はじめに
Kafka Streamsは、kafka用のストリーム処理ライブラリです。
kafkaに配信されたメッセージを連続的に読み込み、任意の処理を実行して出力することができます。
例えば、時間ごとのメッセージの集計(合計、平均とか)など簡単に実行することができます。
このような処理はバッチ処理でも実行できますが、ストリーム処理で行えばミリ秒単位では無理ですが、バッチよりも短い時間で結果を返すことができます。
こんなストリーム処理を実行してみる
実際に使ってみないとなかなか理解できないので、実際に動かしてみました。
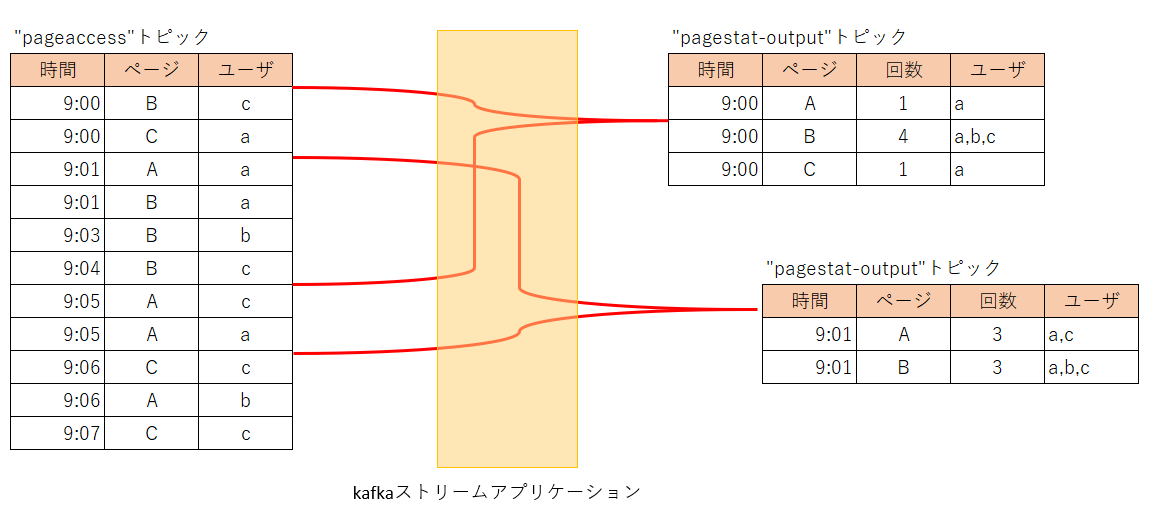
Webサイトに訪問したユーザが表示したページとユーザ数、ユーザ名の一覧を1分間隔で5分間分を集計するストリーム処理を作ってみます。
以下のように、9:00~9:04が集計され、次に9:01~9:05が集計されます。
Kafka Streamsは初めてなので、以下を改造して作成します。
Streams APIはkafka 1.0.0から変更されたのですが、以下のサンプルプログラムはそれ以前のバージョンで作成されているので、Streams API 1.0.0にあわせて一部修正(KStreamBuilderではなくStreamsBuilderを使用する等)しています。
kafka-streams-stockstats
https://github.com/gwenshap/kafka-streams-stockstats
pom.xml修正
pom.xmlを修正し、kafka-clients、kafka-streams、gsonを追加します。
gsonはデータ読み書き時のシリアライズ、デシリアライズで使用します。
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.2.2</version>
</dependency>
Pageクラス
サイトへのユーザの1件分のアクセス情報を保持するクラスです。
ページ名称、ユーザ名、アクセス日時を持ちます。
kafkaのメッセージがPageのインスタンスに変換されます。
package sample.model;
import java.time.LocalDateTime;
public class Page {
private String pageName;
private String user;
private LocalDateTime date;
public Page(String pageName, String user, LocalDateTime date) {
this.pageName = pageName;
this.user = user;
this.date = date;
}
@Override
public String toString() {
return "Page{" +
"pageName='" + pageName + '\'' +
", user=" + user + '\'' +
", date=" + date + '\'' +
'}';
}
public String getPageName() {
return pageName;
}
public void setPageName(String pageName) {
this.pageName = pageName;
}
public String getUser() {
return user;
}
public void setUser(String user) {
this.user = user;
}
public LocalDateTime getDate() {
return date;
}
public void setDate(LocalDateTime date) {
this.date = date;
}
}
集計結果を格納するPageStatsクラス。
package sample.model;
import java.util.HashSet;
import java.util.Set;
public class PageStats {
private String pageName;
private int count;
private Set<String> userSet = new HashSet<String>();
public PageStats add(Page page) {
this.pageName = page.getPageName();
this.count++;
userSet.add(page.getUser());
return this;
}
public PageStats compute() {
return this;
}
}
メインクラス
メインクラスの「PageStatsExample.java」を作成します。
まず、Streamsのプロパティを定義します。
独自のタイムウィンドウを用いるため、「DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG」を指定しています。これを指定しないと、各メッセージのタイムスタンプはkafkaにメッセージが届いた日時が用いられます。今回はサイトへの訪問日時をメッセージの中に含め、その時間を用いて集計するため、独自の「DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG」を指定します。
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "pagestat");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.10.122:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, PageSerde.class.getName());
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(StreamsConfig.DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG, CustomTimestampExtractor.class);
StreamsBuilderのインスタンスを生成し、"pageaccess"トピックを入力とするストリームを定義します。
key=Stringクラス、valueがPageクラス(独自)になっています。
StreamsBuilder builder = new StreamsBuilder();
KStream<String, Page> source = builder.stream("pageaccess");
次にストリームトポロジ(ストリーム内の処理の流れ)を構築します。
ざっくり説明すると以下の処理を定義しています。
".windowedBy(TimeWindows.of(300000).advanceBy(60000))"で5分間の集計を1分間隔で実施することを定義。
".aggregate"でメッセージ受信時の集計方法を指定。
"PageStats::new"はタイムウィンドウ内の初期化で、PageStatsクラスで5分ごとに集計したデータを保持しています。
"(k, v, pagestats) -> pagestats.add(v)"で集計するメソッド(add)を適用しています。
"stats.to("pagestat-output""で結果を書き込むトピックを指定しています。
KStream<PageWindow, PageStats> stats = source
.groupByKey()
.windowedBy(TimeWindows.of(300000).advanceBy(60000))
.aggregate(
PageStats::new,
(k, v, pagestats) -> pagestats.add(v),
Materialized.<String, PageStats, WindowStore<Bytes, byte[]>>as("serde")
.withValueSerde(new PageStatsSerde()))
.toStream((key, value) -> new PageWindow(key.key(), key.window().start()))
.mapValues((page) -> page.computeAvgPrice());
stats.to("pagestat-output",
Produced.with(new PageWindowSerde(), new PageStatsSerde()));
作成すると、後はmainメソッドのあるJavaアプリケーションですので、メインクラスを指定して実行するだけです。
CustomTimestampExtractorクラス
タイムウィンドウの日付を管理するクラスです。
Pageインスタンスのタイムスタンプの値をエポックミリ秒で返すように作っています。
独自にこのようなクラスを作成しない場合は、自動でkafkaから受信した日時がストリーム処理で使用されます。
package sample;
import java.time.ZoneOffset;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.streams.processor.TimestampExtractor;
import sample.model.Page;
public class CustomTimestampExtractor implements TimestampExtractor {
@Override
public long extract(ConsumerRecord<Object, Object> record, long timestamp) {
if (record != null && record.value() != null) {
if (record.value() instanceof Page) {
Page value = (Page) record.value();
return value.getDate().toEpochSecond(ZoneOffset.ofHours(9)) * 1000;
}
}
return timestamp;
}
}
実行
「kafka-console-consumer.sh」を使用して、結果が出力されるpagestat-outputトピックを購読します。
bin/kafka-console-consumer.sh --topic pagestat-output --from-beginning --bootstrap-server 192.168.10.122:9092 --property print.key=true
出力結果は以下のとおりです。
ページとタイムスタンプがキー
{"pageName":"C","timestamp":1536364800000}
となり、
値に合計数とユーザ一覧
{"pageName":"C","count":1,"userSet":["a"]}
が表示されていることが分かります。
9:00と9:01が最初に図で示した計算どおりの件数になっています。
※出力順等は見やすいように整形しています。
# 1536364800000 -> 2018年09月08日 09時00分00秒 000
{"pageName":"C","timestamp":1536364800000} {"pageName":"C","count":1,"userSet":["a"]}
{"pageName":"A","timestamp":1536364800000} {"pageName":"A","count":1,"userSet":["a"]}
{"pageName":"B","timestamp":1536364800000} {"pageName":"B","count":4,"userSet":["c","a","b"]}
# 1536364860000 -> 2018年09月08日 09時01分00秒 000
{"pageName":"B","timestamp":1536364860000} {"pageName":"B","count":3,"userSet":["a","b","c"]}
{"pageName":"A","timestamp":1536364860000} {"pageName":"A","count":3,"userSet":["a","c"]}
ソース
最後に省略していた残りのソースを載せておきます。
package sample;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.common.utils.Bytes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.Materialized;
import org.apache.kafka.streams.kstream.Produced;
import org.apache.kafka.streams.kstream.TimeWindows;
import org.apache.kafka.streams.state.WindowStore;
import sample.model.Page;
import sample.model.PageStats;
import sample.model.PageWindow;
import sample.serde.JsonDeserializer;
import sample.serde.JsonSerializer;
import sample.serde.WrapperSerde;
public class PageStatsExample {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "pagestat");// StreamsアプリのIDを指定する。
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.10.122:9092"); // 接続先のkafkaブローカを指定する
// シリアライズ・デシリアライズするSerdeを指定する。KEYはデフォルトのStringを用いる。
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
// Valueはサイトのアクセス情報を持つクラス(Pageクラス:後述)の独自Serdeを指定する。
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, PageSerde.class.getName());
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(StreamsConfig.DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG, CustomTimestampExtractor.class);
// StreamsBuilderのインスタンスを生成し、"pageaccess"トピックを入力とするストリームを定義します。
// key=Stringクラス、valueがPageクラス(独自)になっています。
StreamsBuilder builder = new StreamsBuilder();
KStream<String, Page> source = builder.stream("pageaccess");
KStream<PageWindow, PageStats> stats = source
.groupByKey()
.windowedBy(TimeWindows.of(300000).advanceBy(60000))
.aggregate(
PageStats::new,
(k, v, pagestats) -> pagestats.add(v),
Materialized.<String, PageStats, WindowStore<Bytes, byte[]>>as("serde")
.withValueSerde(new PageStatsSerde()))
.toStream((key, value) -> new PageWindow(key.key(), key.window().start()))
.mapValues((page) -> page.compute());
stats.to("pagestat-output",
Produced.with(new PageWindowSerde(), new PageStatsSerde()));
KafkaStreams streams = new KafkaStreams(builder.build(), props);
//streams.cleanUp();
streams.start();
// 通常はストリームアプリケーションがずっと実行されているはず
// この例では、入力データは有限なので、しばらく実行して停止します。
Thread.sleep(120000L);
streams.close();
}
static public final class PageSerde extends WrapperSerde<Page> {
public PageSerde() {
super(new JsonSerializer<Page>(), new JsonDeserializer<Page>(Page.class));
}
}
static public final class PageStatsSerde extends WrapperSerde<PageStats> {
public PageStatsSerde() {
super(new JsonSerializer<PageStats>(), new JsonDeserializer<PageStats>(PageStats.class));
}
}
static public final class PageWindowSerde extends WrapperSerde<PageWindow> {
public PageWindowSerde() {
super(new JsonSerializer<PageWindow>(), new JsonDeserializer<PageWindow>(PageWindow.class));
}
}
}
package sample.model;
public class PageWindow {
String pageName;
long timestamp;
public PageWindow(String pageName, long timestamp) {
this.pageName = pageName;
this.timestamp = timestamp;
}
}
以降は流用元と同じ。
package sample.serde;
import java.util.Map;
import org.apache.kafka.common.serialization.Deserializer;
import com.google.gson.Gson;
public class JsonDeserializer<T> implements Deserializer<T> {
private Gson gson = new Gson();
private Class<T> deserializedClass;
public JsonDeserializer(Class<T> deserializedClass) {
this.deserializedClass = deserializedClass;
}
public JsonDeserializer() {
}
@Override
@SuppressWarnings("unchecked")
public void configure(Map<String, ?> map, boolean b) {
if(deserializedClass == null) {
deserializedClass = (Class<T>) map.get("serializedClass");
}
}
@Override
public T deserialize(String s, byte[] bytes) {
if(bytes == null){
return null;
}
return gson.fromJson(new String(bytes),deserializedClass);
}
@Override
public void close() {
}
}
package sample.serde;
import java.nio.charset.Charset;
import java.util.Map;
import org.apache.kafka.common.serialization.Serializer;
import com.google.gson.Gson;
public class JsonSerializer<T> implements Serializer<T> {
private Gson gson = new Gson();
@Override
public void configure(Map<String, ?> map, boolean b) {
}
@Override
public byte[] serialize(String topic, T t) {
return gson.toJson(t).getBytes(Charset.forName("UTF-8"));
}
@Override
public void close() {
}
}
package sample.serde;
import java.util.Map;
import org.apache.kafka.common.serialization.Deserializer;
import org.apache.kafka.common.serialization.Serde;
import org.apache.kafka.common.serialization.Serializer;
public class WrapperSerde<T> implements Serde<T> {
final private Serializer<T> serializer;
final private Deserializer<T> deserializer;
public WrapperSerde(Serializer<T> serializer, Deserializer<T> deserializer) {
this.serializer = serializer;
this.deserializer = deserializer;
}
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
serializer.configure(configs, isKey);
deserializer.configure(configs, isKey);
}
@Override
public void close() {
serializer.close();
deserializer.close();
}
@Override
public Serializer<T> serializer() {
return serializer;
}
@Override
public Deserializer<T> deserializer() {
return deserializer;
}
}