imgPIL.show()
ImageDraw.textbbox(xy, text, font)
pillow 8.0.0で追加された。
テキストボックスではなくテキストビーボックス。テキストバウンディングボックス。
xyはテキストの座標すなわち ImageDraw.text() のそれと同じ値を指定する。
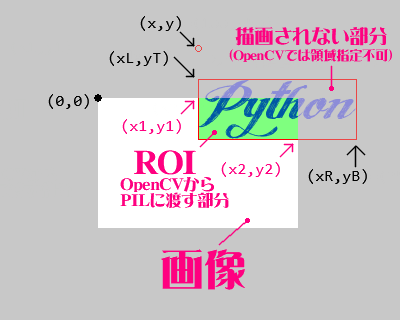
戻り値は(left, top, right, bottom)。我がソースコードの中ではxL, yT, xR, yBという変数に格納している。
ImageDraw.multiline_textbbox() という関数もあるのだが、 ImageDraw.textbbox() でも普通に複数行の文字列のバウンディングボックスを取得できており、違いはよくわからない。
そもそもテキスト描画関数にも ImageDraw.text() と ImageDraw.multiline_text() があって、前者も複数行に対応しているんだよなあ。うーん。

この部分のソースコード
from PIL import Image, ImageDraw, ImageFont
WHITE = (255,255,255)
RED = (255,0,0)
BLUE = (0,0,255)
font = "ANGELTEARS-trial.ttf" # ANGEL TEARS trial
size = 100
fontPIL = ImageFont.truetype(font=font, size=size)
x, y = 20, 20
text = "Black\nJack"
imgPIL = Image.new("RGB", (200, 200), WHITE)
draw = ImageDraw.Draw(imgPIL)
draw.text(xy=(x,y), text=text, fill=BLUE, font=fontPIL)
draw.ellipse(xy=[(x-3,y-3), (x+3,y+3)], outline=RED)
x1, y1, x2, y2 = draw.textbbox((x,y), text, fontPIL)
draw.rectangle([(x1,y1), (x2,y2)], outline=RED)
imgPIL.show()
タイポグラフィを学ぶ
アンカーについて
ImageDraw.textsize() にはなくて ImageDraw.textbbox() では必要になったxyについて調べた。
xyは正確にはアンカーの座標。 ImageDraw.text() のxyも同様。
私は知らなかったのだが、ImageDraw.text() では指定したxyがテキストの左上なのか右下なのか中央なのかを指定できるのだ。ただし複数行のテキストでは不可。
アンカーは公式サイト(ここ)で示された指定の仕方をする。
で、このアンカーを、 ImageDraw.textbbox() でも指定できるというわけ。
一方、従来の ImageDraw.textsize() ではアンカーを指定できないので ImageDraw.text() で左上以外のアンカーを指定したときに詰んでしまう。
下の画像は ImageDraw.textbbox() でアンカーを None、"lt"、"ms"、"rb" と指定したもの。

この部分のソースコード
from PIL import Image, ImageDraw, ImageFont
WHITE = (255,255,255)
RED = (255,0,0)
BLUE = (0,0,255)
font = "ANGELTEARS-trial.ttf" # ANGEL TEARS trial
size = 100
fontPIL = ImageFont.truetype(font=font, size=size)
text = "Python"
imgPIL = Image.new("RGB", (400, 400), WHITE)
draw = ImageDraw.Draw(imgPIL)
for i, anchor in enumerate([None, "lt", "ms", "rb"]):
x, y = 200, 20+120*i
draw.text(xy=(x,y), text=text, fill=BLUE, font=fontPIL, anchor=anchor)
draw.ellipse(xy=[(x-3,y-3), (x+3,y+3)], outline=RED)
x1, y1, x2, y2 = draw.textbbox((x,y), text, fontPIL, anchor=anchor)
draw.rectangle([(x1,y1), (x2,y2)], outline=RED)
imgPIL.show()
アセンダーについて
アンカーのデフォルト値は"la"。lはレフトを、aはアセンダーを意味する。
aやxの文字の高さ(エックスハイト)よりも上の部分のことだ。
下画像はWikipediaより。

え? だったら、この結果はおかしくないですか?
y基準はアセンダーなのに、文字が描画されているのは基準高さよりずっと下になっている。
どこか間違ってる?

ベースラインを求める
具体的な文字列は無くとも、フォントとフォントサイズを指定してやればこれらの値は決まるはず。
実際、PILでは次のように算出することができる。
ここで得られるascentは定義通りのアセンダーではなくベースラインからの高さでエックスハイトを含む数字。エックスハイトを求めることはできないが、デザイン上この数値が必要となることはないとの判断だろう。
from PIL import ImageFont
ascent, descent = ImageFont.FreeTypeFont(font, size).getmetrics()
これを使って、さまざまなフォントでベースラインとアセンダーとディセンダーを求めてみた。

正しくベースラインを求めることができた。つまり、特に間違っているところはなく「フォントの作成者がそのようにアセンダーとディセンダーを設定した」というのが真相のようだ。
この部分のソースコード
from PIL import Image, ImageDraw, ImageFont
WHITE = (255,255,255)
RED = (255,0,0)
GREEN = (0,255,0)
BLUE = (0,0,255)
dics = [{"font":"ANGELTEARS-trial.ttf", "size":100}, # ANGEL TEARS trial
{"font":"Inkfree.ttf", "size":50}, # Ink Free
{"font":"timesbd.ttf", "size":50}, # Times New Roman 太字
{"font":"CONSTAN.TTF", "size":50}, # Constantia 標準
]
texts = ["ace", "key", "Japan"]
imgPIL = Image.new("RGB", (400, 400), WHITE)
draw = ImageDraw.Draw(imgPIL)
y = 20
for dic in dics:
font = dic["font"]
size = dic["size"]
fontPIL = ImageFont.truetype(font, size)
ascent, descent = ImageFont.FreeTypeFont(font, size).getmetrics()
x = 20
for text in texts:
draw.text(xy=(x,y), text=text, fill=BLUE, font=fontPIL)
draw.ellipse(xy=[(x-3,y-3),(x+3,y+3)], outline=RED)
x1, y1, x2, y2 = draw.textbbox((x,y), text, fontPIL)
draw.rectangle([(x1,y1), (x2,y2)], outline=RED)
draw.line([(x1,y),(x2,y)], GREEN, 1)
draw.line([(x1,y+ascent),(x2,y+ascent)], GREEN, 3)
draw.line([(x1,y+ascent+descent),(x2,y+ascent+descent)], GREEN, 1)
x += 100
y += ascent + descent + 30
imgPIL.show()
OpenCV画像に日本語フォントを描画する関数への適用
以上の変化点を我が関数に織り込んでいけばよい。
アンカーの実装
今回、PILのテキスト描画にアンカーの指定があることを知った。そこで我が関数でもアンカーを実装することにした。
ただし従来の引数modeはそのままとする。ここを変更すると我が関数をコピペして使ってくれている人が困ってしまうからだ。
それにしても、modeの値によってテキスト描画する座標を指定した座標から修正する部分を
offset_x = [0, 0, text_w//2]
offset_y = [text_h, 0, text_h//2]
x0 = x - offset_x[mode]
y0 = y - offset_y[mode]
としたのは技巧が先走っていていま見直すとなんとも恥ずかしい。自分で読み返して何をしているのか分からなかったほどだ。
ここは素直に
if mode == 0:
offset_x, offset_y = 0, text_h
elif mode == 1:
offset_x, offset_y = 0, 0
elif mode == 2:
offset_x, offset_y = text_w//2, text_h//2
x0 = x - offset_x
y0 = y - offset_y
という表記にした上で改造を進めた。
これまでの苦労でどうしてもベースライン基準を追加したかったので頑張って実装した。複数行のテキストではアンカーを指定できないというPILの仕様を超え、複数行であっても最下行のベースラインを指定できるようにしている。
modeとanchorで異なる値が指定されていたら? それはソースコードを読み解いてください。
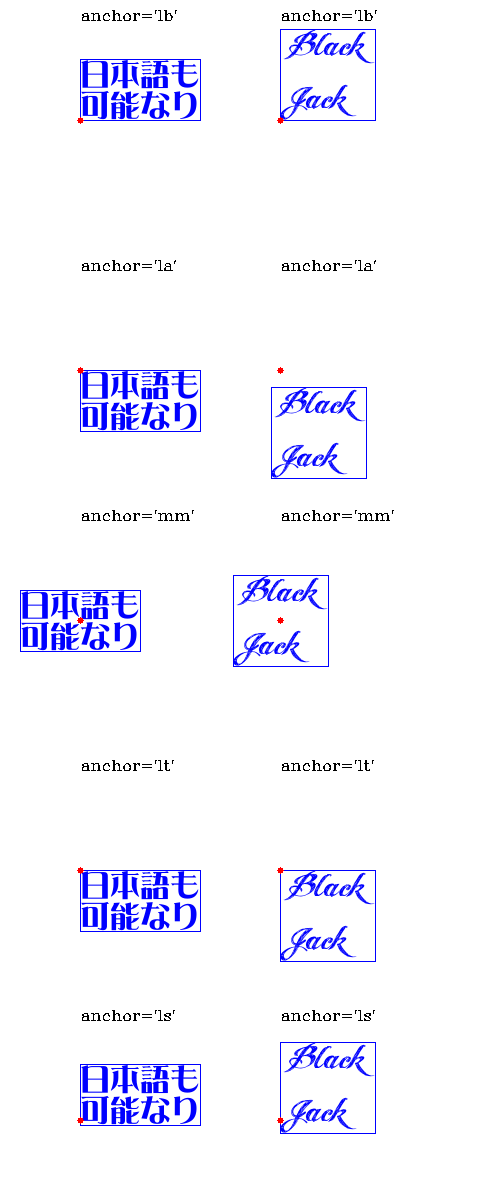
| mode | anchor | 挙動 |
|---|---|---|
| 指定なし | 指定なし | mode=0と同 |
| 0 | "lb"(left bottom) | cv2.PutText()と同様、左下基準 |
| 1 | "la"(left ascender) | ImageDraw.text()と同様、左・アセンダー基準 |
| 2 | "mm"(middle middle) | 中央基準 |
| 3 | "lt"(left top) | 【新】左上基準 |
| 4 | "ls"(left baseline) | 【新】左・ベースライン基準 |
ROIの取得
OpenCVからPILに変換する部分を画像全体ではなくテキスト描画域のみにすることで処理速度向上を図っているのが我が関数の特徴。私が考えついたわけではないけど。
ImageDraw.textsize() はテキストボックスのサイズを返していた。
ImageDraw.textbbox() はバウンディングボックスの左上座標と右下座標を返してくれる。
この仕様の差および私のレベルアップにより、ROIの取得をよりシンプルにおこなえるようになった。
ソースコード
サンプルプログラム付き。
import numpy as np
import cv2
from PIL import Image, ImageDraw, ImageFont
def cv2_putText(img, text, org, fontFace, fontScale, color, mode=None, anchor=None):
"""
mode:
0:left bottom, 1:left ascender, 2:middle middle,
3:left top, 4:left baseline
anchor:
lb:left bottom, la:left ascender, mm: middle middle,
lt:left top, ls:left baseline
"""
# テキスト描画域を取得
x, y = org
fontPIL = ImageFont.truetype(font = fontFace, size = fontScale)
dummy_draw = ImageDraw.Draw(Image.new("L", (0,0)))
xL, yT, xR, yB = dummy_draw.multiline_textbbox((x, y), text, font=fontPIL)
# modeおよびanchorによる座標の変換
img_h, img_w = img.shape[:2]
if mode is None and anchor is None:
offset_x, offset_y = xL - x, yB - y
elif mode == 0 or anchor == "lb":
offset_x, offset_y = xL - x, yB - y
elif mode == 1 or anchor == "la":
offset_x, offset_y = 0, 0
elif mode == 2 or anchor == "mm":
offset_x, offset_y = (xR + xL)//2 - x, (yB + yT)//2 - y
elif mode == 3 or anchor == "lt":
offset_x, offset_y = xL - x, yT - y
elif mode == 4 or anchor == "ls":
_, descent = ImageFont.FreeTypeFont(fontFace, fontScale).getmetrics()
offset_x, offset_y = xL - x, yB - y - descent
x0, y0 = x - offset_x, y - offset_y
xL, yT = xL - offset_x, yT - offset_y
xR, yB = xR - offset_x, yB - offset_y
# バウンディングボックスを描画 不要ならコメントアウトする
cv2.rectangle(img, (xL,yT), (xR,yB), color, 1)
# 画面外なら何もしない
if xR<=0 or xL>=img_w or yB<=0 or yT>=img_h:
print("out of bounds")
return img
# ROIを取得する
x1, y1 = max([xL, 0]), max([yT, 0])
x2, y2 = min([xR, img_w]), min([yB, img_h])
roi = img[y1:y2, x1:x2]
# ROIをPIL化してテキスト描画しCV2に戻る
roiPIL = Image.fromarray(roi)
draw = ImageDraw.Draw(roiPIL)
draw.text((x0-x1, y0-y1), text, color, fontPIL)
roi = np.array(roiPIL, dtype=np.uint8)
img[y1:y2, x1:x2] = roi
return img
def main():
img = np.full((1200,500,3), (255,255,255), dtype=np.uint8)
dics = [{"font":"DFLGS9.TTC", "size":30, "text":"日本語も\n可能なり"}, # DF麗雅宋
{"font":"ANGELTEARS-trial.ttf", "size":60, "text":"Black\nJack"}, # ANGEL TEARS trial
]
x = 80
for dic in (dics):
y = 120
font = dic["font"]
size = dic["size"]
text = dic["text"]
for anchor in (["lb", "la", "mm", "lt", "ls"]):
img = cv2_putText(img, text, (x,y), font, size, (255,0,0), anchor=anchor)
cv2.circle(img, (x,y), 3, (0,0,255), -1)
cv2.putText(img, f"anchor='{anchor}'", (x,y-100), cv2.FONT_HERSHEY_COMPLEX, 0.5, (0,0,0), 1)
y += 250
x += 200
cv2.imshow("", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
今回のサンプル。もちろん画面外への対応もなされている。
終わりに
PySimpleGUIやstreamlitが使えるようになっても、一つの巨大なキャンバスのどの座標に何を配置してという昔ながらのデザイン手法の手軽さを忘れることはできない。
自分のために作った関数だが、多くの人に活用していただけると嬉しいです。