RAGってなに?-RAGの基礎を実装してみた-
🚩はじめに
RAG(Retrieval-Augmented Generation)とは検索拡張生成の略で、LLMの学習データには含まれない、特定の文書などの情報を読み込ませて、回答の精度を高める生成AIです。
確かに大量にある社内文書やマニュアルなどを外部に漏らすことなく、AIで検索する術があることは、多くの人にとって便利で実用的だと考えました。
そこで、簡易的な文書を作成しRAGの基礎を実装することで理解を深めようと思いました🧚♀️
🪢今回のRAG実装の準備
今回はRAGの最低限を理解するために以下の社内システムFAQのサンプル文書を用意しました。
【社内システム よくある質問FAQ】
Q1. パスワードの有効期限はありますか?
A1. 有効期限は90日です。
Q2. ログはどこに保存されていますか?
A2. logs/app.log に保存されています。
Q3. アカウントロックは何回失敗で起きますか?
A3. 5回連続でログインに失敗するとロックされます。
こちらから検索して、ユーザの問いに応答できる仕組みを作ります🪄
🍁実装コード
・ MiniLM を使って、「文章 → 数列(ベクトル)」に変換できるよう準備します。
ベクトル化とは、文章をAIが読み込める形にするため、数列に変換する処理です。
この数列の並びを元に、近しい回答を生成する仕組みを作ります。
// 文章を数列にする
async function main() {
const embedder = await pipeline("feature-extraction", "Xenova/all-MiniLM-L6-v2");
}
・ OpenAI API を使うための設定。
apiKey は環境変数から読み取るようにして安全に扱います。
// LLMを使う準備
const client = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
baseURL: "https://api.openai.com/v1",
});
・ RAGが参照する(今回は社内システムFAQ)を読み込みます。
// 検索したい文章を読み込む
const docs = [
fs.readFileSync("doc1.txt", "utf-8"),
];
・ docsに入っている文章を1つずつ渡してベクトル化をします。
結果は、docEmbeddingsに保存され後で類似度を測るために使います。
// 文章をベクトルに変換する
const docEmbeddings = await Promise.all(
docs.map(async (d) => {
const output = await embedder(d);
return Array.from(output.data[0]);
})
);
・ ユーザからの質問もベクトルに変換します。
// ユーザーからの質問をベクトル化する
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
const query = await new Promise((resolve) => {
rl.question("質問を入力してください: ", (answer) => {
rl.close();
resolve(answer);
});
});
const queryEmb = await embedder(query);
const qvec = Array.from(queryEmb.data[0]);
・ 上記でベクトル化した質問ベクトル と 文書ベクトル を比較して、一番近いものを探します。
コサイン類似度というものを使用し、1に近いほど似ている文章を指します。
// もっとも近い文書を見つける
// 似ている度を計算する関数(コサイン類似度)
// bestDocに最も似ている文章を入れる
function cosineSimilarity(a, b) {
const dot = a.reduce((sum, v, i) => sum + v * b[i], 0);
const na = Math.sqrt(a.reduce((s, v) => s + v * v, 0));
const nb = Math.sqrt(b.reduce((s, v) => s + v * v, 0));
return dot / (na * nb);
}
let bestDoc = docs[0];
let bestScore = -1;
docEmbeddings.forEach((vec, i) => {
const score = cosineSimilarity(vec, qvec);
if (score > bestScore) {
bestScore = score;
bestDoc = docs[i];
}
});
・ 最も近い答えが見つかったら、LLMに渡して回答の生成に移ります。
// LLMに質問する
const response = await client.chat.completions.create({
model: "gpt-4.1-mini",
messages: [
{ role: "system", content: `参考文書: ${bestDoc}` },
{ role: "user", content: query },
],
});
// 回答を出力する
console.log("回答:");
console.log(response.choices[0].message.content);
}
main();
そうすると、、
コンソールに質問を入力する欄が作られました✨
試しに以下のように質問すると
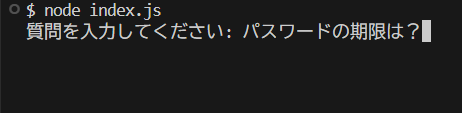
事前に作成していた社内システムFAQから答えが返ってきました🎆

これをもって、ユーザの質問に対し適切な答えを文書の中から検索し、回答してくれているRAGについての基礎を理解できたといえるのではないでしょうか。
🎀まとめ
今回は、「文書の読み込みベクトル化→検索→LLMで回答の生成」というRAGの基本について学習しました。実用化するには、大量のデータを読み込む必要があるためその精度を上げること、PDFを読み込ませる方法など多岐にわたって複雑化していく必要があります。こちらも今後学習していければ良いと考えています!