あけましておめでとうございます!
ついに2020年1月1日に公開するはずだったものが出来ました! やっと年が明けました!(2020/01/18現在)
ネズミ年ですね!
できたもの
遠隔でお経を唱える事ができるマシーン。IoB(*1)

念仏の遠隔操作に成功!
時間あったら全部Githubにアップします。
*1: Internet Of Buddha
きっかけ
2019年の12月24日にブッダマシーンが届いた。折角なので使いたい。
神々しい···#ブッダマシーン pic.twitter.com/hCMnFTHPzs
— みやた@画策中 (@miyata080825) December 24, 2019
どんなサービスを作るか
遠隔で念仏を唱えられるサービス。
ペルソナは、忙しくて念仏唱える暇がない人。
スマホでオッケーグー〇グル、お経読んでと言うとどこかしらでお経が流れる。便利。
どうつくるか想像する
- 念仏処理
- ESP32とブッダマシーン
- Webサービスでやる
- インテント解析
- サーバっていうかPC
- 文章から
お経読むのとかの判断をする
- 音声検知+STT
- Android
念仏処理のみが最高に難易度高い気がする。
何となくのシーケンスは下記参照
Mermaid対応のエディタでご覧ください。
作る順番は下記の通り(難易度順)
- 1.念仏処理
- 2.インテント解析
- 3.音声検知+STT
念仏処理
念仏機を遠隔で使える様に改造する。
- 念仏機の足を出す。
- 電源
- 次の念仏
- 一時停止/再生(使わない)
- 前の念仏
- リレー基板とマイコン基板用の電源基板作る
- 念仏機の足を動作させるためのリレー基板作る
- リレー基盤に信号を送るマイコン基板(ESP32)作る
- ESP32用のソフトを組む
ざっと書いたけど結構大変。
念仏機の足を出す
リレーで操作するだけなので極性など気にせずOK線を出すだけ。
スイッチがついている部分にはんだ付け。

後はケースに穴をあけて外に足を出す。

リレー基板とマイコン基板用の電源基板作る
電源はリレー用の5Vとマイコン用の3Vを作る。
回路図はこんな感じ
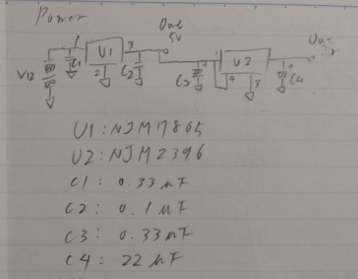
気が向いたら清書する
念仏機の足を動作させるためのリレー基板作る
フォトカプラ経由でリレーを動作させる。
回路図はこんな感じ。
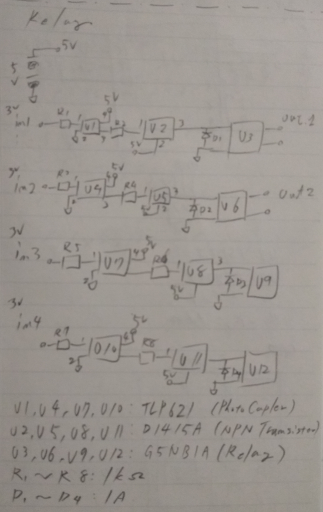
気が向いたら(ry
リレー基板に信号を送るマイコン基板作る
ESP32を使う。ほかの用途でI2Cを使おうとしてたので無駄に配線が多い。
36, 33と3から出てるスイッチは不要。
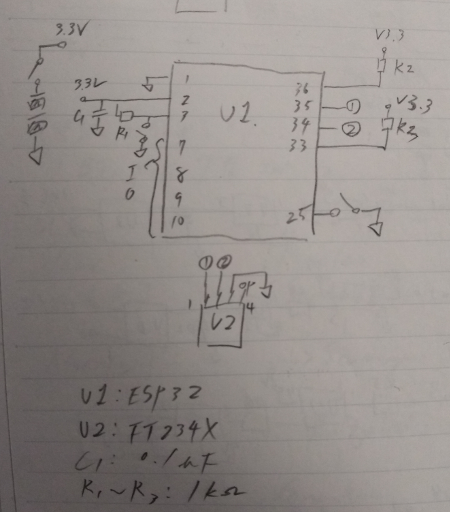
気が向い(ry
ESP32用のソフトを組む
やりたいことは念仏機制御用のWebApiインタフェース構築。
久々なので本家のGet Startedを一回やってからやる。
Restで組んでもよかったが様々な事情があり超絶面倒だったので全部Getでやった。
exampleのhttp_server/simpleにGPIOを組み合わせただけ。
static esp_err_t memorialbuddha_poweron_get_handler(httpd_req_t *req)
{
gpio_set_level(POWER_GPIO, 1);
const char* resp_str = (const char*) req->user_ctx;
httpd_resp_send(req, resp_str, strlen(resp_str));
if (httpd_req_get_hdr_value_len(req, "Host") == 0) {
ESP_LOGI(TAG, "Request headers lost");
}
return ESP_OK;
}
static const httpd_uri_t poweron = {
.uri = "/poweron",
.method = HTTP_GET,
.handler = memorialbuddha_poweron_get_handler,
.user_ctx = "poweron"
};
void app_main(void)
{
gpio_pad_select_gpio(POWER_GPIO);
gpio_set_direction(POWER_GPIO, GPIO_MODE_OUTPUT);
gpio_pad_select_gpio(PREV_GPIO);
gpio_set_direction(PREV_GPIO, GPIO_MODE_OUTPUT);
gpio_pad_select_gpio(PAUSE_GPIO);
gpio_set_direction(PAUSE_GPIO, GPIO_MODE_OUTPUT);
gpio_pad_select_gpio(NEXT_GPIO);
gpio_set_direction(NEXT_GPIO, GPIO_MODE_OUTPUT);
static httpd_handle_t server = NULL;
ESP_ERROR_CHECK(nvs_flash_init());
ESP_ERROR_CHECK(esp_netif_init());
ESP_ERROR_CHECK(esp_event_loop_create_default());
/* This helper function configures Wi-Fi or Ethernet, as selected in menuconfig.
* Read "Establishing Wi-Fi or Ethernet Connection" section in
* examples/protocols/README.md for more information about this function.
*/
ESP_ERROR_CHECK(example_connect());
/* Register event handlers to stop the server when Wi-Fi or Ethernet is disconnected,
* and re-start it upon connection.
*/
# ifdef CONFIG_EXAMPLE_CONNECT_WIFI
ESP_ERROR_CHECK(esp_event_handler_register(IP_EVENT, IP_EVENT_STA_GOT_IP, &connect_handler, &server));
ESP_ERROR_CHECK(esp_event_handler_register(WIFI_EVENT, WIFI_EVENT_STA_DISCONNECTED, &disconnect_handler, &server));
# endif // CONFIG_EXAMPLE_CONNECT_WIFI
# ifdef CONFIG_EXAMPLE_CONNECT_ETHERNET
ESP_ERROR_CHECK(esp_event_handler_register(IP_EVENT, IP_EVENT_ETH_GOT_IP, &connect_handler, &server));
ESP_ERROR_CHECK(esp_event_handler_register(ETH_EVENT, ETHERNET_EVENT_DISCONNECTED, &disconnect_handler, &server));
# endif // CONFIG_EXAMPLE_CONNECT_ETHERNET
/* Start the server for the first time */
server = start_webserver();
}
インテント処理
受け取った文言がなにか類推して念仏機のサービスを叩く。keras+flaskでやる。構成は以下の通り。
- train.py: 学習
- keywords.txt: 学習に使った語彙データ
- learning-data.txt: 学習データ
- memorial-buddha-intent.h5: 学習結果のモデルデータ
- memorial_buddha_action.py: 念仏機を動かすResource
- server.py: FlaskのWebService
- settings.json: 各種設定
- app_setting.py: setting保持
- common_proc.py: 共通処理
学習
適当に文言とインテント番号を振って、
| intent no | description |
|---|---|
| 1 | 念仏開始 |
| 2 | 次の念仏 |
| 3 | 前の念仏 |
| 4 | 念仏停止 |
学習データ適当に作る
念仏唱えて 1
念仏が聞きたい 1
今念仏の気分 1
お経唱えて 1
お経聞きたい 1
今日のお経をかけて 1
お経上げて 1
お経あげて 1
念仏かけて 1
次の念仏かけて 2
次のお経唱えて 2
前のお経唱えて 3
前の念仏唱えて 3
次のお経上げて 2
お経止めて 4
お経やめて 4
...
mecabでばらして単語単位にインデックス降って学習させる。
train.py
import MeCab
import re
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
keywords_filename = "keywords.txt"
train_filename = "learning-data.txt"
model_filename = "memorial-buddha-intent.h5"
train_pattern = r'([^ ]+) ([\d]+)'
sentence_tag_length = 64
keyword_length = 64
batch_size = 32
intent_length = 10
def createWordIndexFromFile():
global keywords_filename
global train_filename
global train_pattern
matcher = re.compile(train_pattern)
tagger = MeCab.Tagger()
keywords = []
with open(train_filename, 'r', encoding="utf-8") as f:
lines = f.readlines()
for line in lines:
line = line.replace('\n', '')
match_result = matcher.match(line)
if match_result != None:
text = match_result.group(1)
print('text: {0}'.format(text))
tagstring = tagger.parse(text)
tags = tagstring.split('\n')
for index in range(len(tags) - 2):
taginfos = tags[index].split('\t')
keywords.append("{0}".format(taginfos[0]))
keywords = dict.fromkeys(keywords)
keywords = sorted(keywords, key=lambda x: len(x) * -1)
for index in range(len(keywords)):
print('{0}: {1}'.format(index, keywords[index]))
with open(keywords_filename, "w", encoding="utf-8") as f:
f.write('\n'.join(keywords))
def getWordIndex():
keywords = []
with open(keywords_filename, "r", encoding="utf-8") as f:
lines = f.readlines()
for line in lines:
keywords.append(line.replace('\n', ''))
return keywords
def exchangeSentenceTags2WordIndexes(tags, keywords):
global sentence_tag_length
global keyword_length
global sentence_tag_length
global keyword_length
x = [[0.0 for i in range(sentence_tag_length)] for j in range(keyword_length)]
for tag_index in range(len(tags)):
for keyword_index in range(len(keywords)):
if tags[tag_index] == keywords[keyword_index]:
print("tag: {0}, tag index: {1}, keyword index: {2}".format(tags[tag_index], tag_index, keyword_index))
x[tag_index][keyword_index] = 1.0
break
return x
def getTrainData():
global train_filename
global train_pattern
global intent_length
global sentence_tag_length
global keyword_length
keywords = getWordIndex()
xs = []
ys = []
matcher = re.compile(train_pattern)
tagger = MeCab.Tagger()
with open(train_filename, 'r', encoding="utf-8") as f:
lines = f.readlines()
for line in lines:
line = line.replace('\n', '')
match_result = matcher.match(line)
if match_result != None:
sentence_tags = []
text = match_result.group(1)
print('text: {0}'.format(text))
tagstring = tagger.parse(text)
tags = tagstring.split('\n')
for index in range(len(tags) - 2):
taginfos = tags[index].split('\t')
sentence_tags.append("{0}".format(taginfos[0]))
x = exchangeSentenceTags2WordIndexes(
sentence_tags,
keywords)
xs.append(x)
y = [0.0 for i in range(intent_length)]
intent = int(match_result.group(2))
print("intent: {0}".format(intent))
y[intent] = 1.0
print(y)
ys.append(y)
trainx = np.array(xs)
trainy = np.array(ys)
print(trainx.shape)
print(trainy.shape)
return trainx, trainy
def main():
global sentence_tag_length
global keyword_length
global batch_size
global model_filename
input_vecsize = sentence_tag_length * keyword_length
createWordIndexFromFile()
x, y = getTrainData()
model = Sequential()
model.add(Dense(
input_vecsize,
input_shape=(sentence_tag_length, keyword_length, )))
model.add(Flatten())
model.add(Dense(2048))
model.add(Activation('relu'))
model.add(Dropout(0.1))
model.add(Dense(1024))
model.add(Activation('relu'))
model.add(Dropout(0.1))
model.add(Dense(1024))
model.add(Activation('relu'))
model.add(Dropout(0.1))
model.add(Dense(10))
model.add(Activation('softmax'))
model.compile(
optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(x, y, epochs=50, batch_size=batch_size)
model.save(model_filename)
if __name__ == "__main__":
main()
テキスト受け付けて結果を返す
Flaskの出番。まずはResource。
memorial_buddha_action.py
import MeCab
import re
import numpy as np
import keras
import traceback
from keras.models import load_model
from flask import request
from flask_restful import Resource
import urllib.request
from app_setting import AppSetting
from common_proc import CommonProc
class MemorialBuddhaAction(Resource):
def __init__(self, tagger, model, keywords, sample):
self.sentence_tag_length = 64
self.keyword_length = 64
self.batch_size = 32
self.setting = AppSetting()
self.tagger = tagger
self.model = model
self.keywords = keywords
print("Resource param: {0}".format(sample))
def post(self):
try:
json = request.get_json(force=True)
print(json)
sentence = json['text']
action_no = self.predict(sentence)
url = ""
if action_no == 1:
url = self.getMemorialBuddhaEndpoint("poweron")
if action_no == 2:
url = self.getMemorialBuddhaEndpoint("next")
if action_no == 3:
url = self.getMemorialBuddhaEndpoint("prev")
if action_no == 4:
url = self.getMemorialBuddhaEndpoint("poweroff")
if url == "":
return CommonProc.generateResultJsonData(
succeed=False,
message="cannnot specified intent.sentence is '{0}'".format(sentence)
)
req = urllib.request.Request(url)
with urllib.request.urlopen(req) as res:
body = res.read()
return CommonProc.generateResultJsonData(succeed=True)
except Exception as e:
message = "{0}".format(e.args)
return CommonProc.generateResultJsonData(
succeed=False,
message=message
)
def getPredictData(self, sentence):
tagstring = self.tagger.parse(sentence)
tags = tagstring.split('\n')
sentence_tags = []
for index in range(len(tags) - 2):
taginfos = tags[index].split('\t')
sentence_tags.append("{0}".format(taginfos[0]))
x = [[0.0 for i in range(self.sentence_tag_length)] for j in range(self.keyword_length)]
for tag_index in range(len(sentence_tags)):
for keyword_index in range(len(self.keywords)):
if sentence_tags[tag_index] == self.keywords[keyword_index]:
print("{0}: tag index:{1}, keyword index: {2}".format(sentence_tags[tag_index], tag_index, keyword_index))
x[tag_index][keyword_index] = 1.0
break
xs = []
xs.append(x)
return np.array(xs)
def predict(self, sentence):
try:
print("sentence: {0}".format(sentence))
x = self.getPredictData(sentence)
print("predict start")
ys = self.model.predict(x, batch_size=self.batch_size, steps=None)
print("predict result: {0}".format(ys))
return np.argmax(ys[0])
except:
print(traceback.format_exc())
return 1
def getMemorialBuddhaEndpoint(self, endpoint):
return "http://{0}/{1}".format(self.setting.budda_machine_address, endpoint)
Flaskで書くときはthreadedとdebugの指定に気を付ける。有効にするとkerasが謎エラー吐く。
app = Flask(__name__)
api = Api(app)
api.add_resource(EchoResource, '/')
api.add_resource(
MemorialBuddhaAction,
'/api/v1/action',
resource_class_kwargs={'tagger': tagger, 'model': model, "keywords": keywords})
app.run(host='0.0.0.0', port=80, threaded=False)
音声検知
ユーザからの音声を受け付けるアプリを組む。アプリで設定する項目は下記点
- サーバアドレス
- 録音開始ボタン
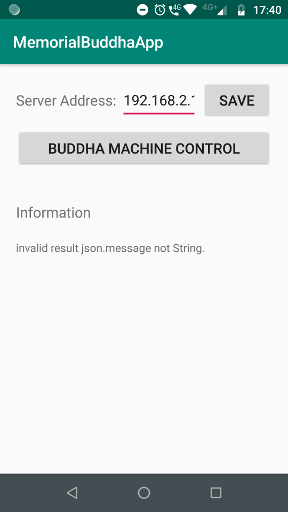
こんな感じ
構成はMVVM
- model
- AppSettings
- BuddhaMachineAction
- view
- MainActivity
- MainFragment
- vm
- MainViewModel
とりあえずキモとなるBuddhaMachineAction
BuddhaMachineAction
package jp.miyatama.memorialbuddhaapp.model
import android.app.Application
import android.content.Context
import android.util.Log
import okhttp3.MediaType.Companion.toMediaTypeOrNull
import okhttp3.OkHttpClient
import okhttp3.Request
import okhttp3.RequestBody
import org.json.JSONObject
import java.lang.Exception
import java.util.concurrent.TimeUnit
class BuddhaMachineAction(val app:Application) {
private val TAG = BuddhaMachineAction::class.java.simpleName
private val SHARED_PREFERENCE_NAME = "settings"
private val SERVER_ADDRESS_KEY = "server_address"
private val SUCCEED_ITEM_NAME = "succeed"
private val MESSAGE_ITEM_NAME = "message"
fun getServerAddress(): String{
val sp = this.app.getSharedPreferences(SHARED_PREFERENCE_NAME, Context.MODE_PRIVATE)
return sp.getString(SERVER_ADDRESS_KEY, "")!!
}
fun doAction(text: String): String{
Log.d(TAG, "doAction: ${text}")
try{
val client = OkHttpClient.Builder()
.connectTimeout(5, TimeUnit.SECONDS)
.writeTimeout(5, TimeUnit.SECONDS)
.readTimeout(5, TimeUnit.SECONDS)
.build()
val address = getServerAddress()
val url = "http://${address}/api/v1/action"
Log.d(TAG, "url: ${url}")
val mediaType = "application/json; charset=utf-8".toMediaTypeOrNull()
val requestBody = RequestBody.create(mediaType, "{ \"text\": \"${text}\"}")
val request = Request.Builder()
.url(url)
.post(requestBody)
.build()
val response = client.newCall(request).execute()
val jsonString = response.body!!.string()
Log.d(TAG , jsonString)
val jsonData = JSONObject(jsonString)
// error check
if (!jsonData.has(SUCCEED_ITEM_NAME)){
return "invalid result json.${SUCCEED_ITEM_NAME} not found."
}
if (!jsonData.has(MESSAGE_ITEM_NAME)){
return "invalid result json.${MESSAGE_ITEM_NAME} not found."
}
if (jsonData.get(SUCCEED_ITEM_NAME) !is Boolean){
return "invalid result json.${SUCCEED_ITEM_NAME} not Boolean."
}
if (jsonData.get(MESSAGE_ITEM_NAME) !is Boolean){
return "invalid result json.${MESSAGE_ITEM_NAME} not String."
}
val succeed = jsonData.getBoolean(SUCCEED_ITEM_NAME)
val message = jsonData.getString(MESSAGE_ITEM_NAME)
// when error
if (!succeed){
return message
}
return "Action Succeed!!"
}catch(e: Exception){
Log.e(TAG , e.toString())
return e.toString()
}
}
}
MainViewModelはこんな感じ
MainViewModel
package jp.miyatama.memorialbuddhaapp.vm
import android.app.Application
import android.content.Intent
import android.os.Bundle
import android.speech.RecognitionListener
import android.speech.RecognizerIntent
import android.speech.SpeechRecognizer
import android.util.Log
import android.view.View
import androidx.lifecycle.AndroidViewModel
import androidx.lifecycle.MutableLiveData
import jp.miyatama.memorialbuddhaapp.model.AppSettings
import jp.miyatama.memorialbuddhaapp.model.BuddhaMachineAction
import kotlinx.coroutines.Dispatchers
import kotlinx.coroutines.GlobalScope
import kotlinx.coroutines.async
import kotlinx.coroutines.launch
import java.util.*
class MainViewModel(val app: Application) : AndroidViewModel(app) {
private val TAG = MainViewModel::class.java.simpleName
val serverAddress = MutableLiveData<String>()
val information = MutableLiveData<String>()
lateinit var appSettings: AppSettings
lateinit var buddhaMachineAction: BuddhaMachineAction
fun init(){
appSettings = AppSettings(app)
buddhaMachineAction =
BuddhaMachineAction(app)
serverAddress.value = appSettings.getServerAddress()
}
fun onClickSaveServerAddress(view: View){
appSettings.setServerAddress(serverAddress.value!!)
}
fun onClickBuddhaControl(veiw: View){
var speechRecognizerIntent = Intent(RecognizerIntent.ACTION_RECOGNIZE_SPEECH)
speechRecognizerIntent.putExtra(RecognizerIntent.EXTRA_LANGUAGE, Locale.getDefault().getLanguage())
speechRecognizerIntent.putExtra(RecognizerIntent.EXTRA_LANGUAGE_MODEL, RecognizerIntent.LANGUAGE_MODEL_FREE_FORM)
speechRecognizerIntent.putExtra(RecognizerIntent.EXTRA_CALLING_PACKAGE, this.app.packageName)
speechRecognizerIntent.putExtra(RecognizerIntent.EXTRA_PREFER_OFFLINE, true)
var speechRecognizer = SpeechRecognizer.createSpeechRecognizer(this.app)
speechRecognizer.setRecognitionListener(object: RecognitionListener{
override fun onReadyForSpeech(p0: Bundle?) {
Log.d(TAG ,"onReadyForSpeech")
}
override fun onRmsChanged(p0: Float) {
Log.d(TAG ,"onRmsChanged")
}
override fun onBufferReceived(p0: ByteArray?) {
Log.d(TAG ,"onBufferReceived")
}
override fun onPartialResults(p0: Bundle?) {
Log.d(TAG ,"onPartialResults")
}
override fun onEvent(p0: Int, p1: Bundle?) {
Log.d(TAG ,"onEvent")
}
override fun onBeginningOfSpeech() {
Log.d(TAG ,"onBeginningOfSpeech")
}
override fun onEndOfSpeech() {
Log.d(TAG ,"onEndOfSpeech")
}
override fun onError(error: Int) {
Log.d(TAG ,"onError")
var message = "speech recognizer unknown error"
when (error) {
SpeechRecognizer.ERROR_AUDIO -> message = "Audio recording error"
SpeechRecognizer.ERROR_CLIENT -> message = "Other client side errors"
SpeechRecognizer.ERROR_INSUFFICIENT_PERMISSIONS -> message = "Insufficient permissions"
SpeechRecognizer.ERROR_NETWORK -> message = "Network related errors"
SpeechRecognizer.ERROR_NETWORK_TIMEOUT -> message = "Network operation timed out"
SpeechRecognizer.ERROR_NO_MATCH -> message = "No recognition result matched"
SpeechRecognizer.ERROR_RECOGNIZER_BUSY -> message = "RecognitionService busy"
SpeechRecognizer.ERROR_SERVER -> message = "Server sends error status"
SpeechRecognizer.ERROR_SPEECH_TIMEOUT -> message = "No speech input"
}
information.value = message
}
override fun onResults(results: Bundle?) {
val result = results!!.getStringArrayList(android.speech.SpeechRecognizer.RESULTS_RECOGNITION)!!
if(result.count() <= 0){
return
}
Log.d(TAG, "detect text: ${result.get(0)}")
GlobalScope.launch(Dispatchers.Main) {
async(Dispatchers.Default) {
buddhaMachineAction.doAction(result.get(0))
}.await().let {
information.value = it
}
}
}
})
speechRecognizer.startListening(speechRecognizerIntent)
}
}
ふりかえり
何回やっても思うが、「電子工作からWebサービスまで」を作成するのは大変。
ざっと上げるだけでも
- 作業時間の確保
- 作業場所の確保
- ネットワーク環境の確保(dns入れる入れないとかssl対応するかどうかとか)
- 部品の買い出しで心が折れる
- Androidの新しい書き方に慣れてない(coroutineっていうかcoroutine)
- ESP32のサンプルが動かない
- etc
ブッダマシーンが2019.12.24に届いてからざっと1カ月ないぐらいなのだが、
体感的には3カ月ぐらいかかった気がする。
月に1回ぐらいAndroidアプリ組むなり電子工作するなりしとかないと、腕は落ちるもんだと思い知らされた。ていうか落ちてた。
進みの早いIT業界。多分今回の経験も、半年後には半分ぐらいしか役に立たなくなってると思う。
フレームワークとか規格とか方針とか、自然現象ではないものは所詮人が作ったもの。
間違ってたり変わったりが当たり前なので、たまに無理して勉強するぐらいがちょうどいいんだと思う。
あんまり関係ないけど、2020年初めての幸運がフエラムネ
フエ星人ゲット!2020年なんかあるぞコレ!#フエ星人 pic.twitter.com/LNFG2WY6FF
— みやた@画策中 (@miyata080825) January 18, 2020