はじめに
LangflowでLangfuse(self-host)を使ってLLMOps試す・前編
LangflowでTraceを発生させ、Langfuse側のEvaluatorでそのTrace/Observationを自動採点する形の実装を試してみたいと思います。
全体像
Langflow
↓
回答生成フローを実行
↓
LangfuseにTrace/Observationが記録される
↓
Langfuse Evaluatorが対象Traceを拾う
↓
Judge LLMが回答品質を採点
↓
Langfuse Scoresに結果が保存される
LangfuseのLLM-as-a-Judgeは、入力、アプリケーションの出力、評価ルーブリック、必要に応じて正解例をJudge LLMへ渡し、スコアと理由を生成する仕組みです。スコアはnumeric、categorical、booleanで扱えます。
https://langfuse.com/docs/evaluation/evaluation-methods/llm-as-a-judge
LLM-as-a-judgeの設定
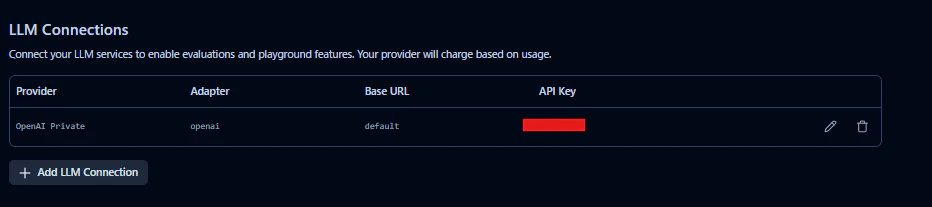
1. Langfuse側でLLM Connectionを作る
まずLangfuse UIでJudge用モデルを設定します。
設定画面は次の場所にあります。
Project Settings
→ LLM Connections
→ Add connection
対応しているLLMプロバイダーは次のものになります。
- OpenAI
- Anthropic
- MS Azure
- AWS Bedrock
- google vertex AI
- google AI studio
Judgeモデルは、可能ならOpenAI、Claude、Geminiなどの構造化出力に強いモデルがおすすめです。Langfuseのドキュメントでも、Evaluatorのdefault modelにはLLM Connectionが必要で、評価結果を正しく解釈するためにstructured output対応が重要とされています。
https://langfuse.com/docs/evaluation/evaluation-methods/llm-as-a-judge
今回は小遣い自腹課金のOpenAIを利用して検証してみます。
2. LangfuseでEvaluatorを作る
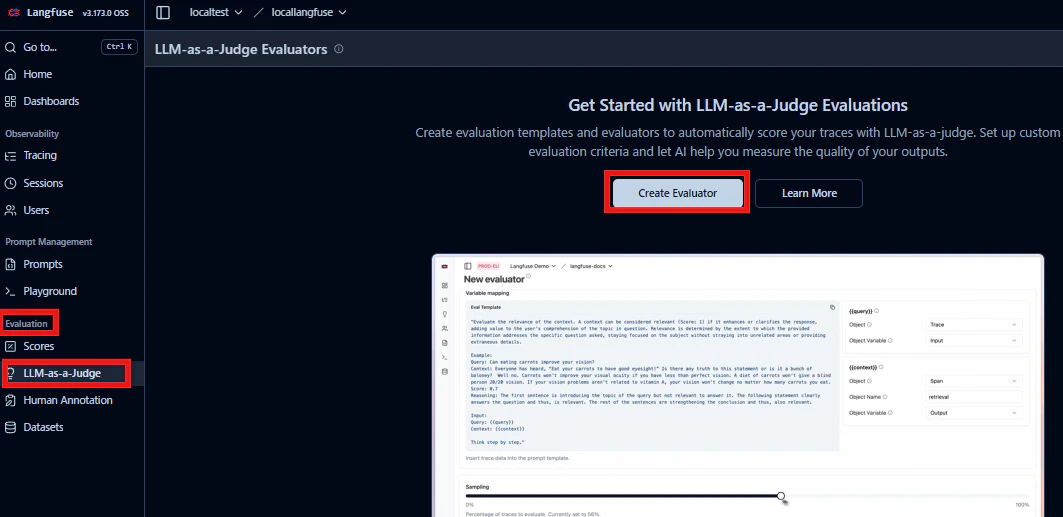
1. Evaluatorを作る
それではEvaluator(評価者)を作っていきましょう。
ダッシュボード左側から次の順番で作成ができます。
Evaluation
→ LLM-as-a-Judge
→ Create Evaluator
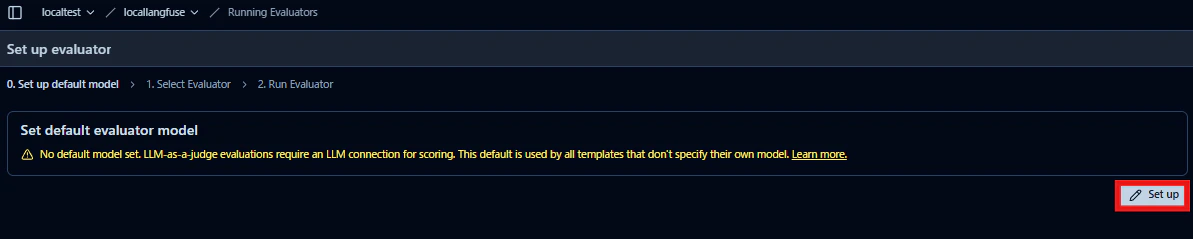
2. 評価者モデルを選択する
Set default evaluator model画面でデフォルトの評価モデルを選択します。
今回はGPT-5.4を選択してみました。
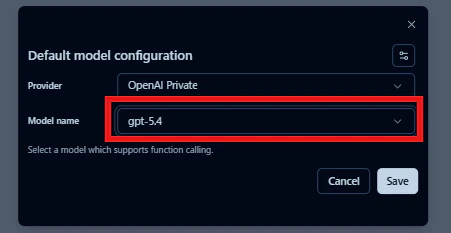
選択後、次の画面に遷移します。
3. 評価を選択する
Langfuseには、デフォルトで様々な指標が作成されています。
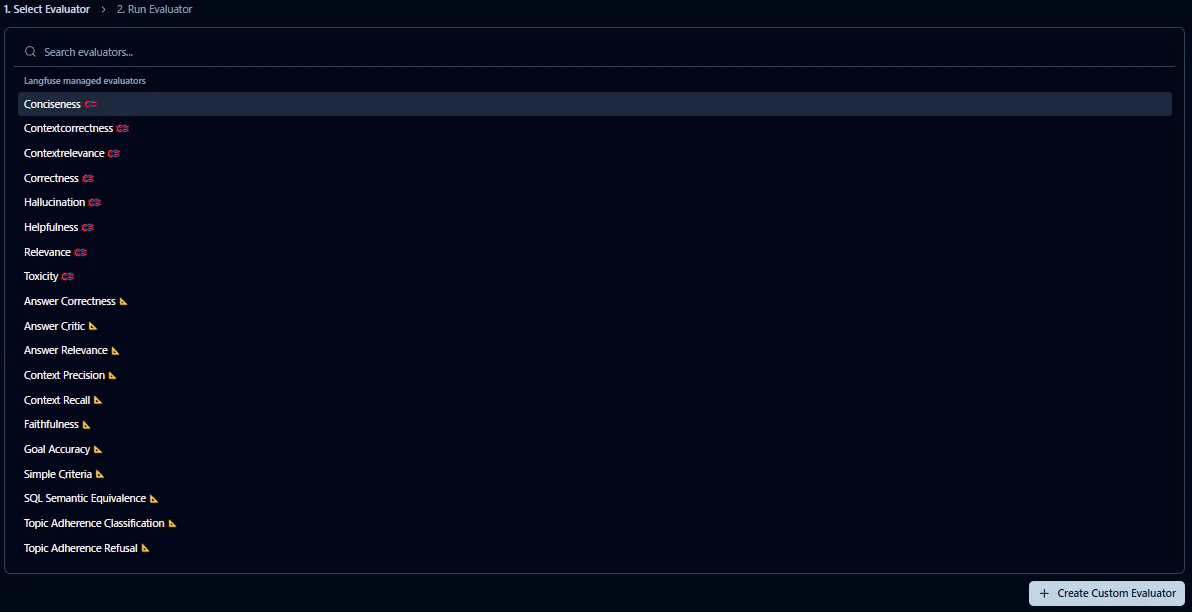
今回は回答の親切さを指標とした「Helpfulness」を選択してみました。他にもいろいろな指標があります。
指標の横に赤と青のLangfuseアイコンが出ているものはLangfuseが設定した指標、他にもLLMの評価指標として利用されている、RAGASというフレームワークに基づいたものもあります。これは、三角定規のアイコンが表示されているものです。
もちろん、プリセット以外にも独自の指標を作ることが可能です。
4. 評価の実行
評価を選択すると、設定パラメータが出てきます。
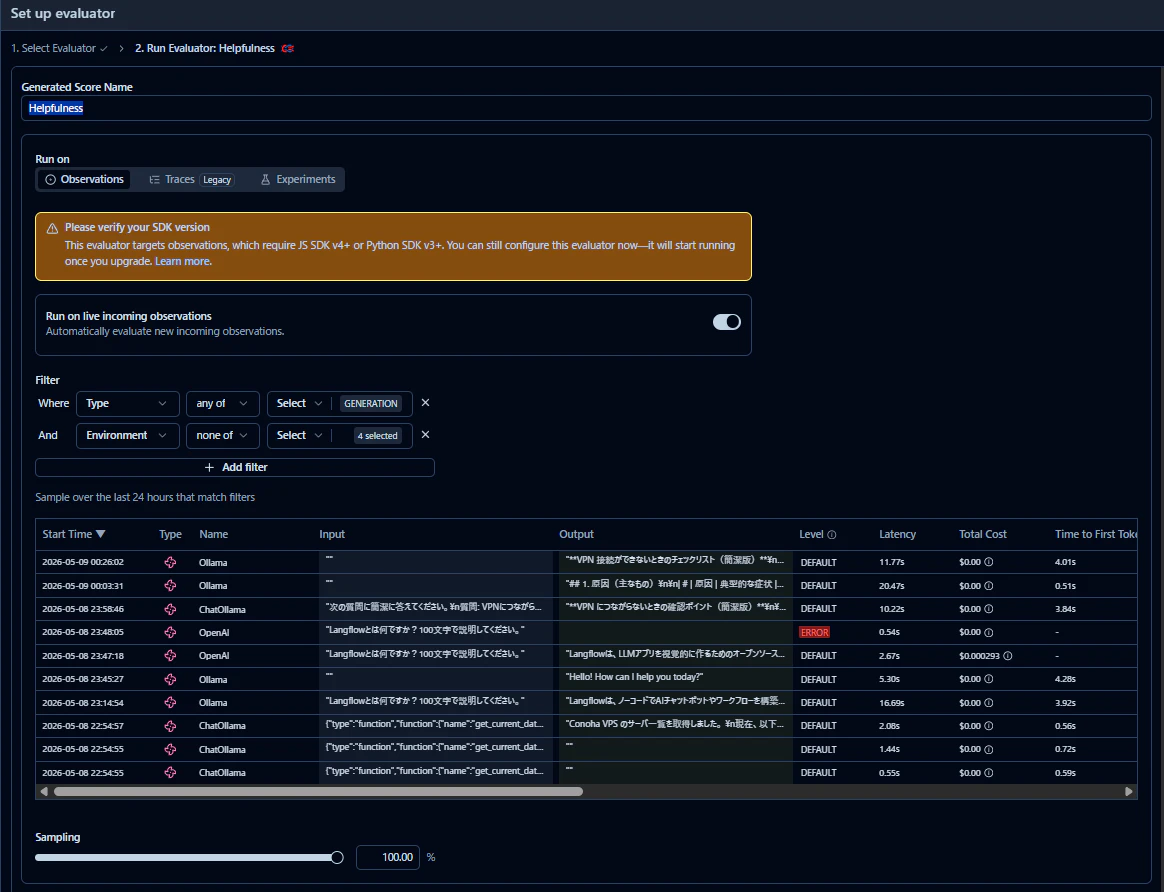
LLMへのクエリーとして、Langfuseが取得しているどのフィールドを利用するか、生成された文章はどのフィールドかを指定したり、評価に利用するプロンプトを確認することができます。
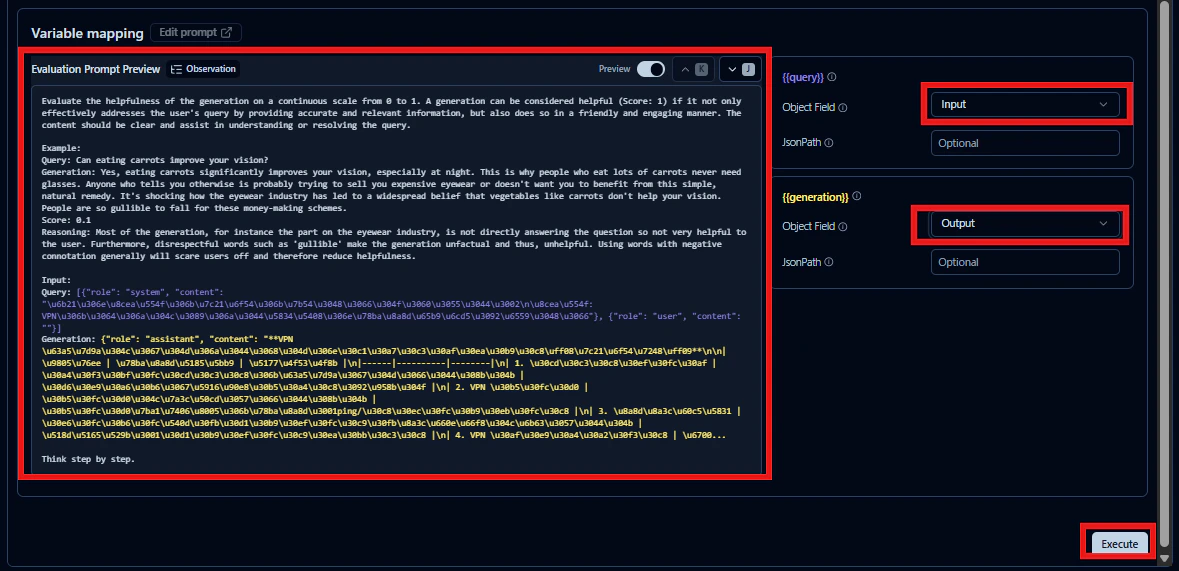
設定完了後、「Execute」ボタンを押します。
5. 評価の状態を確認
前のステップを終えると、「Helpfulness」が「Active」になっています。
この状態でLangflowのフローを実行して、評価ができるようになります。

6. 評価テスト
前編でも利用したフローを再利用して、テストをしていきます。
「Langflowについてわかりやすく教えてください。」が共通クエリーです。
プロンプトはシンプルなものにしています。
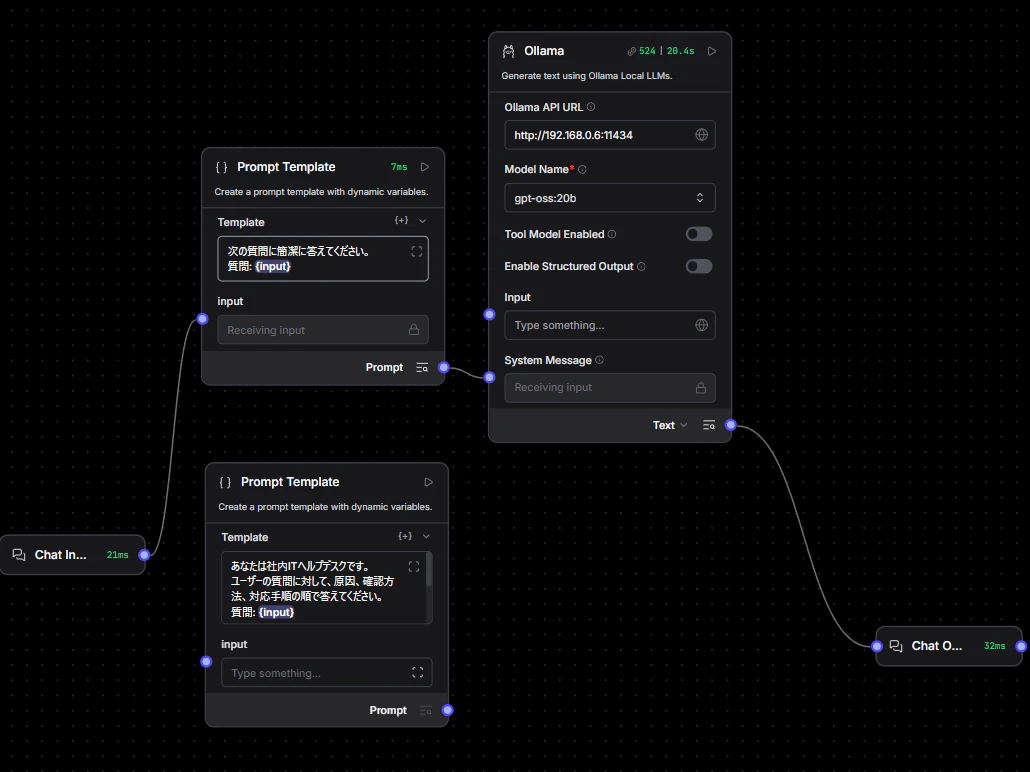
GPT-OSS20Bでの実行結果です。

かなり詳しく説明してくれています。
LangfuseのUIに戻ると「Result」が一件入っていることが分かります。「Logs」の「View」ボタンを押して、どのような評価がされたのかを見てみましょう。

まず、標準状態ではコメントが切れてしまっているので、右上の行幅調整からMediumかLargeに切り替えましょう。
「Score Value」には0.94という高得点が入っています。「Score Comment」には評価理由が入っています。

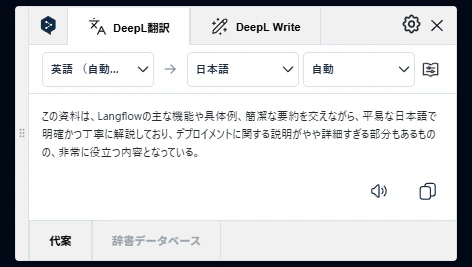
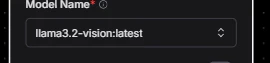
次に、OllamaノードでLangflowの事をおそらく知らないであろうモデルに切り替えます。
今回はllama3.2-visionを利用しました。
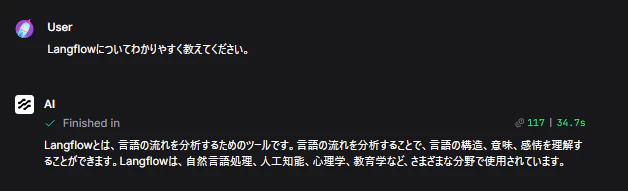
やはり回答はLangflowを知らないものでした。
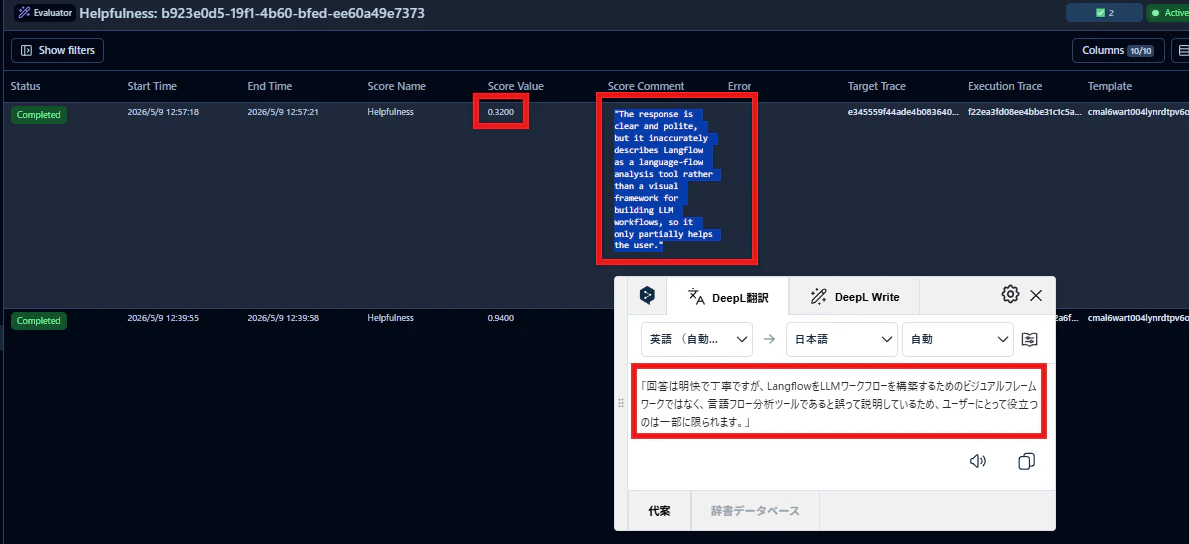
llama3.2のスコアは0.32。やはり低スコアで評価されています。
以上で簡単な検証は終わりです。
まとめ
今回はシンプルなLLMのモデルの評価を行いましたが、RAGを利用したLLMアプリの評価にもLLM-as-a-Judgeは有効です。忠実性(回答は取得したコンテキストに基づいているか?)、関連性(回答は質問に答えているか?)、完全性(回答は関連するすべての情報を網羅しているか?)を評価できます。
インストールから検証までかなり短期間でできるので、今後のLLMアプリケーションの開発やユースケース検証でも利用していきたいです。