概要
scikit-learn の 分類用の決定木 DecisionTreeClassifier の各リーフノードでは、クラス確率が一番高いクラスに分類されます。
ではクラス確率が一番高いクラスが複数ある(同率首位)リーフノードではどのクラスに分類されるのか? を確認しました。
(そもそもこのようなリーフノードは良くありませんが)
確認結果
クラス確率が一番高いクラスが複数あるリーフノードでは、
クラス確率が一番高いクラスのうち、クラスインデックスが一番小さいクラスに分類されます。
確認過程
実行環境
- OS: Windows 10
- Python 3.9.5
- sklearn 0.24.2
- matplotlib 3.4.2
公式ページの説明
sklearn.tree.DecisionTreeClassifier
The predict method operates using the numpy.argmax function on the outputs of predict_proba. This means that in case the highest predicted probabilities are tied, the classifier will predict the tied class with the lowest index in classes_.
引用文の predict_proba は、各クラス確率を出力するメソッドです。(クラスAとクラスBの2値分類の問題の場合、[クラスAである確率, クラスBである確率]を出力)
※ predict_proba() メモ(DecisionTreeClassifier, RandomForestClassifier 対象)
確率値MAXのクラスが複数ある場合、各クラスに割り当てられたインデックスが一番小さいクラスに分類される、ということですね。
サンプルデータで確認
公式ページの説明で分かったつもりではありますが、念のためデータを見ながら確認しておきます。
お馴染みのirisデータセットを使います。
1. 決定木1: 生成とプロット
まず学習まで。
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
iris = load_iris()
# データ確認
print(iris.data[:5]) # 各説明変数の値(先頭5件)
# -> [[5.1 3.5 1.4 0.2]
# -> [4.9 3. 1.4 0.2]
# -> [4.7 3.2 1.3 0.2]
# -> [4.6 3.1 1.5 0.2]
# -> [5. 3.6 1.4 0.2]]
print(iris.feature_names) # 各説明変数名
# -> ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
print(iris.target[:5]) # 正解ラベルの値(先頭5件)
# -> [0 0 0 0 0]
print(set(iris.target)) # 正解ラベルのユニーク値
# -> {0, 1, 2}
print(iris.target_names)
# -> ['setosa' 'versicolor' 'virginica'] ★ 0=setosa, 1=versicolor, 2=virginica
# 学習
X, y = iris.data, iris.target
tree_clf = DecisionTreeClassifier(max_depth=1, random_state=42) # 確認目的の都合で最大深度1
tree_clf.fit(X, y)
次に、クラスインデックス、クラス値の対応 を見ておきます。
for idx, class_val in enumerate(tree_clf.classes_):
print(f"クラスインデックス: {idx} クラス値: {class_val}")
# -> クラスインデックス: 0 クラス値: 0
# -> クラスインデックス: 1 クラス値: 1
# -> クラスインデックス: 2 クラス値: 2
生成された決定木をプロットします。
※ plot_tree()はsklearn Vr.0.21 で追加された機能です。
plot_tree(
tree_clf,
feature_names=iris.feature_names,
class_names=iris.target_names,
impurity=False, # 不純度は今回の話には不要なので表示しない
node_ids=True # 各ノードのIDを表示
)
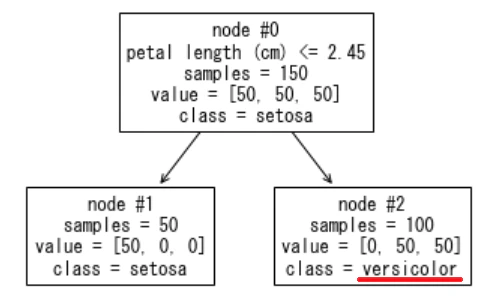
node #2 を見るとクラス1(versicolor), 2(virginica)のサンプル数は同じ(-> ノード内クラス確率が同じ)ですが、クラス1(versicolor)に分類するようです。
(クラスインデックスが小さい方 = クラス1 なので、ドキュメントの記載通り)
2. 決定木1: テストデータの各クラス確率と分類結果
node #2 にやってくるテストデータx_testを作り、各クラス確率と分類結果を確認します。
# テストデータ
x_test = [[5.1, 3.5, 2.5, 1.7]] # petal length(cm)=3つ目の説明変数 > 2.45にする
print(tree_clf.predict_proba(x_test))
# -> [[0. 0.5 0.5]] # [0(setosa)の確率, 1(versicolor)の確率, 2(virginica)の確率] ★1と2の確率が同じ
print(tree_clf.predict(x_test))
# -> [1] # クラス1(versicolor)に分類された
3. 決定木2: 生成とプロット
ここで、クラスインデックスが入れ替わるようにクラス値1を3に置換し、y2を作成します。
y2を正解ラベルとして新しいモデルを作成します。
y2 = y.copy()
# クラス値1(versicolor) の値を 3 にする
y2[y2==1] = 3
print(set(y2))
# -> {0, 2, 3}
# 上記置換に合わせてクラス名のリストを作成
class_names = ["setosa", "virginica", "versicolor"] # 0=setosa, 2=virginica, 3=versicolor
tree_clf2 = DecisionTreeClassifier(max_depth=1, random_state=42)
tree_clf2.fit(X, y2)
新モデルもクラスインデックス、クラス値の対応を見ておきます。
# クラスインデックス、クラス値の対応
for idx, class_val in enumerate(tree_clf2.classes_):
print(f"クラスインデックス: {idx} クラス値: {class_val}")
# -> クラスインデックス: 0 クラス値: 0
# -> クラスインデックス: 1 クラス値: 2
# -> クラスインデックス: 2 クラス値: 3
生成された決定木をプロットします。
plot_tree(
tree_clf2,
feature_names=iris.feature_names,
class_names=class_names,
impurity=False,
node_ids=True
)
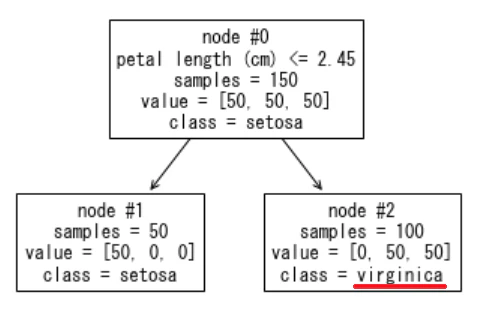
4. 決定木2: テストデータの各クラス確率と分類結果
上記3で使用したテストデータx_testの、新しいモデルによる各クラス確率と分類結果を確認します。
print(tree_clf2.predict_proba(x_test))
# -> [[0. 0.5 0.5]] # [0(setosa)の確率, 2(virginica)の確率, 3(versicolor)の確率]
print(tree_clf2.predict(x_test))
# -> [2] # クラス2(virginica)に分類された
クラスインデックスを変えただけで分類結果が変わりました。
感想
そもそもこのようなリーフノードでは、どちらのクラスに分類すべき、と言えません。
分類結果だけでなく決定木の状態確認も重要ですね。