はじめに
最近、日々の技術調査やメモを Obsidian などのナレッジツールに蓄積している方は多いと思います。私も普段の調べたことや気になるWebサイトの情報、タスク管理等様々な情報を蓄積しています。また、ObsidianはMarkdown形式の情報を扱うこともあり生成AIとの相性よく一緒に活用することが多いです。
そういった情報源時間と共に様々な情報が蓄積されます。そして蓄えるだけはなく何か別の形で活用したくなりますよね。RAGの情報源等として活用することは多いのではないでしょうか。
私も最近それを試してみようと思い今回はFoundry IQの調査もかねて構築してみました。
本記事では、題材としてObsidian Vault にあるmarkdownの情報源をFoundry IQ の Knowledge Base として活用する方法を解説します。特に、推論レベル(retrievalReasoningEffort) と 応答モード(outputMode) の設定による応答の違いにフォーカスし、実際の検索結果を比較し単純なRAGだけでないFoundry IQの便利なところを紹介したいと思います。
従来の RAG との違い
従来のRAGとFoundry IQで利用できるAgentic Retrievalの違いを簡単にまとめてみました。Microsoftの公式のイベント等でもよく「Foundry IQに情報を入れるだけでよしなに最適な情報を取得できるようになる」という話聞いたことがあるかもしれません。Agentic Retrievalの名の通り、情報取得に特化したエージェントを構築することでFoundry IQ内のさまざまな情報源をより最適な形で取得できるようになります。
| 従来の RAG | Foundry IQ(Agentic Retrieval) | |
|---|---|---|
| クエリ処理 | ユーザーのクエリをそのまま検索 | AI がクエリを分解・最適化 |
| ソース選択 | 開発者が事前に指定 | AI が質問に応じてソースを自動選択 |
| 検索方式 | ベクトル or キーワード | ハイブリッド + セマンティックランキング |
| 結果評価 | なし | 反復リフレクション(medium 以上) |
| 開発負担 | インデクサー・クエリ設計が必要 | Knowledge Source 定義のみ |
(参考) Obsidianの情報同期について
今回はFoundry IQに関する事がメインなので、解説はObsidian Vaultの情報をBlob Storageに格納した状態からスタートしています。
実際、これを実現するにあたって、ローカルで使っているObsidian Vaultの情報をAzure Blob Storageに同期化しています。
Azure VMを利用してObsidianのプラグイン[Self-Hosted LiveSync]でVM上にObsidian Vaultを同期化し、Blob Storageへ格納しています。(少し横着してローカルPC⇔Azure VM間は同期時のみTailscaleでVPN接続しています)
Foundry IQ の基本概念
Foundry IQ は、Microsoft Foundry(旧 Azure AI Foundry)が提供するエージェント型ナレッジ検索基盤です。従来の RAG(Retrieval-Augmented Generation)と比較して、AI がクエリを分解し、最適なソースを選択し、検索結果を評価・合成するという高度な検索パイプラインを自動で構築してくれます。
アーキテクチャ
今回は一例としてBlob StorageからFoundry IQに情報を格納しています。全体の簡易的な概要図は以下の通りです。Blob Storageの情報からFoundry IQにナレッジソースとしてインデクサーを作成し知識として活用します。そして、これらの情報を扱うためのKnowledge Baseを接続します。Foundry IQのもっとも面白い機能はこのKnowledge Baseだと思います。
Knowledge Baseは複数のKnowledge Sourceを活用しユーザーからの情報取得要求内容に応じて使用するKnowledge Sourceを切替えて応答を返します。
Knowledge BaseはMCPサーバーとして活用することができます。
Microsoft Foundryを利用している場合はKnowledgeとして追加されます。
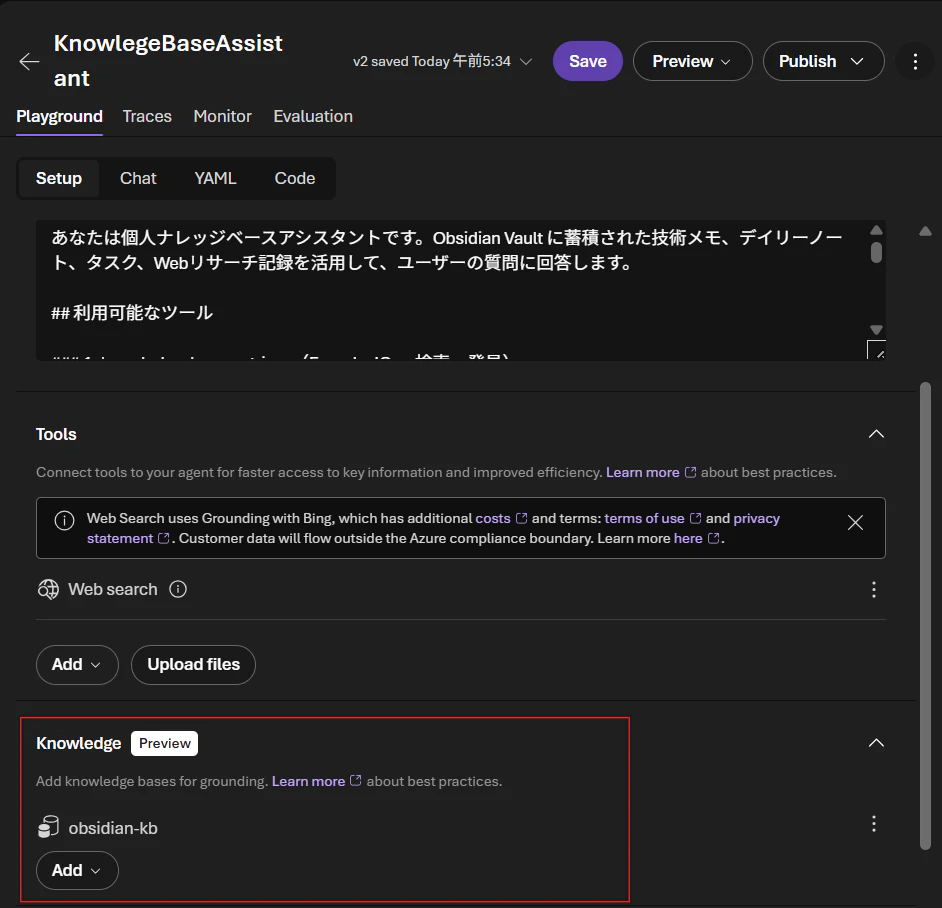
主要コンポーネント
Foundry IQの主要コンポーネントです。ナレッジを利用する側から見るとKnowledge Baseを呼び出すことでAgentic Retrieval Engineがその内容に応じて最適なSourceから情報を引き出します。Agenticというキーワードで気づくかと思いますが、Agentic Retrieval Engineは生成AIを活用して情報の最適化を図っている仕組みです。見方を変えるとナレッジを最適に返すAgentを構築する仕組みともいえるかもしれません。
| コンポーネント | 役割 |
|---|---|
| Knowledge Source | データソース(Blob Storage 等)と接続し、インデクサー・インデックス・スキルセットを自動生成 |
| Knowledge Base | 複数の Knowledge Source を統合管理し、Agentic Retrieval を実行するオーケストレーター |
| Agentic Retrieval Engine | クエリ分解 → ソース選択 → ハイブリッド検索 → セマンティックランキング → 回答合成 |
Knowledge Source の種類
Foundry IQは記事時点では以下のソースを扱うことができます。本記事では azureBlob を使用します。
| kind | 種別 | 説明 |
|---|---|---|
azureBlob |
Indexed | Azure Blob Storage からインデックス化 |
searchIndex |
Indexed | 既存の AI Search インデックスを参照 |
indexedSharePoint |
Indexed | SharePoint からインデックス化 |
remoteSharePoint |
Remote | SharePoint Copilot API 経由のリアルタイム検索 |
web |
Remote | Bing 検索(パブリック Web) |
前提条件
今回はFoundry IQを利用する為にいくつかのAzureのサービスの構築が必要です。今回のBlob StorageをFoundry IQとして活用する場合の例として参考にしてください。
必要な Azure リソース
Foundry IQを利用する際に必ず必要なのがAzure AI Searchと内部で利用する生成AIサービスです。Foundryでホストしている生成AIをAPI経由で設定することも可能です。今回は最終的にMicrosoft Foundryで使う予定だったのでFoundryにデプロイしたモデルを使用しました。
また、注意が必要なこととしてAzure AI Searchは使うデータ量によってSKUを変える必要があります。おそらくプレビュー版だからだと思いますが、SKUの設定は作成時のみなので、後から容量調整する為には削除→再作成が必要です。また、課金はサービスをデプロイした時点で発生し、削除しない限り課金されます。
お試しであればFree(50mb)からでいいと思います。
また、これ以外に関連する生成AIの利用料、データアクセス等でも課金はされるので使用頻度によってはかなりの高額になるため注意が必要です。
| リソース | SKU | 用途 | 月額目安 |
|---|---|---|---|
| Azure Blob Storage | Standard_LRS | ナレッジファイルの格納 | ~300円 |
| Azure AI Search | Basic 以上 | Knowledge Base + インデクサー | ~11,000円 |
| Azure OpenAI | — | Embedding + クエリ計画 | ~1,500円 |
AI Search の Basic tier 以上が必要です(Semantic Ranker が必須のため)。検証が終わったら AI Search を削除すれば Blob Storage のみ(~300円/月)に抑えられます。
必要なデプロイメント
Foundry IQは内部ではいくつか生成AIを利用します。今回はFoundryでホストされたOpenAIモデルを利用しました。
| Azure OpenAI デプロイメント | 用途 |
|---|---|
text-embedding-3-large(または text-embedding-3-small) |
Knowledge Source の Embedding 生成 |
gpt-5-mini(または gpt-4.1-mini) |
Knowledge Base のクエリ計画・回答合成 |
SDK / ツール
ツール関係ですが、Blob StorageからFoundry IQへのデータの投入はPython SDKを使って行いました。今回環境として利用したのは以下の通りです。
- Python 3.10+
pip install python-dotenv requests- Azure CLI(
azコマンド)
データの準備(Blob Storage)
今回は Obsidian Vault の情報を Azure Blob Storage に格納し、情報カテゴリ毎に Knowledge Source を分けます。
コンテナ設計
今回はObsidian Vaultの情報を以下のように分割しました。普段の管理として技術調査、Webサイトで気になった時のメモ、日報、タスクといくつかフォルダ階層にわけて管理しているのでその構造に合わせて分割しています。
| Vault フォルダ | Blob コンテナ | 内容 |
|---|---|---|
010_Tech/ |
obsidian-010-tech |
技術調査資料 |
000_Research/ |
obsidian-000-research |
Web 記事要約 |
020_DaylyNote/ |
obsidian-020-daily |
デイリーノート |
030_Tasks/ |
obsidian-030-tasks |
タスク・イベント |
フォルダごとにコンテナを分けることで、それぞれでリソースを作成します。これによってKnowledge Source 単位での検索制御が可能になります。また、全体でRAG化するよりも最適化されることを期待しています。
この他、例えば「技術的な質問には obsidian-010-tech を優先」といったルーティングが実現できます。
(参考)Blob Storage の作成
今回はAzure VM上にObsidian Vaultの情報があるので一手間加えています。Knowledge Sourceを作成するためにローカルPCのVaultの情報をAzure VM上で同期しさらにBlob Storageに送っています。
# リソースグループ作成
az group create --name rg-obsidian --location japaneast
# ストレージアカウント作成
az storage account create \
--name <ストレージアカウント名> \
--resource-group rg-obsidian \
--location japaneast \
--sku Standard_LRS \
--kind StorageV2
# コンテナ作成
for container in obsidian-010-tech obsidian-000-research obsidian-020-daily obsidian-030-tasks; do
az storage container create --name $container --account-name <ストレージアカウント名>
done
データのアップロードは azcopy sync で定期同期しています。
# 初回同期(例: 010_Tech フォルダ)
azcopy sync \
"/path/to/obsidian-vault/010_Tech" \
"https://<ストレージアカウント名>.blob.core.windows.net/obsidian-010-tech" \
--recursive
# 全フォルダを一括同期するスクリプト例
FOLDERS=("010_Tech:obsidian-010-tech" "000_Research:obsidian-000-research" "020_DaylyNote:obsidian-020-daily" "030_Tasks:obsidian-030-tasks")
for entry in "${FOLDERS[@]}"; do
IFS=":" read -r folder container <<< "$entry"
azcopy sync "/path/to/obsidian-vault/$folder" \
"https://<ストレージアカウント名>.blob.core.windows.net/$container" \
--recursive --delete-destination=true
done
認証には Managed Identity(azcopy login --identity)または SAS トークンが利用可能です。定期実行には cron や Docker サイドカーでの自動化が効果的です。
Knowledge Source の作成
Foundry IQにKnowledge Source を作成すると、インデクサー・インデックス・スキルセット・データソースが自動生成されます。手動での AI Search インデクサー構成は不要です。
Azure Portal と Python SDK のどちらからでも作成できます。
Azure Portal から作成する場合
ここでは、Azure AI Searchが作成済みの状態からの手順を紹介します。Azure AI Searchの作成については特に難しい設定はないのですが先ほど話した通りで作成時に容量を決める必要があるのでそこだけ注意してください。
- Azure Portal で AI Search リソースを開く
- 作成済みのAzure AI Searchを開く

- 左メニューの 「Knowledge sources」 を選択し、「+ Add knowledge source」 をクリック

- リソースのタイプを選択できるので、**Azure Blob(インデックス付き)**を選択します

- ナレッジリソースの設定をおこないます。
必須以外の項目は任意で設定します。今回はテキストのベクトル化、イメージの言語化も設定しました。
- 名前:任意の名前
- 説明:任意の説明
- サブスクリプション:ストレージアカウントの存在するサブスクリプション
- ストレージ アカウント : ナレッジリソース化するストレージアカウントを選択
- BLOB コンテナー : ナレッジリソース化するコンテナーを選択
- BLOB フォルダー : フォルダ指定をしたい場合は設定する(空の場合全体)
- モード : 最小/標準から選択(今回は最小)。標準を選択した場合Microsoft Foundryリソースとして登録されます。
- 「テキストベクトル化を有効にする」、「イメージの言語化を有効にする」を設定します。
今回はFoundryにデプロイしているtext-embedding-3-largeを設定しました。
- 最後にスケジュールを選択します。デフォルトは1日です。指定した間隔でリソースの整理が行われます。
- 「Create」 をクリック
この手順を Blob コンテナごとに繰り返します(今回は 4 つ)。
コストを考慮して「テキストベクトル化を有効にする」、「イメージの言語化を有効にする」を使わない方法も可能です。この場合テキストについては全文検索、画像、PDF等は対象外になります。
Python SDK で作成する場合
API スキーマの注意点: Foundry IQ はプレビュー機能のため、API のプロパティ名が変更されることがあります。例えば type → kind、resourceUrl → resourceUri、deploymentName → deploymentId などの変更がありました。エラーが出た場合は 最新の API リファレンス を確認してください。
import os
import requests
from dotenv import load_dotenv
load_dotenv()
SEARCH_ENDPOINT = f"https://{os.getenv('AZURE_SEARCH_SERVICE')}.search.windows.net"
SEARCH_API_KEY = os.getenv("AZURE_SEARCH_API_KEY")
AOAI_ENDPOINT = os.getenv("AZURE_OPENAI_ENDPOINT")
AOAI_API_KEY = os.getenv("AZURE_OPENAI_API_KEY")
BLOB_CONN_STR = os.getenv("AZURE_BLOB_CONNECTION_STRING")
API_VERSION = "2025-11-01-preview"
headers = {
"api-key": SEARCH_API_KEY,
"Content-Type": "application/json",
"Prefer": "return=representation",
}
# Knowledge Source の定義
sources = [
("obsidian-010-tech-ks", "obsidian-010-tech",
"技術調査資料。Azure, AI, XR等の技術メモ。"),
("obsidian-000-research-ks", "obsidian-000-research",
"Webアクセス履歴から整理した興味記事の要約。"),
("obsidian-020-daily-ks", "obsidian-020-daily",
"デイリーノート。タスク実績、気づき、学びの記録。"),
("obsidian-030-tasks-ks", "obsidian-030-tasks",
"タスクとイベント。期限管理、Wish リスト。"),
]
for ks_name, container, description in sources:
body = {
"name": ks_name,
"description": description,
"kind": "azureBlob", # ※ "type" ではなく "kind"
"azureBlobParameters": {
"connectionString": BLOB_CONN_STR,
"containerName": container,
"isAdlsGen2": False,
"ingestionParameters": {
"disableImageVerbalization": True,
"embeddingModel": {
"kind": "azureOpenAI", # ※ "type" ではなく "kind"
"azureOpenAIParameters": {
"resourceUri": AOAI_ENDPOINT, # ※ "resourceUrl" ではない
"apiKey": AOAI_API_KEY,
"deploymentId": "text-embedding-3-large", # ※ "deploymentName" ではない
"modelName": "text-embedding-3-large",
}
},
"contentExtractionMode": "minimal",
}
}
}
url = f"{SEARCH_ENDPOINT}/knowledgesources('{ks_name}')?api-version={API_VERSION}"
resp = requests.put(url, headers=headers, json=body)
if resp.status_code in (200, 201):
print(f" {ks_name} created")
else:
print(f" {ks_name} failed: {resp.text[:200]}")
disableImageVerbalization と chatCompletionModel の排他制約について
chatCompletionModel は、インジェスト時に 画像を自然言語に変換(Image Verbalization) したり、ドキュメントからコンテキストを抽出するために使用される LLM です(API リファレンス)。disableImageVerbalization: true を設定すると画像言語化機能自体が無効化されるため、その処理を担う chatCompletionModel の指定と矛盾します。そのため同時設定するとエラーになります。
Markdown ファイルのみを扱う場合は画像の言語化は不要なので、disableImageVerbalization: true で chatCompletionModel を省略するのがコスト面でも最適です。逆に、PDF や画像を含むドキュメントを扱う場合は disableImageVerbalization: false(デフォルト)のまま chatCompletionModel に gpt-4.1-mini 等を指定してください。
インデクサーの動作
Knowledge Source を作成すると、以下が自動生成されます:
| 自動生成されるリソース | 名前の例 | 役割 |
|---|---|---|
| データソース | obsidian-010-tech-ks-datasource |
Blob Storage への接続 |
| インデクサー | obsidian-010-tech-ks-indexer |
定期的にデータを取得・インデックス化 |
| インデックス | obsidian-010-tech-ks-index |
検索用インデックス |
| スキルセット | obsidian-010-tech-ks-skillset |
テキスト分割 + Embedding 生成 |
インデクサーはデフォルトで 1日1回 自動実行されます。
初回インジェストの所要時間について: 初回実行時はすべてのファイルのチャンキング・Embedding 生成が行われるため、ファイル数が多い場合は 数時間かかる可能性 があります。数千〜数万ファイル規模の Vault では、Basic tier で 2〜4 時間程度を見込んでください。2 回目以降は差分のみの処理となるため短時間で完了します。インデクサーの進捗は Azure Portal の AI Search リソース > インデクサー画面で確認できます。
Knowledge Base の作成
Knowledge Base は複数の Knowledge Source を束ね、Agentic Retrieval を制御するオーケストレーターです。ここで推論レベルと応答モードを設定します。
Azure Portal から作成する場合
- AI Search リソースの左メニューから 「Knowledge bases」 を選択
-
「+ Add knowledge base」 をクリック。設定画面が表示されます。

- 以下を設定:
- 基本
-
Name:
obsidian-kb - Description: ナレッジベースの説明
- Knowledge sources: 先ほど作成した 4 つの Knowledge Source を全て選択
-
Name:
- 取得
- 推論作業: 最小/低/中(低推奨。詳細は後述)
- 取得時の指示: 検索時のソース選択ルール(例:「技術的な質問には obsidian-010-tech-ks を優先」)
- チャット補完モデル
取得時に使用する生成AIモデル
- 出力構成
- 出力モード: 応答の合成/抽出データ(今回は応答の合成を選択)
- 回答手順: 回答生成ルール(例:「日本語で回答せよ」)※出力モードが応答の合成の場合
- 基本
- 「Create」 をクリック
Python SDK で作成する場合
KB_NAME = "obsidian-kb"
body = {
"name": KB_NAME,
"description": "個人ナレッジベース。技術メモ、デイリーノート、タスク管理、Webリサーチ記録を統合検索する。",
"retrievalInstructions": (
"検索クエリの内容に応じて適切なソースを選択せよ。"
"技術的な質問には obsidian-010-tech-ks を優先。"
"日々の活動やスケジュールには obsidian-020-daily-ks と obsidian-030-tasks-ks を使用。"
"Webで見た記事については obsidian-000-research-ks を使用。"
"複数ソースにまたがる質問は並列検索せよ。"
),
"answerInstructions": (
"日本語で回答せよ。引用元のファイルパスを必ず提示せよ。"
),
"outputMode": "answerSynthesis",
"knowledgeSources": [
{"name": ks_name} for ks_name, _, _ in sources
],
"models": [{
"kind": "azureOpenAI",
"azureOpenAIParameters": {
"resourceUri": AOAI_ENDPOINT,
"apiKey": AOAI_API_KEY,
"deploymentId": "gpt-5-mini",
"modelName": "gpt-5-mini",
}
}],
"retrievalReasoningEffort": {
"kind": "low" # ※ 文字列ではなくオブジェクト
},
}
url = f"{SEARCH_ENDPOINT}/knowledgebases('{KB_NAME}')?api-version={API_VERSION}"
resp = requests.put(url, headers=headers, json=body)
if resp.status_code in (200, 201):
print(f"Knowledge Base '{KB_NAME}' created")
mcp_endpoint = (
f"{SEARCH_ENDPOINT}/knowledgebases/{KB_NAME}"
f"/mcp?api-version={API_VERSION}"
)
print(f"MCP Endpoint: {mcp_endpoint}")
else:
print(f"Failed: {resp.text[:200]}")
設定パラメータの解説
Knowledge Base の3つの重要な設定について詳しく見ていきます。これらのパラメータは推論の質や速度に影響があるため都度適切に設定する必要があります。
推論作業(retrievalReasoningEffort) — 推論レベルの比較
推論作業(retrievalReasoningEffort) は、Foundry IQ がどれだけ「考えて」検索するかを制御します。Foundry IQでは思考の深さに応じて3つのレベルが定義されています。それぞれの処理イメージを模式図で表現しました。
それぞれの違いについては以下の通りです。レベルを最小にすると生成AIの推論が行なわれず単純なキーワード検索程度の能力まで落ちます。レベルの中に注目してください。設定すると反復検証も可能である一方、時間とコストがその分かかることになります。
| レベル | クエリ分解 | ソース選択 | セマンティックランキング | 反復リフレクション | 用途 |
|---|---|---|---|---|---|
| 最小 | n | n | y | n | 単純なキーワード検索 |
| 低 | y | y | y | n | 日常的なナレッジ検索(推奨) |
| 中 | y | y | y | y | 複雑な横断検索 |
応答の違い(実験)
実際にいくつかの応答の違いについて試してみました。ナレッジベースは、設定内容をチェックするためにチャットが使えるようになっています。
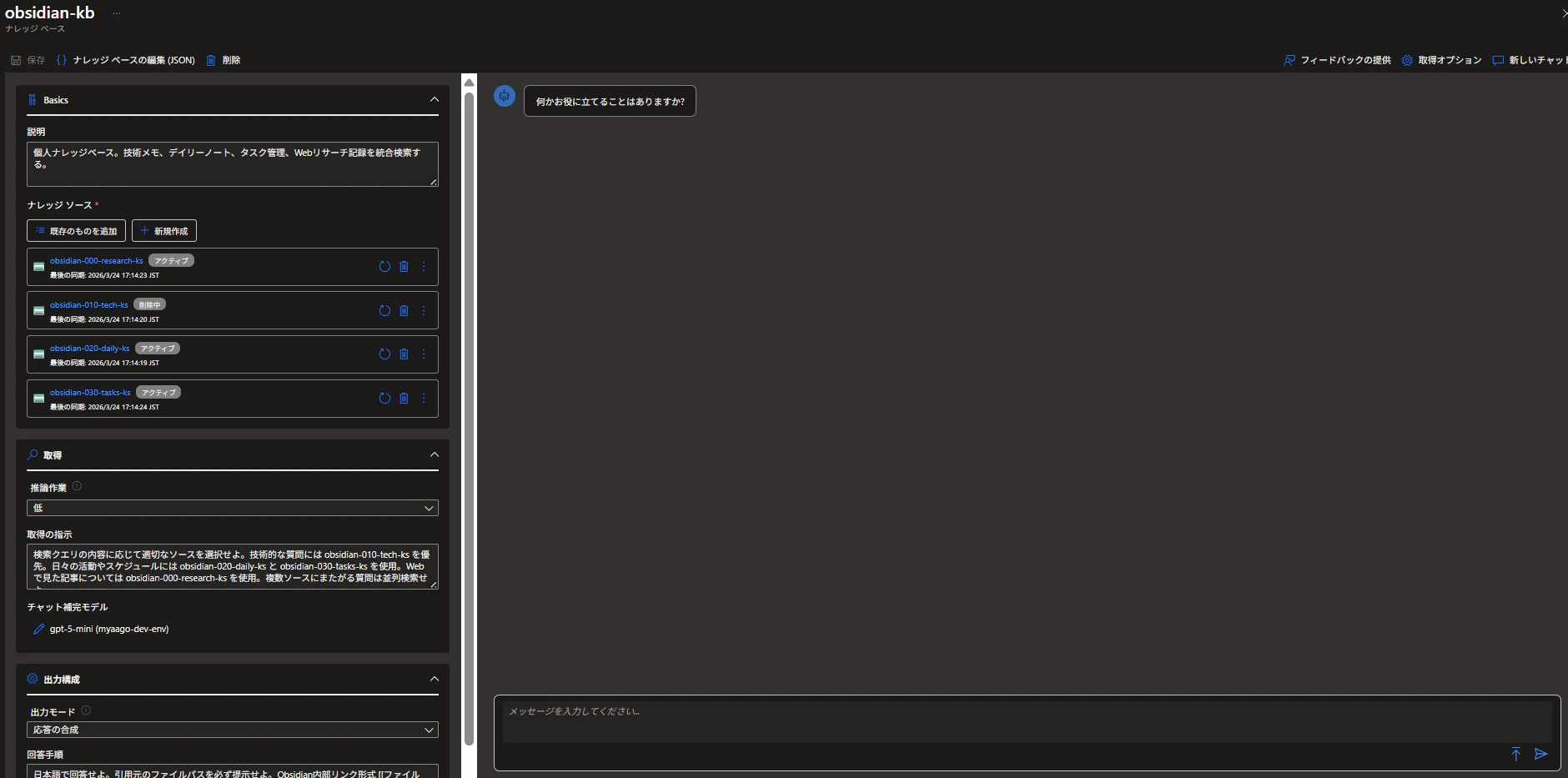
今回は個人ナレッジの中で以下のような質問を投げることでどういった情報の戻り方の違いがあるか試してみました。
質問: 「Microsoft FoundryとVoice Live API との関連は?」
ナレッジベースについては以下の情報を設定しています。
- 取得の指示
- 検索クエリの内容に応じて適切なソースを選択せよ。技術的な質問にはobsidian-010-tech-ks を優先。日々の活動やスケジュールにはobsidian-020-daily-ks と obsidian-030-tasks-ks を使用。Webで見た記事についてはobsidian-000-research-ks を使用。複数ソースにまたがる質問は並列検索せよ。
- 出力モード
- 日本語で回答せよ。引用元のファイルパスを必ず提示せよ。Obsidian内部リンク形式 [[ファイル名]] で参照先を示すこと。
推論作業の違い
推論の幅を変化させたときに応答の違いです。なお、最小を選択すると推論しない状態になるのですが、この場合は出力構成が「抽出データ」固定になります。
今回はBlob Storageに実データを使用しています。情報の中身が多岐にわたるため結果の違いがあまり伝わらないかもしれません。
なので検証結果が分かりやすいデータに今後差し替えるかもしれません。以下の内容は、できるだけ違いが分かるように解説はいれているつもりです。
抽出データ
最小の応答:
以下のようになりました。入力した条件に対してナレッジソースの関連性の高いファイルを単純に抽出している印象でした。ID:3,4のpptxはmarkdownからpptxに変換したテスト用のファイルで中身の情報はプレゼン資料のため、他のリソース(QiitaやWeb調査資料)に比べると情報量は少ないです(一方でキーワードは入ってるのでスコアは高い模様)。またID:5についてはyoutubeの概要欄の記載内容でこれも質問の情報の質からいうとあまりいい情報ではありません。
ドキュメントの内容をあまり吟味せずに抽出されていることが分かる結果になっていました。
| ID | ファイル | ナレッジソース |
|---|---|---|
| 1 | BRK198 - Voice Agents- Building the Conversational Enterprise Interface.md | obsidian-010-tech-ks |
| 2 | 2026-01-26 Microsoft Foundry ACS連携によるAIエージェント音声通話機能 | obsidian-010-tech-ks |
| 3 | voicelive-preview-pandoc-test.pptx | obsidian-010-tech-ks |
| 4 | voicelive-preview-editable.pptx | obsidian-010-tech-ks |
| 5 | Microsoft Foundry _ Voice Live API with Photo Avatar Demo on XR Devices_ _ YouTube.md | obsidian-000-research-ks |
| 6 | 2026-01-17 Voice Live API Avatar WebRTC.md | obsidian-010-tech-ks |
低の応答:
質問に対してかなり的確な情報を返していました。"最小"の応答の時に比べると、ソースの選択が行われていることが分かります。解説記事等の比較的情報量が多いドキュメントが選定されていました。なお、今回は偶然かもしれませんが、同じファイル名の方を返してきています。
| ID | ファイル | ナレッジソース |
|---|---|---|
| 1 | 【Microsoft Foundry】Voice Live APIでAvatarとリアルタイム会話を実現する - WebRTC接続の仕組みを詳解.md | obsidian-010-tech-ks |
| 2 | 音声ライブ API の使用方法 プレビュー _ Azure AI services _ Microsoft Learn.md | obsidian-000-research-ks |
| 3 | BRK198.pdf | obsidian-010-tech-ks |
| 4 | 音声ライブ API を使用する方法 _ Foundry Tools _ Microsoft Learn.md | obsidian-000-research-ks |
| 5 | 音声ライブ API の使用方法 プレビュー _ Azure AI services _ Microsoft Learn.md | obsidian-000-research-ks |
| 6 | Microsoft Foundry 概要.md | obsidian-010-tech-ks |
中の応答:
"低"の場合と同様、質問に対してかなり的確な情報を返していました。また、反復処理を行ったためかファイルの重複などは発生していません。"低"の場合は「音声ライブ API ~」のファイルが3つほど選定されている点を見ても反復処理が効いていると言えると思います。
| ランク | ファイル | ナレッジソース |
|---|---|---|
| 1 | 【Microsoft Foundry】Voice Live APIでAvatarとリアルタイム会話を実現する - WebRTC接続の仕組みを詳解.md | obsidian-010-tech-ks |
| 2 | Voice Live API リファレンス _ Foundry Tools _ Microsoft Learn.md | obsidian-000-research-ks |
| 3 | 音声ライブ API の使用方法 プレビュー _ Azure AI services _ Microsoft Learn.md | obsidian-000-research-ks |
| 4 | 2026-01-26 Microsoft Foundry ACS連携によるAIエージェント音声通話機能.md | obsidian-010-tech-ks |
| 5 | 2026-01-17 Voice Live API Avatar WebRTC.md | obsidian-010-tech-ks |
| 6 | voicelive-preview.pdf | obsidian-010-tech-ks |
出力モード(outputMode) — 応答モードの比較
outputMode は、検索結果をどのように返すかを制御します。
2つのモード
| モード | 説明 | 用途 |
|---|---|---|
抽出データextractiveData
|
元データからの抽出データをそのまま返す | 引用・参照・データ分析 |
応答の合成answerSynthesis
|
AI が検索結果を基に回答を合成する | 対話・要約・Q&A |
ポータルではナレッジベースの中で設定可能です。
SDKを使った場合の設定は以下の通りです。
# 抽出データモード
"outputMode": "extractiveData"
# 回答合成モード(推奨)
"outputMode": "answerSynthesis"
応答の違い(実験)
応答の違いについてですが、抽出データについては先ほど推論レベルの違いで出力結果を出しているので省略します。
(応答の合成)answerSynthesis の応答:
応答結果の一例
以下は、Microsoft Foundry と Voice Live API の関連性(統合の有無、連携方法、認証/エンドポイント/SDK/ユースケースの違い)について、取得された情報に基づく簡潔かつ技術的に正確な要点です。出典はファイルパス(Obsidian内部リンク形式)で併記します。
-
統合の有無(概要)
- Microsoft Foundry は AI アプリケーション/エージェント開発の統合プラットフォームであり、Azure Speech(Voice Live API を含む)が Foundry の中核コンポーネントとしてシームレスに統合されている。Foundry 上で音声認識→生成→音声合成まで一気通貫で扱えることが明示されている。[1][2] [[obsidian-010-tech-ks-index]]
-
利用シナリオ(ユースケースの違い)
- Foundry の役割:Agent Service やテンプレート(例:Call Center Voice Agent)を通じて、エージェントの構築・ホスティング・管理やワークフロー統合を提供するプラットフォーム機能を担う。[2][1] [[obsidian-010-tech-ks-index]]
- Voice Live API の役割:低遅延リアルタイム音声会話を実現する API 群(音声入力(STT)、生成AI、音声出力(TTS)、ノイズ抑制・エコーキャンセル・割り込み検出などの会話機能拡張、Avatar 統合など)。コールセンターや騒音環境での応答、自動応答電話業務などの音声インタラクションに着目した機能群を提供する。[2][1][3] [[obsidian-010-tech-ks-index]]
-
技術的接続方法(エンドポイント/認証方式/SDK/サンプルフロー)
- エンドポイントと API バージョン:Voice Live を利用するエンドポイント(例: https://your-endpoint.azure.com)と API バージョン(例: 2025-05-01-preview)がサンプル内で明示されている。4 [[obsidian-010-tech-ks-index]]
- 認証方式:取得コンテンツでは API キー(例: header に api-key を指定する形式)を使った接続確認コマンドの例が示されている(curl のヘッダ指定)。これがサンプルの認証方法として利用されていることが読み取れる。[5] [[obsidian-010-tech-ks-index]]
- SDK:Foundry 向け SDK や C# 用のサンプル実装が存在し、Foundry 連携や Voice Live API のサンプルは GitHub リポジトリやドキュメントに公開されている。Foundry 用 SDK の配布やドキュメント参照リンクが案内されている(SDK ダウンロード、ドキュメント参照の案内)。[1][6][3] [[obsidian-010-tech-ks-index]]
- 通信プロトコルとサンプルフロー:
- Foundry と Voice Live API(Avatar 利用時)は、まず WebSocket で Foundry サーバへ接続し session.update などで avatar 使用を宣言、その応答に含まれる ICE サーバ情報を用いてクライアントと Avatar サーバ間で WebRTC ペアリング(SDP オファー/アンサーの交換)を行い、最終的に H.264 映像ストリームと Opus オーディオストリームがクライアントへ配信されるフローが示されている。[2][6] [[obsidian-010-tech-ks-index]]
- サンプルでは WebSocket メッセージ例(session.avatar.connect 等)や SDP Base64 エンコードの扱い、受信側で setRemoteDescription(answer) を呼ぶ流れが示されている。[6] [[obsidian-010-tech-ks-index]]
- 実装サンプル(提示があるが詳細コードは省略):
- Unity/C# のサンプルがあり、開始処理で WebSocket 初期化→OnConnect→SessionUpdate するフローや、音声バッファ処理の概略が掲載されている(詳細はサンプル参照)。[4] [[obsidian-010-tech-ks-index]]
-
注意点/運用上のポイント
- Avatar を利用する場合は WebSocket に加え WebRTC(P2P)接続が必須であり、ICE/TURN の設定や SDP 交換を正しく実装する必要がある点に注意する。[2][6] [[obsidian-010-tech-ks-index]]
- 音声品質対策(ノイズ抑制、エコー除去、割り込み検出など)は Voice Live API が提供するが、現場(例:空港など高雑音)ではテストとチューニングが必要である(Gulf Air の導入事例が示されている)。[1][3] [[obsidian-010-tech-ks-index]]
- 認証/エンドポイント情報はサンプルにあるが、実運用ではセキュアな API キー管理や Foundry の Agent 設定(MCP サーバ設定など)を適切に行う必要がある(MCP サーバを Foundry ツールとしてセットアップする流れが説明されている)。[7][5] [[obsidian-010-tech-ks-index]]
-
不足している情報(追加確認を推奨)
- 正確な認証スキームの全面仕様(OAuth2 などのサポート有無)は取得資料に明確な記載がない。API キーの使用例はあるが、エンタープライズ向けの推奨認証フローやロール/権限制御の詳細は追加確認が必要である。[5][4] [[obsidian-010-tech-ks-index]]
- 実際の API レスポンススキーマ、エラーコード一覧、レート制限やコストに関する詳細は取得資料に含まれていないため、公式ドキュメントの該当ページ参照を推奨する。[6][3] [[obsidian-010-tech-ks-index]]
-
提案(実務向け)
- まずは Foundry の Call Center Voice Agent テンプレートでプロトタイプを作成し、Voice Live API を WebSocket + WebRTC(Avatar 必要時)で統合する流れを検証することを推奨する。具体的な実装サンプルや SDK、クイックスタートはサンプルリポジトリ/ドキュメントを参照してください。[1][6][3] [[obsidian-010-tech-ks-index]]
(出典)Obsidian ファイルパス: [[obsidian-010-tech-ks-index]]。各事実の引用元は以下の ref_id です。 [1][2][5][6][4][3][7]
| ID | ファイル名 | ナレッジソース |
|---|---|---|
| 1 | BRK198 - Voice Agents- Building the Conversational Enterprise Interface.md | obsidian-010-tech-ks |
| 2 | 【Microsoft Foundry】Voice Live APIでAvatarとリアルタイム会話を実現する - WebRTC接続の仕組みを詳解.md | obsidian-010-tech-ks |
| 3 | BRK198.pdf | obsidian-010-tech-ks |
| 4 | Azure AI Foundry Voice Live APIをUnityで使う実装解説.md | obsidian-010-tech-ks |
| 5 | README.md | obsidian-010-tech-ks |
| 6 | 【Microsoft Foundry】Voice Live APIでAvatarとリアルタイム会話を実現する - WebRTC接続の仕組みを詳解.md | obsidian-010-tech-ks |
| 7 | BRK198.txt | obsidian-010-tech-ks |
Instructions のカスタマイズ
Knowledge Base には2種類の Instructions を設定でき、検索と回答の挙動を制御します。
取得の指示(retrievalInstructions) — 検索の制御
検索時のソース選択やクエリ計画に影響します。
"retrievalInstructions": (
"検索クエリの内容に応じて適切なソースを選択せよ。"
"技術的な質問には obsidian-010-tech-ks を優先。"
"日々の活動やスケジュールには obsidian-020-daily-ks と "
"obsidian-030-tasks-ks を使用。"
"Webで見た記事については obsidian-000-research-ks を使用。"
"複数ソースにまたがる質問は並列検索せよ。"
)
ポイント: Knowledge Source 名を明示的に指定することで、AI のソース選択精度が向上します。
回答手順(answerInstructions) — 回答の制御
answerSynthesis モード時の回答生成に影響します。
"answerInstructions": (
"日本語で回答せよ。"
"引用元のファイルパスを必ず提示せよ。"
"Obsidian内部リンク形式 [[ファイル名]] で参照先を示すこと。"
)
ポイント: 回答のフォーマットや言語を指定できます。引用元の提示方法もここで制御します。
Foundry Agent Service との接続
作成した Knowledge Base は MCP エンドポイント として公開され、Foundry Agent Service から knowledge_base_retrieve ツールとして利用できます。
接続方法
Foundry ポータルから Agent を作成する場合、プロジェクトに AI Search の Connection を追加すると、Knowledge Base が自動的に認識されます。
- Foundry ポータル > Operate > Admin > Add connection > Azure AI Search
- AI Search のエンドポイントと認証情報を設定
- Agent Builder で Knowledge Base がツールとして表示される
SDK から接続する場合は、以下の手順で RemoteTool Connection の作成 → Agent 作成 → 質問 → クリーンアップを行います。
# 必要なパッケージのインストール(azure-ai-projects v2.x が必要)
pip install "azure-ai-projects>=2.0.0" azure-identity python-dotenv requests
Foundry IQを使ったエージェント作成&呼出
import os
import requests
from dotenv import load_dotenv
from azure.ai.projects import AIProjectClient
from azure.ai.projects.models import MCPTool, PromptAgentDefinition
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
load_dotenv()
# === 設定 ===
credential = DefaultAzureCredential()
project_endpoint = os.getenv("AZURE_AI_PROJECT_ENDPOINT")
project_resource_id = os.getenv("AZURE_AI_PROJECT_RESOURCE_ID")
search_service_endpoint = os.getenv("AZURE_SEARCH_ENDPOINT")
search_api_key = os.getenv("AZURE_SEARCH_API_KEY")
knowledge_base_name = "obsidian-kb"
project_connection_name = "obsidian-kb-mcp-connection"
agent_name = "obsidian-knowledge-agent"
agent_model = "gpt-5.4-mini" # プロジェクトにデプロイ済みのモデル名
mcp_endpoint = (
f"{search_service_endpoint}/knowledgebases/{knowledge_base_name}"
f"/mcp?api-version=2025-11-01-preview"
)
# === Step 1: RemoteTool Connection の作成 ===
# ポータルが自動作成する Connection と同等のものを SDK から作成する。
# 重要: authType は "CustomKeys" を使用すること。
# 公式ドキュメントでは "ProjectManagedIdentity" が推奨されているが、
# ポータルが実際に作成する Connection は "CustomKeys" であり、
# "ProjectManagedIdentity" では 403 Forbidden が発生する場合がある。
print("Step 1: Creating RemoteTool connection...")
bearer_token_provider = get_bearer_token_provider(
credential, "https://management.azure.com/.default"
)
headers = {"Authorization": f"Bearer {bearer_token_provider()}"}
response = requests.put(
f"https://management.azure.com{project_resource_id}"
f"/connections/{project_connection_name}?api-version=2025-10-01-preview",
headers=headers,
json={
"name": project_connection_name,
"type": "Microsoft.MachineLearningServices/workspaces/connections",
"properties": {
"authType": "CustomKeys",
"category": "RemoteTool",
"target": mcp_endpoint,
"isSharedToAll": True,
"credentials": {
"keys": {
"api-key": search_api_key
}
},
"metadata": {
"type": "knowledgeBase_MCP",
"knowledgeBaseName": knowledge_base_name
}
}
}
)
response.raise_for_status()
print(f" Connection '{project_connection_name}' created.")
# === Step 2: Agent の作成 ===
print("Step 2: Creating agent...")
project = AIProjectClient(endpoint=project_endpoint, credential=credential)
openai = project.get_openai_client()
mcp_kb_tool = MCPTool(
server_label="knowledge-base",
server_url=mcp_endpoint,
require_approval="never",
allowed_tools=["knowledge_base_retrieve"],
project_connection_id=project_connection_name,
)
agent = project.agents.create_version(
agent_name=agent_name,
definition=PromptAgentDefinition(
model=agent_model,
instructions=(
"You are a helpful assistant that must use the knowledge base "
"to answer all questions.\n"
"Every answer must provide annotations from the knowledge base.\n"
"If you cannot find the answer, respond with 'I don't know'.\n"
"日本語で回答してください。"
),
tools=[mcp_kb_tool],
),
)
print(f" Agent '{agent.name}' created (version: {agent.version})")
# === Step 3: 質問 ===
print("Step 3: Sending query...")
conversation = openai.conversations.create()
response = openai.responses.create(
conversation=conversation.id,
input="Foundry IQ の Agentic Retrieval の仕組みを教えて",
extra_body={
"agent_reference": {"name": agent.name, "type": "agent_reference"}
},
)
print(f"Response: {response.output_text}")
# === Step 4: クリーンアップ ===
print("Step 4: Cleaning up...")
project.agents.delete_version(
agent_name=agent.name, agent_version=agent.version
)
print(" Agent deleted.")
# Connection の削除(任意)
# resp = requests.delete(
# f"https://management.azure.com{project_resource_id}"
# f"/connections/{project_connection_name}?api-version=2025-10-01-preview",
# headers={"Authorization": f"Bearer {bearer_token_provider()}"},
# )
# print(f" Connection deleted: {resp.status_code}")
-
azure-ai-projectsは v2.0.0 以上が必要です(v1.x とは互換性がありません) - 事前に
az loginで Azure CLI 認証を行ってください -
AZURE_AI_PROJECT_ENDPOINTは Foundry ポータルのプロジェクト詳細から取得できます(例:https://your-resource.services.ai.azure.com/api/projects/your-project) -
AZURE_AI_PROJECT_RESOURCE_IDは Azure Portal のプロジェクト概要ページの ARM リソース ID です(例:/subscriptions/.../providers/Microsoft.CognitiveServices/accounts/.../projects/...) - Step 1 で
RemoteToolカテゴリの Connection を自動作成しています。ポータルの Connected resources 画面には表示されませんが、REST API 経由で確認可能です -
authTypeはCustomKeysを使用してください。公式ドキュメントではProjectManagedIdentityが推奨されていますが、ポータルが作成する Connection はCustomKeysであり、ProjectManagedIdentityでは 403 エラーが発生する場合があります
エージェントからの検索フロー
まとめ
Foundry IQ を使うことで、Blob Storage に格納した個人ナレッジを開発負担最小限で AI 検索基盤にすることができました。
Foundry IQ の強み
- Knowledge Source を定義するだけでインデクサー・インデックス・スキルセットが自動生成
- Agentic Retrieval により、クエリ分解・ソース選択・ランキングを AI が自動実行
- 推論レベルの調整で精度とコストのバランスを制御可能
- Instructions のカスタマイズで検索・回答の挙動を柔軟に制御
推論レベルの使い分け
| ユースケース | 推奨レベル |
|---|---|
| 単純なキーワード検索 | minimal |
| 日常的なナレッジ検索 | low(推奨) |
| 複雑な横断検索・分析 | medium |