ターゲット
- 巨大なSPAを作ってしまった人へ
- 巨大なSPAを作らないように気をつけたい人へ
今回はJSだけにフォーカスするが、もっというと、 超速本 を読んでください。
注意:本資料は、webpack チャンクの挙動を概念的に説明することを重視しているので、 webpack の詳細な設定や、出力ファイル名などは実際の処理と一致しない。適宜自分の手元にある設定とすり合わせるように。
昨今のJSビルド問題と、その解決のためのゴール設定
巨大なJS(+最近は in JS された各種SVGやCSS)はダウンロードだけではなく、UIスレッドのCPUをブロックする。
これはとくにCPUが貧弱な端末で体験が悪化する。そしてビルド時間で開発者体験を阻害する。
できれば webpack 推奨の 144kb 以内にしたい…が現実的に難しいので、 せめて 350kb ぐらいに抑えたい。
SPAなら (ローディングスピナーなどのアニメーションを出した上で) 1.5MB ぐらいに抑えたい。
ビルドサイズが 3MB 超えたあたりで、日本の一般的な 4G 環境では使い物にならなくなる。
必要となる知識
さっそく実践…といきたいところだが、まずこの辺の知識が必要になる
- Tree Shaking
- Dead Code Elimination
- Dynamic Import
- Webpack 環境下での Dynamic Import
- npm の peerDependencies
Tree Shaking
ESM で Import されないモジュールを削除する機能。webpack と terser が担ってる。(rollup なら単体でできる)
import { flatten } from "lodash-es"; // tree shaking 対応ライブラリ
console.log(flatten([1, [2, [3]]]));
lodash-es のうち、flatten 以外のコードが落とされる。ただし、 flatten が内部で import してるコードは含まれる。
有効にするには、 typescript 環境では tsconfig.json で "module": "es2015" 以上、 babel 環境では [env, {"modules": false}] (commonjsに変換しない) にする必要がある。
Dead Code Elimination: 不要コード削除
terser の機能
// webpack.config.js
const webpack = require('webpack');
// ... 略
plugins: [
new webpack.DefinePlugin({
'process.env.NODE_ENV': JSON.stringify("production")
});
]
このような設定をした上で、
if (process.env.NODE_ENV !== "production") { ... }
のコードは、
.1 if (process.env.NODE_ENV !== "production") { ... }
.2 if ("production" !== "production") {...} (webpack.Define が置換)
.3 if (false) {...} (terser が定数同士をコンパイル時比較)
.4 なし
と展開されて、消える。これは開発環境でしか使わないライブラリで有用。
あくまでコンパイル時にしか効かないことに注意。
Dynamic Import
import a from "./a" は必ずトップレベルでの宣言が必須で、静的に解決されるが、
ESM の import("...") 関数は、スクリプトの評価時に読み込まれる。これによって、必要になるまで評価を遅延することが可能。
if(USE_LIB) {
const a = await import("./a"); // default を自動解決できないことに注意
a.default();
}
Webpack 環境下での Dynamic Import
↑ というのがネイティブブラウザでの挙動だが、 webpack 環境下では複雑な動きをする。
- output.path に複数のJSチャンクを吐く。
- 仮に
main.js,chunk.a.js -
main.jsでimport('./a')が評価されると、output.publicPathから相対パスでchunk.a.jsをダウンロードして、eval する。 - XHR で取得するので、Dynamic Import 未対応のIEでも動く(が、IE以外では大抵サポート済みで…)
- 仮に
詳しいドキュメントは https://webpack.js.org/guides/code-splitting/ にて
TypeScript 環境で dynamic import を使うには、 "module": "esnext" の指定が必要。そうでない場合は インラインの require にコンパイルされ、分割されない。
npm の peerDependencies
lerna や yarn workspaces, または単なるリポジトリ分割で、パッケージを分割すると、異なるライブラリ指定で内部的に重複してしまうことがある。
これを避けるために、dependencies ではなく、 peerDependencies で指定する。
"dependencies": {
- "lodash": "4.17.15"
},
+ "peerDependencies": {
+ "lodash": "4.*"
+ }
- dependencies と違って、自分で指定ライブラリをインストールせず、一緒にインストールされることを期待する
- 例えば react のUIライブラリは react を自分自身で持たず、 peer に指定する。これによりバージョン違いのインスタンスの重複を省く。
- node_modules
- react@16.12.0
- element-react => `peerDependencies: react@*`
という感じで、 element-react でも react@16.12.0 が使われる
これが失敗してると
- node_modules
- react@16.12.0
- element-react
- react@15
みたいになり、複数インスタンスが重複して、コード量が増えると同時に、バージョンが混ざって動作も怪しくなる。この例は多分動かない。
とはいえ、自分たちだけでやるにも限界があり、とにかく lodash を引き連れてくるライブラリが多く、行儀が悪いライブラリなら使わないという選択肢も重要になる。
実際にビルドしてどのぐらいのサイズになるかは、 https://bundlephobia.com/ にライブラリ名を突っ込んでみるのが便利
実践編: モダンフロントエンドの発達段階と最適化
ブートストラップ初期 (~100kb)
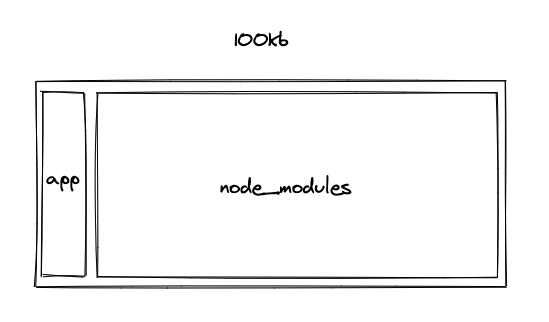
- ちょろっとDOMをマウントするだけ
- lodash, vue, react などのライブラリが支配的
開発中期 (~1.0MB)
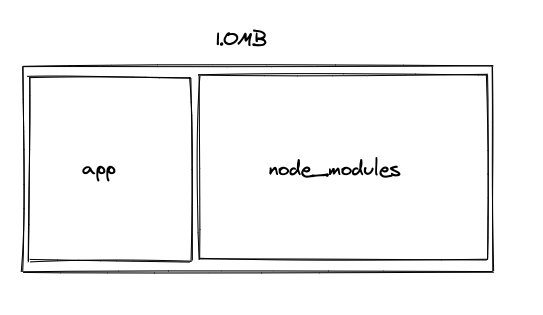
- app 側は膨らむが、同時に要求に従って
node_modules配下も増えていく。 - SPA としてはギリギリ許容範囲。パフォーマンス要求されるニュースやブログは厳しい
巨大で最適化されていない SPA (5.0MB~)
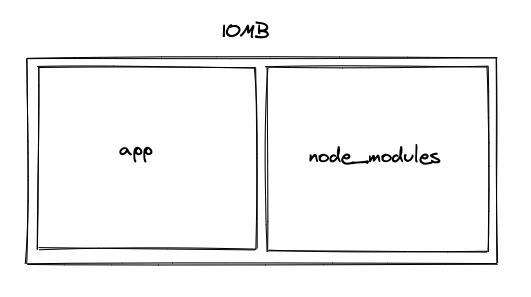
- 比率は下がるが、やっぱり要求仕様に従って
node_modulesが増える - モバイルは無理
- この辺が「嫌われるSPA」
これをどう解決するか
- Routing ごとにチャンク分割する
- vendor chunk を分割する
- dynamic import で隔離する
1. Routing ごとにチャンク分割
あるルーティングで使ってるコードは、他の画面では使ってない、ということが多い。
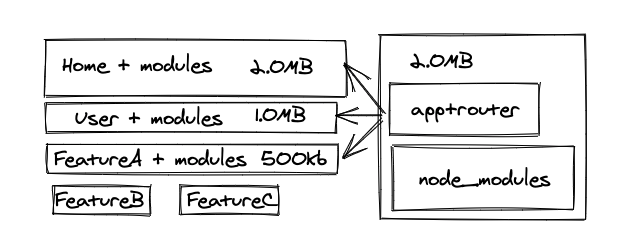
なので、ルーターに握らせるコンポーネントを遅延にする
// react
- import Foo from "./foo";
const Foo = React.lazy(() => import("./foo"));
<Route path="/foo">
<React.Suspense fallback="...">
<Foo />
</React.Suspense>
</Route>
// vue
- import Foo from "./foo.vue";
const Foo = () => import("./foo.vue");
これで、ルーティングごとに必要なものだけ遅延で解決されるチャンクにしてしまう。
ネットワーク的には、ルーティングアクションが発火してから取りに行くので、1RTT 増えてはいるが、それより不要な画面のチャンクを取ってないので軽くはなる。また、動的評価なので、クライアントサイドルーティング(CSR) にも対応している。
問題は、SSR時に非同期コンポーネントを解決して展開するのが大変で(フレームワークごとにググって)、この辺を隠蔽して自動で解決してくれるのが、 next.js/nuxt.js の良さだったりする。
2. vendor chunk を分割する
(はっきりいって、ここは難しく、評価順の問題で事故が起きがちなので、自信がないならやらなくてよい)
↑ だけだとまだ問題がある。各チャンクと router で使ってる node_modules で、ライブラリがかなりの部分で重複してしまう。(react, vue など)
なので、 vendor chunk という共通チャンクに追い出すテクニックがある。
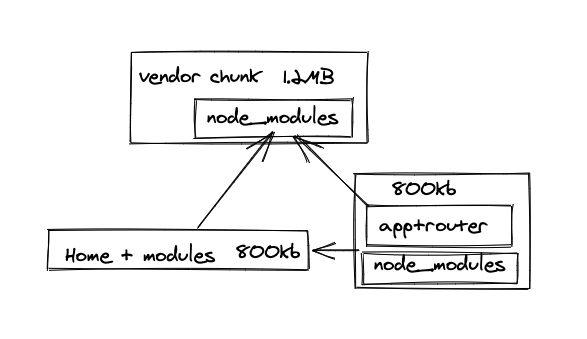
このように分割できた場合は、イニシャルのロードサイズが10MB から 2.8MB になった。あとはルーティングのたびに差分を取得する。
webpack.config.js での vendor の設定例
// https://webpack.js.org/plugins/split-chunks-plugin/
module.exports = {
//...
optimization: {
splitChunks: {
cacheGroups: {
defaultVendors: {
// Note the usage of `[\\/]` as a path separator for cross-platform compatibility.
test: /react|react-dom|react-router/
}
}
}
}
};
面倒なのが、この場合、HTML側の script タグが2つ必要になる。 <script src="main.js"></script> の前に、 <script src="vendor.js"></script> (どういう名前を付けるかによる) をロードする必要がある。
実際には、 app+router と書いた部分をいかに小さくするかが、ハイパフォーマンスなSPA設計の肝になる。フレームワークの初期化とRouting 定義以外何もないのが望ましい。が、Routing 先が共通で読み込むチャンクがあるなら、それを含んでしまうと結果として小さくなる。例えば、ほとんどのケースで lodash があるとか…
可能ならコア部分は 500kb 以下を目指したい。
3. dynamic import で隔離する
実際には、一つのライブラリが支配的なビルドサイズを締めていることがある。
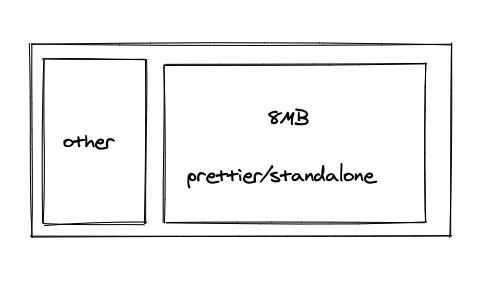
これは、ブラウザでの実行を想定していない、node ライブラリを、無理矢理コンパイルしている際に多い。例に出した, prettier/standalone などがそう。パーサやコンパイラ一式を梱包している。
このようなライブラリ、一部のケースでしか読み込まれないことも多く、必要になるまで、評価しないように、 Dynamic Import でオフロードしてしまう。
let prettier = null;
export async function format(str) {
if (prettier == null) {
prettier = await import("prettier/standalone")
}
// prettier.format(...)
}
こうすると、初めてこの format() 関数を実行した時にキャッシュが読み込まれる
この変形として、イニシャルロードを避けたいだけなら、次のようなパターンも考えられる。
const loadingPromise = import("prettier/standalone");
export async function format(str) {
const prettier = await loadingPromise;
// prettier.format(...)
}
初期化時に読み込み自体は開始される。
とはいえ、8MBの初期化は重いので、結局どこかの時点で、UIスレッドをブロックしてしまう。これは画面が突然応答しなくなる、といった体験として現れる。これも避けたければ、web worker を使って、別スレッドで扱うといった方法がある。
comlink と Worker についてはまた長くなるので、本記事では解説しない。
comlink-loader はとにかく便利なので、手元のたまとして覚えておくと便利
おまけ:ありがちなアンチパターン
チャンク分割を知らない人が webpack を運用しているケースがとても多く(というか大抵はそうなのだが)、 Routing ごとに違う webpack の設定を切り替えたビルドを作ってしまってるケース。よく目にする。現職、フリーランス時代を含めて、3つほど見た。
src/shared.js
src/route-a.js # => shared.js を参照
src/route-a.js # => shared.js を参照
webpack/a.config.js # src/route-a.js => dist/a.js を出力
webpack/b.config.js # src/route-b.js => dist/b.js を出力
これは webpack を複数プロセス走らせる必要があるだけでなく、依存ツリーの解析ができなくなり、チャンクの分割ができなくなる。また、cp によるアセットの配置も複雑なこととセットになってることが多い。
可能な限り、相互干渉するビルドは、一つの webpack プロセスにまとめたほうが、出力効率がよくなる。(ビルド時に要するメモリサイズはやや膨らむ)
なので、上の例は、理想的にはこうするとよい。
src/router.js # `import("./route-a")` と import("./route-b") を含む
src/route-a.js
src/route-b.js
webpack.config.js # src/router.js => dist/router.js | dist/chunk.a.js | dist/chunk.b.js | dist/chunk.vendor.js
昨今ありがちなDocker for Mac が遅いよーという前に、 webpack プロセスを一つにまとめるのを個人的におすすめしている。
(それはそうと開発環境時の node は、元が Xplat な言語なのもあり Docker の恩恵がなさすぎるので、Docker 不要だと思うが…)
おまけ: マイクロフロントエンド戦略時の webpack 戦略
全く独立したビルド系統のコンポーネントを、同じUIに埋め込んでいる時に起こりがちなケース。
例えば、ヘッダとコンテンツを別チームで管理しているが、ヘッダとコンテンツが、ともに共通のライブラリを参照して、5MB の 重複がある。しかし、別々にビルドしているので、依存解析ができないので、内部的に重複が放置されてしまう。
これは、チャンクを最適化すれば、5MB削れるが、とはいえ、その場合プロジェクト間の政治的な調整などが発生しがちで、マイクロフロントエンドはそもそも概念としてそもそもビルドサイズは無視しているので、その辺のベストプラクティスがない。
考えられる手段としては…
- どちらかに webpack のビルド系統を統一して、例えばヘッダ側がライブラリとして振る舞い、 peerDependencies を指定(個人的におすすめ)
- さらにメタな vendor チャンクを用意して、そこからライブラリを共有(複数webpack間で共有できるチャンクを作れるのか、自分が知らないので要調査)
- とにかくお互いのサイズなどを考えないでいいように、preact や lit-html などで小さく作る。
という感じになるのではないか。
おわり
ちなみに、この辺の最適化が最初からやられているのが next.js なので、これを理解した上で next.js のベストプラクティスを保つと、ハイパフォーマンスなアプリになります。
server side push の仕様が死んだ今、しばらく webpack 捨てられないので、社内の誰か一人がこの辺を学んでおくといいと思います。