Hello!!!!
What's up everybody guys!!
ということで
あまたのTouchdesignerユーザーが集うこのアドカレのTOPバッターを務めさせていただくことに感謝を申し上げます。
完全にタイトルが2年前の1日目の
TouchDesignerでOpenCVを使った簡単な顔認識について
に寄せていますが、これも何かの縁ですのでOpenCVでのロゴ検出についてお話していきます
今回の制作物
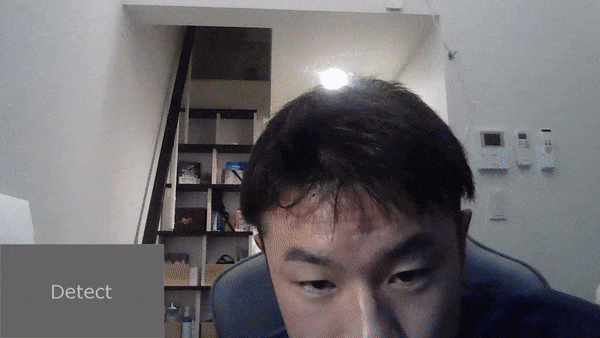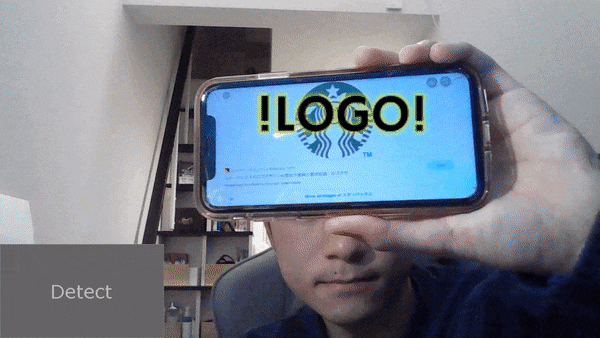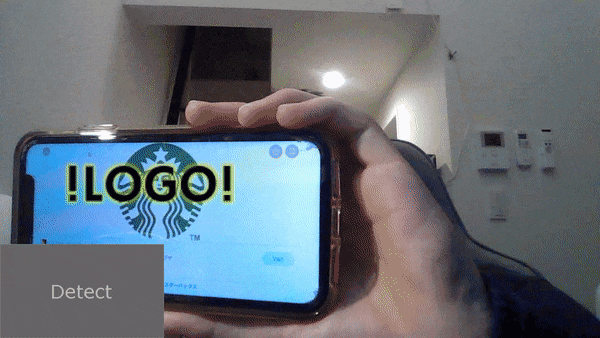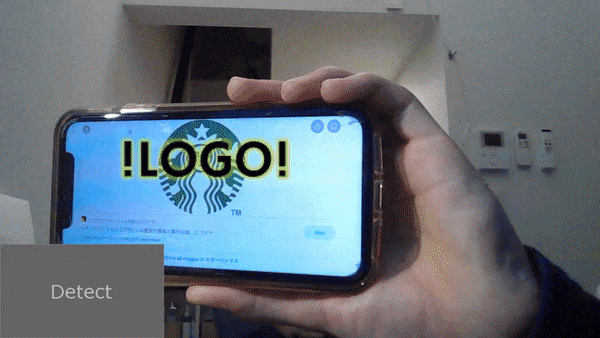
buttonを押すと、スタバのロゴ検出して、そこに !LOGO! がついてきますね。
今回は0からこれを作っていきます。
チュートリアル
まず初めに、この記事には間違っていることやよりいい方法があるかもしれません。その際はこそっと教えてください!
個人的に、文字で説明するよりYoutubeでチュートリアルをやることが多くそっちの方がわかりやすいので、動画を作っています!
ぜひこちらからご覧ください(少し前にqiitaでyoutubeを埋め込みできるようになりました)
内容もりもりで少し長くなっちゃった(てへ)
要点解説
動画の内容を大事なところに絞って解説していきます。
今回使うロゴ
今回はこちらのスターバックスのロゴを使います

ネットで拾ってきたやつですが
ただ個人として使うので、勝手に使ったねーはい!逮捕!とか言わないでええ
project file
そしてこちらのロゴの写真も入ったproject fileがgithubに上がっていますので
動画の概要欄のリンクからぜひダウンロードしてくださいまし
基本セットアップ
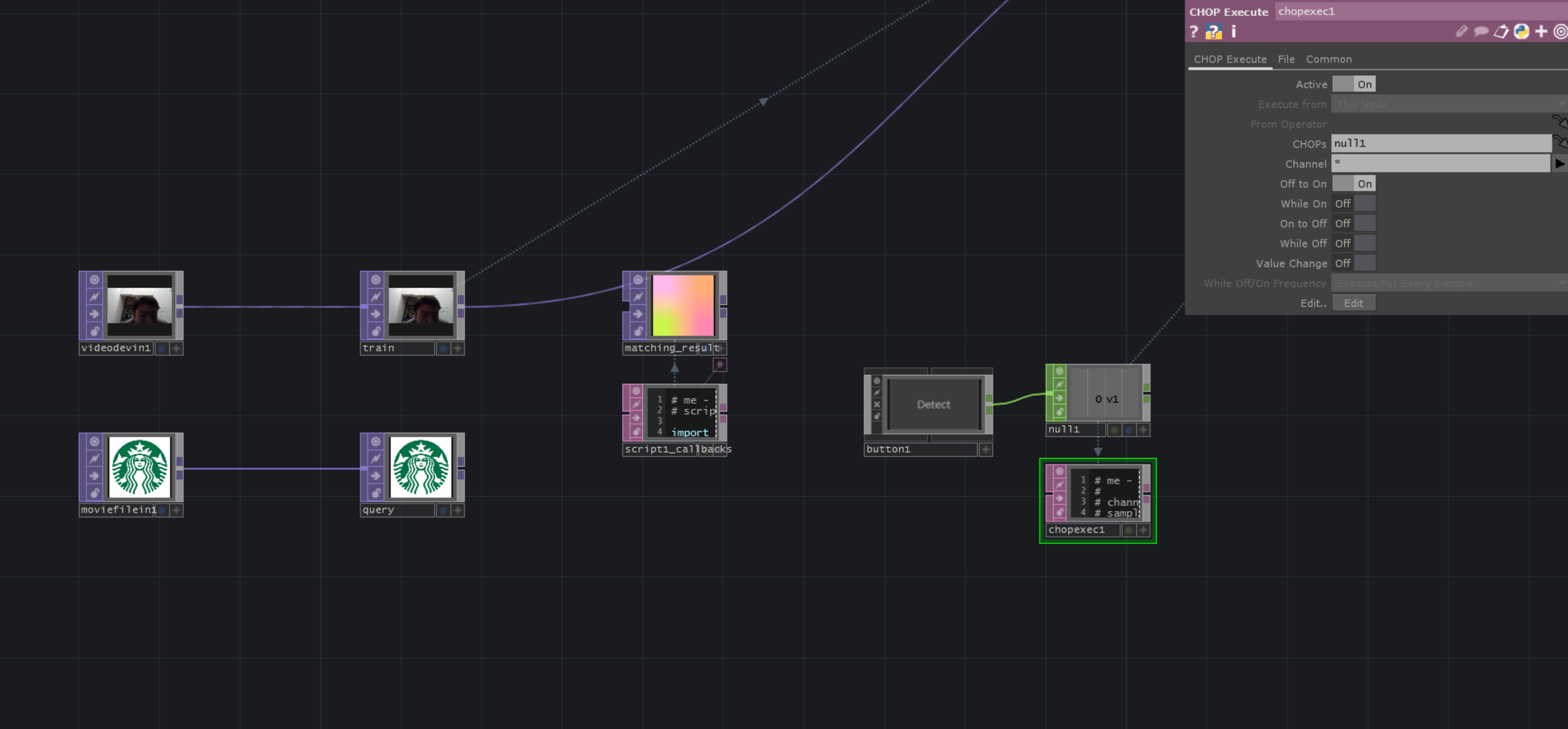
-
video device in-> ロゴを見つけるTOP -
movie file in-> ロゴ参照
それぞれnullにつなげます。
そして検知する方を train
元のロゴを query
と名付けます。
-
script SOP-> 結果確認用 「matching_result」 -
button COMP-> ロゴ検出スタート -
chop execute DATOff To Onで使います。そしてここにコードを書いていきます!
全コード
少し説明することが多いので、まず全コードを公開します!
その後pointごとに解説します!
import numpy
import cv2
def onOffToOn(channel, sampleIndex, val, prev):
trainOp = op('train')
queryOp = op('query')
for i in range(2):
train = trainOp.numpyArray(delayed = True)
query = queryOp.numpyArray(delayed = True)
input_list = []
ratio = 0.65
for item in [train, query]:
item_255 = item * 255
item_uint8 = item_255.astype('uint8')
input_list.append(item_uint8)
train = input_list[0]
query = input_list[1]
#feature detect
detector = cv2.ORB_create()
kp_query, des_query = detector.detectAndCompute(query,None)
kp_train, des_train = detector.detectAndCompute(train,None)
dst_query = cv2.drawKeypoints(query, kp_query, None)
#matcher
matcher = cv2.BFMatcher(cv2.NORM_HAMMING)
try:
#matching
matches = matcher.knnMatch(des_query, des_train, k=2)
#ratio test
good_matches = []
for q, t in matches:
if q.distance < t.distance * ratio:
good_matches.append(q)
matches = good_matches
num_goodmatches = len(matches)
op('good_matches').par.value0 = num_goodmatches
if num_goodmatches > 8:
x_train_pt = [kp_train[m.trainIdx].pt[0] - (trainOp.width/2) for m in matches]
y_train_pt = [kp_train[m.trainIdx].pt[1] - (trainOp.height/2) for m in matches]
x_mean = sum(x_train_pt) / len(x_train_pt)
y_mean = sum(y_train_pt) / len(y_train_pt)
op('text_logo').par.fontalpha = 1
op('transform_logo').par.tx = x_mean
op('transform_logo').par.ty = y_mean
else:
op('text_logo').par.fontalpha = 0
#draw_matching
draw_params = dict(matchColor = (0, 255, 0),
singlePointColor = (255, 0, 0),
flags = cv2.DrawMatchesFlags_DEFAULT)
matching_result = cv2.drawMatches(query, kp_query, train, kp_train, matches, None, **draw_params)
op('matching_result').copyNumpyArray(matching_result)
except cv2.error:
op('matching_result').copyNumpyArray(dst_query)
return
def whileOn(channel, sampleIndex, val, prev):
return
def onOnToOff(channel, sampleIndex, val, prev):
return
def whileOff(channel, sampleIndex, val, prev):
return
def onValueChange(channel, sampleIndex, val, prev):
return
そして残りのノードも全公開
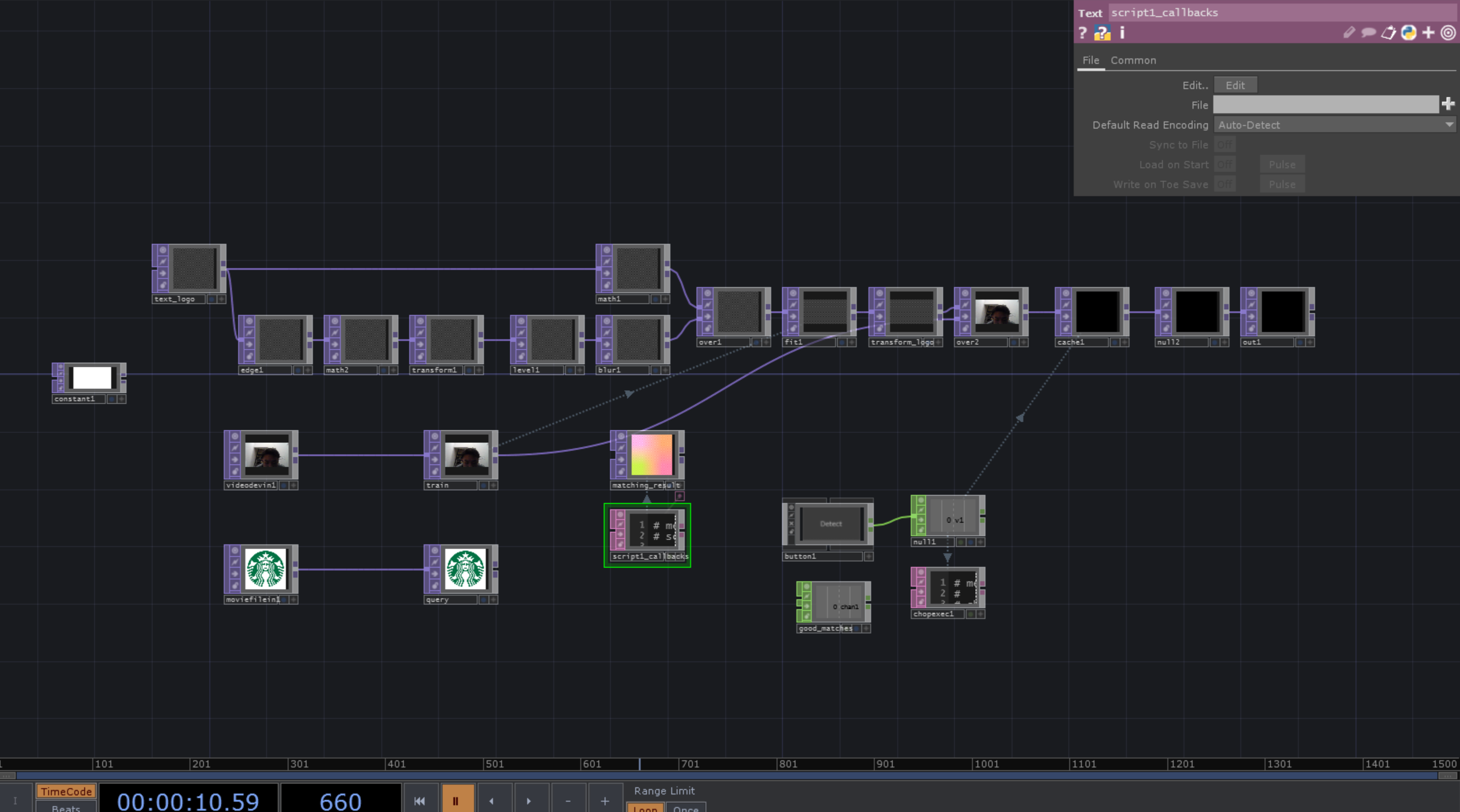
ロゴ検出までの一連の流れ
さあロゴ検出において、OpenCV使うことは予想できていると思います。
じゃあ具体的にどうやんの??
これですよね。
ちょーざっくり言うと、
1.TOPをnumpyに変える
2.train, queryそれぞれの特徴点を検出する
3.それぞれの特徴点をマッチングさせる
4.マッチングした特徴点が多ければ~、ロゴだよね!!
って感じ!
1.TOPをnumpyに変える
これ嘘かと思うかもしれないんですが、
TOPってnumpyなんです
TOPって!numpyなんです!
ごり押ししてすみません
あ、numpyってなに?って方のために
NumPyはベクトルや行列の計算を高速に処理するためのライブラリ
です!
そしてTOPはnumpyの配列になっているので、OpenCVとかのライブラリが使えるわけですね!
今回で言うとここのコードでTOPをnumpyに変換
for i in range(2):
train = trainOp.numpyArray(delayed = True)
query = queryOp.numpyArray(delayed = True)
numpyの配列(matching_result)をTOPに変換
op('matching_result').copyNumpyArray(matching_result)
ちょっとした注意ポイント
numpyArray()だけだと、呼び出すタイミングによってはうまくnumpyに変換することができないことがあります。
それを防ぐのが(delayed = True)です。
これでうまくいった!
と思いがちなんですが、(delayed = True)にすると、
前の処理の結果が返ってきます!!
これは困る!!!!!
ってことでfor文で2回処理を呼んであげてるわけですね!
詳しくはTOP classのdocumentにも記載があるので是非!!
2.train, queryそれぞれの特徴点を検出する
特徴点を検出するには、検出器が必要になります。
フリーザーの戦闘力が知りたい!!ってなったらスカウターが必要ですよね。
そのスカウター自体が検出器
そんなイメージです
今回はORBというアルゴリズムで検出器を作ります
detector = cv2.ORB_create()
そして実際に検出する!
kp_query, des_query = detector.detectAndCompute(query,None)
kp_train, des_train = detector.detectAndCompute(train,None)
思ったよりシンプル。
返り値は、
- keypoint -> 座標とかが入ってる
- descriptor -> マッチングの際に使う
って感じ!
検出された特徴点を確認したいときは、
dst_query = cv2.drawKeypoints(query, kp_query, None)
3.それぞれの特徴点をマッチングさせる
特徴点同士をマッチングさせるときには、マッチング器が必要になります。
これはレアスニーカー鑑定士と一緒ですね。そのスニーカーの特徴が本物と同じであれば、それはレアものとして間違いない!!
となるわけです。
今回はBFMatcherというものを使います!
matcher = cv2.BFMatcher(cv2.NORM_HAMMING)
これまたシンプル!
そしたら、今回のメインディッシュ!
特徴点マッチング!!
#matching
matches = matcher.knnMatch(des_query, des_train, k=2)
#ratio test
good_matches = []
for q, t in matches:
if q.distance < t.distance * ratio:
good_matches.append(q)
matches = good_matches
matcher.knnMatch(des_query, des_train, k=2) はknnMatchといって
それぞれをマッチングさせて上位k個の特徴点を探します
そして信頼度の低い結果を除くため
ratio testというものを行います!
ratioの値が1に近ければ、甘くなって、0に近いほど厳しくなります。
で最終的に、matchesにマッチングできた特徴点のリストが入っている!
というわけでございます!
4.マッチングした特徴点が多ければ~、ロゴだよね!!
さあこのmatches中身が多ければ多いほどマッチング率が高いので
それはロゴ!!
とみなすことができます。
今回はその閾値を8としてそれ以上len(matches)があれば検出!
ということでした。
num_goodmatches = len(matches)
op('good_matches').par.value0 = num_goodmatches
if num_goodmatches > 8:
特徴点の位置
特徴点の位置、ようはピクセルがどこか知りたいときありますよね!
それは、keypointのptというアトリビュートに格納されています。
例えば、indexが1の特徴点の位置は、
kp_train[1].pt -> (x,y)
です。
今回では、特徴点がいくつかあるので平均をその位置として、
値がxは0~1280、yは0~720で入ってくるので
それをTouchdesigner用に、
x -640~640
y -360~360
に変換しています。
transform_logoのTranslateをPixelsに変えるのをお忘れなく!!
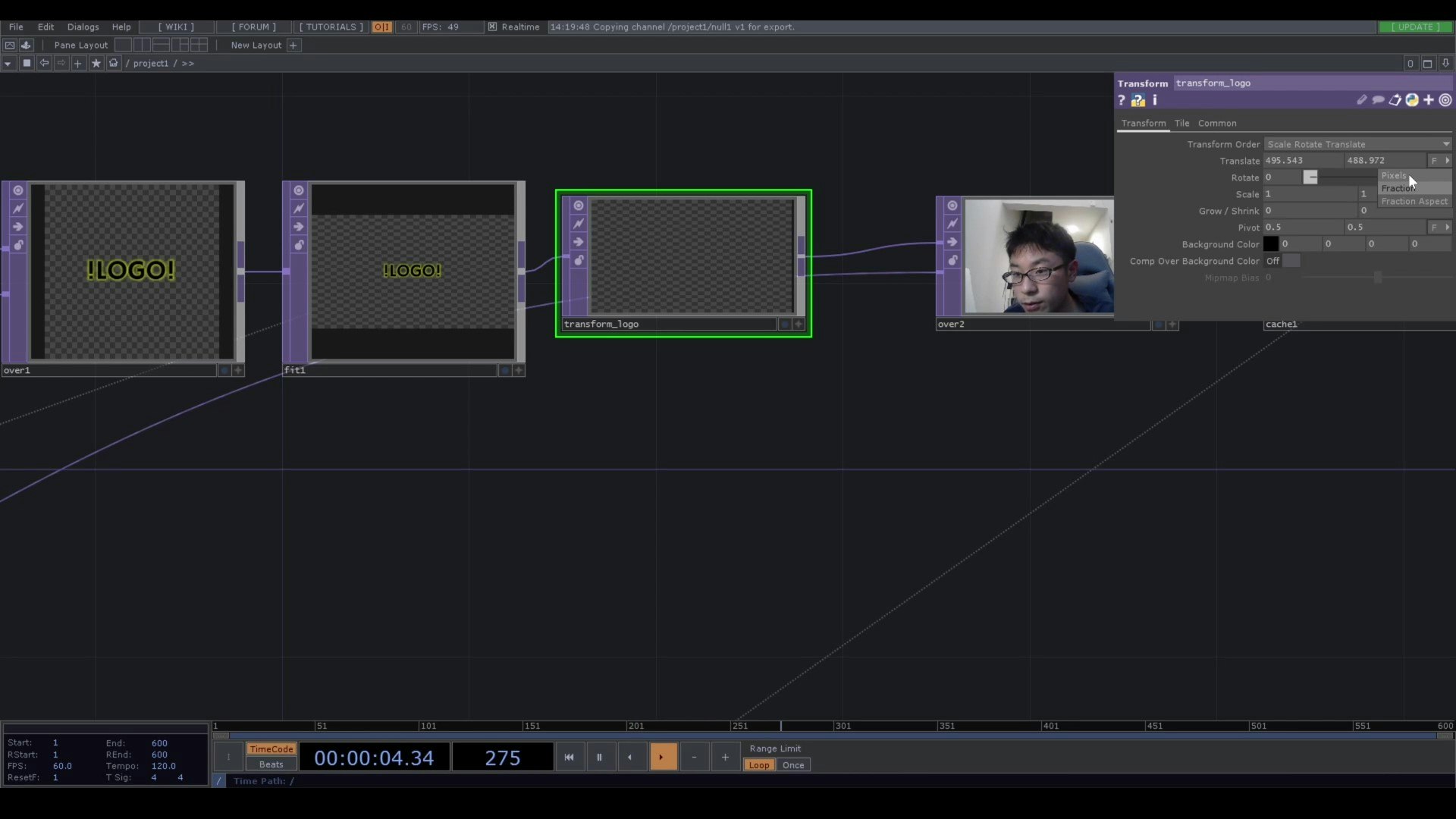
そのほかは動画にて
だいたいのポイントはこちらにて解説しました!
が、例外処理やその他細かいところは動画にてご覧ください!
今回のロゴ検出以外にも、L-systemやHokuyoなどTouchdesigner初心者向けにチュートリアルいくつか出してるので
是非ご覧いただければ嬉しい限りです!
僕の思いとしては、少しでもTouchdesignerを触る人が増えて業界全体を盛り上げることができたらいいな!
と思って、動画や記事を作っていますの今後も皆さんと一緒に歩みたい!
ちょっと最後熱くなってしまいましたが、最後まで読んでいただきありがとうございます!
それでは~~~~