はじめに
本記事では、
・宿泊旅行統計の非整形データをETLで統一
・都道府県別に稼働率×変動リスク×需給比を可視化
・“回復しているように見える市場”の構造的違いを整理しました。
分析編(何が分かったか/どう解釈できるか) と 技術編(どうやってデータを作ったか) を意図的に分けた構成にしております。
(分析の話と実装・設計の話は、混ぜると紛らわしくなるため分離しました)
コード一式(Notebook・ETLコード)は以下に置いています。
前半:分析編(何が分かったか/どう解釈できるか)
1. 目的
コロナ禍前後で、ホテルの需給動向はどのように変化したのか。
また、その回復は「需要が戻った」という事実だけで説明できるのか、それとも
需給構造や市場特性の違いによって、回復の“見え方(指標上の回復)”に差が生じているのか。
本記事では、国土交通省(観光庁)の 「宿泊旅行統計調査」 を用いて、
都道府県別にホテル市場の回復状況を「構造的に整理」することを目的としました。
単に「回復している/していない」を判定するのではなく、
- 稼働率の水準(どの程度の稼働を維持しているか)
- 需要の変動リスク(稼働率のブレの大きさ)
- 供給規模との関係(供給の厚みを踏まえた見え方)
といった観点から、回復の背後にある市場構造の違いを可視化することを狙いとしています。
2. 背景
この分析の出発点は、単なるデータ分析の練習ではありません。
ホテルの不動産鑑定評価や不動産投資判断において、
収益還元法で将来キャッシュフロー(CF)を見立てる際には、
- 稼働率はどこまで回復すると想定できるのか
- その回復は一時的な反動なのか、構造的に持続しうるものなのか
といった点について、エリア特性を踏まえた説明が求められます。
しかし、
「全国平均では回復している」「観光需要が戻ってきている」
といったマクロな議論だけでは、個別エリアのCFリスクや安定性を評価するには不十分です。
そこで本記事では、宿泊旅行統計という公的データを用いながら、
- 回復状況のばらつき
- 需給構造の違い
- 将来CFの振れやすさを示唆する要素
を整理し、将来キャッシュフローを検討する際の補助的な判断材料を得ることを背景目的としています。
なお、本分析は将来CFを直接予測したり、投資判断を断定するものではありません。
あくまで、
エリアごとの回復構造とリスク特性を整理し、実務上の検討材料を増やすための一つの視点
として位置づけています。
3. 分析結果
3-1. 全国平均:月次稼働率の回復軌跡
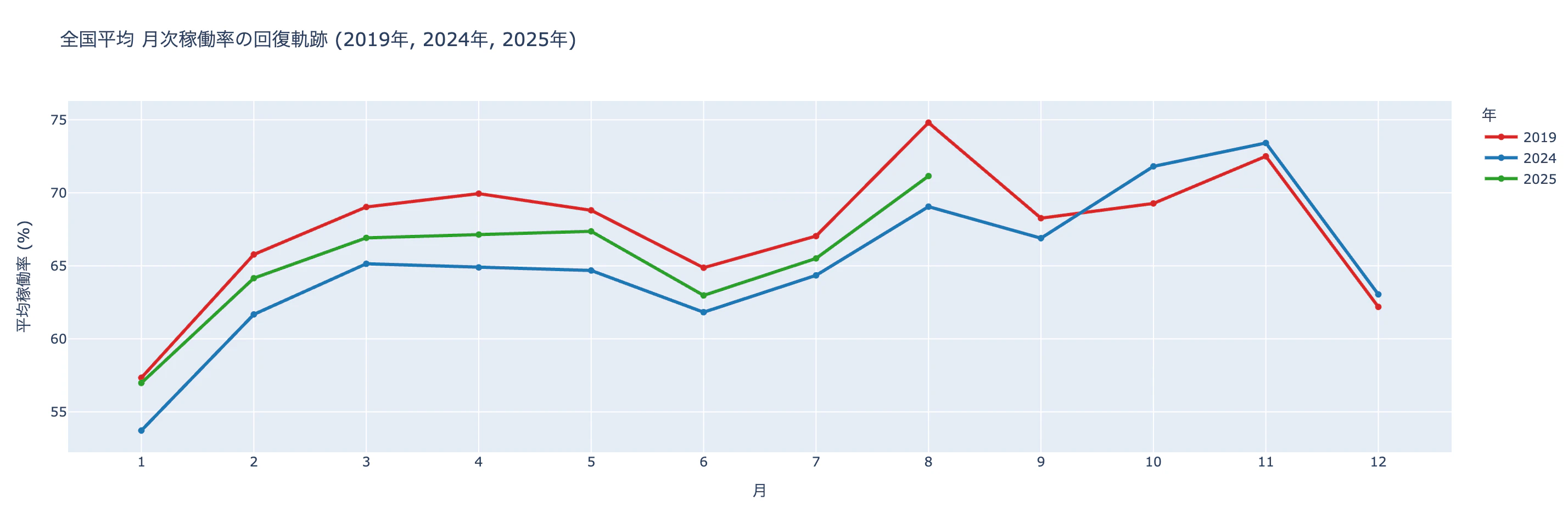
全国平均で見る限り、直近の稼働率水準は2019年と近い水準まで回復しつつあるように見えます。
ただし、この回復が
- 地域別に均質なのか
- 市場構造の違いを無視して「回復した」と言えるのか
は別問題です。そこで以降は、都道府県別に構造を分解して確認します。
3-2. 都道府県別:稼働率 2019年比 回復度ランキング
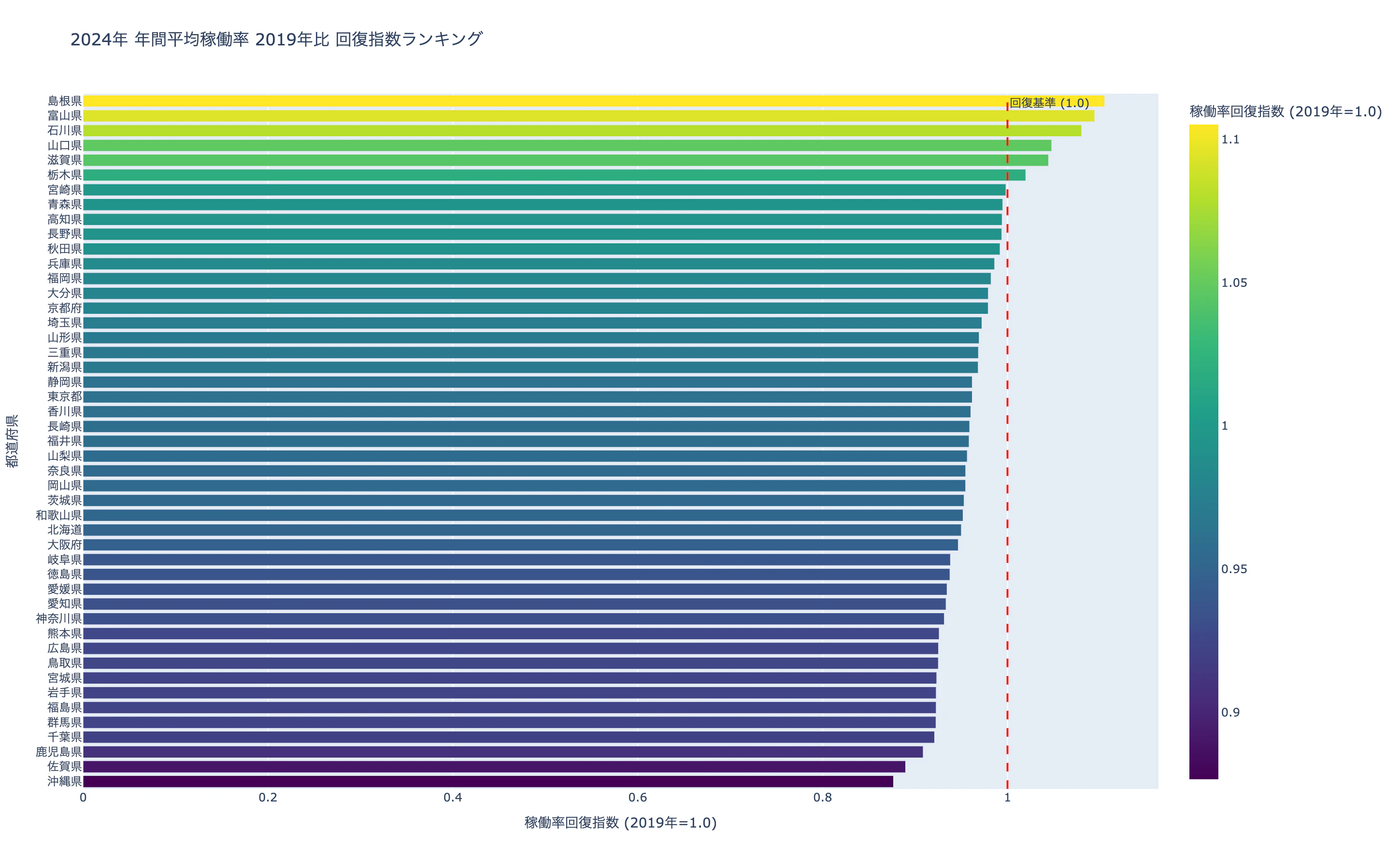
これは、2024年度の年間平均稼働率を2019年度と比較し、
都道府県別に「稼働率回復指数」として算出・ランキング化したものです。
稼働率回復指数 = 2024年度稼働率 ÷ 2019年度稼働率
この図を見ると、上位に地方県が多く含まれていることが分かります。
一方で、大都市圏を含む一部の県では、依然として2019年水準を下回る地域も見られます。
回復指数と市場構造の関係(簡易的な傾向整理)
稼働率回復指数の高低によって都道府県を2グループに分け、
2024年時点の市場特性を比較しました。
集計結果(上位10県 vs 下位10県)
| グループ | 平均稼働率 (%) | 平均変動係数 | 平均施設数 |
|---|---|---|---|
| 回復指数 高(上位10) | 65.0 | 0.19 | 1,148 |
| 回復指数 低(下位10) | 62.9 | 0.19 | 1,633 |
傾向として読み取れること
傾向①:回復指数が高い地域は、稼働率水準もやや高い
回復指数が高いグループでは、2024年の平均稼働率が 65.0% と、
回復指数が低いグループ(62.9%)をやや上回っています。
ただし差は限定的であり、「稼働率が高い=必ず回復指数も高い」と言い切れるほどではありません。
傾向②:変動リスク(季節性)の差は小さい
月次稼働率の変動係数(CV)は両グループとも 平均0.19程度 とほぼ同水準でした。
このため、本指標だけで「回復が進むほど不安定」「回復が遅いほど安定」と結論づけることは難しく、
少なくとも本指標単体ではリスク優劣は明確ではないと言えます。
傾向③:回復指数が高い地域は、供給規模が比較的小さい傾向
平均施設数は、回復指数 高:1,148件、回復指数 低:1,633件 でした。
この差は、供給規模が比較的小さい地域ほど、需要回復が稼働率に反映されやすい(=回復指数が上がりやすい)可能性を示唆します。
ただし、個別地域の事情(観光政策、イベント、宿泊形態の違いなど)を直接説明するものではありません。
3-3. 地域構造セグメンテーション(稼働率 × 変動リスク)

- 縦軸:2024年度 年間平均稼働率(%)
- 横軸:月次稼働率 変動係数(リスク)
- 色:インバウンド依存度
- バブルサイズ:2024年度 需給比(延べ宿泊者数 ÷ 施設数)
この図は、都道府県別に「回復の水準」と「回復のリスク構造」を同時に見える化したものです。
本分析は因果関係を断定するものではありませんが、少なくとも次の点が示唆されます。
- 稼働率が高く見える市場であっても、月次変動が大きい地域では 将来CFのブレが大きくなりやすい
- 需給比が小さい地域では、稼働率が一定水準に見えても 供給過多リスクを内包している可能性がある
- 需給比が比較的高く、稼働率と変動リスクのバランスが取れている地域は、相対的にCFの安定性を見込みやすい可能性がある
このことから、
「回復しているかどうか」だけでなく、
「どのようなリスク構造のもとで回復しているか」
を整理する視点が、将来キャッシュフローを検討する際の補助的な判断材料になり得ると考えられます。
4. 指標設計の考え方
4-1. 外国人比率(インバウンド依存度)
各都道府県における 延べ宿泊者数に占める外国人宿泊者の割合です。
- インバウンド需要への依存度を測るための指標
- 為替・国際情勢・政策変更など、市場外要因の影響を受けやすい需要構造を把握する目的
👉 外国人比率が高い市場ほど、回復が速く見える局面があっても、外部ショックにより変動しやすい可能性があります。
4-2. 需給比
各都道府県における 施設数に対する延べ宿泊者数です。
- 需給バランスを測るための指標
👉 需給比が高い市場ほど、施設数に対する延べ宿泊者が多く、市場が緩い可能性があることを示しています。
4-3. 稼働率 2019年比(回復指数)
2024年の年間平均稼働率 ÷ 2019年の年間平均稼働率。
- コロナ禍前を基準とした 回復度合いの相対比較
- 絶対水準ではなく、「どこまで戻ったか」を見るための指標
👉 単年の稼働率だけではなく、回復の相対比較を目的にしています。
4-4. リスク指標(変動係数:CV)
月次稼働率の 平均に対するばらつき(変動の大きさ) を示す指標として、変動係数(CV)を採用しました。
risk_metrics = (
df_monthly_for_structural.groupby("pref_name")["occ"]
.agg(std="std", mean="mean")
.reset_index()
)
risk_metrics["cv"] = risk_metrics["std"] / risk_metrics["mean"]
- 季節性やイベント依存度の強さを反映しやすい
- 年間平均だけでは見えない キャッシュフローのブレ を補足する意図
👉 「高稼働=安全」ではない、という判断軸を明示的に分析へ組み込みました。
5. 課題(分析編):限界と未対応領域(3本立て)
本分析は、ホテル市場の回復状況を構造的に把握するための基礎分析であり、
意思決定に用いるには、いくつかの制約と未対応領域があります。
5-1. 統計データ起因の限界(観測できない要素)
公的統計で取得可能なデータのみを用いているため、以下は直接観測できません。
- 人件費高騰・人手不足による 意図的な稼働抑制(売り止め・営業日調整)
- ADR / RevPAR 等の価格指標を含めていない
- 都道府県単位であり、市区町村・観光地別の粒度ではない
そのため、
統計上は「回復していない」ように見えても、
実務的には収益性を確保した健全運営をしている
ケースを取りこぼす可能性があります。
👉 鑑定評価・投資判断に使う場合は、他指標との併用が前提です。
5-2. クラスタリング未実施による構造把握の限界
本分析は、稼働率・リスク・供給規模等を 可視化・比較 していますが、
都道府県を統計的に意味のあるグループへ自動分類する クラスタリング(k-means 等) は未実施です。
- 「どの県とどの県が構造的に似た市場か」
- 「解釈ベースの分類が統計的に妥当か」
は、分析者の解釈に依存する部分が残ります。
👉 今後、複数指標を用いたクラスタリングにより、地域類型の客観性を高める余地があります。
5-3. 時系列予測を行っていない(将来CFへの接続)
本分析は、2019年と2024年の比較、および月次変動の評価が中心であり、
- SARIMA / Prophet 等による将来の宿泊者数・稼働率予測
- トレンドと季節性の分離
までは踏み込んでいません。
👉 将来キャッシュフローへ直接つなげるには、時系列モデルでの補完が有効と考えられます。
後半:技術編(どうやってデータを作ったか)
6. 技術スタック
- Python(pandas / numpy)
- Plotly
- Google Colab
7. ETL設計(目指すべき姿)
今回の分析でまず必要だったのは、
「年をまたいで比較可能な形に宿泊旅行統計を整形すること」でした。
やりたかったこと自体はシンプルで、以下の情報を
都道府県 × 年月単位で縦持ち(long形式) に揃えることです。
- 年月
- 都道府県
- 延べ宿泊者数(日本人/外国人)
- 稼働率
- 施設数
最終的には、
「どの年の、どの月に、どの都道府県で、
どれくらい宿泊され、どれくらい稼働していたのか」
を、機械的に集計・比較できる状態を目指しました。
<整形前データ構造(横持ち)>

↓
<整形後データ構造イメージ(縦持ち)>

データ加工のステップ
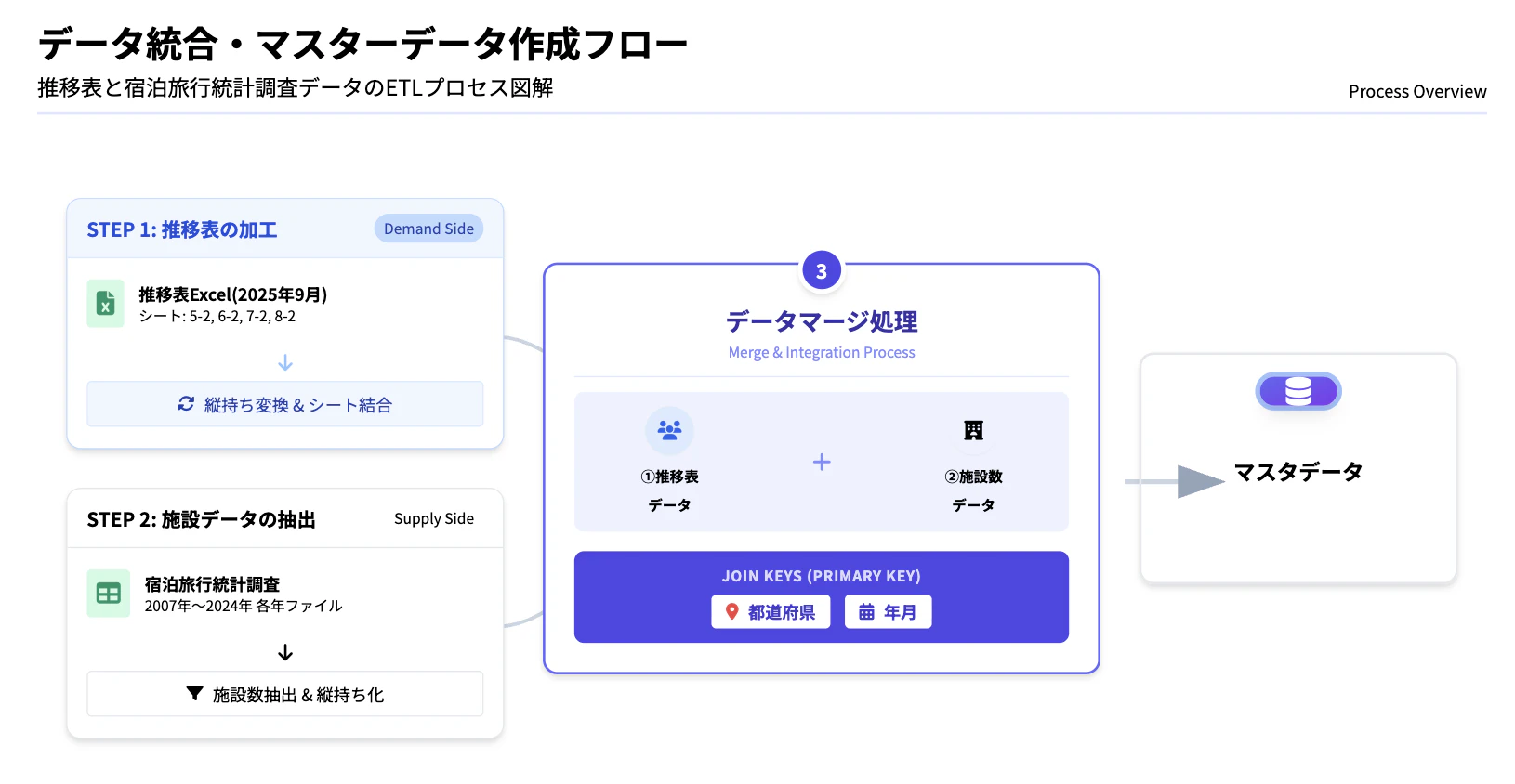
① 推移表データ(需要サイド)の縦持ち化・統合
宿泊旅行統計の「推移表」に含まれる、以下の月次時系列シートを対象に処理を行いました。
-
対象シート:
5-2: 都道府県別 延べ宿泊者数(従業者数10人以上の施設)推移表(月別)
6-2: 都道府県別 日本人延べ宿泊者数(従業者数10人以上の施設)推移表(月別)
7-2: 都道府県別 外国人延べ宿泊者数(従業者数10人以上の施設)推移表(月別)
8-2: 都道府県別・宿泊施設タイプ別 客室稼働率(従業者数10人以上の施設)推移表(月別) -
加工内容:
形式変換: 都道府県 × 月が横持ち(wide形式)で構成されているデータを、都道府県 × 年月単位の縦持ち(long形式)に変換。 -
指標の整形: 各指標(延べ宿泊者数、日本人/外国人宿泊者数、稼働率)ごとに整形を実施。
-
データ結合: 「年月」と「都道府県」をキーとして結合し、需要サイドの時系列データを作成。
② 施設数データ(供給サイド)の時系列化
推移表には施設数(供給サイド)の時系列データが含まれていないため、宿泊旅行統計調査の各年別Excelファイル(2007〜2024年)を別途利用しました。
-
課題: 年度ごとにシート構成が異なり、表の開始行や表記が統一されていない。
-
対応: コードによって年度ごとの差異を吸収し、各年・各月の施設数を抽出。
-
加工内容:
都道府県 × 年月単位の縦持ちデータに統合し、供給サイドの時系列データを作成。
③ 需要・供給データの統合
上記プロセスで作成した2つのデータを統合し、分析の基盤となるデータセットを構築しました。
-
マージ手法:① 需要サイドの時系列データ + ② 供給サイドの時系列データ
-
結合キー:「都道府県 × 年月」
成果物:分析に用いる最終的なマスターデータを作成。
8. データの問題点(なぜ手作業が破綻するか)
e-Statから一括DLした宿泊旅行統計(2007〜2024年)を開くと、
すぐに「これは手作業では無理だ」と分かります。
- 年ごとにExcelファイルが分かれており、ファイル名が統一されていない

- シート構成が年度ごとに微妙に異なる(表の数が違う等)
画像は2024のものですが、最も古い2007年のデータだと第5表までしかありません

- 表の開始行が年によって違う
- 「参考第1表」など、分析対象ではない表が混在
- 和暦・西暦が混在
- 列名・表記に全角/半角のゆれがある
2007〜2024年の 18年分 を扱う以上、
「今年は例外だから手で直す」
を繰り返す構造は、早々に破綻すると判断しました。
9. 戦略(例外を潰すのではなく、例外を飲み込む)
方針は以下です。
例外を個別対応するのではなく、
例外があっても最終的に同じ形に着地するパイプラインを作る
具体的には、
- Excelファイルは
globで一括取得 - シート名は 正規表現+正規化(NFKC) によって探索
- 年情報はファイル名・シート内セルから自動抽出(和暦→西暦変換)
- 行開始位置のズレは、固定位置前提にせず条件判定で吸収
- すべてDataFrameに落としてから結合
- 最終的に wide → long 変換して統一スキーマへ
9-1. 実装のキモ①:分析対象シートを機械的に探す
import unicodedata
def normalize(s):
return unicodedata.normalize("NFKC", s)
def find_first_table_sheet(sheet_names):
"""
シート名から「第1表」を含み、かつ「参考」を含まないものを探索
"""
normalized = [normalize(x) for x in sheet_names]
for raw, norm in zip(sheet_names, normalized):
if ("第1表" in norm) and ("参考" not in norm):
return raw
return sheet_names[0] if sheet_names else None
9-2. 実装のキモ②:和暦/西暦が混在する年情報を吸収する
import re
def parse_jp_year_to_ad(cell):
if not isinstance(cell, str):
return None
if "平成" in cell:
num = re.sub(r"\D", "", cell)
return 1988 + int(num) if num else None
if "令和" in cell:
num = re.sub(r"\D", "", cell)
return 2018 + int(num) if num else None
if re.match(r"^\d{4}$", cell.strip()):
return int(cell.strip())
return None
👉 年が取れない場合は無理に補完せず、スキップする方針にしています。
9-3. 実装のキモ③:宿泊統計特有の wide 表を long 形式へ変換
import pandas as pd
def wide_pref_to_long(df_wide, value_col_name):
year_row = df_wide.iloc[0]
month_row = df_wide.iloc[1]
current_year = None
cols = []
for col in year_row.index:
y = parse_jp_year_to_ad(str(year_row[col]))
if y:
current_year = y
cell = month_row[col]
if isinstance(cell, str) and "月" in cell and current_year:
month = int(cell.replace("月", "").strip())
cols.append((col, current_year, month))
data = df_wide.rename(columns={df_wide.columns[0]: "pref"})
data = data[data["pref"].astype(str).str.match(r"^\d{2}", na=False)]
data["pref_code"] = data["pref"].astype(str).str[:2].astype(int)
data["pref_name"] = data["pref"].astype(str).str[2:]
rows = []
for col, year, month in cols:
tmp = data[["pref_code", "pref_name", col]].copy()
tmp = tmp.rename(columns={col: value_col_name})
tmp["year"] = year
tmp["month"] = month
rows.append(tmp)
return pd.concat(rows, ignore_index=True) if rows else pd.DataFrame()
学び:手作業を捨てた瞬間から楽になった
最初は「今年だけ例外だから…」と手で直そうとしましたが、
それをやめた瞬間に、設計が一気にシンプルになりました。
- 例外を潰すより、例外を飲み込む構造を作る
- データを疑い、コードで一貫性を担保する
- 「全部まとめて流し込める形」を先に設計する
この考え方は、公的統計やレガシーな業務データにも
汎用性が高いと感じています。
10. 技術編の課題と今後の拡張余地
本記事では、年をまたいだ分析が可能な
ETLパイプラインの構築までを扱いました。
一方で、実務や継続運用を考えると技術的にはまだ未完成です。
10-1. Power BI 等によるダッシュボード構築
現状のアウトプットは Notebook 上の可視化が中心であり、
意思決定者が触れる形での提供には課題があります。
課題
- Notebook は分析者向けで、非エンジニアには扱いづらい
- 年度・地域・指標を横断的に確認しづらい
次のステップ案
- 整形済みデータを Star Schema 化
- Power BI / Looker Studio による インタラクティブ分析
- 投資・鑑定用途を想定した シナリオ比較ビュー
10-2. API連携によるデータ更新・集計の自動化
現状は、e-Stat の Excel 一括DLを前提としており、
データ更新が手動です。
課題
- 新しい月次データの追加が手動
- 再実行コストが高く、定期更新に向かない
次のステップ案
- e-Stat API による自動取得
- 年月指定での差分更新
- ETL → 集計 → 可視化 の自動実行
10-3. 外部データとの連携(為替・気温・訪日外客統計など)
宿泊旅行統計だけでは、
需要変動の「要因」までは説明しきれません。
課題
- 要因分析に踏み込めていない
- インバウンド依存や季節性の背景がブラックボックス
次のステップ案
- 為替(円安・円高)
- 気温・降雪量(季節性の説明)
- 訪日外客数統計(インバウンドの精緻化)
おわりに
本記事では、
- 分析として何が言えるか
- そのためにどんなデータ設計が必要だったか
を意図的に分けて整理しました。
結果そのものよりも、
どう考え、どこで詰まり、どう直したか
が、同じように
非整形な公的データと向き合う人の参考になれば幸いです。