はじめに

前回の言語処理100ノックの続きです。
今回はN-gramだけです。
コード作成はJSでプログラムイメージを作ってLipsに変換しました。
出回っている解答サイトのコードは短く簡単ですが
N-gramって何ですかというレベルからのチャレンジでした。
[変更履歴]
2026/01/02 初稿
2026/01/03 「(1) Lipsのvectorを使った場合」追加
2026/01/08 お題 「06.集合」追加
2026/01/15 お題 「07. テンプレートによる文生成」~「09. Typoglycemia」追加
お題 「05. ngram」
与えられたシーケンス(文字列やリストなど)からn-gramを作る関数を作成せよ.この関数を用い,"I am an NLPer"という文から単語bi-gram,文字bi-gramを得よ.
N-gramとは
文章は一つ以上の単語の並びでできていますね。単語は文字列でできています。
という前提で私は以下のように理解しました。
N-gramは一つの文章から任意の単語数または文字数を1塊ずつシフトしながら抜き出す操作のことです。
N-gramは抽出する塊のサイズによって1-gram(uni-gram)、3-gram(tri-gram)という単位があります。(理論的には4以上も可能です)
注意する点があります。抽出するサイズの単位を何にするかです。
- 単語(word)単位 (対象:英語のように単語単位で分かち書きできることば)
文字列をリスト化する前処理が必要になります。 - 文字(char)単位 (対象:日本語など単語単位で分かち書きできないことば)
データ形式がリストであれば文字列化等の前処理が必要になります。
"I am an NLPer"を単語単位で2語ずつn-gram(bi-gram)すると次のようになります。

"私は学生です"を文字単位で2文字ずつn-gram(bi-gram)すると次のようになります。
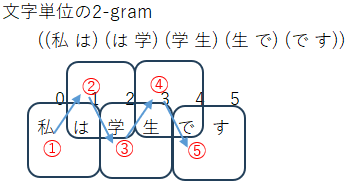
今回のお題は上記のことができればよいわけです。
では、以下にお題の解答プログラムを見てみましょう。
JSコード
JSはArray.sliceのおかげで簡単にできました。(解答サイトのpythonコードをgeminiで変換してもらっただけですが)
/**
* n-gramを作成する関数
* @param {number} n - 区切り数
* @param {string|string[]} data - 文字列または単語の配列
* @returns {any[]} n-gramのリスト
*/
function ngram(n, data) {
const lis = [];
for (let i = 0; i < data.length - n + 1; i++) {
lis.push(data.slice(i, i + n));
}
return lis;
}
// 単語bi-gram:単語単位でN-gram処理する
function ngramByWords(n, text) {
return ngram(n, text.split(" "))
}
// 文字bi-gram:文字単位でN-gram処理する
function ngramByString(n, text) {
return ngram(n, text)
}
const text1 = "I am an NLPer";
const text2 = "私は学生です";
console.log("単語bi-gram:", ngramByWords(2, text1));
console.log("文字bi-gram(J):", ngramByString(2, text2));
console.log("文字bi-gram(E):", ngramByString(2, text1));
// 出力:
// 単語bi-gram: [ [ 'I', 'am' ], [ 'am', 'an' ], [ 'an', 'NLPer' ] ]
// 文字bi-gram(J): [ '私は', 'は学', '学生', '生で', 'です' ]
// 文字bi-gram(E): [
// 'I ', ' a', 'am', 'm ', ' a', 'an',
// 'n ', ' N', 'NL', 'LP', 'Pe', 'er'
// ]
Lipsコード
(1) Lipsのvectorを使った場合
LipsのvectorはJSのArrayで実装されているのでJSコードをほぼ直訳できます。
この後の「(2) 普通のScheme風コード」の改造版になります。
;; n-gramを作成関数
(define (ngram n data)
(let (
(vec (list->vector data)) ; 処理したい文をベクター化する
(n_loop (- (length data) n)) ; 単語数または文字数
)
(let loop (
(i 0) ; ループカウンター
(acc '()) ; 抽出結果
)
(if (> i n_loop)
(reverse acc) ; 結合データを反転させて終わり
(loop
(+ i 1) ; カウントアップ
(cons (vec.slice i (+ i n)) acc) ; slice結果結合 (JSのdata.pushに該当)
)
) ; --- end of (if) ---
) ; -- end of (let loop (i) (acc)) --
) ; - end of (let (vec) (n_loop)) -
)
;; 単語bi-gram
(define (ngram-by-words n text)
;; スペースで区切って単語単位のリストにする
(ngram n (string-split " " text))
)
;; 文字bi-gram
(define (ngram-by-string n text)
;; 文字列をcar/cdr関数で扱えるようにするため文字リスト化する
(ngram n (string->list text))
)
(define text1 "I am an NLPer")
(define text2 "私は学生です")
;; テスト実行
(display "単語bi-gram: ")
(display (ngram-by-words 2 text1))
(newline)
(display "文字bi-gram(J): ")
(display (ngram-by-string 2 text2))
(newline)
(display "文字bi-gram(E): ")
(display (ngram-by-string 2 text1))
(newline)
;; 実行結果
;; 単語bi-gram: ((I am) (am an) (an NLPer))
;; 文字bi-gram(J): ((私 は) (は 学) (学 生) (生 で) (で す))
;; 文字bi-gram(E): ((I ) ( a) (a m) (m ) ( a) (a n) (n ) ( N) (N L) (L P) (P e) (e r))
(2) 普通のScheme風コード
geminiによるJS->Lips変換したコードがベースになっています。
sub-sequenceがコア処理になります。JSのArray.sliceに相当する関数です。
;; n-gramを作成する共通関数
(define (ngram n data)
(let (
(len (length data)) ; リストサイズ
;; (len2 (- len n)) ; 切り出しサイズ(N)
)
;; 切り出しサイズ分ループしてN語(またはN字)単位のリストを積み上げる(consする)
(let loop (
(i 0) ; ループカウンター
(acc '()) ; N-gram塊のリスト(戻り値)
)
(if (> i (- len n)) ;(> 0 1)->(> 1 2)->(> 2 2)...
; ex.(0,1)->(I am),(1,2)->(am an),(2,2)->(an NLPer)
(reverse acc) ; 戻り値(acc)
(loop (+ i 1) (cons (sub-sequence data i (+ i n)) acc)))
)
)
)
;; リストまたは文字列から部分シーケンスを抽出する(JSのArray.slice該当機能)
(define (sub-sequence data start end)
(if (string? data) ;対象がリスト操作か文字列操作かを判定する
(substring data start end) ; trueで文字単位で抽出する
(let loop ( ; falseであればあれば単語単位で抽出する
(curr data)
(i 0)
(res '())
)
(cond
((= i end) (reverse res))
((>= i start) (loop (cdr curr) (+ i 1) (cons (car curr) res)))
(else (loop (cdr curr) (+ i 1) res))
)
) ; -- end of (let loop) --
) ; - end of (if (string)) -
)
;; 単語bi-gram
(define (ngram-by-words n text)
;; スペースで区切って単語単位のリストにする
(ngram n (string-split " " text)))
;; 文字bi-gram
(define (ngram-by-string n text)
;; 文字列をcar/cdr関数で扱えるようにするため文字リスト化する
(ngram n (string->list text))
)
;; テストデータ
(define text1 "I am an NLPer")
(define text2 "私は学生です")
;; テスト出力
(display "単語bi-gram: ")
(display (ngram-by-words 2 text1))
(newline)
(display "文字bi-gram(J): ")
(display (ngram-by-string 2 text2))
(newline)
(display "文字bi-gram(E): ")
(display (ngram-by-string 2 text1))
(newline)
;; 出力結果
;; 単語bi-gram: ((I am) (am an) (an NLPer))
;; 文字bi-gram(J): ((私 は) (は 学) (学 生) (生 で) (で す))
;; 文字bi-gram(E): ((I ) ( a) (a m) (m ) ( a) (a n) (n ) ( N) (N L) (L P) (P e) (e r))
お題 「6.集合」
"paraparaparadise"と"paragraph"に含まれる文字bi-gramの集合を,それぞれ, XとYとして求め,XとYの和集合,積集合,差集合を求めよ.
さらに,'se'というbi-gramがXおよびYに含まれるかどうかを調べよ.
処理手順
pythonの解答例をみるとプログラムは以下の処理ができればよいようです。
-
前処理 - Setを使ってngram結果からダブりを除去する
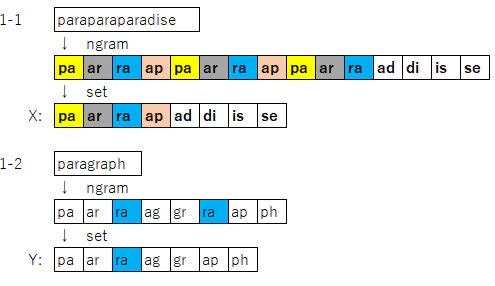
-
XとYの和集合を求める。X ∪ Y = {x | x ∈ X または x ∈ Y}

-
XとYの積集合を求める。X ∩ Y = {x | x ∈ X かつ x ∈ Y}
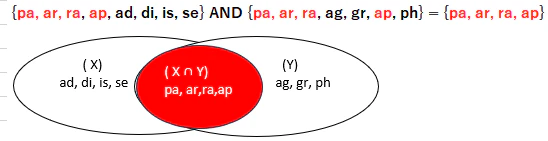
-
XとYの差集合を求める。X - Y = {x | x ∈ X でかつ x ∉ Y}

では以下にコードを見ていきましょう。まず馴染みのJSコードでプログラムフローを把握しましょう。
JSコード
/**
* n-gramを作成する関数
* @param {number} n - 区切り数
* @param {string|string[]} data - 文字列または単語の配列
* @returns {any[]} n-gramのリスト
*/
function ngram(n, data) {
const lis = [];
for (let i = 0; i < data.length - n + 1; i++) {
lis.push(data.slice(i, i + n));
}
return lis;
}
// const text1 = "I am an NLPer";
// const text2 = "私は学生です";
const text1 = "paraparaparadise";
const text2 = "paragraph";
const X = new Set(ngram(2, text1));
const Y = new Set(ngram(2, text2));
console.log("X:", X);
console.log("Y:", Y);
// --- 集合演算の実装 ---
// 和集合 (Union): X | Y
const union = new Set([...X, ...Y]);
console.log("和集合:", union);
// 積集合 (Intersection): X & Y
const intersection = new Set([...X].filter(item => Y.has(item)));
console.log("積集合:", intersection);
// 差集合 (Difference): X - Y
const difference = new Set([...X].filter(item => !Y.has(item)));
console.log("差集合:", difference);
// --- 含有確認 ---
// "se"というbi-gramが含まれるか
console.log("X:", X.has("se"));
console.log("Y:", Y.has("se"));
JSコードのコンソール出力:
X: Set(8) { 'pa', 'ar', 'ra', 'ap', 'ad', 'di', 'is', 'se' }
Y: Set(7) { 'pa', 'ar', 'ra', 'ag', 'gr', 'ap', 'ph' }
和集合: Set(11) {'pa','ar','ra','ap','ad','di','is','se','ag','gr', 'ph'}
積集合: Set(4) { 'pa', 'ar', 'ra', 'ap' }
差集合: Set(4) { 'ad', 'di', 'is', 'se' }
X: true
Y: false
Lips
「05. ngram」ではvectorとリストの混在でしたが、集合処理ではschemeリストによる
set相当の作り込み処理ではパフォーマンスに難があったのでデータをvector化してJSのSet/Arrayを使いました。
;; N-gram抽出関数
(define (ngram n vec)
(let ((len (vector-length vec)) (acc (make-vector)))
(let loop ((i 0))
(if (> i (- len n))
acc ; 結果を返してループ終わり
;; else
(let (
(sub-vec (vector-copy vec i (+ i n)))
)
;; (print sub-vec)
(vector-set! acc i sub-vec)
(loop (+ i 1))
)
) ; ---- (if) -----
) ; ---- (let loop) ----
) ; ---- (let (len)) ----
)
(define (ngram-by-string n text)
(let* (
(data (list->vector (string->list text)))
)
;; ngram処理結果の各要素を文字配列に変換して返す
(vector-map vector->string (ngram n data))
)
)
(define (set-ngram text)
(let* (
(result (ngram-by-string 2 text))
;; setでダブリ要素を除去する
(set-result (new Set result))
)
;; 配列形式にして返す
(Array.from set-result)
)
)
;; --- メイン処理 ---
(let (
(X (set-ngram "paraparaparadise"))
(Y (set-ngram "paragraph"))
)
(display "Set X : ") (print X)
(display "Set Y : ") (print Y)
(let ((union (new Set (vector-append X Y))) )
;; 和集合: JS-Set(11) {'pa','ar','ra','ap','ad','di','is','se','ag','gr','ph'}
(display "(Union X Y) : ") (print (Array.from union))
)
(let ((X-lst (vector->list X)))
;; 積集合: Set(4) { 'pa', 'ar', 'ra', 'ap' }
(display "(Intersection X Y) : ") (print (filter (lambda (x) (Y.includes x)) X-lst))
;; 差集合: Set(4) { 'ad', 'di', 'is', 'se' }
(display "(Difference X Y) : ") (print (filter (lambda (x) (not (Y.includes x))) X-lst))
)
(display "X に 'se' は含まれるか: ") (display (if (X.includes "se") #t #f)) (newline)
(display "Y に 'se' は含まれるか: ") (display (if (Y.includes "se" ) #t #f)) (newline)
)
Lipsコードのコンソール出力:
Set X : #(pa ar ra ap ad di is se)
Set Y : #(pa ar ra ag gr ap ph)
(Union X Y) : #(pa ar ra ap ad di is se ag gr ph)
(Intersection X Y) : (pa ar ra ap)
(Difference X Y) : (ad di is se)
X に 'se' は含まれるか: #t
Y に 'se' は含まれるか: #f
お題 「07. テンプレートによる文生成」
引数x, y, zを受け取り「x時のyはz」という文字列を返す関数を実装せよ.さらに,x=12, y="気温", z=22.4として,実行結果を確認せよ.
この問題はJavaScriptでいうところのテンプレートリテラルについてです。
JSコード
function template(x, y, z) {
return `${x}時の${y}は${z}`;
}
// 実行例
console.log(template(12, '気温', 22.4));
JSコードをLipsに変換すると下のようになります。ほぼAIまかせの変換でOKでした。
LIPSコード
(define (template x y z)
;; ~a は表示用(標準出力)のプレースホルダです
;; (JS) "${x}時の${y}は${z}" → (Lips) "~a時の~aは~a"
(format "~a時の~aは~a" x y z)
)
;; テスト実行
(display (template 12 "気温" 22.4)) ; => 12時の気温は22.4
お題 「08. 暗号文」
与えられた文字列の各文字を,以下の仕様で変換する関数cipherを実装せよ.
・英小文字ならば(219 - 文字コード)の文字に置換
・その他の文字はそのまま出力
・この関数を用い,英語のメッセージを暗号化・復号化せよ.
まずはお題の暗号化方式の内容理解から取り組みました。
この暗号化方式は換字暗号(Substitution Cipher)の特定のバリエーションの一つで
アトバシュ暗号(Atbash cipher)と呼ばれています。
原理は対象文字をある一定量だけシフトして暗号/復号化するというものです。
問題の例ではa~zに対して219を減算することで次のような処理を行っています。
(219 - 'a') → z
(219 - 'b') → y
:
:
(219 - 'y') → b
(219 - 'z') → a
次に解答サイトのpythonコードをJS変換して内容を確認してみます。
JSコード
/**
* 参考: https://qiita.com/moriwo/items/4fde7f725db215ce1a26#07-%E3%83%86%E3%83%B3%E3%83%97%E3%83%AC%E3%83%BC%E3%83%88%E3%81%AB%E3%82%88%E3%82%8B%E6%96%87%E7%94%9F%E6%88%90
* 渡された英文を暗号化します。
* 小文字のみを反転させ、それ以外の文字(大文字、記号、数字)はそのまま保持します。
* * @param {string} s - 対象の文字列
* @returns {string} - 暗号化(または復号)された文字列
*/
const cipher = (s) => {
return s.split('').map(c => {
// 小文字 'a' (97) から 'z' (122) の範囲内かチェック
if (c >= 'a' && c <= 'z') {
// 219 - 文字コード の計算結果を文字に戻す
return String.fromCharCode(219 - c.charCodeAt(0));
}
return c;
}).join('');
};
// テスト
const enc1 = cipher('aBcYz');
console.log("暗号化 AaBcYz =>", enc1);
console.log("複合化 =>", cipher(enc1));
// 出力結果
// 暗号化 AaBcYz => zBxYa
// 複合化 => aBcYz
LIPSコード
JSをベースにLIPS変換しました。
処理概要 : [1.文字列-リスト変換] → [2.文字コードチェック&シフト] → [3.リスト-文字列変換]
(define (cipher s)
(list->string
(map (lambda (c)
(let ((code (char->integer c)))
;; 'a' (97) から 'z' (122) の範囲内か文字コードチェック
(if (and (char>=? c #\a) (char<=? c #\z))
(integer->char (- 219 code)) ; -219して数値-文字コード変換して値を返す
c ; else 暗号化対象外であればそのまま文字を返す
)
)
) (string->list s))
)
)
;; テスト
(display (cipher "AaBbCc"))
(newline) ;; 出力: AzByCx
お題 「09. Typoglycemia」
スペースで区切られた単語列に対して,各単語の先頭と末尾の文字は残し,それ以外の文字の順序をランダムに並び替えるプログラムを作成せよ.
ただし,長さが4以下の単語は並び替えないこととする.
適当な英語の文(例えば"I couldn't believe that I could actually understand what I was reading : the phenomenal power of the human mind .")を与え,その実行結果を確認せよ.
Typoglycemiaとは
私はこの課題でタイポグリセミア(Typoglycemia)という言葉を初めて知りました。
ある長さの英単語で1文字目と最後の文字が正しいとき、その間がごちゃ混ぜ(jumbled)文字列(綴り)であっても読めてしまう誤記状態のことです。(読み辛さには個人差があります。)
例えば下のような文も英語に拒否反応がなければ、読んでしまえるのでしょう。
Aoccdrnig to rscheearch at Cmabrigde ...
According to reaseach at Cambridge…
参考:https://ja.wikipedia.org/wiki/%E3%82%BF%E3%82%A4%E3%83%9D%E3%82%B0%E3%83%AA%E3%82%BB%E3%83%9F%E3%82%A2
では以下に解答サイトのpythonコードを元にしたJS変換コードで内容を理解してLips変換まで行ってみましょう。
JSコード
// export function shuffle_word(word) {
function shuffle_word(word) {
if(word.length <= 4) return word; // 4文字以下であれば何もしない。
const first = word[0]; // 単語の1文字目
const last = word[word.length - 1]; // 単語の最終文字
// 単語文字列から1文字目と最終文字を除いた文字配列を作る
let middle = word.slice(1, -1).split("");
for (let i = middle.length - 1; i > 0; i--) {
// スワップする文字配列の位置を乱数で決定する
const j = Math.floor(Math.random() * (i + 1));
[middle[i], middle[j]] = [middle[j], middle[i]];
}
return first + middle.join("") + last;
}
const text = "I couldn’t believe that I could actually understand what I was reading : the phenomenal power of the human mind .";
// メイン処理
const text_splitted = text.split(" ");
const result = text_splitted.map(word => {
return shuffle_word(word);
});
console.log(result.join(" "));
実行結果:
I cudln’ot bilevee that I colud auclalty udnsteanrd what I was rdanieg : the pnneahoeml peowr of the human mind .
シャッフル処理における文字配置の例
例として"believe"から"eliev"をmiddleに抜き出したときのmiddleの状態遷移を見てみましょう。
シャッフル処理は乱数によってスワップ元と先を決定します。下図のように文字スワップが進められます。
※ このプログラムではシャッフル前と後の比較は行っていないので乱数の発生状況によっては変化がない場合があります。

次にLIPSコードを見てみましょう。LIPSは組み込みのshuffleを提供しています。
Lipsソース(lips.js)にはフィッシャー–イェーツ・シャッフルというアルゴリズム名が書かれています。
LIPSコード
;; 単語をシャッフルする関数
(define (shuffle-word word)
(let ((len (string-length word)))
(if (<= len 4)
word ; 4文字以下であればwordをそのまま返す
(let* ( ; else
;; (chars (string->list word))
(first (string-ref word 0)) ; 先頭文字 ; (first (car chars))
(last (string-ref word (- len 1))) ; 最終文字 ;(last (car (reverse chars)))
;; 中間の文字を抜き出してリスト化
(middle (substring word 1 (- len 1)))
;; 組み込みの shuffle 関数を使用
(shuffled-middle (shuffle (string->list middle)))
)
;; 退避しておいた先頭文字と最終文字をシャッフル結果に結合する
(list->string (cons first (append shuffled-middle (list last))))
) ; --- end of (let*) ---
) ; -- end of (if) --
) ; - end of (let ((len))) -
)
;; JSコードとLipsのshuffleのパフォーマンス比較 - ソースの内容は同じなのでパフォーマンスの差はない - Lipsの起動時が重たいだけ
;; (define js-shuffle (require "./shuffle.js")) ; JSコードテスト
;; メインテキスト
(define text "I couldn’t believe that I could actually understand what I was reading : the phenomenal power of the human mind .")
;; メイン処理
;; 1. 空白で分割 (split)
;; 2. 各単語に shuffle-word を適用 (map)
;; 3. 空白で結合 (join)
(let* (
(words (string-split " " text))
(result (map shuffle-word words))
;; (result (map (lambda (word) (js-shuffle.shuffle_word word)) words)) ; JSテスト
)
(print (string-join " " result))
)
参考
終わりに
年が明けて2026年がはじまりました。9回目のqiita投稿になりました。
本年もご指導ご鞭撻のほどよろしくお願いいたします。🙇