概要
Amazon SageMaker Model Monitorを使用して機械学習モデルの継続的監視を実装する方法を解説します。ベースラインジョブから監視ジョブの設定、データ更新時の再実行手順まで、実践的な手順を詳しく説明します。
目次
- はじめに
- SageMaker Model Monitorの基本概念
- データドリフトの語源と意味
- ベースラインジョブの実行
- 監視ジョブの設定とエンドポイントへのアタッチ
- データ更新時の対応手順
- 監視結果の確認とアラート設定
- 料金とベストプラクティス
- 終わりに
- 参考文献・参考サイト
はじめに
機械学習モデルを本番環境で運用する際、トレーニング時の性能を維持し続けることは困難です。時間が経つにつれて、実際のデータがトレーニングデータと異なる傾向を示すことで、モデルの予測精度が低下する現象が発生します。これを「データドリフト」と呼びます。
Amazon SageMaker Model Monitorは、こうした問題を自動的に検出し、モデルの品質を継続的に監視するマネージドサービスです。本記事では、実際にModel Monitorを使用してモデル監視を実装する手順を詳しく解説します。
SageMaker Model Monitorの基本概念
SageMaker Model Monitorは、機械学習モデルの品質を本番環境で監視するサービスです。主に以下の2つのアプローチで監視を行います:
- リアルタイムエンドポイントでの継続的監視
- 定期的に実行されるバッチ変換ジョブでの監視
Model Monitorの動作プロセスは以下の通りです:
- ベースライン作成: リアルタイムトラフィックと比較するためのベースラインを作成
- 監視スケジュール設定: ベースライン作成後、継続的に評価・比較するスケジュールを設定

ベースラインジョブとは
ベースラインジョブは、統計的なルールと制約を生成し、後のモデル分析の基礎となる重要な処理です。トレーニングデータや検証データを使用して、データの統計的特性を分析し、正常な状態の基準を設定します。
監視ジョブの役割
監視ジョブを定義してエンドポイントにスケジュールでアタッチし、Model Monitorがモデルの予測を分析する監視ジョブを開始します。この監視ジョブが、リアルタイムデータをベースラインと比較し、異常を検出します。
データドリフトの語源と意味
ドリフト(Drift)の語源
「ドリフト」という言葉は、もともと「漂流」や「流れ」を意味する英語の「drift」に由来します。船が潮流に流されて目的地からずれてしまうように、データも時間とともに当初の特性から「漂流」してしまうことから、この名前が付けられました。
データドリフトとコンセプトドリフトの違い
機械学習の分野でドリフトには主に2つの種類があります:
データドリフト(Data Drift)
MLモデルが本番環境で受け取る特徴量の分布の変化を指します。これは入力データの統計的特性が変化することで、モデルの性能低下を引き起こす可能性があります。
コンセプトドリフト(Concept Drift)
目的変数の統計的特性が予期しない方法で時間とともに変化することを指します。MLモデルが学習したデータパターンと関係性の変化によって、モデルの品質が低下します。
例:データドリフトは「住宅価格予測モデルで、入力される住宅の築年数や面積の分布が変化すること」であり、コンセプトドリフトは「同じ条件の住宅でも、経済状況の変化により価格の決まり方自体が変わること」です。
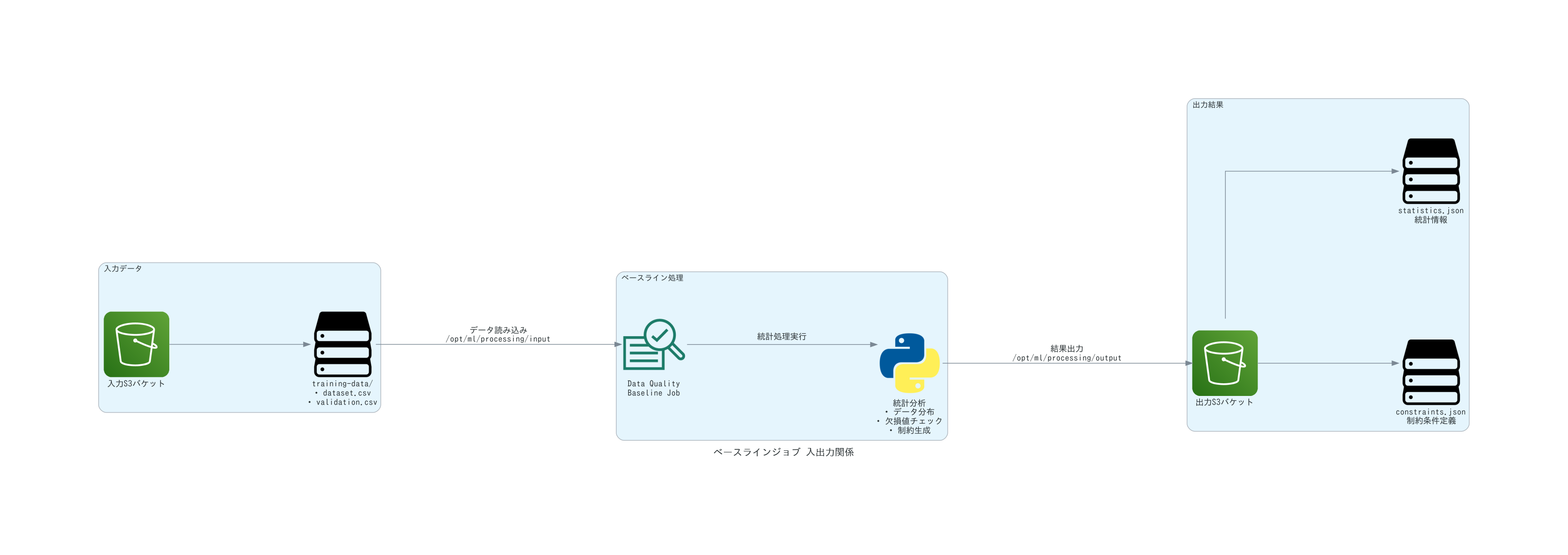
ベースラインジョブの実行
必要な前提条件
ベースラインジョブを実行するために、以下の準備が必要です:
- SageMaker実行ロールの設定
- トレーニングデータまたは検証データのS3保存
- モデルエンドポイントの作成(既存または新規)
AWS CLIを使用した実行手順
以下のコマンドでベースラインジョブを作成します:
# ベースラインジョブの作成
aws sagemaker create-data-quality-job-definition \
--job-definition-name my-model-baseline-job \
--data-quality-app-specification ImageUri=your-monitoring-container-uri \
--data-quality-job-input S3Input='{
"S3Uri": "s3://your-bucket/training-data/",
"LocalPath": "/opt/ml/processing/input",
"S3DataType": "S3Prefix",
"S3InputMode": "File"
}' \
--data-quality-job-output-config S3Output='{
"S3Uri": "s3://your-bucket/baseline-results/",
"LocalPath": "/opt/ml/processing/output"
}' \
--role-arn arn:aws:iam::123456789012:role/SageMakerExecutionRole
出力結果の確認方法
ベースラインジョブの完了後、S3に以下のファイルが出力されます:
-
constraints.json: データ品質の制約条件 -
statistics.json: データの統計情報
これらのファイルは、後続の監視ジョブでベースラインとして使用されます。
監視ジョブの設定とエンドポイントへのアタッチ
監視ジョブの定義方法
ベースラインリソース(制約と統計)を使用してリアルタイムトラフィックやバッチジョブの入力と比較する監視ジョブを定義します:
# 監視スケジュールの作成
aws sagemaker create-monitoring-schedule \
--monitoring-schedule-name my-model-monitoring-schedule \
--monitoring-schedule-config '{
"ScheduleExpression": "cron(0 * * * ? *)",
"MonitoringType": "DataQuality",
"MonitoringJobDefinition": {
"BaselineConfig": {
"ConstraintsResource": {
"S3Uri": "s3://your-bucket/baseline-results/constraints.json"
},
"StatisticsResource": {
"S3Uri": "s3://your-bucket/baseline-results/statistics.json"
}
},
"MonitoringInputs": [{
"EndpointInput": {
"EndpointName": "your-model-endpoint",
"LocalPath": "/opt/ml/processing/input",
"S3DataDistributionType": "FullyReplicated",
"S3InputMode": "File"
}
}],
"MonitoringOutputConfig": {
"S3Output": {
"S3Uri": "s3://your-bucket/monitoring-results/",
"LocalPath": "/opt/ml/processing/output"
}
},
"MonitoringResources": {
"ClusterConfig": {
"InstanceType": "ml.m5.xlarge",
"InstanceCount": 1,
"VolumeSizeInGB": 20
}
},
"RoleArn": "arn:aws:iam::123456789012:role/SageMakerExecutionRole"
}
}'
エンドポイントへの適用手順
監視スケジュールは、指定したエンドポイントに自動的にアタッチされます。エンドポイントでデータキャプチャが有効になっている必要があります:
# エンドポイント設定の確認
aws sagemaker describe-endpoint --endpoint-name your-model-endpoint
監視スケジュールの設定
監視の実行頻度は、cron式で柔軟に設定できます:
- 毎時実行:
cron(0 * * * ? *) - 毎日実行:
cron(0 0 * * ? *) - 週1回実行:
cron(0 0 ? * SUN *)

データ更新時の対応手順
データ更新が必要なケース
以下の状況では、ベースラインジョブの再実行が必要です:
- 新しい特徴量が追加された場合
- トレーニングデータが大幅に更新された場合
- 季節性やトレンドの変化により、現在のベースラインが適切でない場合
- モデル自体が再トレーニングされた場合
ベースラインジョブの再実行プロセス
データが更新された場合の推奨手順:
- 既存の監視スケジュールを停止
aws sagemaker stop-monitoring-schedule \
--monitoring-schedule-name my-model-monitoring-schedule
- 新しいデータでベースラインジョブを実行
# 新しいトレーニングデータでベースラインジョブを再実行
aws sagemaker start-data-quality-job-definition \
--job-definition-name my-model-baseline-job-v2 \
--data-quality-job-input S3Input='{
"S3Uri": "s3://your-bucket/updated-training-data/"
}'
-
監視ジョブの更新
新しいベースラインファイルを参照するよう監視スケジュールを更新します。
監視ジョブの更新方法
既存の監視スケジュールを削除し、新しいベースラインを使用する監視スケジュールを作成します:
# 既存スケジュールの削除
aws sagemaker delete-monitoring-schedule \
--monitoring-schedule-name my-model-monitoring-schedule
# 新しいベースラインを使用する監視スケジュールの作成
aws sagemaker create-monitoring-schedule \
--monitoring-schedule-name my-model-monitoring-schedule-v2 \
--monitoring-schedule-config '{
"BaselineConfig": {
"ConstraintsResource": {
"S3Uri": "s3://your-bucket/updated-baseline-results/constraints.json"
}
}
}'
監視結果の確認とアラート設定
CloudWatchでの監視メトリクス確認
Model Monitorは、検出された異常をCloudWatchメトリクスとして自動的に送信します。主なメトリクスには以下があります:
- データ品質違反の数
- 統計的特性の変化度合い
- 欠損値の割合
CloudWatchコンソールまたはAWS CLIで確認できます:
# CloudWatchメトリクスの取得
aws cloudwatch get-metric-statistics \
--namespace AWS/SageMaker/ModelMonitor \
--metric-name DataQualityViolations \
--dimensions Name=EndpointName,Value=your-model-endpoint \
--start-time 2024-01-01T00:00:00Z \
--end-time 2024-01-02T00:00:00Z \
--period 3600 \
--statistics Sum
アラート設定のベストプラクティス
効果的な監視には、適切なアラート設定が重要です:
- しきい値の設定: 業務に与える影響を考慮して、適切なしきい値を設定
- 通知チャネルの設定: SNSトピックを使用したメール、Slack通知の設定
- エスカレーション手順: 重要度に応じた段階的な通知設定
# CloudWatchアラームの作成例
aws cloudwatch put-metric-alarm \
--alarm-name "ModelMonitor-DataDrift-Alert" \
--alarm-description "Data drift detected in model endpoint" \
--metric-name DataQualityViolations \
--namespace AWS/SageMaker/ModelMonitor \
--statistic Sum \
--period 3600 \
--threshold 5 \
--comparison-operator GreaterThanThreshold \
--alarm-actions arn:aws:sns:us-east-1:123456789012:model-monitoring-alerts
料金とベストプラクティス
監視にかかるコスト
Model Monitorの料金は以下の要素で決まります:
- 処理インスタンス: 監視ジョブで使用するインスタンスタイプと実行時間
- データストレージ: S3での監視データ保存料金
- CloudWatchメトリクス: カスタムメトリクスの使用料金
一般的な監視設定(ml.m5.xlarge、1時間ごと実行)では、月額約50-100ドル程度が目安です。
効率的な監視運用のポイント
コスト効率と監視効果を両立するためのベストプラクティス:
- 監視頻度の最適化: 業務要件に応じた適切な監視間隔の設定
- リソースサイジング: データ量に応じた適切なインスタンスタイプの選択
- データ保存期間の管理: 古い監視データのライフサイクル管理
- 段階的な監視: 重要度の高いモデルから段階的に監視を導入
終わりに
Amazon SageMaker Model Monitorを使用することで、機械学習モデルの継続的な品質監視を自動化できます。ベースラインジョブから監視ジョブの設定、そしてデータ更新時の適切な対応手順を理解することで、本番環境でのモデル運用をより安全かつ効率的に行えます。
データドリフトは避けられない現象ですが、適切な監視体制を構築することで、問題を早期発見し、迅速な対応が可能になります。継続的な監視により、ビジネスに与える影響を最小限に抑えながら、機械学習モデルの価値を最大化していきましょう。
次のステップとして、実際の業務データを使用したベースラインジョブの実行と、監視結果に基づいたモデル改善のワークフロー構築を検討されることをお勧めします。
参考文献・参考サイト
- 「Data and model quality monitoring with Amazon SageMaker Model Monitor」AWS Documentation, https://docs.aws.amazon.com/sagemaker/latest/dg/model-monitor.html
- 「Create a Baseline」AWS Documentation, https://docs.aws.amazon.com/sagemaker/latest/dg/model-monitor-create-baseline.html
- 「Schedule monitoring jobs」AWS Documentation, https://docs.aws.amazon.com/sagemaker/latest/dg/model-monitor-scheduling.html
- 「Model Monitor FAQs」AWS Documentation, https://docs.aws.amazon.com/sagemaker/latest/dg/model-monitor-faqs.html
- AWS Machine Learning Blog「Monitoring in-production ML models at large scale using Amazon SageMaker Model Monitor」AWS, August 23, 2021, https://aws.amazon.com/blogs/machine-learning/monitoring-in-production-ml-models-at-large-scale-using-amazon-sagemaker-model-monitor/
- 「Concept drift」Wikipedia, https://en.wikipedia.org/wiki/Concept_drift
- 「What is data drift in ML, and how to detect and handle it」Evidently AI, https://www.evidentlyai.com/ml-in-production/data-drift
- 「What is concept drift in ML, and how to detect and address it」Evidently AI, https://www.evidentlyai.com/ml-in-production/concept-drift