概要
サーバーレスアプリケーションでレスポンスが遅い?AWS X-RayとLambdaの組み合わせでボトルネックを可視化し、効率的に問題を特定・解決する方法を実践的に解説します。分散トレーシングの基本から具体的な改善手法まで、実際の事例を交えて紹介します。
目次
- はじめに
- AWS X-Rayとは
- Lambda関数でのX-Ray有効化
- パフォーマンスボトルネックの特定方法
- よくあるボトルネックパターンと対処法
- アラートとモニタリングの自動化
- 終わりに
1. はじめに
サーバーレスアプリケーションが普及する中、「なぜレスポンスが遅いのか」「どこでエラーが発生しているのか」といった疑問に直面することが増えています。従来のモノリシックなアプリケーションとは異なり、サーバーレスアプリケーションは複数のサービスが連携して動作するため、問題の特定が困難になりがちです。
例えば、API Gateway → Lambda → DynamoDB → 外部APIという流れでデータを処理するアプリケーションを考えてみましょう。全体の処理時間が5秒かかっているとして、どのコンポーネントがボトルネックになっているかを特定するのは容易ではありません。
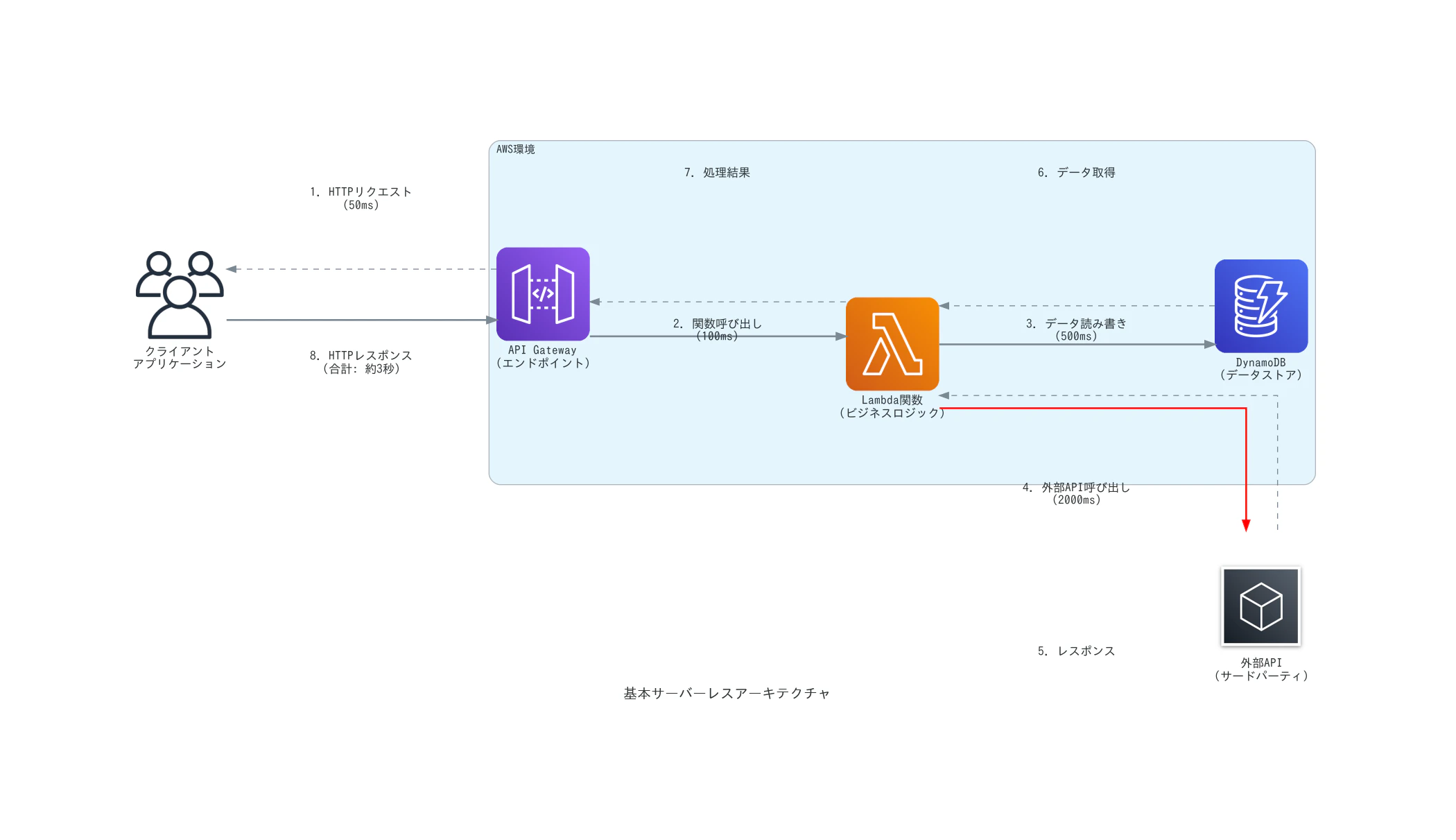
こうした課題を解決するのがAWS X-Rayです。AWS X-Ray を使用して、アプリケーションのコンポーネントの視覚化、パフォーマンスのボトルネックの特定、およびエラーの原因となったリクエストのトラブルシューティングを行うことができます。
本記事では、AWS X-RayとLambdaを組み合わせて、サーバーレスアプリケーションのパフォーマンス問題を効率的に特定・解決する実践的な方法を解説します。
2. AWS X-Rayとは
2.1 分散トレーシングの基本概念
AWS X-Rayは、アプリケーションから AWS のサービス や外部ウェブ API への各接続の詳細なトレースマップとレイテンシー情報を提供します。分散トレーシングとは、複数のサービスにまたがるリクエストの処理過程を追跡し、可視化する技術です。
身近な例で説明すると、宅配便の追跡システムのようなものです。荷物が発送されてから配達されるまでの各拠点での処理時間や状況を確認できるように、X-Rayはリクエストが各AWSサービスでどの程度の時間を要したかを詳細に記録します。
2.2 X-Rayの主要コンポーネント
X-Rayは以下の主要コンポーネントで構成されています:
| コンポーネント | 説明 | 役割 |
|---|---|---|
| トレース | 1つのリクエストの全体的な処理過程 | リクエストの全体像を把握 |
| セグメント | 各サービスでの処理単位 | 個別サービスの処理時間を記録 |
| サブセグメント | セグメント内の詳細な処理単位 | より細かい処理の内訳を記録 |
| サービスマップ | アプリケーション全体の構成図 | サービス間の依存関係を視覚化 |
分散アプリケーションの場合、X-Ray は、同一のトレース ID を含むリクエストを処理するすべてのサービスのノードを、単一のサービスグラフに組み合わせます。
2.3 X-Rayの料金体系
X-Rayの料金は以下のように構成されています(2024年1月時点):
- 記録されたトレース: 100万トレースあたり5.00USD
- 取得されたトレース: 100万トレースあたり0.50USD
- スキャンされたトレース: 100万トレースあたり0.50USD
毎月最初の100,000トレースは無料で利用できるため、小規模なアプリケーションであれば追加料金なしで使用できます。
3. Lambda関数でのX-Ray有効化
3.1 Lambda関数でのX-Ray設定
Lambda関数でX-Rayを有効化する方法は複数あります。最も簡単な方法はAWSコンソールから設定することです。
3.1.1 AWSコンソールでの設定
- Lambda関数の設定画面を開く
- 「Configuration」タブ → 「Monitoring and operations tools」を選択
- 「Active tracing」を有効化
3.1.2 AWS CLIでの設定
aws lambda update-function-configuration \
--function-name my-function \
--tracing-config Mode=Active
3.1.3 CloudFormationでの設定
MyLambdaFunction:
Type: AWS::Lambda::Function
Properties:
FunctionName: my-function
Runtime: python3.9
Handler: index.handler
Code:
ZipFile: |
def handler(event, context):
return {"statusCode": 200, "body": "Hello World"}
TracingConfig:
Mode: Active
3.2 X-Ray SDKの活用
Lambda関数内でより詳細なトレーシングを行うには、X-Ray SDKを使用します。
3.2.1 Pythonでの実装例
import json
import boto3
from aws_xray_sdk.core import xray_recorder
from aws_xray_sdk.core import patch_all
# AWS SDKの自動パッチ
patch_all()
@xray_recorder.capture('lambda_handler')
def lambda_handler(event, context):
# DynamoDBクライアントの初期化
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('my-table')
# カスタムサブセグメントの作成
with xray_recorder.in_subsegment('database_operation'):
response = table.get_item(Key={'id': event['id']})
# 外部API呼び出し
with xray_recorder.in_subsegment('external_api_call'):
# 外部API呼び出しの処理
pass
return {
'statusCode': 200,
'body': json.dumps(response)
}
3.3 API Gatewayとの連携
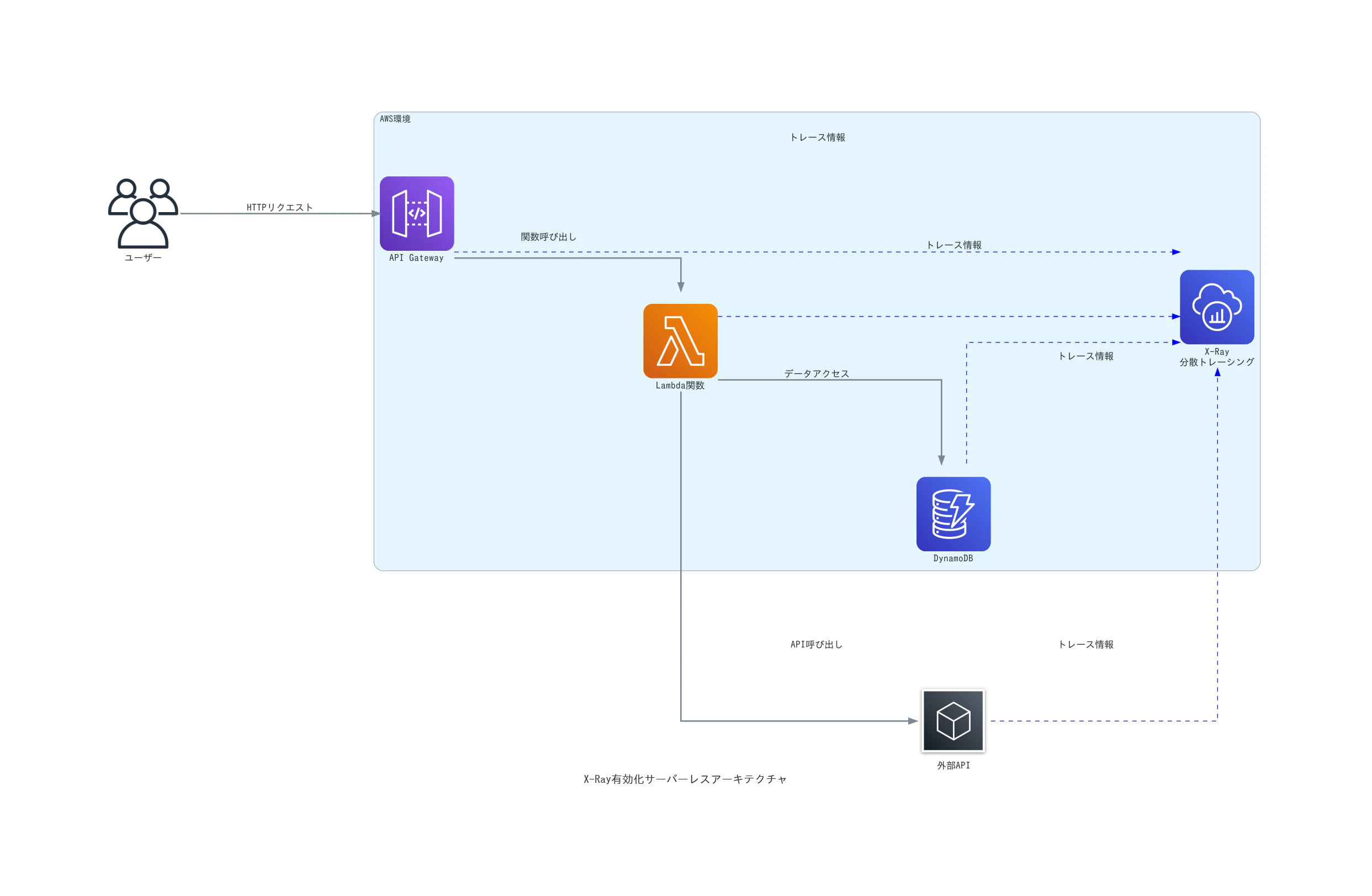
マイクロサービスアーキテクチャでよく使われるAPI GatewayとLambdaの組み合わせでは、両方でX-Rayを有効化することで、エンドツーエンドのトレーシングが可能になります。
3.3.1 API GatewayでのX-Ray有効化
API Gateway にデプロイされ...選択します。そこで、[Logs/Tracing] タブへ移動して、[Enable X-Ray Tracing] を選択して [Save Changes] をクリックすることで、X-Ray 追跡を有効にすることができます。
4. パフォーマンスボトルネックの特定方法
4.1 サービスマップの読み方
X-Rayコンソールのサービスマップは、アプリケーションの全体像を把握するための重要なツールです。各ノードの色と数値が示す意味を理解することで、効率的に問題を特定できます。
4.1.1 ノードの色分け
| 色 | 意味 | 対応が必要な状況 |
|---|---|---|
| 緑 | 正常 | 特に問題なし |
| 黄 | 警告(レスポンス時間が遅い) | パフォーマンスチューニング検討 |
| 赤 | エラー発生 | 緊急対応が必要 |
4.1.2 レスポンス時間の分析
より詳細なリクエスト毎の詳細なセグメントの所要時間は、トレース結果の [ID] を選択すると以下のように確認ができます。
具体的には以下の項目を確認します:
- AWS::Lambda: Lambda関数の起点となる実行環境
- AWS::Lambda::Function: 実際のLambda関数の処理時間
- AWS::DynamoDB: DynamoDB操作の処理時間
- Remote: 外部API呼び出しの処理時間
4.2 トレースの詳細分析
個別のトレースを詳細に分析することで、具体的なボトルネックを特定できます。
4.2.1 セグメントの階層構造
AWS::Lambda (総処理時間: 3.2秒)
├── AWS::Lambda::Function (関数実行時間: 2.8秒)
│ ├── DynamoDB操作 (0.5秒)
│ ├── 外部API呼び出し (2.0秒) ← ボトルネック
│ └── レスポンス生成 (0.3秒)
└── Lambda初期化 (0.4秒)
この例では、外部API呼び出しが全体の処理時間の約60%を占めており、明確なボトルネックとなっています。
4.2.2 エラーの特定
X-Rayはエラーの種類も詳細に記録します:
- スロットリングエラー: DynamoDBやAPI Gatewayの制限に達した場合
- タイムアウトエラー: Lambda関数の実行時間制限に達した場合
- 認証エラー: IAM権限の問題
- リソースエラー: 外部サービスの一時的な障害
4.3 パフォーマンスメトリクスの活用
X-Rayは以下のメトリクスを提供します:
| メトリクス | 説明 | 活用方法 |
|---|---|---|
| Response Time | 平均応答時間 | 全体的なパフォーマンス把握 |
| Throughput | 秒間処理件数 | 処理能力の評価 |
| Error Rate | エラー発生率 | サービスの安定性評価 |
5. よくあるボトルネックパターンと対処法
5.1 Lambda関数のコールドスタート問題
5.1.1 問題の特定
X-Rayのトレースで初期化セグメントが長時間(数秒)続く場合、コールドスタートが発生している可能性があります。
# 問題のあるコード例
import boto3
import pandas as pd # 重いライブラリ
def lambda_handler(event, context):
# 毎回新しいクライアントを作成
dynamodb = boto3.resource('dynamodb')
# 処理...
5.1.2 対処法
# 改善されたコード例
import boto3
import json
# グローバルスコープで初期化
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('my-table')
def lambda_handler(event, context):
# 既に初期化されたクライアントを使用
response = table.get_item(Key={'id': event['id']})
return {
'statusCode': 200,
'body': json.dumps(response, default=str)
}
さらに、Provisioned Concurrencyを使用することで、コールドスタートを完全に回避できます:
aws lambda put-provisioned-concurrency-config \
--function-name my-function \
--provisioned-concurrency-config AllocatedConcurrency=10
5.2 DynamoDB性能問題
5.2.1 問題の特定
DynamoDBセグメントで以下のような問題が観察される場合:
- レスポンス時間の増加: 100ms以上の応答時間
- スロットリングエラー: ProvisionedThroughputExceededException
- ホットパーティション: 特定のパーティションキーに負荷集中
5.2.2 対処法
パーティションキーの分散
# 問題のあるアクセスパターン
def get_user_data(user_id):
response = table.get_item(Key={'user_id': user_id})
return response
# 改善されたアクセスパターン
def get_user_data(user_id):
# パーティションキーにタイムスタンプを追加
partition_key = f"{user_id}#{datetime.now().strftime('%Y%m%d')}"
response = table.get_item(Key={'partition_key': partition_key})
return response
バッチ処理の活用
# 単発での処理(非効率)
def process_items(item_ids):
results = []
for item_id in item_ids:
response = table.get_item(Key={'id': item_id})
results.append(response)
return results
# バッチ処理(効率的)
def process_items_batch(item_ids):
request_items = {
'my-table': {
'Keys': [{'id': item_id} for item_id in item_ids]
}
}
response = dynamodb.batch_get_item(RequestItems=request_items)
return response
5.3 外部API呼び出しの最適化
5.3.1 問題の特定
外部APIセグメントで以下のような問題が観察される場合:
- 長いレスポンス時間: 2秒以上の応答時間
- タイムアウトエラー: 外部サービスの応答遅延
- レート制限: 外部APIの呼び出し制限に達している
5.3.2 対処法
接続プールの使用
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
# セッションの設定(グローバルスコープ)
session = requests.Session()
retry_strategy = Retry(
total=3,
backoff_factor=1,
status_forcelist=[429, 500, 502, 503, 504],
)
adapter = HTTPAdapter(max_retries=retry_strategy, pool_connections=20, pool_maxsize=20)
session.mount("http://", adapter)
session.mount("https://", adapter)
@xray_recorder.capture('external_api_call')
def call_external_api(url, data):
response = session.post(url, json=data, timeout=5)
return response.json()
非同期処理の活用
import asyncio
import aiohttp
async def call_external_apis(urls):
async with aiohttp.ClientSession() as session:
tasks = []
for url in urls:
tasks.append(fetch_data(session, url))
results = await asyncio.gather(*tasks)
return results
async def fetch_data(session, url):
async with session.get(url) as response:
return await response.json()
5.4 メモリ不足問題
5.4.1 問題の特定
Lambda関数のメモリ使用量が設定値に近づくと、以下のような問題が発生します:
- 処理速度の低下: ガベージコレクションの頻発
- メモリ不足エラー: OutOfMemoryError
- 実行時間の増加: スワップ処理の発生
5.4.2 対処法
メモリ設定の最適化
# 現在のメモリ使用量を確認
aws logs filter-log-events \
--log-group-name /aws/lambda/my-function \
--filter-pattern "REPORT" \
--limit 10
# メモリ設定の変更
aws lambda update-function-configuration \
--function-name my-function \
--memory-size 1024
効率的なデータ処理
# メモリ効率の悪いコード
def process_large_dataset(data):
# 全データをメモリに読み込み
processed_data = []
for item in data:
processed_item = heavy_processing(item)
processed_data.append(processed_item)
return processed_data
# メモリ効率の良いコード
def process_large_dataset_efficient(data):
# ジェネレータを使用してメモリ使用量を抑制
for item in data:
yield heavy_processing(item)
6. アラートとモニタリングの自動化
6.1 CloudWatchアラームの設定
X-Rayメトリクスを基にしたアラームを設定することで、問題の早期発見が可能になります。
6.1.1 レスポンス時間のアラーム
aws cloudwatch put-metric-alarm \
--alarm-name "Lambda-High-Response-Time" \
--alarm-description "Lambda function response time is too high" \
--metric-name ResponseTime \
--namespace AWS/X-Ray \
--statistic Average \
--period 300 \
--threshold 2.0 \
--comparison-operator GreaterThanThreshold \
--evaluation-periods 2 \
--alarm-actions arn:aws:sns:region:account:alert-topic
6.1.2 エラー率のアラーム
aws cloudwatch put-metric-alarm \
--alarm-name "Lambda-High-Error-Rate" \
--alarm-description "Lambda function error rate is too high" \
--metric-name ErrorRate \
--namespace AWS/X-Ray \
--statistic Average \
--period 300 \
--threshold 0.05 \
--comparison-operator GreaterThanThreshold \
--evaluation-periods 1 \
--alarm-actions arn:aws:sns:region:account:alert-topic
6.2 カスタムメトリクスの作成
より詳細な監視のために、カスタムメトリクスを作成できます。
import boto3
from aws_xray_sdk.core import xray_recorder
cloudwatch = boto3.client('cloudwatch')
@xray_recorder.capture('custom_metric_handler')
def lambda_handler(event, context):
start_time = time.time()
try:
# 処理の実行
result = process_data(event)
# 成功メトリクス
cloudwatch.put_metric_data(
Namespace='MyApplication',
MetricData=[
{
'MetricName': 'ProcessingSuccess',
'Value': 1,
'Unit': 'Count'
}
]
)
return result
except Exception as e:
# エラーメトリクス
cloudwatch.put_metric_data(
Namespace='MyApplication',
MetricData=[
{
'MetricName': 'ProcessingError',
'Value': 1,
'Unit': 'Count',
'Dimensions': [
{
'Name': 'ErrorType',
'Value': type(e).__name__
}
]
}
]
)
raise
finally:
# 処理時間メトリクス
processing_time = time.time() - start_time
cloudwatch.put_metric_data(
Namespace='MyApplication',
MetricData=[
{
'MetricName': 'ProcessingTime',
'Value': processing_time,
'Unit': 'Seconds'
}
]
)
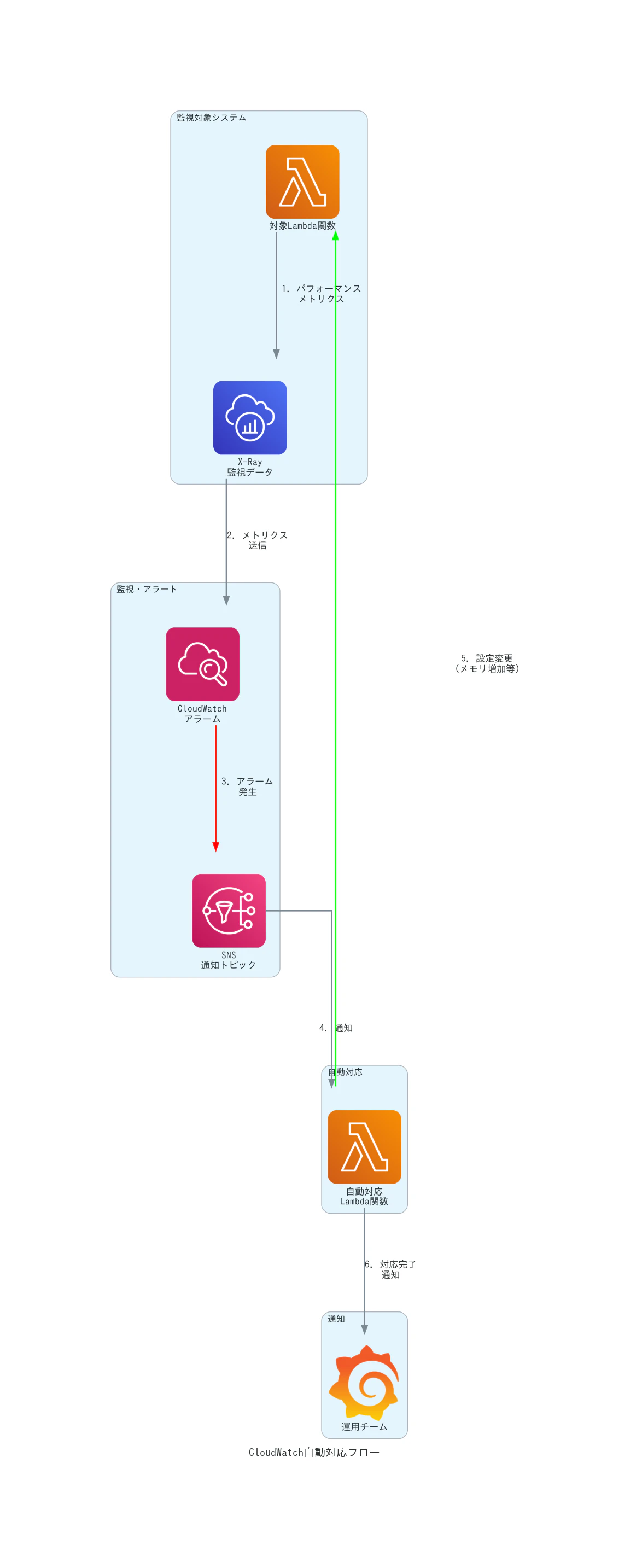
6.3 自動レスポンス機能の実装
問題が検出された際に自動的に対応する仕組みを構築できます。
import json
import boto3
lambda_client = boto3.client('lambda')
def lambda_handler(event, context):
# CloudWatchアラームからの通知を処理
message = json.loads(event['Records'][0]['Sns']['Message'])
if message['AlarmName'] == 'Lambda-High-Response-Time':
# メモリサイズの自動調整
lambda_client.update_function_configuration(
FunctionName='my-function',
MemorySize=1024 # 現在の設定より大きな値に調整
)
# 運用チームへの通知
sns = boto3.client('sns')
sns.publish(
TopicArn='arn:aws:sns:region:account:ops-alerts',
Message=f'Lambda function memory increased due to high response time',
Subject='Auto-scaling triggered'
)
return {'statusCode': 200}
7. 終わりに
本記事では、AWS X-RayとLambdaを活用したサーバーレスアプリケーションのパフォーマンス監視について、基本的な概念から実践的な改善手法まで解説しました。
主なポイントのまとめ
- X-Rayの基本理解: 分散トレーシングの概念とX-Rayの主要コンポーネント
- 効率的な設定方法: Lambda関数とAPI GatewayでのX-Ray有効化手順
- ボトルネック特定技術: サービスマップとトレース分析によるパフォーマンス問題の特定
- 具体的な改善手法: コールドスタート、DynamoDB、外部API呼び出しの最適化
- 自動化の重要性: CloudWatchアラームとカスタムメトリクスによる継続的な監視
次のステップ
X-Rayによる監視を導入した後は、以下のようなステップで継続的な改善を進めることをお勧めします:
- ベースラインの確立: 現在のパフォーマンスメトリクスを記録
- 継続的な監視: アラームと自動レスポンスの設定
- 定期的な見直し: 月次でのパフォーマンスレポート作成
- チーム共有: 監視結果とベストプラクティスの共有
サーバーレスアプリケーションの監視は、一度設定して終わりではなく、継続的な改善が重要です。X-Rayを活用して、より信頼性の高いサービスを構築していきましょう。
参考文献・参考サイト
AWS公式ドキュメント
- 「AWS X-Ray で AWS Lambda を使用する」AWS Documentation, https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/services-xray.html
- 「とは AWS X-Ray」AWS Documentation, https://docs.aws.amazon.com/ja_jp/xray/latest/devguide/aws-xray.html
- 「AWS X-Ray の概念」AWS Documentation, https://docs.aws.amazon.com/ja_jp/xray/latest/devguide/xray-concepts.html
- 「API Gateway での AWS X-Ray サービスマップとトレースビューの使用」AWS Documentation, https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/apigateway-using-xray-maps.html
技術記事・ブログ
- 「AWS X-Ray と Amazon CloudWatch RUM を用いたパフォーマンス監視のベストプラクティス」Techouse Developers Blog, December 19, 2024, https://developers.techouse.com/entry/aws-x-ray-and-rum
- 「AWS X-Rayにサクッと入門する」Fenrir Engineers, October 1, 2024, https://engineers.fenrir-inc.com/entry/2024/10/01/134253
- 「LambdaでX-Rayトレースが出てこない? ~パッシブ計測にお気を付けください~」SKYARCH BROADCASTING, January 9, 2024, https://www.skyarch.net/blog/lambdaでx-rayトレースが出てこない?-~パッシブ計測に/