背景
モールス信号は . と - の並びなので、画像から読み取るだけなら普通の OCR で十分そうに見えます。
ただ、Morse code image decoder を作る立場で見ると、これは意外と扱いにくい入力です。画像の中にあるのは自然言語の文字列ではなく、点・線・空白・改行・単語間隔の組み合わせです。OCR が一部を読み落とすだけで、復号後の文章全体が崩れます。
この記事では、Morse Coder の画像デコード機能を例に、画像内のモールス信号を OCR だけで処理しづらい理由と、OCR の初期結果を AI 補助で見直す流れについて整理します。
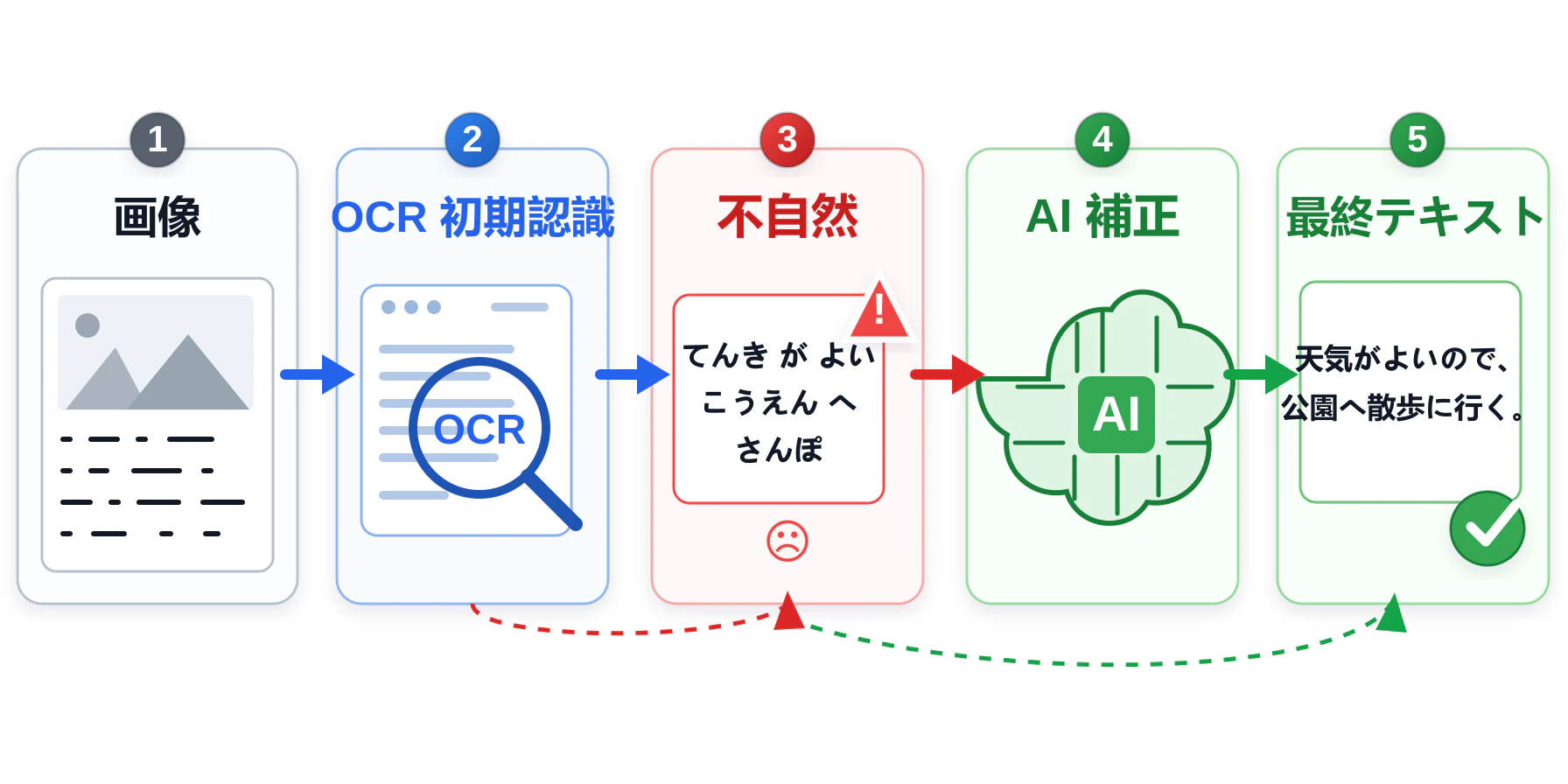
なぜ普通の OCR だけではつらいのか
通常の OCR は、文字の形を読んで単語や文章にします。一方、モールス信号画像で重要なのは、文字の形そのものよりも次のような構造です。
- 点と線の長さの違い
- 文字内の間隔
- 文字同士の間隔
- 単語同士の間隔
- 行折り返しや画像の余白
- スクリーンショットや写真の圧縮ノイズ
たとえば ... --- ... のようなきれいな入力なら簡単ですが、実際の画像では点が小さすぎたり、線がかすれたり、余白が詰まったりします。OCR が . を読み落とす、- を別の記号として扱う、空白を潰す、といったことが起きると、モールスとしての区切りが失われます。
今回使っている処理フロー
Morse Coder では、画像デコードを「OCR で一発確定」とは扱っていません。基本的には次のような流れです。
画像アップロード
↓
OCR による初期読み取り
↓
モールスとして復号
↓
文章として不自然な場合は AI が画像と文脈を見直す
↓
候補結果を人間が確認する
ここで重要なのは、AI を OCR の代わりとして雑に置くのではなく、OCR の結果が文章として不自然なときに補助的に使う点です。最初の OCR 結果をそのまま信じるより、画像そのものと復号後の文脈をもう一度見直した方が、点・線・間隔の取り違えに気づきやすくなります。
失敗しやすい条件
画像内のモールス信号は、次の条件で特に不安定になりやすいです。
- 低解像度のスクリーンショット
- 斜めから撮影された写真
- 背景と点・線のコントラストが弱い画像
- 文字間・単語間の空白が均一でない画像
- 複数行に分かれていて行間が狭い画像
- 圧縮で点や線の端が潰れている画像
このあたりは、通常の文章 OCR でも問題になりますが、モールス信号では空白が意味を持つため影響が大きくなります。特に「文字間の空白」と「単語間の空白」を誤ると、復号後の英文がまったく別の見え方になります。
使う側でできる対策
ツール側でできることには限界があります。入力画像を用意する側で、次の点を意識すると結果を確認しやすくなります。
- できるだけ高解像度の画像を使う
- 点・線と背景のコントラストを上げる
- 余白を残しつつ、対象部分だけを切り抜く
- 斜め撮影ではなく正面から撮る
- 結果が不自然な場合は原画像と照らし合わせる
デコーダーの出力は最終答案というより、確認しやすい候補として扱う方が安全です。
デモ
この流れは Morse Coder の画像デコードページ で試せます。
ブラウザ上で画像をアップロードし、OCR の初期結果と AI 補助の結果を確認する形です。入力画像の品質によって結果は変わるため、重要な用途では必ず原画像との照合が必要です。
まとめ
画像内のモールス信号は、見た目よりも OCR に向いていません。理由は、読むべき対象が「文字」ではなく、点・線・空白の時間的な構造に近いものだからです。
そのため、OCR で初期結果を出し、復号後の文章が不自然なときに AI 補助で画像と文脈を見直す、という段階的な流れにしています。全自動で確定する認識ではなく、人間が確認しやすい候補を作るためのワークフローとして考えるのが現実的でした。