この記事は言語実装 Advent Calendar 2018 13日目の記事です。前日は、raviqqeさんのLLVMでの効率的なUnion型の扱いでした。すっかりLLVM IRが読めなくて愕然としました。alloca命令で返ってくる値は単なる領域を確保されたアドレスだと思ってると、思わぬ最適化をされてびっくりした記憶があります。
さて、私の記事を始めたいと思います。予告編がありますので、読むとより楽しめるかもしれませんし、へたくそなポエムを読まされただけになるかもしれません。
はじめに
現在、mrubyのJIT2(仮称)というプログラムを作っています。正式な名前がまだ無かったり、レポジトリが昔作ったプログラムに間借りしていたりととてもいい加減なもんです。長いのでここではJIT2とします。JIT2の目的は、
- とにかくRubyで書いたものを高速で実行する。その為にコンパイル時間やメモリがどれだけかかっても構わない
- できるかぎりリスキーな技術を使い派手に面白く失敗する。
といったものです。1番目の目的はStalinというSchemeコンパイラの目的に近いでしょうか。
派手に失敗するという目的は、このプログラムが実用を考えていないことを意味します。企業や大学のOSSでは難しい個人ならではの目的と言えるでしょう。派手で面白い失敗は良いアイデアの元です。
JIT2の概要
JIT2はmrubyで書かれたmrubyのコンパイラです。概要はこんな感じです
- mrubyのVM(RITEVM)のバイトコード命令列をSSA化したような中間コードを持っています。JIT2の本質はこの中間コードです
- 中間コードレベルで最適化に必要な情報を集めてコード生成するというアーキテクチャを考えています。データフロー解析などに必要な情報はメモリの肥大化を躊躇することなく持たせます。
- 中間コードを生成するにあたってRITEVMの命令列を仮想実行して、型やデータの寿命などを収集します(仮想実行(Abstract Interpretation))。Rubyでありながら変数やメソッドの型は。基本的に静的に決定しているものとしてコード生成できます。
今の所、型を推定して中間コードを生成するところがある程度のレベルまで完成し、この中間コードの応用例としてC言語に変換するコードを書いています。メソッドの再定義や整数演算のオーバーフロー時の扱いなどをRubyの仕様に忠実に実装するためには最終的には何らかの方法で機械語を直接生成する必要があると考えています。
この記事では型推定については説明しません(興味がある人は多いだろうなとは思いますが)。前に書いた、スライドや記事を参照してください。
中間コード
中間コードは静的単一代入(SSA)のような構造をしています。SSAは代入が必ず一回しか現れないコード形式です。SSAを実装するためには
- 代入は必ず1回だけにするため、複数回代入する場合にはバージョン付きの物にリネームする必要があります
- SSAでは制御構造の扱いが面倒になります。内部に制御構造を含まないコード列(基本ブロックと呼ばれますが、Rubyのブロックと紛らわしいのでここではNodeと呼びます)に分解する必要があります。
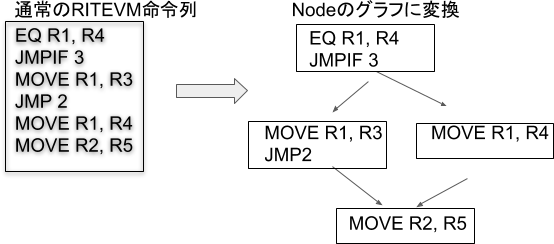
- SSAのφ関数とは違い、この中間コードではレジスタが生存していようと、死んでいようと全てのレジスタをNode間で受け渡します(手抜き)。レジスタが生存しているかどうか判定するのはユーザの責任です。
JIT2の中間コードは単なるテキスト列(またはバイト列)ではなく、複数の種類のmrubyのオブジェクトが配列またはリンクリストで接続されているような構造を持っています。そのため、命令列としてテキストに書きだすことは(おそらく)困難でです。
しかし、SSAで重要な面倒なレジスタの名前を定義箇所に応じたバージョン付きの物にリネームする問題がオブジェクトのIDという形で簡単になるというメリットがあります。
中間コードの構造
中間コードは以下のような、Block, Node, INST(命令)と階層構造になっています。これらはすべてmrubyのオブジェクトです。

また、色々な所にレジスタとありますが、このレジスタもmrubyのオブジェクトです。
レジスタは様々な情報を保持しており、次のような情報をもっています。RITEVMのレジスタだけではなく、インスタンス変数やグローバル変数や配列の要素などにも同じようにレジスタオブジェクトを割り当てています。
- type 型
- genpoint このレジスタに代入した命令(単一代入だから常に1つ)
- refpoint このレジスタを参照している命令
typeの重要性は言うまでもないですが、genpointを使うことで定数畳み込みなどの最適化が容易になるし、refpointを用いることで寿命解析が可能になります。詳しくはC言語への生成の所で説明します。
また、typeの中身である型を表す型オブジェクトには次のような情報をもっています。
- class_object クラス(Rubyの生のクラスオブジェクト)
- val 値(あれば)
- place この型のデータが存在する場所
placeが変わっているというかなにこれ?って思われると思いますが、エスケープ解析を実現するためのしくみです。型情報などを収集するために行う仮想実行で、代入命令やArray#[]=メソッドの実行などの時にplaceに情報を付け加えていきます。placeは場所を表すオブジェクトの集合(実装はHash)で次のようなオブジェクトからなります。
- レジスタ そのレジスタに格納されている可能性がある(現在実行中のメソッドのRITEVMのレジスタを除く)
- true グローバル変数などに入るため必ずエスケープする
- Procの型オブジェクト このProcオブジェクトのクロージャに入っている可能性がある
placeが空集合の時はエスケープしないと言えます。trueが含まれているときは必ずエスケープします。そうじゃない時は、その親(インスタンス変数ならそのインスタンス)がエスケープするかによります。
C言語への変換
ここでは、具体的に中間コードをCに変換する手順を紹介します。全部紹介するのは無理なので、私が面白いと思ったところを紹介します。
型
Rubyの型推定の結果をCの型に変換する処理です。大体は自明なことですけど、自明じゃない部分もあります。処理全体はこんな感じです。汚いプログラムで済みません。
TTABLE = {
Fixnum => :mrb_int,
Float => :mrb_float,
Array => :array,
NilClass => :nil
}
def self.get_ctype_aux(ccgen, inst, reg, tup)
rtype = reg.type[tup]
if !rtype then
# for element of array
rtype = reg.type[reg.type.keys[0]]
if rtype.nil? then
return :mrb_value
end
end
cls0 = rtype[0].class_object
if rtype.all? {|e| e.class_object == cls0} then
res = TTABLE[cls0]
if res then
return res
end
end
if rtype.all? {|e|
cls = e.class_object
cls == TrueClass || cls == FalseClass
} and rtype.size > 0 then
return :mrb_bool
end
:mrb_value
end
def self.get_ctype(ccgen, inst, reg, tup)
type = get_ctype_aux(ccgen, inst, reg, tup)
case type
when :array
if !is_escape?(reg) then
uv = MTypeInf::ContainerType::UNDEF_VALUE
ereg = reg.type[tup][0].element[uv]
rc = get_ctype_aux(ccgen, inst, ereg, tup)
if rc == :array then
:mrb_value
else
rc
end
else
:mrb_value
end
else
type
end
end
get_ctypeがRubyの型をCの方に変換するメインになるのですが、配列を除くと下請メソッドのget_ctype_auxで行っています。get_ctype_auxの方が簡単なので、はじめにここから説明します。
TTABLE = {
Fixnum => :mrb_int,
Float => :mrb_float,
Array => :array,
NilClass => :nil
}
def self.get_ctype_aux(ccgen, inst, reg, tup)
rtype = reg.type[tup]
if !rtype then
# for element of array
rtype = reg.type[reg.type.keys[0]]
if rtype.nil? then
return :mrb_value
end
end
cls0 = rtype[0].class_object
if rtype.all? {|e| e.class_object == cls0} then
res = TTABLE[cls0]
if res then
return res
end
end
if rtype.all? {|e|
cls = e.class_object
cls == TrueClass || cls == FalseClass
} and rtype.size > 0 then
return :mrb_bool
end
:mrb_value
end
最初の、if !rtype then の部分は闇です。無いと動かない場合がありますが、これが何をしているのか型推定の所で挙げたスライドを全部理解した人なら説明して分かってもらえるかもって話のなので飛ばします。
ここを除くと後は簡単です。単にテーブルを引くだけです。ここで、Arrayのarrayという型、こんな型Cにあったっけ?って思うかもしれません。この型はダミーでget_ctypeで使います。
def self.get_ctype(ccgen, inst, reg, tup)
type = get_ctype_aux(ccgen, inst, reg, tup)
case type
when :array
if !is_escape?(reg) then
uv = MTypeInf::ContainerType::UNDEF_VALUE
ereg = reg.type[tup][0].element[uv]
rc = get_ctype_aux(ccgen, inst, ereg, tup)
if rc == :array then
:mrb_value
else
rc
end
else
:mrb_value
end
else
type
end
end
get_ctype_auxで:arrayが返って来た時だけget_ctypeは仕事をします。それ以外は丸投げです。
:arrayが返って来た時は、このレジスタのデータがエスケープするかを判定します。エスケープする場合は配列をヒープに取らないといけないので、有無を言わさずCレベルの型はmrb_value(mrubyでRubyのオブジェクトを格納する型)になります。
エスケープしないならCレベルの配列になるのですが、Cでは配列を宣言するためには要素の型が必要です。JIT2では当然配列の要素の型も推定しているので、それを取り出します。reg.type[tup][0].element[uv]がその場所です。配列の要素を表すレジスタを取り出して、再帰的に型を取り出します。配列が入れ子だった場合はがんばることもできるのですが、ここではがんばらないでRubyの配列を使います。
エスケープするかどうかを判定するis_escape?の定義はこんな感じです。
def self.is_escape?(reg)
plist = reg.type.keys.map { |tup|
reg.type[tup].map {|ty| ty.place.keys}.flatten.uniq
}.flatten.uniq
plist.size != 0
end
小難しそうですが、placeが完全に空ならエスケープしない、そうじゃなければエスケープするって判定しているだけです。もっと精度が高くて面倒くさいコードにすることもできますが、今の所は手抜きバージョンを使っています。
メソッド呼び出し
C言語への変換はRITE VMの命令を変換することで行います。命令毎にどう変換するのかはcgen_c_oprule.rbに定義してあります。しかし、これ見てもらえると分かると思いますが、ほとんどの命令は何もしません。では何もしていないかというとそんなことはありません。
何かをおこなう命令の1つであるメソッド呼び出しをおこなうSEND命令を例にどうC言語に変換するか説明します。
SEND命令の処理は次のようになります。
def self.op_send_aux(ccgen, inst, node, infer, history, tup)
name = inst.para[0]
intype = inst.inreg.map {|reg| reg.flush_type(tup)[tup] || []}
intype[0] = [intype[0][0]]
rectype = intype[0][0].class_object
mtab = MTypeInf::TypeInferencer.get_ruby_methodtab
rectype.ancestors.each do |rt|
if @@ruletab[:CCGEN_METHOD][name] and mproc = @@ruletab[:CCGEN_METHOD][name][rt] then
return mproc.call(ccgen, inst, node, infer, history, tup)
else
if mtab[inst.para[0]] and mtab[inst.para[0]][rt] then
proc = mtab[inst.para[0]][rt]
else
next
end
nreg = inst.outreg[0]
ccgen.dcode << gen_declare(ccgen, inst, nreg, tup)
ccgen.dcode << ";\n"
utup = infer.typetupletab.get_tupple_id(intype, MTypeInf::PrimitiveType.new(NilClass), tup)
fname = gen_method_func(name, rt, utup)
args = inst.inreg.map {|reg|
reg_real_value(ccgen, reg, node, tup, infer, history)
}.join(", ")
ccgen.pcode << "v#{nreg.id} = #{fname}(mrb, #{args});\n"
minf = [name, proc, utup]
if ccgen.using_method.index(minf) == nil then
ccgen.using_method.push minf
end
return
end
end
ccgen.pcode << "mrb_no_method_error(mrb, mrb_intern_lit(mrb, \"#{name}\"), mrb_nil_value(), \"undefined method #{name}\");\n"
nil
end
まずは、メソッド名、引数の型・レジスタ、レシーバーの型などを使いやすいようにローカル変数に格納します。
name = inst.para[0]
intype = inst.inreg.map {|reg| reg.flush_type(tup)[tup] || []}
intype[0] = [intype[0][0]]
rectype = intype[0][0].class_object
mtab = MTypeInf::TypeInferencer.get_ruby_methodt
次にメソッド検索を行います。現状はレシーバーの型が一意に決まる場合のみをサポートしています。そのため、メソッドサーチのコードは生成しません(できません)。
メソッドサーチはこんな感じでコンパイル時に行います。レシーバーの型が分かっているので簡単です。
メソッドが組み込みメソッドかの判定
if @@ruletab[:CCGEN_METHOD][name] and mproc = @@ruletab[:CCGEN_METHOD][name][rt] then
メソッドがユーザ定義の物かの判定
if mtab[inst.para[0]] and mtab[inst.para[0]][rt] then
次に引数を組み立てます。引数を組み立て終わればあとはメソッドを呼び出すだけです。JIT2ではメソッドはCの関数の形で定義されます。
args = inst.inreg.map {|reg|
reg_real_value(ccgen, reg, node, tup, infer, history)
}.join(", ")
reg_real_valueってのがレジスタの値がCに変換するメソッドです。こんな定義です。
def self.reg_real_value(ccgen, reg, node, tup, ti, history)
rc = reg_real_value_noconv(ccgen, reg, node, tup, ti, history)
end
def self.reg_real_value_noconv(ccgen, reg, node, tup, ti, history)
if reg.is_a?(RiteSSA::ParmReg) then
if node.enter_link.size == 1 then
pnode = node.enter_link[0]
preg = pnode.exit_reg[reg.genpoint]
return reg_real_value(ccgen, preg, pnode, tup, ti, history)
end
if node.enter_link.size == 0 then # TOP of block
ptype = ti.typetupletab.rev_table[tup][reg.genpoint]
if ptype and ptype.size == 1 and
ptype[0].class == MTypeInf::LiteralType then
return ptype[0].val
end
end
return "v#{reg.id}"
end
gins = reg.genpoint
if !gins then
return "mrb_nil_value()"
end
case gins.op
when :MOVE
reg_real_value(ccgen, gins.inreg[0], node, tup, ti, history)
when :LOADL, :LOADI
gins.para[0]
when :LOADSYM
"mrb_intern_lit(mrb, \"#{gins.para[0]}\")"
when :LOADNIL
"mrb_nil_value()"
when :LOADSELF
"self"
when :GETCONST
gins.para[1]
when :ENTER
i = gins.outreg.index(reg)
reg_real_value(ccgen, gins.inreg[i], node, tup, ti, history)
when :EQ
gen_term(ccgen, gins, node, tup, ti, history, gins.inreg[0], gins.inreg[1], :==)
when :LT
gen_term(ccgen, gins, node, tup, ti, history, gins.inreg[0], gins.inreg[1], :<)
when :LE
gen_term(ccgen, gins, node, tup, ti, history, gins.inreg[0], gins.inreg[1], :<=)
when :GT
gen_term(ccgen, gins, node, tup, ti, history, gins.inreg[0], gins.inreg[1], :>)
when :GE
gen_term(ccgen, gins, node, tup, ti, history, gins.inreg[0], gins.inreg[1], :>=)
when :ADD
gen_term(ccgen, gins, node, tup, ti, history, gins.inreg[0], gins.inreg[1], :+)
when :SUB
gen_term(ccgen, gins, node, tup, ti, history, gins.inreg[0], gins.inreg[1], :-)
when :MUL
gen_term(ccgen, gins, node, tup, ti, history, gins.inreg[0], gins.inreg[1], :*)
when :DIV
gen_term(ccgen, gins, node, tup, ti, history, gins.inreg[0], gins.inreg[1], :/)
when :ADDI
gen_term(ccgen, gins, node, tup, ti, history, gins.inreg[0], gins.para[1], :+)
when :SUBI
gen_term(ccgen, gins, node, tup, ti, history, gins.inreg[0], gins.para[1], :-)
else
"v#{reg.id}"
end
end
くそ長いですが、やっていることは分かりやすいと思います。 gins = reg.genpointの部分が肝です。これでregを作成した命令(つまりregの値はこの命令の出力)を得ています。これらが、何かで場合分けすることでレジスタの代入,参照を1つスキップできます。
さらに、それらの命令が四則演算や比較であれば、さらに遡って展開できます。また値が定数ならその場で計算してしまいます(eval便利)。この辺がgen_termの仕事で次のようなコードです。
def self.gen_term(ccgen, gins, node, tup, ti, history, reg0, reg1, op)
if reg0.is_a?(RiteSSA::Reg) then
arg0 = reg_real_value(ccgen, reg0, node, tup, ti, history)
case reg0.type[tup].size
when 1
type0 = reg0.type[tup][0].class_object
else
type0 = Object
end
else
arg0 = reg0
type0 = arg0.class
end
if reg1.is_a?(RiteSSA::Reg) then
arg1 = reg_real_value(ccgen, reg1, node, tup, ti, history)
case reg1.type[tup].size
when 1
type1 = reg1.type[tup][0].class_object
else
type1 = Object
end
else
arg1 = reg1
type1 = arg1.class
end
if (type0 == Fixnum or type0 == Float) and
(type1 == Fixnum or type1 == Float) then
if arg0.class != String and arg1.class != String then
eval "(#{arg0} #{op} #{arg1})"
else
"(#{arg0} #{op} #{arg1})"
end
elsif op == :== and
type0 == type1 then
if arg0.class != String and arg1.class != String then
eval "(#{arg0} #{op} #{arg1})"
else
"(#{arg0} #{op} #{arg1})"
end
else
op_send_aux(ccgen, gins, node, ti, history, tup)
nil
end
end
今見たら、最後のop_send_auxの部分がバグっていることに気づきました。そんな感じでこのコードの解説はなしです。
配列の生成と参照
配列を生成するところと参照するところが、エスケープ解析の結果を使っていて面白いと(私は)思います。
生成がこんな感じ。
define_ccgen_rule_op :ARRAY do |ccgen, inst, node, infer, history, tup|
reg = inst.outreg[0]
aescape = is_escape?(reg)
vals = inst.inreg.map {|reg|
src = reg_real_value(ccgen, reg, node, tup, infer, history)
}
dstt = nil
if aescape then
dstt = :mrb_value
else
dstt = get_ctype(ccgen, inst, inst.outreg[0], tup)
end
i = 0
vals2 = inst.inreg.map {|reg|
srct = get_ctype(ccgen, inst, reg, tup)
rc = gen_type_conversion(dstt, srct, vals[i])
i = i + 1
rc
}
if aescape then
ccgen.hcode << "mrb_value v#{reg.id};"
ccgen.pcode << "{\n"
ccgen.pcode << "mrb_value tmpele[] = {\n"
ccgen.pcode << vals2.join(', ')
ccgen.pcode << "\n};\n"
ccgen.pcode << "v#{reg.id} = mrb_ary_new_from_values(mrb, #{vals.size}, tmpele);\n"
ccgen.pcode << "}\n"
else
type = get_ctype_aux(ccgen, inst, reg, tup)
if type == :array then
uv = MTypeInf::ContainerType::UNDEF_VALUE
ereg = reg.type[tup][0].element[uv]
etype = get_ctype_aux(ccgen, inst, ereg, tup)
ccgen.pcode << "#{etype} v#{reg.id}[] = {\n"
ccgen.pcode << vals2.join(', ')
ccgen.pcode << "\n};\n"
end
end
nil
end
aescapeってのがARRAY命令で出来た配列がエスケープするかの情報をもっていて、エスケープするか、しないかで場合分けしています。もし、エスケープするので配列をヒープに取る必要があるのに、初期値がmrb_valueではない場合は型変換をする必要がありますが、型変換コードを生成するのが、gen_type_conversionです。コードはこんな感じ。mrubyのソース読んだことある人は、なるほどそういうことねって思うし、読んだことが無い人は意味不明なコードかと思います。
def self.gen_type_conversion(dstt, srct, src)
if dstt == srct then
return src
end
case dstt
when :mrb_value
case srct
when :mrb_int
"(mrb_fixnum_value(#{src}))"
when :mrb_float
"(mrb_float_value(mrb, #{src}))"
when :mrb_bool
"((#{src}) ? mrb_true_value() : mrb_false_value())"
when :nil
"#{src}"
else
raise "Not support yet #{dstt} #{srct}"
end
when :mrb_int
"(mrb_fixnum(#{src}))"
when :mrb_float
"(mrb_float(#{src}))"
when :mrb_bool
"(mrb_test(#{src}))"
when :nil
"mrb_nil_value()"
else
raise "Not support yet #{dstt} #{srct}"
end
end
配列を作る所がエスケープするかで場合分けしているので、参照するところも場合分けする必要があるわけです。そんなわけで、配列の参照の生成のコードです。
define_ccgen_rule_method :[], Array do |ccgen, inst, node, infer, history, tup|
srct = get_ctype(ccgen, inst, inst.inreg[0], tup)
dstt = get_ctype(ccgen, inst, inst.outreg[0], tup)
src = reg_real_value(ccgen, inst.inreg[0], node, tup, infer, history)
nreg = inst.outreg[0]
ccgen.dcode << gen_declare(ccgen, inst, nreg, tup)
ccgen.dcode << ";\n"
idx = reg_real_value(ccgen, inst.inreg[1], node, tup, infer, history)
if is_escape?(inst.inreg[0]) then
src = "mrb_ary_ref(mrb, #{src}, #{idx})"
src = gen_type_conversion(dstt, :mrb_value, src)
else
src = "#{src}[#{idx}]"
if srct == :nil then
src = "mrb_nil_value()"
else
src = gen_type_conversion(dstt, srct, src)
end
end
ccgen.pcode << "v#{nreg.id} = #{src};\n"
nil
end
C言語への変換の例
C言語への変換のプログラムはあまり出来ていないので、かぎられた簡単なプログラムしか変換できないのですが、2つほどの変換例を紹介します。
フィボナッチ
def fib(n)
if n == 1 then
1
elsif n == 0 then
1
else
fib(n - 1) + fib(n - 2)
end
end
MTypeInf::inference_main {
p fib(35)
}
MTypeInf::inference_mainはまだファイルから読みだして変換する処理を作っていないのでとりあえずのおまじないです。これを変換すると、次のようなコードが生成されます。
mrb_int main_Object_0(mrb_state *mrb, mrb_value self) {
mrb_int v17;
mrb_int v19;
L0:;
v17 = fib_Object_1(mrb, self, 35, mrb_nil_value());
mrb_p(mrb, (mrb_fixnum_value(v17)));
v19 = v17;
return v19;
}
mrb_int fib_Object_1(mrb_state *mrb, mrb_value self, mrb_int v135, mrb_value v136) {
mrb_int v199;
mrb_int v204;
mrb_int v211;
L9:;
L11:;
L13:;
v199 = fib_Object_2(mrb, self, 34, mrb_nil_value());
v204 = fib_Object_2(mrb, self, 33, mrb_nil_value());
v211 = (v199 + v204);
L14:;
return v211;
}
mrb_int fib_Object_2(mrb_state *mrb, mrb_value self, mrb_int v135, mrb_value v136) {
mrb_int v211;
mrb_int v199;
mrb_int v204;
L9:;
if ((v135 == 1)) goto L10; else goto L11;
L10:;
v211 = 1;
L14:;
return v211;
L11:;
if ((v135 == 0)) goto L12; else goto L13;
L12:;
v211 = 1;
goto L14;
L13:;
v199 = fib_Object_2(mrb, self, (v135 - 1), mrb_nil_value());
v204 = fib_Object_2(mrb, self, (v135 - 2), mrb_nil_value());
v211 = (v199 + v204);
goto L14;
}
もともと生成されたCコードはインデントがついていないのですが、読みやすいようにインデントを付けました。また、ヘッダファイルとかmain関数とかは省いてありますので、このままではコンパイルできません。
fib_Object_1, fib_Object_2がfibメソッドをCに変換したものです。fibはメソッド名、Objectはレシーバのクラス、1とか2が引数の型の組み合わせによるメソッドのバージョン(JIT2ではtupと呼んでいます)です。fibの引数に2バージョンあるの?って思う人がいるかもしれませんが、JIT2の型推定ではfib(35)とfib(n)を別の型として取り扱います。
このことと、定数同士の演算は畳込む最適化から、fib_Object_1であたかも1段インライン化したようなコードになっています。たしか、LLVMもこのようなコードが出ていたと記憶しています(ver 2.5くらいの10年以上前の話ですが)。
ちなみに、mrubyの60~70倍の速度が出ます。
配列
配列の例はJIT2の型推定とエスケープ解析のパワーのデモンストレーションです。
まずは、配列の参照がすべて範囲内で配列そのものがエスケープしない場合です。この場合は明示的にnilを代入していない限り配列の参照でnilが返ってくることが無いしエスケープしない場合は配列はスタックに取ることが出来るので、ほとんどCを手書きしたようなコードが生成されます。
def foo
a = [1, 2, 3]
a[0] + a[1] + a[2]
end
MTypeInf::inference_main {
p foo
}
mrb_int main_Object_0(mrb_state *mrb, mrb_value self) {
mrb_int v15;
mrb_int v17;
L0:;
v15 = foo_Object_1(mrb, self, mrb_nil_value());
mrb_p(mrb, (mrb_fixnum_value(v15)));
v17 = v15;
return v17;
}
mrb_int foo_Object_1(mrb_state *mrb, mrb_value self, mrb_value v82) {
mrb_int v101;
mrb_int v105;
mrb_int v111;
L4:;
mrb_int v97[] = {
1, 2, 3
};
v101 = v97[0];
v105 = v97[1];
v111 = v97[2];
return ((v101 + v105) + v111);
}
一方、範囲外の配列の参照がある場合、nilが返ってきます。配列の参照でnilが返る可能性がある場合はCの型は使えずにRubyのオブジェクトの配列として宣言する必要があります。配列の参照のインデックスが定数ではなく変数である場合、現時点では常に範囲外の参照があるものとして取り扱います。
しかし、これではあまりにも厳しすぎるので何とか配列の参照のインデックスが変数でも範囲外の参照が無いことを保障できないか検討しています。例えば、何らかの宣言を取り入れるとか、整数型に範囲の概念を入れるとか考えています。
def bar
a = [1, 2, 3]
a[0] + a[1] + a[2] + a[3]
end
MTypeInf::inference_main {
p bar
}
mrb_value main_Object_0(mrb_state *mrb, mrb_value self) {
mrb_value v15;
mrb_value v17;
L0:;
v15 = bar_Object_1(mrb, self, mrb_nil_value());
mrb_p(mrb, v15);
v17 = v15;
return v17;
}
mrb_value bar_Object_1(mrb_state *mrb, mrb_value self, mrb_value v88) {
mrb_int v107;
mrb_int v111;
mrb_int v117;
mrb_value v123;
L4:;
mrb_value v103[] = {
(mrb_fixnum_value(1)), (mrb_fixnum_value(2)), (mrb_fixnum_value(3))
};
v107 = (mrb_fixnum(v103[0]));
v111 = (mrb_fixnum(v103[1]));
v117 = (mrb_fixnum(v103[2]));
v123 = v103[3];
mrb_no_method_error(mrb, mrb_intern_lit(mrb, "+"), mrb_nil_value(), "undefined method +");
return mrb_nil_value();
}
配列がエスケープする場合は、配列はヒープに取る必要があります。この場合は、Rubyのオブジェクトとして配列を取り扱います。この場合、配列の参照もmrubyのAPIを用いるように変換されます。
def baz
a = [1, 2, 3]
a[0] + a[1] + a[2]
a
end
MTypeInf::inference_main {
p baz
}
mrb_value main_Object_0(mrb_state *mrb, mrb_value self) {
mrb_int v15;
mrb_int v17;
L0:;
v15 = baz_Object_1(mrb, self, mrb_nil_value());
mrb_p(mrb, v15);
v17 = v15;
return v17;
}
mrb_value baz_Object_1(mrb_state *mrb, mrb_value self, mrb_value v82) {
mrb_int v101;
mrb_int v105;
mrb_int v111;
L4:;
{
mrb_value tmpele[] = {
(mrb_fixnum_value(1)), (mrb_fixnum_value(2)), (mrb_fixnum_value(3))
};
v97 = mrb_ary_new_from_values(mrb, 3, tmpele);
}
v101 = (mrb_fixnum(mrb_ary_ref(mrb, v97, 0)));
v105 = (mrb_fixnum(mrb_ary_ref(mrb, v97, 1)));
v111 = (mrb_fixnum(mrb_ary_ref(mrb, v97, 2)));
return v97;
}
つまり、Rubyレベルで配列を使うと、その場で一番ふさわしい配列の内部表現を自動的に選んでくれるわけです。
これから
まだ、JIT2でのC生成はほとんどできていません。さしあたっての難関はProcオブジェクト(クロージャ)です。RubyらしいプログラムはProcオブジェクトを多用するので、これは必須です。ある程度できているのですが、Cの型システムではどうやってもできないのでお行儀の悪いこと(void*とか)が必要ですがどうやろうか悩んでいます。
ある程度Cで動くようになったらそれ以上作り込むのは無駄です。次はいよいよ機械語を直接生成する処理を作るわけですが、x86/x86-64/armで動かしたいので良いコード生成系を探しているところです。
明日はtzmfreedomさんの「自作言語のデバッガ実装について」の予定です。