はじめに
最近、機械学習や深層学習の問い合わせが増えてきていて、もう少し実践的な事例を少し増やしてみたほうが良いかな〜なんて考えていたら家にトミカがいくつかあったのでこれを使って畳み込みニューラルネットワーク(CNN)を試してみました。
用意したもの
- パソコン(MacPro, RAM 64GB, SSD 256GB + HDD 4TB)
- Python 3.x(pyenv + Anaconda)
- OpenCV
- TensorFlow
- Keras
- Yolo(DarkFlow)
- ターンテーブル(ダイソーで150円でした)
- スマートフォン用3脚(ダイソーで100円でした)
- 撮影用スマートフォン(iPhone)
データ作成
これと...

これを...

使って、ターンテーブルを手でくるくる回しながら...

動画を撮影します。
撮影した動画は以下のような感じ。

撮影した動画はファイル名から車種がわかるように、発売年と番号を使ったファイル名にしておきます(例「0000-000.mov」)。
今回は手元にあった3つのトミカを使用しました。
環境構築
大まかな部分は以下の記事を参照。
ただ、今ではOpenCVはコマンド一発でインストールできるので、Anacondaを入れたら以下の手順に進んで下さい。
Macで深層学習の環境をさくっと作る手順 with TensorFlow and OpenCV
- OpenCV
pip install opencv-python
- TensorFlow
pip install tensorflow
tensorflowのバージョンが2.0以降では動作しないようなので、以下の対応が必要。
pip uninstall tensorflow
pip install tensorflow==1.14
- Keras
pip install keras
- Yolo
git clone https://github.com/thtrieu/darkflow.git
cd darkflow
pip install .
ついでにこちらもダウンロードしておきます。
作業ディレクトリ
ホームにworkというフォルダを作成して作業します。
cd ~/
mkdir work
cd work
mkdir bin
mkdir cfg
mkdir mov
mkdir img
ここで、binには先ほどダウンロードしたyolov3.weightsを入れます。
cfgにはdrakfowの中にあるcfgフォルダからyolo.cfgをコピーします。
movには先ほど撮影したトミカの動画を入れておきます。
imgには次のステップで動画から切り出したトミカの画像を入れます。
トミカ画像の抽出
以下のスクリプトを作成して実行。
import cv2
import os
from glob import glob
from darkflow.net.build import TFNet
# Yoloの初期化
options = {
"model": "cfg/yolo.cfg",
"load": "bin/yolov3.weights",
"threshold": 0.4,
"gpu": 0.4
}
tfnet = TFNet(options)
# 動画ファイル取得
files = glob("mov/*.MOV")
for file in files:
image_dir = "img/"
# 動画名から保存用ディレクトリを作成
dirname = filename.split("/")[1].split(".")[0]
image_dir = image_dir + dirname + "/"
print(image_dir)
os.mkdir(image_dir)
# 動画読込
cap = cv2.VideoCapture(filename)
print("frame count : {}".format(cap.get(cv2.CAP_PROP_FRAME_COUNT)))
i = 0
cnt = 0
while(cap.isOpened()):
# フレーム画像を取得
flag, src = cap.read()
if flag == False:
break
# 被写体を検出
result = tfnet.return_predict(src)
# 検出物体を切り出し、連番でファイルに保存
for rs in result:
if rs["label"] == "car":
top = rs["topleft"]["y"]
left = rs["topleft"]["x"]
bottom = rs["bottomright"]["y"]
right = rs["bottomright"]["x"]
dst = src[top:bottom, left:right]
dst = cv2.resize(dst, (224,224))
cv2.imwrite(image_dir + "{:06}.jpg".format(cnt), dst)
cnt += 1
i += 1
cap.release()
実行が終わると、以下のようにトミカのみを抽出した画像が入手できます。
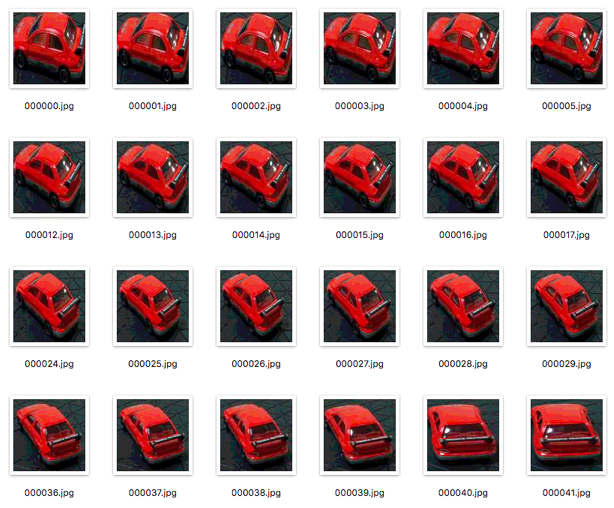
感覚的にターンテーブルは2回くらい回せば十分な画像が手にな入るかなと思います(^-^)
画像を学習
以下のスクリプトを作成して実行。
import cv2
import numpy as np
import sys
import os
from glob import glob
import random
from sklearn import model_selection
from sklearn.metrics import confusion_matrix
from keras.utils.np_utils import to_categorical
from keras.models import Sequential
from keras.layers import Activation, Conv2D, Dense, Flatten, MaxPooling2D
files = glob("img/*/*.jpg")
# ラベル作成
labels = []
for file in files:
label = file.split("/")[1]
if label not in labels:
print(label)
labels.append(label)
labels.sort()
# ファイル読込
ref = list(range(len(files)))
random.shuffle(ref)
X = []
y = []
for i in ref:
file = files[i]
label = file.split("/")[1]
y.append(labels.index(label))
img = cv2.imread(file)
X.append(img)
X = np.array(X)
X = X / 255
# データを学習・検証・テスト用に分割
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=.5, random_state=42)
X_valid, X_test, y_valid, y_test = model_selection.train_test_split(X_test, y_test, test_size=.5, random_state=42)
y_train = to_categorical(y_train)
y_valid = to_categorical(y_valid)
y_test = to_categorical(y_test)
# 学習モデルの作成
model = Sequential()
input_shape = X[0].shape
model.add(Conv2D(input_shape=input_shape, filters=32, kernel_size=(3, 3), strides=(1, 1), padding="same", activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=32, kernel_size=(3, 3), strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=32, kernel_size=(3, 3), strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation("sigmoid"))
model.add(Dense(128))
model.add(Activation('sigmoid'))
model.add(Dense(len(labels)))
model.add(Activation('softmax'))
# モデルのコンパイル
model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy'])
# 学習
history = model.fit(X_train, y_train, batch_size=10, epochs=5, verbose=1, shuffle=True, validation_data=(X_valid, y_valid))
# 予測
pred = model.predict(X_test,batch_size=1)
y_obs = []
y_pred = []
for i in range(len(pred)):
y_obs.append(np.argmax(y_test[i]))
y_pred.append(np.argmax(pred[i]))
print(confusion_matrix(y_obs, y_pred))
実行結果。
Train on 650 samples, validate on 325 samples
Epoch 1/5
650/650 [==============================] - 61s 93ms/step - loss: 1.0946 - acc: 0.4554 - val_loss: 0.9541 - val_acc: 0.4492
Epoch 2/5
650/650 [==============================] - 58s 90ms/step - loss: 0.7881 - acc: 0.6954 - val_loss: 0.5581 - val_acc: 0.7015
Epoch 3/5
650/650 [==============================] - 60s 93ms/step - loss: 0.4407 - acc: 0.8492 - val_loss: 0.3551 - val_acc: 0.9754
Epoch 4/5
650/650 [==============================] - 61s 93ms/step - loss: 0.2700 - acc: 0.9877 - val_loss: 0.2128 - val_acc: 0.9908
Epoch 5/5
650/650 [==============================] - 60s 92ms/step - loss: 0.1481 - acc: 1.0000 - val_loss: 0.1389 - val_acc: 0.9908
array([[ 93, 0, 0],
[ 0, 139, 0],
[ 0, 0, 93]])
できた!
その後
3台だった車種を6台に増やして、新しく撮影した写真をつかって正しく車種を識別できるか試してみました。
まず、上述の学習スクリプトの末尾に以下の一文を追記して再学習。
# モデルを保存
model.save("mdl_tomica.h5")
mdl_tomica.h5に学習済みモデルが保存されるので、これを読み込んで車種を識別するスクリプトを作成します。
import cv2
import numpy as np
import sys
import os
from glob import glob
import random
from darkflow.net.build import TFNet
from keras.models import load_model
# Yoloの初期化
options = {
"model": "cfg/yolo.cfg",
"load": "bin/yolo3.weights",
"threshold": 0.4,
"gpu": 0.4
}
tfnet = TFNet(options)
# ラベル初期化
files = glob("img/*")
labels = []
for file in files:
label = file.split("/")[1]
if label not in labels:
print(label)
labels.append(label)
labels.sort()
# 学習済みモデル読込
model = load_model("mdl_tomica.h5")
# 識別用関数
def pred_from_file(file):
src = cv2.imread(file)
print(type(src))
result = tfnet.return_predict(src)
result
for rs in result:
top = rs["topleft"]["y"]
left = rs["topleft"]["x"]
bottom = rs["bottomright"]["y"]
right = rs["bottomright"]["x"]
dst = src[top:bottom, left:right]
dst = cv2.resize(dst, (224,224))
X_pred = [dst]
X_pred = np.array(X_pred)
X_pred = X_pred / 255
pred = model.predict(X_pred,batch_size=1)
print(pred)
print(labels[np.argmax(pred)])
print()
files = "img/IMG_8235.jpeg"
print("* " + file)
pred_from_file(file)
使用したのはこの写真。

Yoloで抽出した画像は以下のような感じ。

実行した結果は、以下のとおり。
* img/IMG_8235.jpeg
<class 'numpy.ndarray'>
[[0.02794252 0.00380562 0.05379121 0.28816053 0.61778307 0.00851709]]
2005-33
正解!
これは台数増やしても高精度で識別できるんだろうか...試すか、もうやめるか...悩むところですね〜。