ここのところ組織内の生成AIプロダクト利用促進や、利用ルールの整備、新規プロダクトの組織内展開に向けた準備作業をしています。
そのなかでMicrosoft 365 CopilotやKiro・Claudeなどの生成AIプロダクトを組織内のメンバーが利用できるよう準備するときの難しさについて気づく機会を得ました。生成AIはもちろん(?)、法務にはまったく明るくない人間として、ポイントをまとめます。
当たり前のことかもしれませんが、とくに難しいのは個人情報も含む機密情報の取り扱いと著作権侵害の問題。生成AI導入の難しさとして挙げられるものにはコスト、個人・組織のスキル、精度課題の克服方法、文化的・心理的障壁などさまざまありますが、やはり重大性(クリティカル性)が高いのはこの2つ。いずれも法的な問題であり、重大でありながら回避・解決が困難な問題です。
保存しない? 訓練もしない? 第三者提供もしない?
まずは機密情報の取り扱い。
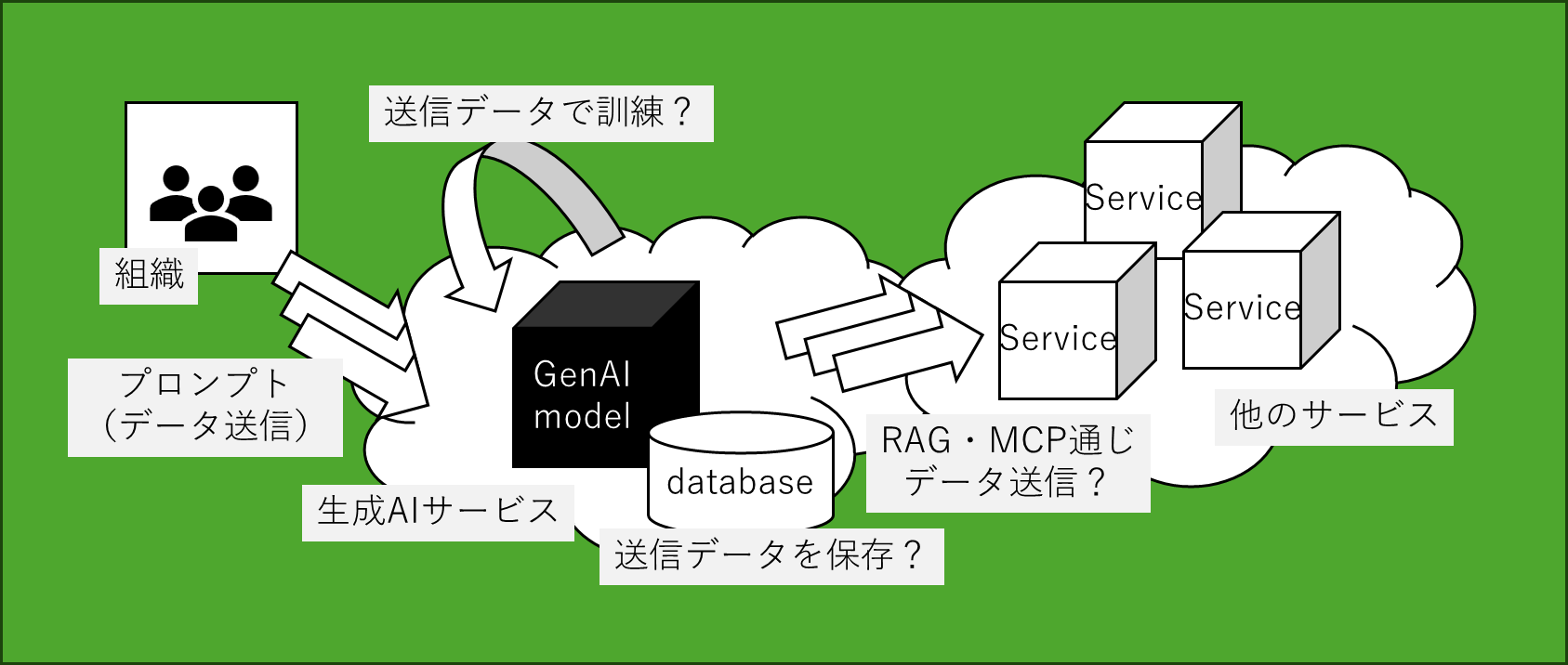
組織内で生成AI利用する場合、プロンプトに(個人情報を含む)機密情報が含まれる可能性があり、大きく4つの問題があります:
- 送信されたデータを処理する生成AIサービスがISO127001やSOC2などの枠組みで認証済みか?
- 送信されたデータが当該サービスに保存されるか?(される場合、その保護や削除がきちんとなされるか?)
- 送信されたデータが生成AIモデルの訓練(学習)に利用されるか?(=他の利用へのサービス提供に利用されてしまうか?)
- RAGやMCPを通じて他のAI/非AIなサービスに送信されるか?
言うまでもないことですが、#3が「利用される」の場合、組織利用としては即座にNGとなるはず。
#1が「認証済みでない」場合や#2が「保存される(保護や削除の規定がない)」場合もふつうはNGとなるはずです。
加えて厄介なのは#4で、内部で他のサービス(例えばGoogle・Bingのような検索エンジンや各種ベンダーが提供するMCPサーバー)を使って最新情報を取得するような機能がある場合、組織のメンバーの入力し送信されたデータが推移的にそれら他のサービスにも渡ってしまうことです。
いずれも個人情報保護法や会社法・J-SOX法などに関わる重大な問題です。
無断利用していない? 無断利用を許していない?
続いて、著作権の問題。
生成AIを利用して作成したモノ(とくに画像)には著作権について2つの観点があります:
- 他者の著作権を侵害していないか? 生成AIモデルは、インターネットほかさまざまなデータソースから得られたモノを使って訓練され、それをもとに新たなモノを生成する。RAGやMCPの機能を備えたものであれば外部サービスから最新のデータも取得して生成する。この時、他の個人や組織の著作権を侵害していないかが問題となる。
- 他者に著作権を主張できるか? 生成AIモデルが生成したものを組織が(とくに外部向けのコンテンツで)利用するとき、そのモノの著作権を主張できる状態でない。一般に「著作性」は人間を前提にしており生成AIによる生成物について容易に著作権が認めらることはない。プロンプトでよほど高度(質的・量的)な人間のコミットメントがないと著作権の主張は困難となる。
著作権侵害は法的に即NGであることはもちろん、著作性により独占的(排他的)権利を主張できないこともまた問題。著作権が認められないと外部の二次利用をコントロールできずブランド毀損するリスクなどが生じます。

さいごに
以上、たいへん皮相なレベルではありますが、組織内で生成AIプロダクトを展開するとき、考慮しなくてはならないことの中でもとくに重要度の高い機密情報の取り扱いと著作権侵害の問題について見てきました。
こうした法的な問題は、自組織単体でも問題となることですが、業務を委託/受託しているケースであれば、問題が発生した時の責任の所在について複数組織間での事前の取り決めも必要となることもあるかもしれません。
いずれにせよ、組織で生成AIを利用するときには、「気をつけよう」ではすまない、法務や経営の判断が必要なことが多くあるということでした。