はじめに
VoltDBの機能にはkafkaのメッセージをインポート/エクスポートする以下の機能があるので試してみます。
以下、インポート・エクスポートの簡単な機能説明です。
・インポート
kafkaの任意のTopicのメッセージが配信されると、VoltDBのプロシージャを呼び出し、任意のテーブルにメッセージを挿入・更新することができます。メッセージとテーブルは1対1だけではなく、1つのメッセージを2つのテーブルに分割して格納することもできます。
インポートは、ファイル、HTTP、Hadoop(WebHDFS)、JDBC、Kafka、RabbitMQ、ElasticSearchに対応します。
・エクスポート
VoltDB上のストリーム(仮想のテーブルのようなもの)にレコードを挿入すると、kafkaの任意のTopicのメッセージを配信します。
エクスポートは、Kafka、Kinesis、CSV/TSVに対応します。
VoltDBからkafkaへエクスポートして、kafka streamsでストリーム処理してVoltDBにインポートしたら楽しそう!(やらないけど。いや、そのうちやるかも・・・)
VoltDBが超高速なのでストリーム処理と相性が良さそうです。
インポートについては、kafka connectのVoltDB用connectorでも同様のことができるようです。
今回使用した環境
・CentOS 7
・VoltDB 8.2
・kafka 2.0.0
インポートを試してみる
事前準備(VoltDBへテーブルを作成)
VoltDBに対して、事前にインポート用のTEST_DATAテーブルを以下のDDLで作成。
また、TEST_DATAテーブルへインサートするプロシージャInsertDataを作成しVoltDBへロードしています。
CREATE TABLE TEST_DATA (
NAME varchar(50) NOT NULL,
DATA smallint,
UNIQUE (NAME),
PRIMARY KEY (NAME)
);
PARTITION TABLE TEST_DATA ON COLUMN NAME;
package test;
import org.voltdb.SQLStmt;
import org.voltdb.VoltProcedure;
import org.voltdb.VoltTable;
public class InsertData extends VoltProcedure {
public final SQLStmt insertData = new SQLStmt("insert into test_data values(?, ?)");
public VoltTable[] run(String name, int data) {
voltQueueSQL(insertData, name, data);
VoltTable[] results = voltExecuteSQL();
return results;
}
}
VoltDBにインポート設定を追加
VoltDBの設定ファイル(deployment.xml)には以下のインポート用の設定を追記します。
「type="kafka"」でkafkaからインポートするように指定。
brokersは192.168.10.121:9092、インポート用のTopic名は"TEST_DATA"、
procedureはインポート時に使用するVoltDBのプロシージャを指定。
<import>
<configuration type="kafka" format="csv" enabled="true">
<property name="brokers">192.168.10.121:9092</property>
<property name="topics">TEST_DATA</property>
<property name="procedure">InsertData</property>
</configuration>
</import>
Kafkaインポータは、指定されたKafkaメッセージングサービスに接続し、1つ以上のKafkaトピックをインポートし、そのレコードをVoltDBデータベースに書き込みます。 データは指定された形式(デフォルトではカンマ区切り値(CSV))に従ってデコードされ、指定されたストアドプロシージャを使用してVoltDBデータベースに挿入されます。
kafkaのTopicを作成
VoltDBへインポートするTopicをkafkaに作成します。
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 2 --topic TEST_DATA
# bin/kafka-console-producer.sh --broker-list 192.168.10.121:9092 --topic TEST_DATA
Topicへメッセージを配信
先ほど作成した"TEST_DATA"のトピックへ対してメッセージを配信します。
以下では「test01,100」のCSVデータを配信しています。
# bin/kafka-console-producer.sh --broker-list 192.168.10.121:9092 --topic TEST_DATA
>test01,100
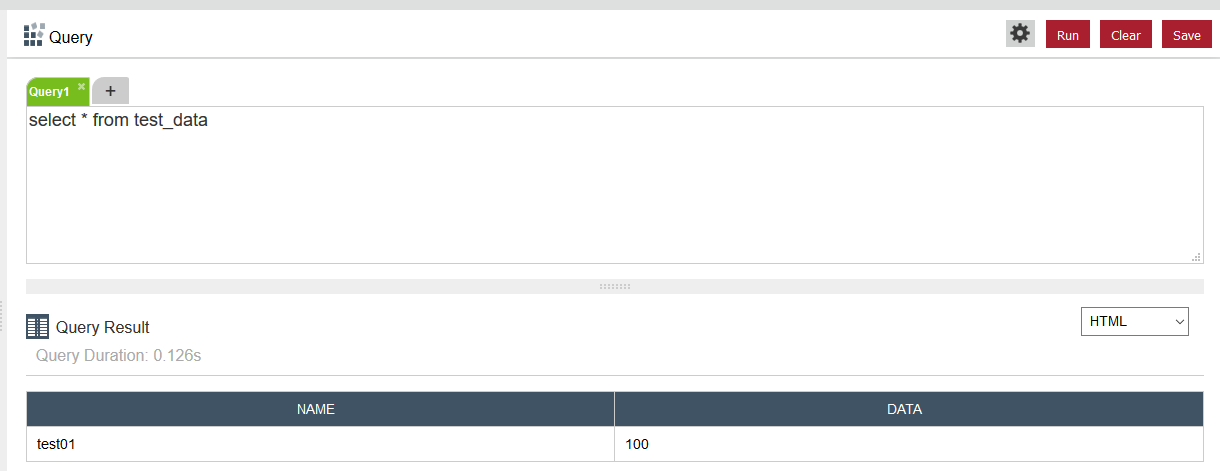
VoltDBへインポートされたことを確認
実行前は0レコードです。

kafkaへメッセージを配信すると、TEST_DATAテーブルのレコード数(Row Count)が1になっています。

「select * from test_data」のSQLを実行すると、kafkaに送信したデータが入っている!!!!
ちなみにインポート機能を利用すると、Importerというタブが追加され、トランザクション量などのグラフが表示されました。
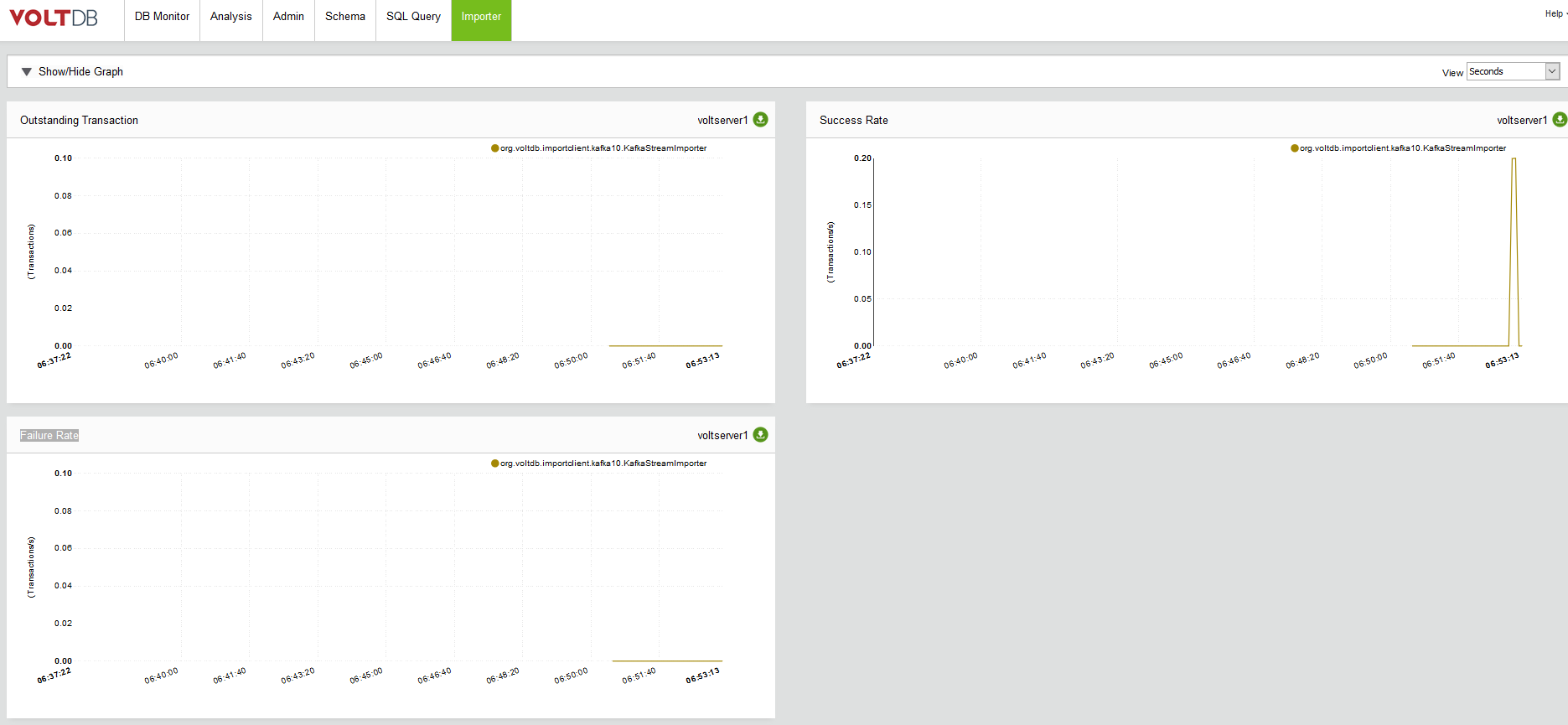
以下の3つのグラフが表示されています。
・Outstanding Transaction(Transactions)
・Success Rate(Transactions/s)
・Failure Rate(Transactions/s)
なんと、ここまでで設定以外はInsertのプロシージャしかプログラミングしていません。
エクスポート
VoltDBからのエクスポートは設定ファイルに基づき、VoltDBの起動時に自動で開始されます。
また、「voltadmin update」コマンドで設定ファイルを更新することで、起動中のVoltDBのエクスポートを開始・停止することもできます。
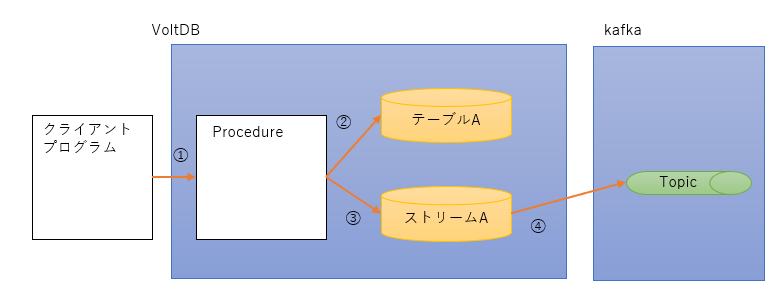
処理の概念は上図のとおりです。
① クライアントからInsert用のProcedureを呼び出す。
② Procedureが受信したデータをテーブルへInsertする。
③ 受信したデータをStreamにも流す。
④ Streamに入ったデータをVoltDBが非同期にkafkaへ配信する。
以下、公式サイトのエクスポートの説明を翻訳(一部意訳)したものです。
エクスポートは非同期です。 エクスポート対象のデータの実際の配信は、データ転送を開始するトランザクションとは非同期です。
非同期アプローチの利点は、エクスポートされたデータを相手側システムに配信する際の遅延がVoltDBデータベースのパフォーマンスに影響を及ぼさないことです。 欠点は、VoltDBがエクスポートデータをキューイングして処理するため、相手側への送信が保留されていることです。これはシステム障害時の耐久性の確保も含まれます。このタスクはVoltDBサーバープロセスによって自動的に処理されます。
エクスポートターゲットへの処理が追いつかず、データキューがいっぱいになると、VoltDBはエクスポートバッファ内のオーバーフローデータをディスクに書き出します。
相手先に継続して到達できない場合、またはデータフローに追いつけない場合は、ディスクに書き込むことで、宛先が追いつくのを待つ間にVoltDBの過剰なメモリ消費を避けることができます。
データベースが停止している場合、エクスポートデータはセッション間で保持されます。 データベースが再始動すると、コネクターはオーバーフロー・データを取り出し、エクスポート・キューに再挿入します。
それでは実際にエクスポートを試してみます。
まず、Streamを作成します。テーブル作成とほとんど同じですね。
ただし、テーブルではないので主キーやインデックスは必要ありません。
カラムは元のテーブルTEST_DATAと同じにしていますが、サブセットでも構いません。
CREATE STREAM TEST_DATA_STREAM
EXPORT TO TARGET archive (
NAME varchar(50) NOT NULL,
DATA smallint
);
次にVoltDBの設定ファイルにエクスポートの設定を追加します。
<export>
<configuration enabled="true" target="archive" type="kafka">
<property name="bootstrap.servers">192.168.10.121:9092</property>
<property name="acks">1</property>
<property name="topic.key">TEST_DATA_STREAM.TEST_DATA_EXPORT</property>
</configuration>
</export>
「topic.key」だけ分かりにくいのですが、
ストリーム名.テーブル名
で指定します。
kafkaのTopicを作成
エクスポート先のkaftのTopicとして、"TEST_DATA_EXPORT"を作成しています。VoltDBの設定ファイルに指定したTopic名を使用します。
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 2 --topic TEST_DATA_EXPORT
次に「kafka-console-consumer.sh」を使って、先ほど作成した"TEST_DATA_EXPORT"のTopicのメッセージを購読します。
# bin/kafka-console-consumer.sh --bootstrap-server 192.168.10.121:9092 --from-beginning --topic TEST_DATA_EXPORT
以下のSQLでエクスポート対象のストリームに対して、3つのデータを投入しています。
ストリームはテーブルではないのですが、テーブルと同様にSQLを利用できます。
本当は、プロシージャで処理するのですが、ここでは簡単にSQLで実行しています。
insert into test_data_stream values('test100', 100)
insert into test_data_stream values('test101', 101)
insert into test_data_stream values('test102', 102)
すると、エクスポート先のTopicに3つのデータが配信されたことを確認できます。
# bin/kafka-console-consumer.sh --bootstrap-server 192.168.10.121:9092 --from-beginning --topic TEST_DATA_EXPORT
"3619631923363842","1535666920335","0","2","8589934592","1","test100","100"
"3619631923396610","1535667258494","1","2","8589934592","1","test101","101"
"3619631923429378","1535667308716","2","2","8589934592","1","test102","102"
エクスポートデータは、公式サイトに以下のような説明がありました。
エクスポートデータは、kafkaにカンマ区切り値(CSV)形式の文字列として送信されます。 このメッセージには、6つのメタデータ列(トランザクションIDやタイムスタンプなど)と、エクスポートストリームの列値が続きます。
6つのメタデータ列については、具体的な仕様は公式サイトに記載されていませんでした。
2列目は「1535666920335-> 2018-08-31T07:08:40」でしたので実行日時のようです。
おわりに
・プログラムをほとんど書かずに、kafkaとインメモリデータベース(VoltDB)との間でデータのインポート・エクスポートが実現できました。
・kafkaとVoltDBの両方が超高速なので、kafka streamsを組み合わせると面白そうです。