データ基盤 Advent Calendar 2020の16日目です。
データ基盤のアーキテクチャを考えるときに、イベントソーシング+コマンドクエリ責務分離パターン(CQRS)で整理して考えたら割とキレイに考えられる気がするので、その紹介をします。
このパターン自体は数年前からすでに言われていたので、知ってる人にとってはそれほど新しい概念ではないかもしれない。
イベントソーシング
詳細はMSのドキュメントがわかりやすかったので、それを見てもらうと良いかな。(余談ですが、MSのクラウド設計パターンのページがよくまとまってるので、設計考えるときにおすすめです)
https://docs.microsoft.com/ja-jp/azure/architecture/patterns/event-sourcing
簡単に説明すると、データの現在の状態ではなく、データの変更を引き起こすイベントの方を記録しましょう、という設計パターンです。ドメイン駆動設計の考え方らしいです。
例えばカートのDBを設計する場合、普通のDB場合はこんな感じで、現在の状態を保持します。
| User ID | Cart Item ID |
|---|---|
| A | item1 |
| A | item2 |
| A | item4 |
| B | item5 |
これがイベントソーシングだと、次のようなイベントの状態を保存することになります。
| User ID | Event | Cart Item ID |
|---|---|---|
| A | add | item1 |
| A | add | item2 |
| B | add | item5 |
| A | add | item3 |
| A | add | item4 |
| A | delete | item3 |
イベントを保存しておいて、活用するとき(例えばカート商品一覧画面を表示する時など)にイベントから現在の状態を再現して使うことになります。
容易に想像できる通り、データの書き込みについては更新操作と比較して軽い追記操作というアトミックな処理で完結します。その代わり、データの読み込み時に大量のデータを読み込んで現在の状態を再現するという重い処理が必要となります。実際にはイベントソーシング単体だとあまり実用的ではないため、次のコマンドクエリ責務分離パターンと組み合わせて使われることが多いようです。
コマンドクエリ責務分離パターン(CQRS)
これもMSの説明がとても分かりやすかったです。
https://docs.microsoft.com/ja-jp/azure/architecture/patterns/cqrs
ここでいうコマンドというのは書き込みリクエスト、クエリというのは読み込みリクエストを指します。下記図のように、データの書き込みの仕組みと読み取りの仕組みを分離して作る設計パターンになります。
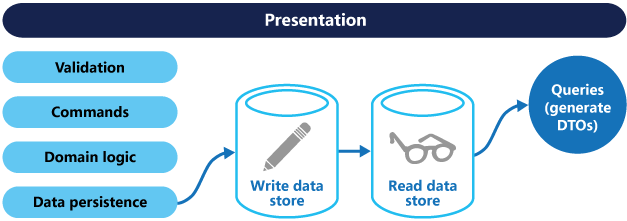
CQRS パターン - Azure Architecture Center | Microsoft Docs より引用
DBのprimaryとreplicationの関係と考えればわかりやすいかなと思います。多くの場合、書き込みリクエストと読み取りリクエストはそのリクエスト頻度や読み出しデータ量などが大きく違います。そのため、これらを分離することで、柔軟でパフォーマンスの高いシステムが作れます。
で、何が新しいの
これを見て大して新しい発想じゃないな、と思った人も多いかなと思います。実際、以下のようなものもこのイベントソーシング+CQRSパターンと言って良さそうです。全く新しい概念のデータ基盤設計というより、今までの設計を整理し直した、と見るのが良さそうです。
- DataWarehouseとDataMart
- DataLakeと分析結果
- kappaアーキテクチャのLog-structured data flow
データ基盤の場合、大量のデータを集めるため書き込みがネックになり、対して読み取りは分析時まで多少時間的猶予があるため、まさにこのパターンの強みが当てはまります。また、ストリーム処理・バッチ処理どちらの場合も適用できる考え方なので、使いやすい概念かなと思います。
概念として整理されていることで、”DataLakeなのにappend-onlyじゃない"とか、"DataMartに直接書き込んでしまってる"みたいなアンチパターンにも気付きやすくなるかなと思いって、紹介してみました。