darknet yoloにはv1とv2があり、c言語で書かれている。
tensorflowバージョン
https://github.com/gliese581gg/YOLO_tensorflow
kerasバージョン
https://github.com/sunshineatnoon/Darknet.keras
torchバージョン
https://github.com/tommy-qichang/yolo.torch
chainerバージョン
https://github.com/ashitani/YOLO_chainer
chainerバージョン yolov2 神説明
https://github.com/leetenki/YOLOv2
windowsバージョン
https://github.com/AlexeyAB/yolo-windows
windows版の詳しい使い方
https://github.com/AlexeyAB/darknet#how-to-use
ハマりポイント
内部でjpgで検索してしまってるのでjpgの画像でないと学習できない。
画像はimages、ラベルはlabelsに格納して同階層に配置しないといけない。
画像は大きすぎないようがいい。600*400程が良い。
bbox toolで吐き出した座標は変換をかける必要がある。
大まかにいうとyolo-v1って
ちょっと精度が下がるが早い物体検出アルゴリズム。
固定でグリッドを分けて2個のバウンディングボックスと信頼度で検出。configを変えれば変えれるはず。

初期設定(v1)
git clone https://github.com/pjreddie/darknet.git
cd darknet
# v1まで戻す
git checkout c71bff69eaf1e458850ab78a32db8aa25fee17dc
# gpuを使う場合はMakefileを編集
Makefileのgpuを1へ
make
テスト(v1)
wget http://pjreddie.com/media/files/yolov1.weights
./darknet yolo test cfg/yolo.cfg yolov1.weights data/dog.jpg
predictions.pngが出力されて入ればOK
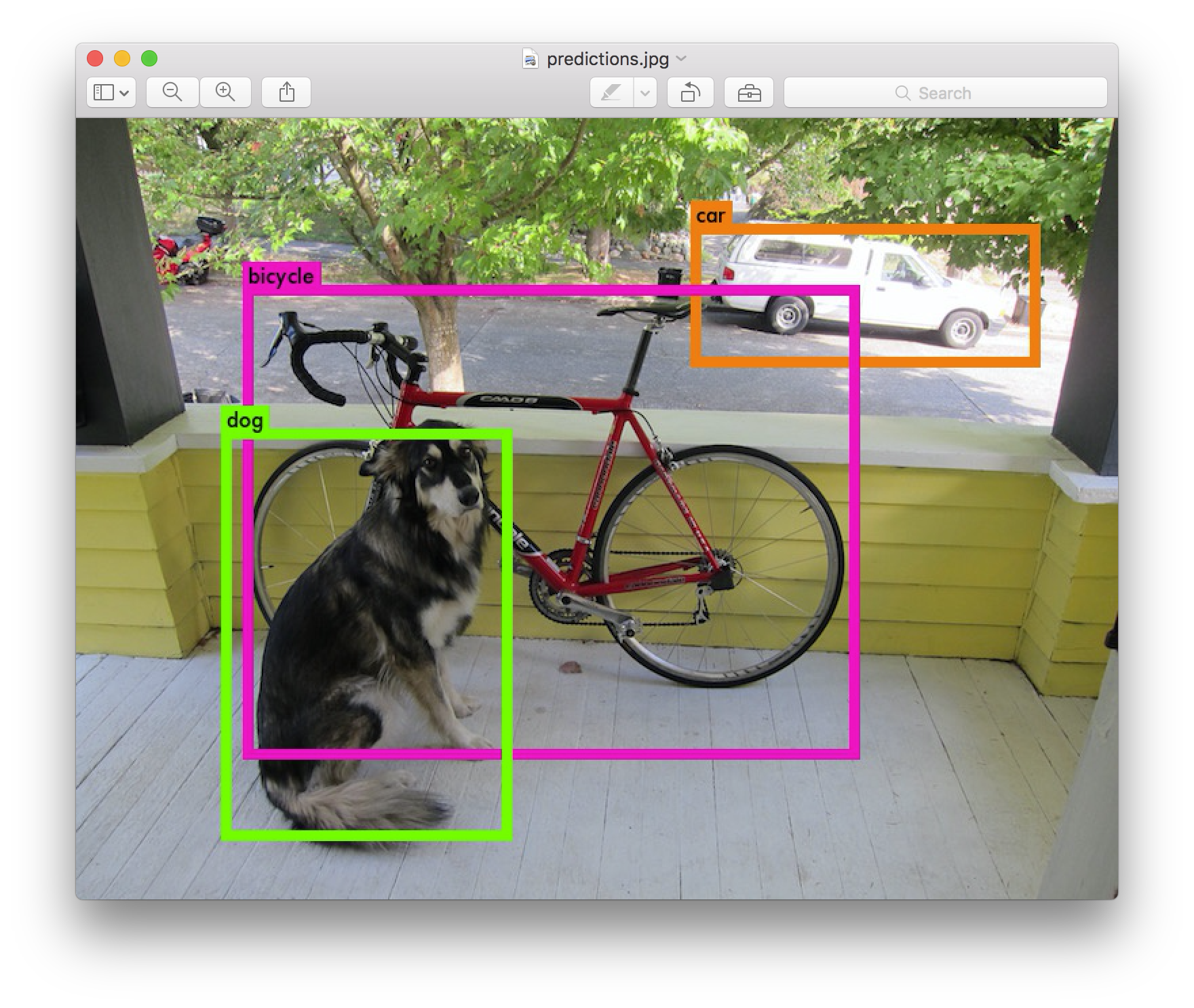
pascal voc形式の画像でファインチューニングをしてみる(v1)
pascal voc形式ファイルを取得
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar
の形式のテキストファイルで、クラスと座標が入っています。
python voc_label.py #script配下にあるのでdata以下にコピーしてくる
cat 2007_* 2012_train.txt > train.txt
images、labelsのフォルダを同じ階層に作成する。
imagesには画像ファイル:画像は.jpgか.JPEGじゃないと拾ってくれない。
labelsにはpascal voc形式のテキストファイル
自分で作成したpascal voc形式データセットで学習
ちょっとツールをいじる必要はあるが、だいたい下記のようなツールで座標ファイルを作れる。
https://github.com/puzzledqs/BBox-Label-Tool
座標に注意!!
voc2007のデータを元に確認すると
<width>353</width><height>500</height><depth>3</depth></size>
<bndbox><xmin>48</xmin><ymin>240</ymin><xmax>195</xmax><ymax>371</ymax></bndbox></object>
下記でコンバートしてる。
size=353,500
box=48,240,195,371
box=xmin,ymin,xmax,ymax
つまり引数のboxは左上の座標と右下の座標。
回帰用にに1〜0の間に数字を圧縮してるような気がする。。
def convert(size, box):
dw = 1./size[0] #1以内で横サイズの比率を出す
dh = 1./size[1] #1以内で縦サイズの比率を出す
x = (box[0] + box[1])/2.0 #左上の座標のxとy座標の加算を2で割る
y = (box[2] + box[3])/2.0 #右下の座標のxとy座標の加算を2で割る
w = box[1] - box[0] #boxの横サイズ
h = box[3] - box[2] #boxの縦サイズ
x = x*dw #x座標に比率をかける
w = w*dw #w座標に比率をかける
y = y*dh #y座標に比率をかける
h = h*dh #h座標に比率をかける
return (x,y,w,h)
全ソース
# -*- coding: utf-8 -*-
import os
import cv2
import glob
import numpy as np
from PIL import Image, ImageTk
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
for name in glob.glob("/home/hogehoge/labels/*.txt"):
for line in open(name, 'r'):
print("label name is " + name)
print("image name is " + name.replace("labels","images").replace(".txt",".jpg"))
img = cv2.imread(name.replace("labels","images").replace(".txt",".jpg"))
h, w = img.shape[:2]
print(line)
l = line.split(" ")
print l[0]
print l[1]
print l[2]
print l[3]
print l[4]
b = (float(l[1]), float(l[3]), float(l[2]), float(l[4]))
bb = convert((w,h), b)
print(str(l[0]) + " " + " ".join([str(a) for a in bb]))
list_write_file = open(name.replace("labels", "labels_new"), 'a')
list_write_file.write(str(l[0]) + " " + " ".join([str(a) for a in bb]) + "\n")
list_write_file.close()
#break
src/yolo.cを編集
18 char *train_images = "/home/pjreddie/data/voc/test/train.txt";
19 char *backup_directory = "/home/pjreddie/backup/";
train.txtのパスを指定。backupフォルダを作成してパスを指定。この中に学習結果の重みが保存される。
make
重みの初期値を取得
wget http://pjreddie.com/media/files/extraction.conv.weights
学習
./darknet yolo train cfg/yolov1/yolo.train.cfg extraction.conv.weights
gpuの1を使用する場合
./darknet yolo train cfg/yolov1/yolo.train.cfg extraction.conv.weights -i 1
出力画像の名前を変える場合
...略
void test_detector(char *datacfg, char *cfgfile, char *weightfile, char *filename, float thresh, float hier_thresh, char *outfile, int\
fullscreen)
{
...略
else{
printf(" %s ", filename);
save_image(im, "predictions");
...略
検出結果座標を出力したい
...略
void draw_detections(image im, int num, float thresh, box *boxes, float **probs, float **masks, char **names, image **alphabet, int cl\
asses)
{
...略
if(left < 0) left = 0;
if(right > im.w-1) right = im.w-1;
if(top < 0) top = 0;
if(bot > im.h-1) bot = im.h-1;
#追加
printf("%d, %d, %d, %d \n", left, right, top, bot);
draw_box_width(im, left, top, right, bot, width, red, green, blue);
if (alphabet) {
...略
}
...略
ラベル数を変更した場合の計算(v1)
v2では計算方法とか設定ファイルが変わってしまってる。
ただyolo2ではカテゴリもすごい増えててすごい。
v1ではyolo.train.cfgの[detection]のclassesと[connected]のoutputを変更する必要がある。
論文より
>これらのスコアは、ボックスに表示されるそのクラスの確率と予測されたボックスがオブジェクトにどのくらいフィットするかの両方を符号化します。
PASCAL VOCのYOLOを評価するには、S = 7、B = 2を使用します。PASCAL VOCには20のラベルクラスがあり、C = 20です。最終的な予測は7×7×30テンソルです。
画像をS×Sグリッドに分割し、グリッドセルごとに、Bバウンディングボックス、それらのボックスの信頼性、およびCクラス確率を予測する。 これらの予測は、S×S×(B×5 + C)のテンソルとして符号化される。
論文ではB=2を使用しているが、v1の最後の方ではB(num)=3を使用している。
s=グリッド
c=クラス数
b=3
1クラスの場合
784
2クラスの場合
ss(b5+c)
77*(35+2)
4917=833
6クラスの場合
ss(b5+c)
77*(35+6)
4921=1029
20クラスの場合
ss(b5+c)
77*(35+20)
4935=1715
train.txtを作るコードの例
import os, csv, time
import glob
listFile = 'train.txt'
f = open(listFile, 'w')
for filename in glob.glob("/hogehoge/*.jpg"):
print(filename)
f.write(filename+"\n")
f.close()
cfgファイル
yolo.train.cfg:学習用
[net]
batch=64
subdivisions=4
yolo.cfg:テスト用
[net]
batch=1
subdivisions=1
opencvを使う場合
2018/10/31
3.4.0をいれて
https://github.com/opencv/opencv/releases/tag/3.4.0
git clone https://github.com/Itseez/opencv.git
cd opencv
checkout -b 3.4.0
sudo apt-get install build-essential
sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
sudo apt-get install python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev
mkdir build
cd build
cmake -D ENABLE_CXX11=1 ..
make -j4 or make -j8
sudo make install
この後にdarknetをビルド。
この情報はもう古そう。
opencv 2.4をインストールすること
※注意!!
そもそもopencv2系でしかC言語がサポートされてない!!
gitのreleaseタブから2系をダウンロードするとsampleの中にC言語のフォルダがあるとOK!!
そもそもC言語でopencvで動くか確認してからdarknetのビルドをすると困らない。
while loading shared libraries: libopencv_highgui.so
yolo v2
基本的な操作は公式ページ通りに。
コード的にはyolo.cがなくなってるので、パスをコードからいじる必要がなくなってる。
パスは設定ファイルにまとまってる。
クラス分類数を変える場合の計算
cfgファイルのFiltersを変える。
(#classes + #coords(4) + 1)*(NUM)
6クラスの場合
(6+4+1)*5=55
2クラスの場合
(2+4+1)*5=35
参考
https://groups.google.com/forum/#!topic/darknet/B4rSpOo84yg
学習時はbatch sizeに注意。
QA
1つのラベルでも学習できますか?
はい
参考
https://groups.google.com/forum/#!topic/darknet/yGTOphxqWEs
yolo v2の学習について
参考
https://groups.google.com/forum/#!msg/darknet/B4rSpOo84yg/XxHVgR51CQAJ
1クラスで学習した場合のエラー
うまくいかない事例が報告されてる
https://groups.google.com/forum/#!topic/darknet/PSfpLeP9dTI
Segmentation fault
※注意※学習データとラベルデータのフォルダは同階層にimagesとlabelsで統一すること。
→内部でハードコーディングしちゃってるので、そのフォルダしか拾えない。
メモリのエラー
使いすぎか他が使ってる。
バッチサイズを下げるか、画像サイズを下げる。あるいは他のプログラムが使ってないか調べる。nvidea-smiコマンド。
forced: Using default '0'
$ ./darknet yolo train cfg/yolo.cfg extraction.conv.weights
yolo
0: Crop Layer: 448 x 448 -> 448 x 448 x 3 image
shift: Using default '0.000000'
1: Convolutional Layer: 448 x 448 x 3 image, 64 filters -> 224 x 224 x 64 image
2: Maxpool Layer: 224 x 224 x 64 image, 2 size, 2 stride
3: Convolutional Layer: 112 x 112 x 64 image, 192 filters -> 112 x 112 x 192 image
4: Maxpool Layer: 112 x 112 x 192 image, 2 size, 2 stride
5: Convolutional Layer: 56 x 56 x 192 image, 128 filters -> 56 x 56 x 128 image
6: Convolutional Layer: 56 x 56 x 128 image, 256 filters -> 56 x 56 x 256 image
7: Convolutional Layer: 56 x 56 x 256 image, 256 filters -> 56 x 56 x 256 image
8: Convolutional Layer: 56 x 56 x 256 image, 512 filters -> 56 x 56 x 512 image
9: Maxpool Layer: 56 x 56 x 512 image, 2 size, 2 stride
10: Convolutional Layer: 28 x 28 x 512 image, 256 filters -> 28 x 28 x 256 image
11: Convolutional Layer: 28 x 28 x 256 image, 512 filters -> 28 x 28 x 512 image
12: Convolutional Layer: 28 x 28 x 512 image, 256 filters -> 28 x 28 x 256 image
13: Convolutional Layer: 28 x 28 x 256 image, 512 filters -> 28 x 28 x 512 image
14: Convolutional Layer: 28 x 28 x 512 image, 256 filters -> 28 x 28 x 256 image
15: Convolutional Layer: 28 x 28 x 256 image, 512 filters -> 28 x 28 x 512 image
16: Convolutional Layer: 28 x 28 x 512 image, 256 filters -> 28 x 28 x 256 image
17: Convolutional Layer: 28 x 28 x 256 image, 512 filters -> 28 x 28 x 512 image
18: Convolutional Layer: 28 x 28 x 512 image, 512 filters -> 28 x 28 x 512 image
19: Convolutional Layer: 28 x 28 x 512 image, 1024 filters -> 28 x 28 x 1024 image
20: Maxpool Layer: 28 x 28 x 1024 image, 2 size, 2 stride
21: Convolutional Layer: 14 x 14 x 1024 image, 512 filters -> 14 x 14 x 512 image
22: Convolutional Layer: 14 x 14 x 512 image, 1024 filters -> 14 x 14 x 1024 image
23: Convolutional Layer: 14 x 14 x 1024 image, 512 filters -> 14 x 14 x 512 image
24: Convolutional Layer: 14 x 14 x 512 image, 1024 filters -> 14 x 14 x 1024 image
25: Convolutional Layer: 14 x 14 x 1024 image, 1024 filters -> 14 x 14 x 1024 image
26: Convolutional Layer: 14 x 14 x 1024 image, 1024 filters -> 7 x 7 x 1024 image
27: Convolutional Layer: 7 x 7 x 1024 image, 1024 filters -> 7 x 7 x 1024 image
28: Convolutional Layer: 7 x 7 x 1024 image, 1024 filters -> 7 x 7 x 1024 image
29: Connected Layer: 50176 inputs, 4096 outputs
30: Dropout Layer: 4096 inputs, 0.500000 probability
31: Connected Layer: 4096 inputs, 1470 outputs
32: Detection Layer
forced: Using default '0'
Loading weights from extraction.conv.weights...Done!
Learning Rate: 0.001, Momentum: 0.9, Decay: 0.0005
/Users/stiaje/Projects/darknet/voc/VOCdevkit/VOC2007/JPEGImages/003434.jpg
[1] 43754 abort ./darknet yolo train cfg/yolo.cfg extraction.conv.weights
参考
https://groups.google.com/forum/#!topic/darknet/WjBFAus83ww
Couldn't open file:
yolo.cで指定しているパスがない。
train_imagesなど指定してるパスがない可能性がある。
変更して再度makeして実行。
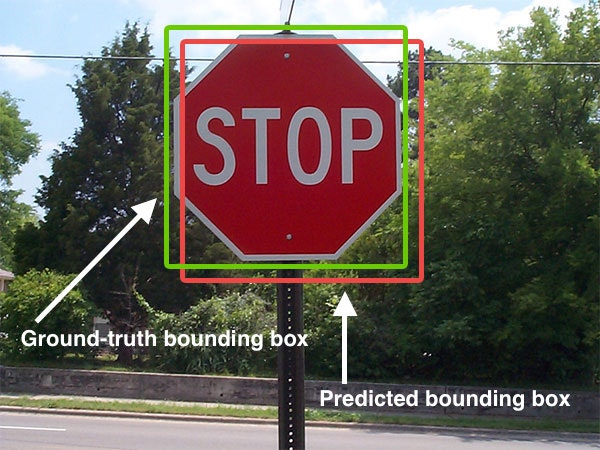
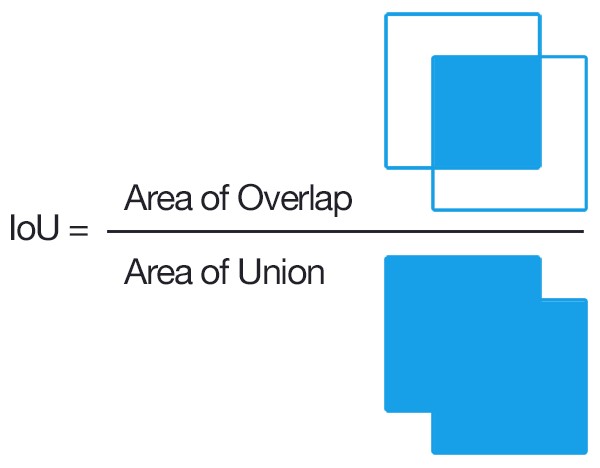
評価関数のIOUって何ですか
全体分の重なってる部分です。
# import the necessary packages
from collections import namedtuple
import numpy as np
import cv2
# define the `Detection` object
Detection = namedtuple("Detection", ["image_path", "gt", "pred"])
def bb_intersection_over_union(boxA, boxB):
# determine the (x, y)-coordinates of the intersection rectangle
xA = max(boxA[0], boxB[0])
yA = max(boxA[1], boxB[1])
xB = min(boxA[2], boxB[2])
yB = min(boxA[3], boxB[3])
# compute the area of intersection rectangle
interArea = (xB - xA + 1) * (yB - yA + 1)
# compute the area of both the prediction and ground-truth
# rectangles
boxAArea = (boxA[2] - boxA[0] + 1) * (boxA[3] - boxA[1] + 1)
boxBArea = (boxB[2] - boxB[0] + 1) * (boxB[3] - boxB[1] + 1)
# compute the intersection over union by taking the intersection
# area and dividing it by the sum of prediction + ground-truth
# areas - the interesection area
iou = interArea / float(boxAArea + boxBArea - interArea)
# return the intersection over union value
return iou
http://stackoverflow.com/questions/28723670/intersection-over-union-between-two-detections
http://www.pyimagesearch.com/2016/11/07/intersection-over-union-iou-for-object-detection/
文字コードが合ってない あるいは フォーマットがあってない
train.txtやtest.txtなど学習する画像一覧の書かれたファイルをutf-8に変換
変えるコードの場所はこの辺。
https://github.com/pjreddie/darknet/blob/master/src/yolo.c#L123
STB Reason: can't fopen
nkf -w train.txt > train.txt
あるいは
voc_label.py
を改造してテキストファイルを出力するとうまくいく。
参考
https://groups.google.com/forum/#!topic/darknet/NI9ITPlXZ_4
学習がうまくいってない例
画像と同じ名前のラベルが同階層にない。あるいは画像が大きすぎる可能性もある。
488.488で学習してるので大きい画像には向かない。
Learning Rate: 0.0005, Momentum: 0.9, Decay: 0.0005
Loaded: 3.574655 seconds
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: 0.001198, count: 0
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: 0.001633, count: 0
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: 0.001763, count: 0
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: 0.000777, count: 0
1: 0.053943, 0.053943 avg, 0.000500 rate, 10.892705 seconds, 64 images
Loaded: 0.000015 seconds
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: 0.001044, count: 0
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: 0.001514, count: 0
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: 0.001512, count: 0
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: 0.000377, count: 0
2: 0.054860, 0.054035 avg, 0.000500 rate, 10.890522 seconds, 128 images
Loaded: 0.000017 seconds
2821: 0.000026, 0.000030 avg, 0.005000 rate, 11.260962 seconds, 180544 images
Loaded: 0.000020 seconds
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: 0.000005, count: 0
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: -0.000022, count: 0
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: -0.000015, count: 0
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: 0.000015, count: 0
2822: 0.000033, 0.000030 avg, 0.005000 rate, 11.377686 seconds, 180608 images
Loaded: 0.000017 seconds
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: 0.000006, count: 0
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: 0.000013, count: 0
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: 0.000013, count: 0
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: 0.000011, count: 0
2823: 0.000025, 0.000030 avg, 0.005000 rate, 11.340076 seconds, 180672 images
Loaded: 0.000020 seconds
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: -0.000004, count: 0
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: -0.000035, count: 0
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: 0.000010, count: 0
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: 0.000029, count: 0
2824: 0.000033, 0.000030 avg, 0.005000 rate, 11.433349 seconds, 180736 images
Loaded: 0.000017 seconds
Detection Avg IOU: -nan, Pos Cat: -nan, All Cat: -nan, Pos Obj: -nan, Any Obj: 0.000010, count: 0
出力された座標をプロットする
出てきたxとyは画像の真ん中なのでx-w/2-1が必要。yも同様。
x = int(x - w/2 - 1)
y = int(y - h/2 - 1)
# coding: utf-8
import cv2
from matplotlib import pyplot as plt
# 画像の読み込み
img = cv2.imread("data/dog.jpg", 1)
# 画像の高さ、幅を取得
height = img.shape[0]
width = img.shape[1]
# dog/ height, width 576 , 768
print("height, width ", height, ", ", width)
# いぬ
# 216.75436401367188, 393.0237121582031, 256.93603515625, 325.7979431152344
# x = int(216)
# y = int(393)
# w = int(256)
# h = int(325)
# 502.99591064453125, 114.5804214477539, 115.98054504394531, 95.33753967285156
x = int(502)
y = int(114)
w = int(115)
h = int(95)
x = int(x - w/2 - 1)
y = int(y - h/2 - 1)
w = w
h = h
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 0, 255), 2)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)
plt.show()
ログをプロット
準備としてtmuxを記録する。
https://qiita.com/docokano/items/8418cc1b2561df03e8d9
tmuxのログを残したらファイルを一旦移動してる。
cp ~/.tmux/log/20190128-220050-0-1.0.log test4.log
いらない箇所を削除してる。
tmuxのゴミを消すスクリプト。
# coding:utf-8
import re
"""
s1 = "[2018_1119_112932_516922122] Loaded: 0.000041 seconds"
result = re.sub(r'\[[0-9_]+\]', "", s1)
print(result)
s2 = "[2018_1119_135405_194632645] Region Avg IOU: 0.426638, Class: 0.945059, Obj: 0.354702, No Obj: 0.006519, Avg Recall: 0.392157, count: 102"
result = re.sub(r'\[[0-9_]+\]', "", s2)
"""
# print(result)
f = open('test3.log','r')
for row in f:
result = re.sub(r'\[[0-9_]+\] ', "", row.strip())
#print(result)
#print(row.strip())
with open("test3_a.log", mode='a') as f2:
f2.write(result+"\n")
f.close()
python plot_log.py --log-file test4_a.log
import argparse
import logging
import os
import platform
import re
import sys
# set non-interactive backend default when os is not windows
if sys.platform != 'win32':
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
from matplotlib.ticker import MultipleLocator, FormatStrFormatter
def get_file_name_and_ext(filename):
(file_path, temp_filename) = os.path.split(filename)
(file_name, file_ext) = os.path.splitext(temp_filename)
return file_name, file_ext
def show_message(message, stop=False):
print(message)
if stop:
sys.exit(0)
def parse_args():
parser = argparse.ArgumentParser(description="training log parser by DeepKeeper ")
parser.add_argument('--source-dir', dest='source_dir', type=str, default='./',
help='the log source directory')
parser.add_argument('--save-dir', dest='save_dir', type=str, default='./',
help='the directory to be saved')
parser.add_argument('--csv-file', dest='csv_file', type=str, default="",
help='training log file')
parser.add_argument('--log-file', dest='log_file', type=str, default="",
help='training log file')
parser.add_argument('--show', dest='show_plot', type=bool, default=False,
help='whether to show')
return parser.parse_args()
def log_parser(args):
if not args.log_file:
show_message('log file must be specified.', True)
log_path = os.path.join(args.source_dir, args.log_file)
if not os.path.exists(log_path):
show_message('log file does not exist.', True)
file_name, _ = get_file_name_and_ext(log_path)
log_content = open(log_path).read()
iterations = []
losses = []
fig, ax = plt.subplots()
# set area we focus on
ax.set_ylim(0, 8)
major_locator = MultipleLocator()
minor_locator = MultipleLocator(0.5)
ax.yaxis.set_major_locator(major_locator)
ax.yaxis.set_minor_locator(minor_locator)
ax.yaxis.grid(True, which='minor')
pattern = re.compile(r"([\d].*): .*?, (.*?) avg")
# print(pattern.findall(log_content))
matches = pattern.findall(log_content)
# print(type(matches[0]))
counter = 0
log_count = len(matches)
if args.csv_file != '':
csv_path = os.path.join(args.save_dir, args.csv_file)
out_file = open(csv_path, 'w')
else:
csv_path = os.path.join(args.save_dir, file_name + '.csv')
out_file = open(csv_path, 'w')
for match in matches:
counter += 1
if log_count > 200:
if counter % 200 == 0:
print('parsing {}/{}'.format(counter, log_count))
else:
print('parsing {}/{}'.format(counter, log_count))
iteration, loss = match
iterations.append(int(iteration))
losses.append(float(loss))
out_file.write(iteration + ',' + loss + '\n')
ax.plot(iterations, losses)
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.tight_layout()
# saved as svg
save_path = os.path.join(args.save_dir, file_name + '.svg')
plt.savefig(save_path, dpi=300, format="svg")
if args.show_plot:
plt.show()
if __name__ == "__main__":
args = parse_args()
log_parser(args)
学習前チェック
- yolo.cのパスがあってること
- 学習logのcountが0以外になっていること
- cfgの設定があっていること
- 数時間回してからtestを走らせてみること
→最後まで回してうまくいってないことがある。
ブラウザから動かしたい場合
動いた。アップロードしたら結果が返って来る。
https://github.com/zhreshold/yolo-demo-server
自分の環境ではエラーで動いてない。
https://gitlab.lif.univ-mrs.fr/benoit.favre/darknet-rest-server
スライディングウィンドウ、DPM、R-CNNすべての学習領域ベースの分類器で検出を実行

YOLOでは、画像を一度見るだけで検出を実行します

画像をグリッドに分割


各セルはボックスと信頼を予測します:P(オブジェクト)






各セルはまた、クラス確率を予測する。


条件付きオブジェクト:P(Car | Object)

次に、ボックスとクラスの予測を結合します。

最後に、NMSとしきい値検出を行います

Non-Maximum suppression(局所的に最大値以外を0に抑える)
if bbox_iou(boxes[index_i], boxes[index_j]) >= nms_threshold:
boxes[index_j].classes[c] = 0
このパラメータ化は、出力サイズ
各セルは次のように予測します。
各バウンディングボックスについて:
- 4 coordinates (x, y, w, h)
- 1 confidence value
いくつかのクラス - 確率
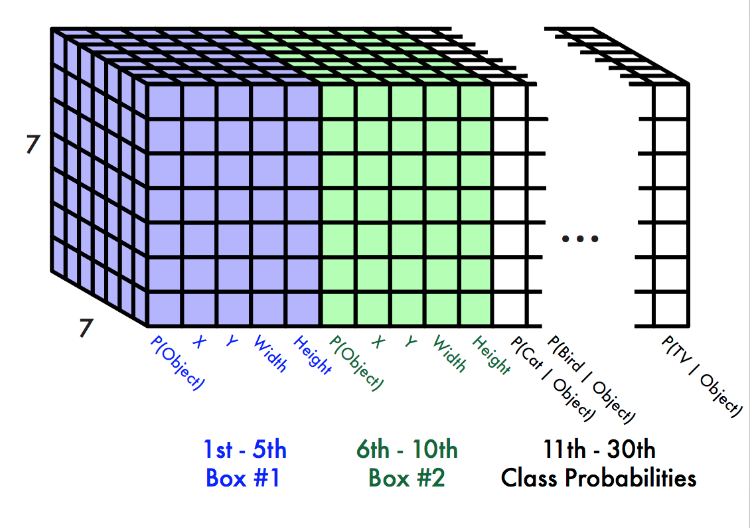
パスカルVOCの場合:
- 7x7 grid
- 2 bounding boxes / cell
- 20 classes
7 x 7 x (2 x 5 + 20) = 7 x 7 x 30 tensor = 1470 outputs
したがって、1つのニューラルネットワークを全体の検出パイプラインとして訓練することができます

トレーニング中に、右のセルに一致する例


そのセルのクラス予測を調整する

そのセルの予想されるボックスを見てください

最高のものを見つけてそれを調整し、信頼を高める


他のボックスの信頼度を下げる


一部のセルには真実の検出がありません!


これらのボックスの信頼性を下げる


クラスの確率や座標を調整しないでください

一般的な方法を使用
学習済みImagenet
学習率の低下するSGD
データ水増し
アートワークの人物検出に一般化するとき、YOLOはDPMやR-CNNなどのメソッドより優れています

# You Only Look Once:Unified, 統合されたリアルタイムオブジェクトの検出
抜粋
オブジェクト検出の新しいアプローチであるYOLOを紹介。
オブジェクト検出を回帰問題として、空間的に分離されたバウンディングボックスと関連するクラス確率を学習する。
単一のニューラルネットワークは、1つの評価で完全な画像から直接境界ボックスおよびクラス確率を予測する。検出パイプライン全体は単一のネットワークであるため、検出性能に直接エンドツーエンドで最適化することができます。私たちの統一されたアーキテクチャは非常に高速です。当社のベースYOLOモデルは、毎秒45フレームでリアルタイムで画像を処理します。より小さなバージョンのネットワークであるFast YOLOは、他のリアルタイム検出器のmAPを2倍にしながら、1秒間に驚異的な155フレームを処理します。最先端の検出システムと比較して、YOLOはより多くのローカライズエラーを生成しますが、バックグラウンドでの誤検出を予測する可能性は低いです。最後に、YOLOはオブジェクトの非常に一般的な表現を学びます。自然画像からアートワークのような他のドメインに一般化するとき、DPMやR-CNNなどの他の検出方法より優れています。
1.はじめに
人間はイメージを一瞥して、イメージ内のどのオブジェクトがどこにあるのか、どのオブジェクトがどのように相互作用しているのかをすぐに知ることができます。人間の視覚システムは、迅速かつ正確であり、私たちはほとんど意識的な思考で運転するような複雑な作業を行うことができます。オブジェクト検出のための高速で正確なアルゴリズムは、コンピュータが特別なセンサなしで車を運転し、支援装置がリアルタイムのシーン情報を人間のユーザに伝えることを可能にし、汎用の応答性の高いロボットシステムの可能性を解き放つ。現在の検出システムは、分類器を使用して検出を行う。オブジェクトを検出するために、これらのシステムは、そのオブジェクトのための分類器を取り、それをテスト画像の様々な位置およびスケールで評価する。変形可能パーツモデル(DPM)のようなシステムでは、画像全体にわたって均等に配置された場所で分類器が実行されるスライディングウインドウアプローチが用いられている[10]。 R-CNNのような最近のアプローチは、画像内に潜在的なバウンディングボックスを生成し、次にこれらの提案されたボックス上でクラシファイアを実行するために、領域提案方法を使用する。分類後、後処理を使用してバウンディングボックスを改良し、重複した検出を排除し、シーン内の他のオブジェクトに基づいてボックスを再センシングする[13]。これらの複雑なパイプラインは、個々のコンポーネントを個別に訓練する必要があるため、最適化が遅く、困難です。オブジェクトの検出は、画像ピクセルからバウンディングボックスの座標とクラス確率に直接回帰する単一の回帰問題として再構成されます。私たちのシステムを使用すると、イメージで一度だけ(YOLO)を見て、どのオブジェクトが存在し、どこにあるかを予測します。 YOLOは爽快でシンプルです。図1を参照してください。単一の畳み込みネットワークは、複数の境界ボックスとそれらのボックスのクラス確率を同時に予測します。 YOLOは完全な画像を取得し、検出性能を直接最適化します。この統一モデルは、従来の物体検出方法に比べていくつかの利点を有する。
 図1:YOLO検出システム。 YOLOで画像を処理するのは簡単で簡単です。 我々のシステム(1)は、入力画像を448×448にサイズ変更し、(2)画像上に単一の畳み込みネットワークを実行し、(3)モデルの信頼度によって検出結果を閾値処理する。
図1:YOLO検出システム。 YOLOで画像を処理するのは簡単で簡単です。 我々のシステム(1)は、入力画像を448×448にサイズ変更し、(2)画像上に単一の畳み込みネットワークを実行し、(3)モデルの信頼度によって検出結果を閾値処理する。
まず、YOLOは非常に高速です。回帰問題としてフレーム検出を行うので、複雑なパイプラインは必要ありません。ニューラルネットワークをテスト時に新しい画像で実行して検出を予測するだけです。当社のベースネットワークは、毎秒45フレームで動作し、Titan X GPUではバッチ処理を行わず、高速版は150fps以上で動作します。これは、25ミリ秒未満のレイテンシでストリーミングビデオをリアルタイムで処理できることを意味します。さらに、YOLOは他のリアルタイムシステムの平均精度の2倍以上を達成しています。ウェブカメラ上でリアルタイムに実行されるシステムのデモについては、プロジェクトウェブページ
http://pjreddie.com/yolo/をご覧ください。
第二に、YOLOは、予測を行うときにイメージに関する世界的な理由がある。スライディングウインドウやリージョンプロポーザルベースのテクニックとは異なり、YOLOはトレーニングやテストの時間中に画像全体を見るので、クラスとその外観に関するコンテキスト情報を暗黙的にエンコードします。トップ検出法であるFast R-CNN [14]は、より大きな文脈を見ることができないため、物体の画像内の背景パッチを間違える。 YOLOは、Fast R-CNNと比較して、バックグラウンドエラーの数の半分以下になります。第3に、YOLOはオブジェクトの一般化可能表現を学習する。自然画像で訓練を受け、アートワークでテストされたとき、YOLOはDPMやR-CNNなどの優れた検出手法よりも優れています。 YOLOは非常に一般化可能であるため、新しいドメインや予期しない入力に適用すると分解される可能性は低くなります。 YOLOは、最先端の検出システムよりも精度がまだ劣っています。画像内のオブジェクトをすばやく識別できますが、一部のオブジェクト、特に小さなオブジェクトを正確にローカライズするのに苦労します。我々は、これらのトレードオフを我々の実験においてさらに検討する。トレーニングとテストのコードはすべてオープンソースです。様々な事前トレーニングされたモデルもダウンロード可能です。
2.統合検出
オブジェクト検出の別々のコンポーネントを単一のニューラルネットワークに統合します。私たちのネットワークは、イメージ全体からのフィーチャを使用して各境界ボックスを予測します。また、画像のすべてのクラスにまたがるすべての境界ボックスを同時に予測します。これは、私たちのネットワークが、イメージ全体のイメージとイメージのすべてのオブジェクトについてグローバルに理由があることを意味します。 YOLOデザインは、高い平均精度を維持しながらエンドツーエンドのトレーニングとリアルタイムのスピードを可能にします。
我々のシステムは、入力画像をS×Sグリッドに分割する。
オブジェクトの中心がグリッドセルに入ると、そのグリッドセルがそのオブジェクトを検出します。各グリッドセルは、これらのボックスのB境界ボックスと信頼スコアを予測します。これらの信頼スコアは、モデルがボックスにオブジェクトを含むことのモデルがどれほど自信を持っているか、そしてボックスが予測しているとどのくらい正確かを反映しています。
正式には、信頼度をPr(Object)* IOUtruth predと定義する。そのセルにオブジェクトが存在しない場合、信頼スコアはゼロになるはずです。さもなければ、信頼スコアが予測されたボックスと地面の真理との間の和集合(IOU)上の交点に等しくなるようにします。
それぞれの境界ボックスは、x、y、w、h、および信頼度の5つの予測から構成されます。 (x、y)座標は、グリッドセルの境界を基準にしたボックスの中心を表します。幅と高さは画像全体に対して予測されます。最後に、信頼予測は、予測されたボックスと任意のグランドトゥルースボックスとの間のIOUを表す。各格子セルは、C条件付きクラス確率Pr(Classi | Object)も予測する。これらの確率は、オブジェクトを含むグリッドセルで調整されます。
テスト時に、条件付きクラス確率と個々のボックス確信度予測、すなわち各ボックスのクラス固有の信頼スコアを与える
 pred=断定
truth=真実
pred=断定
truth=真実
を掛けます。
これらのスコアは、ボックスに表示されるそのクラスの確率と予測されたボックスがオブジェクトにどのくらいフィットするかの両方を符号化します。
PASCAL VOCのYOLOを評価するには、S = 7、B = 2を使用します。PASCAL VOCには20のラベルクラスがあり、C = 20です。最終的な予測は7×7×30テンソルです。
 図2:モデル。 我々のシステムは、回帰問題として検出をモデル化する。 画像をS×Sグリッドに分割し、グリッドセルごとに、Bバウンディングボックス、それらのボックスの信頼性、およびCクラス確率を予測する。 これらの予測は、S×S×(B×5 + C)のテンソルとして符号化される。
図2:モデル。 我々のシステムは、回帰問題として検出をモデル化する。 画像をS×Sグリッドに分割し、グリッドセルごとに、Bバウンディングボックス、それらのボックスの信頼性、およびCクラス確率を予測する。 これらの予測は、S×S×(B×5 + C)のテンソルとして符号化される。
2.1 ネットワーク設計
このモデルを畳み込みニューラルネットワークとして実装し、PASCAL VOC検出データセット[9]で評価する。ネットワークの最初の畳み込み層は画像から特徴を抽出し、完全に連結された層は出力確率および座標を予測する。私たちのネットワークアーキテクチャは、画像分類のためのGoogLeNetモデル[34]に触発されています。私たちのネットワークは24の畳み込みレイヤーとそれに続く完全に接続された2つのレイヤーを持っています。 GoogLeNetで使用される開始モジュールの代わりに、Linら[22]と同様に、1×1の縮小レイヤーとそれに続く3×3の畳み込みレイヤーを使用します。完全なネットワークは図3に示されています。高速オブジェクト検出の境界を押し広げるために設計されたYOLOの高速バージョンも訓練します。高速YOLOは、より少ない畳み込みレイヤー(24ではなく9)とそれらのレイヤー内のフィルターの数が少ないニューラルネットワークを使用します。ネットワークのサイズ以外は、YOLOとFast YOLOの間で、すべてのトレーニングとテストのパラメータが同じです。我々のネットワークの最終的な出力は、7×7×30テンソルの予測である。

図3:アーキテクチャ。 我々の検出ネットワークは、24個の畳み込み層とそれに続く2つの完全に接続された層を有する。 交互に1×1の畳み込み層は、先行する層から特徴空間を縮小する。 我々はImageNet分類タスクの畳み込みレイヤーを分解能の半分(224×224入力画像)でプリトレインし、検出分解能を倍にします。
2.2 トレーニング
我々は、ImageNet 1000クラスの競合データセット[30]に畳み込みレイヤをプリトレインしています。事前トレーニングのために、図3の最初の20個の畳み込みレイヤーと、それに続く平均プールレイヤーと完全に接続されたレイヤーを使用します。このネットワークを約1週間トレーニングし、CaffeのModel Zoo [24]のGoogLeNetモデルに匹敵する、ImageNet 2012検証セットで88%の最高精度を達成しました。すべてのトレーニングと推論にDarknetフレームワークを使用します[26]。
その後、モデルを変換して検出を実行します。 Ren et al。 事前訓練されたネットワークに畳み込みレイヤと接続レイヤの両方を追加することでパフォーマンスが向上することを示しています[29]。 これらの例に従って、4つの畳み込みレイヤーと2つの完全に接続されたレイヤーをランダムに初期化されたウェイトで追加します。 検出はしばしば細かいビジュアル情報を必要とするので、ネットワークの入力解像度を224×224から448×448に増加させる。我々の最終層は、クラス確率とバウンディングボックス座標の両方を予測する。 境界ボックスの幅と高さを画像の幅と高さで正規化して、それらが0と1の間になるようにします。境界ボックスのxとy座標を特定のグリッドセル位置のオフセットにパラメータ化し、0と1 我々は最終層に線形活性化関数を使用し、他のすべての層は次の漏れ整流線形活性化を使用する。
2017年3月時点ではyolo9000が出ており、9000カテゴリを学習させる方法が書かれてある。