警告
この記事はすでにサポートが打ち切られているChainer v1の最終リリース(v1.24.0)向けに書かれた笑えないレベルで古すぎる記事です。
2017年12月時点での最新安定版のChainer v3向けに書かれた記事がこちらにありますので、どうしてもv1に入門する必要があるという超特殊事情を抱えた方以外は、今すぐそちらに飛んでください。
Go!! -> Chainer v3 ビギナー向けチュートリアル
第1回 Chainer Beginner's Hands-onを大手町にあるPreferred Networksオフィスの多目的室にて開催いたしました。この記事は、このハンズオンで行った内容を記事化したものです。
ハンズオン当日に使用した資料等は以下のGithubリポジトリにまとめられています。
当日は、さくらインターネット様より4つのPascal TITAN Xが搭載されたGPUサーバを20台(合計80GPUs!)、無償にてお借りし、参加者の皆様に使って頂く形でハンズオンを行いました。この場をお借りしてさくらインターネット様に感謝申し上げます。さくら高火力コンピューティングでは、近日、時間単位でのGPUサーバのレンタルサービスが開始されるとのことですので、GPU環境の導入をご検討の方は、ぜひチェックしてみてください。
ハンズオン当日はまず、このお借りしたさくら高火力の各ノードにsshログインしていただき、NVIDIA CUDAをインストールするところから始めましたが、この記事ではその部分はスキップし、Chainerの使い方に関する部分からまとめていきます。
環境構築の方法については、以下の資料にまとめてありますので、ご参照ください。
これは一部を除けばUbuntu 14.04で動いているNVIDIA GPUが搭載されたサーバに対する環境構築の手順としてお使い頂けます。
それでは本題に入っていきます。以下は、Ubuntu14.04に標準でインストールされているPython 3.4を前提として書かれたチュートリアルになっています。あらかじめ上記資料のP.9、P.11あたりを参考に、関連ライブラリとChainer自体のインストールは済ませてください。以下のコード部分とそれに続く出力結果は、Jupyter notebook上で実行した場合を想定したものとなっています。
学習ループを書いてみよう
ここでは、
- データセットからデータを取り出す
- モデルに入力する
- Optimizerを使ってモデルのパラメータを更新して学習を行うループを回す
ことをやってみます。これらを通して、Trainerを使わない学習ループの書き方が体験できます。
1. データセットの準備
ここでは、Chainerが用意しているMNISTデータセットを使うための便利なメソッドを利用します。これを使うと、データのダウンロードから、一つ一つのデータを取り出せるようにするところまでが隠蔽されます。
from chainer.datasets import mnist
# データセットがダウンロード済みでなければ、ダウンロードも行う
train, test = mnist.get_mnist(withlabel=True, ndim=1)
# matplotlibを使ったグラフ描画結果がnotebook内に表示されるようにします。
%matplotlib inline
import matplotlib.pyplot as plt
# データの例示
x, t = train[0]
plt.imshow(x.reshape(28, 28), cmap='gray')
plt.show()
print('label:', t)
出力結果:
Downloading from http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz...
Downloading from http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz...
Downloading from http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz...
Downloading from http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz...
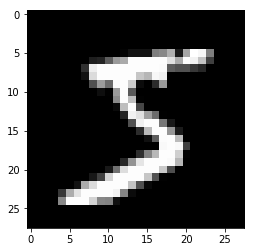
label: 5
2. Iteratorの作成
データセットから決まった数のデータを取得し、それらを束ねてミニバッチを作成して返してくれるIteratorを作成しましょう。これをこの後の学習ループの中で使用していきます。イテレータは、next()メソッドで新しいミニバッチを返してくれます。内部ではデータセットを何周なめたか(epoch)、現在のイテレーションが新しいepochの最初のイテレーションか、を管理するプロパティ(is_new_epoch)などを持っています。
from chainer import iterators
batchsize = 128
train_iter = iterators.SerialIterator(train, batchsize)
test_iter = iterators.SerialIterator(test, batchsize,
repeat=False, shuffle=False)
Iteratorについて
- Chainerがいくつか用意しているIteratorの一種である
SerialIteratorは、データセットの中のデータを順番に取り出してくる最もシンプルなIteratorです。 - 引数にデータセットオブジェクトと、バッチサイズを取ります。
- このとき渡したデータセットオブジェクトから、何周も何周もデータを繰り返し読み出す必要がある場合は
repeat引数をTrueとし、1周が終わったらそれ以上データを取り出したくない場合はこれをFalseとします。デフォルトでは、Trueになっています。 -
shuffle引数にTrueを渡すと、データセットから取り出されてくるデータの順番をエポックごとにランダムに変更します。
ここで、batchsize = 128としているので、ここで作成した訓練データ用のIteratorであるtrain_iterおよびテストデータ用のIteratorであるtest_iterは、それぞれ128枚の数字画像データを一括りにして返すIteratorということになります。1
3. モデルの定義
ここでは、シンプルな三層パーセプトロンを定義します。これは全結合層のみからなるネットワークです。中間層のユニット数は適当に100とし、出力は10クラスなので10とします。ここで用いるMNISTデータセットは10種のラベルを持つためです。では、モデルを定義するために必要なLink, Function, そしてChainについて、簡単にここで説明を行います。
LinkとFunction
- Chainerでは、ニューラルネットワークの各層を、
LinkとFunctionに区別します。 Linkは、パラメータを持つ関数です。Functionは、パラメータを持たない関数です。- これらを組み合わせてモデルを記述します。
- パラメータを持つ層は、
chainer.linksモジュール以下にたくさん用意されています。 - パラメータを持たない層は、
chainer.functionsモジュール以下にたくさん用意されています。 - これらを簡単に使うために、
import chainer.links as L
import chainer.functions as F
と別名を与えて、L.Convolution2D(...)やF.relu(...)のように用いる慣習があります。
Chain
- Chainは、パラメータを持つ層=**
Linkをまとめておくためのクラス**です。 - パラメータを持つということは、基本的にモデルの学習の際にそれらを更新していく必要があるということです(例外はあります)。
- そこで、学習中に
Optimizerが更新すべき全てのパラメータを簡単に取得できるように、Chainで一箇所にまとめておきます。
Chainを継承して定義されるモデル
- モデルは
Chainクラスを継承したクラスとして定義されることが多いです。 - その場合、モデルを表すクラスのコンストラクタで、親クラスのコンストラクタにキーワード引数の形で登録したい層の名前と、オブジェクトを渡しておくと、自動的に
Optimizerから見つけられる形で保持しておいてくれます。 - これは、別の場所で
add_linkメソッドを使っても行うことができます。 - また、関数呼び出しのようにしてモデルに
()アクセサでデータを渡せるように、__call__メソッドを定義して、その中にforward処理を記述すると便利です。
GPUで実行するには
-
Chainクラスはto_gpuメソッドを持ち、この引数にGPU IDを指定すると、指定したGPU IDのメモリ上にモデルの全パラメータを転送します。 - これはモデル内部でのforward/backward計算をその指定したGPU上で行うために必要になります。
- これを行わない場合、それらの処理はCPU上で行われます。
それでは、モデルを定義していきます。まずは乱数シードを固定して、本記事とほぼ同様の結果が再現できるようにしておきましょう。(より厳密に計算結果の再現性を保証したい場合は、deterministicというオプションについて知る必要があります。こちらの記事が役に立ちます:ChainerでGPUを使うと毎回結果が変わる理由と対策。
import numpy
numpy.random.seed(0)
import chainer
if chainer.cuda.available:
chainer.cuda.cupy.random.seed(0)
それでは実際にモデルの定義を行い、オブジェクトを作って、GPUに送信してみましょう。
import chainer
import chainer.links as L
import chainer.functions as F
class MLP(chainer.Chain):
def __init__(self, n_mid_units=100, n_out=10):
# パラメータを持つ層の登録
super(MLP, self).__init__(
l1=L.Linear(None, n_mid_units),
l2=L.Linear(n_mid_units, n_mid_units),
l3=L.Linear(n_mid_units, n_out),
)
def __call__(self, x):
# データを受け取った際のforward計算を書く
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
return self.l3(h2)
gpu_id = 0
model = MLP()
model.to_gpu(gpu_id) # CPUで処理を行いたい場合は、この行をコメントアウトしてください。
NOTE
ここで、L.Linearクラスは全結合層を意味します。コンストラクタの第一引数にNoneを渡すと、実行時に、データがその層に入力された瞬間、必要な数の入力側ユニット数を自動的に計算し、(n_input) $\times$ n_mid_unitsの大きさの行列を作成し、パラメータとして保持します。これは後々、畳み込み層を全結合層の前に配置する際などに便利な機能です。
前述のように、Linkはパラメータを持つので、そのパラメータの値にアクセスすることができます。例えば、上のモデルMLPはl1という名前の全結合層が登録されています。この全結合相はWとbという2つのパラメータを持ちます。これらは外からアクセスすることができます。例えばbへアクセスするには、以下のようにします。
print('1つ目の全結合相のバイアスパラメータの形は、', model.l1.b.shape)
print('初期化直後のその値は、', model.l1.b.data)
出力結果
1つ目の全結合相のバイアスパラメータの形は、 (100,)
初期化直後のその値は、 [ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
ここで、model.l1.Wにアクセスしようとすると、以下のようなエラーが出ます。
AttributeError: 'Linear' object has no attribute 'W'
これは、上記モデルの定義ではLinearリンクのコンストラクタの第一引数にNoneを渡したため、実行時まで行列Wは確保されないからです。存在してはいないが、存在する予定であることはLinearオブジェクトの内部で把握されています。
4. 最適化手法の選択
Chainerは多くの最適化手法を提供しています。chainer.optimizersモジュール以下にそれらはあります。ここでは最もシンプルな勾配降下法の手法であるoptimizers.SGDを用います。Optimizerのオブジェクトには、setupメソッドを使ってモデル(Chainオブジェクト)を渡します。こうすることでOptimizerは、自身が更新すべきモデル内のパラメータを自動的にたどってくれます。
他にもいろいろな最適化手法が手軽に試せるので、色々と試してみて結果の変化を見てみてください。例えば、下のchainer.optimizers.SGDのうちSGDの部分をMomentumSGD, RMSprop, Adamなどに変えて、結果の違いを見てみると良いでしょう。
from chainer import optimizers
optimizer = optimizers.SGD(lr=0.01)
optimizer.setup(model)
NOTE
今回はSGDのコンストラクタのlrという引数に $0.01$ を与えました。この値は学習率として知られ、モデルをうまく訓練して良いパフォーマンスを発揮させるために調整する必要がある重要なハイパーパラメータとして知られています。
5. 学習ループ
いよいよ学習ループです。今回は分類問題なので、softmax_cross_entropyというロス関数を使って最小化すべきロスの値を計算します。
Chainerでは、FunctionやLinkを使ってモデルのforward計算を行い、結果と正解ラベルをFunctionの一種でありスカラ値を返すロス関数に渡してやり、ロスの計算を行うと、それは他のLinkやFunctionと同じく、Variableオブジェクトを返します。Variableオブジェクトはこれまでの計算過程をあとから逆向きに辿り返すための参照を保持しているため、Variable.backward()メソッドを呼ぶだけで、自動的にそこからこれまでの計算過程を遡って、途中で施された計算に用いられたパラメータの勾配を計算してくれます。
つまり、学習ループの1回の中で行うのは、以下の4項目です。
- モデルにデータを渡して出力
yを得る -
yと正解ラベルtを使って、最小化すべきロスの値をsoftmax_cross_entropy関数で計算する -
softmax_cross_entropy関数の出力Variableのbackwardメソッドを呼んで、モデル内部のパラメータにgradプロパティ(これがパラメータ更新に使われる勾配)を持たせる - Optimizerの
updateメソッドを呼び、3.で計算したgradを使って全パラメータを更新する
以上です。分類問題ではなく、例えば簡単な回帰問題に取り組むような場合、F.softmax_cross_entropyの代わりにF.mean_squared_errorなどを用いることもできます。他にも、いろいろな問題設定に対応するために様々なロス関数がChainerには用意されています。こちらからその一覧を見ることができます:Loss functions。
では、さっそく訓練ループを書いていきます。
import numpy as np
from chainer.dataset import concat_examples
from chainer.cuda import to_cpu
max_epoch = 10
while train_iter.epoch < max_epoch:
# ---------- 学習の1イテレーション ----------
train_batch = train_iter.next()
x, t = concat_examples(train_batch, gpu_id)
# 予測値の計算
y = model(x)
# ロスの計算
loss = F.softmax_cross_entropy(y, t)
# 勾配の計算
model.cleargrads()
loss.backward()
# パラメータの更新
optimizer.update()
# --------------- ここまで ----------------
# 1エポック終了ごとにValidationデータに対する予測精度を測って、
# モデルの汎化性能が向上していることをチェックしよう
if train_iter.is_new_epoch: # 1 epochが終わったら
# ロスの表示
print('epoch:{:02d} train_loss:{:.04f} '.format(
train_iter.epoch, float(to_cpu(loss.data))), end='')
test_losses = []
test_accuracies = []
while True:
test_batch = test_iter.next()
x_test, t_test = concat_examples(test_batch, gpu_id)
# テストデータをforward
y_test = model(x_test)
# ロスを計算
loss_test = F.softmax_cross_entropy(y_test, t_test)
test_losses.append(to_cpu(loss_test.data))
# 精度を計算
accuracy = F.accuracy(y_test, t_test)
accuracy.to_cpu()
test_accuracies.append(accuracy.data)
if test_iter.is_new_epoch:
test_iter.epoch = 0
test_iter.current_position = 0
test_iter.is_new_epoch = False
test_iter._pushed_position = None
break
print('val_loss:{:.04f} val_accuracy:{:.04f}'.format(
np.mean(test_losses), np.mean(test_accuracies)))
出力結果
epoch:01 train_loss:0.7828 val_loss:0.8276 val_accuracy:0.8167
epoch:02 train_loss:0.3672 val_loss:0.4564 val_accuracy:0.8826
epoch:03 train_loss:0.3069 val_loss:0.3702 val_accuracy:0.8976
epoch:04 train_loss:0.3333 val_loss:0.3307 val_accuracy:0.9078
epoch:05 train_loss:0.3308 val_loss:0.3079 val_accuracy:0.9129
epoch:06 train_loss:0.3210 val_loss:0.2909 val_accuracy:0.9162
epoch:07 train_loss:0.2977 val_loss:0.2781 val_accuracy:0.9213
epoch:08 train_loss:0.2760 val_loss:0.2693 val_accuracy:0.9232
epoch:09 train_loss:0.1762 val_loss:0.2566 val_accuracy:0.9263
epoch:10 train_loss:0.2444 val_loss:0.2479 val_accuracy:0.9284
val_accuracyに着目してみると、最終的に10エポックで $0.9286$ になっています。おおよそ93%程度の精度で手書きの数字が分類できるようになりました。
6. 学習済みモデルを保存する
Chainerには2つのシリアライズ機能が用意されています。一つはHDF5形式でモデルを保存するもので、もう一つはNumPyのNPZ形式でモデルを保存するものです。今回は、追加ライブラリのインストールが必要なHDF5ではなく、NumPy標準機能で提供されているシリアライズ機能を利用したNPZ形式でのモデルの保存を行います。
from chainer import serializers
serializers.save_npz('my_mnist.model', model)
# ちゃんと保存されていることを確認
%ls -la my_mnist.model
* 最後の行はJupyter notebook上でなければ動作しません。
出力結果
-rw-rw-r-- 1 ubuntu ubuntu 333853 Mar 29 16:51 my_mnist.model
7. 保存したモデルを読み込んで推論する
今しがた保存したNPZファイルを読み込んで、テストデータに対するラベルの予測をネットワークに行わせてみます。NPZファイルにはパラメータが保存されているので、forward計算のロジックを持つモデルのオブジェクトをまず作成し、そのパラメータを先程保存したNPZが持つ値で上書きすることで学習直後のモデルの状態を復元します。
# まず同じモデルのオブジェクトを作る
infer_model = MLP()
# そのオブジェクトに保存済みパラメータをロードする
serializers.load_npz('my_mnist.model', infer_model)
# GPU上で計算させるために、モデルをGPUに送る
infer_model.to_gpu(gpu_id)
# テストデータ
x, t = test[0]
plt.imshow(x.reshape(28, 28), cmap='gray')
plt.show()
print('label:', t)
出力結果

label: 7
これからモデルに推論させることになるテストデータを表示してみました。以下がこの画像に対し推論を行わせる例になります。
from chainer.cuda import to_gpu
# ミニバッチの形にする(ここではサイズ1のミニバッチにするが、
# 複数まとめてサイズnのミニバッチにしてまとめて推論することもできる)
print(x.shape, end=' -> ')
x = x[None, ...]
print(x.shape)
# GPU上で計算させるため、データもGPU上に送る
x = to_gpu(x, 0) # CPU上で行う場合は、ここをコメントアウトしてください。
# モデルのforward関数に渡す
y = infer_model(x)
# Variable形式で出てくるので中身を取り出す
y = y.data
# 結果をCPUに送る
y = to_cpu(y) # CPU上で行う場合は、ここをコメントアウトしてください。
# 最大値のインデックスを見る
pred_label = y.argmax(axis=1)
print('predicted label:', pred_label[0])
出力結果
(784,) -> (1, 784)
predicted label: 7
Trainerを使ってみよう
Trainerを使うと学習ループを陽に書く必要がなくなります。またいろいろな便利なExtentionを使うことで可視化やログの保存などが楽になります。
1. データセットの準備
from chainer.datasets import mnist
train, test = mnist.get_mnist()
2. Iteratorの準備
from chainer import iterators
batchsize = 128
train_iter = iterators.SerialIterator(train, batchsize)
test_iter = iterators.SerialIterator(test, batchsize, False, False)
3. Modelの準備
ここでは、先程と同じモデルを再度用います。
import chainer
import chainer.links as L
import chainer.functions as F
class MLP(chainer.Chain):
def __init__(self, n_mid_units=100, n_out=10):
super(MLP, self).__init__(
l1=L.Linear(None, n_mid_units),
l2=L.Linear(n_mid_units, n_mid_units),
l3=L.Linear(n_mid_units, n_out),
)
def __call__(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
return self.l3(h2)
gpu_id = 0
model = MLP()
model.to_gpu(gpu_id) # CPUを使用する場合は、ここをコメントアウトしてください。
4. Updaterの準備
Trainerは学習に必要な全てのものをひとまとめにするクラスです。Trainerと、それが内部に持つユーティリティクラスやモデル、データセットクラスなどは、以下のような関係になっています。
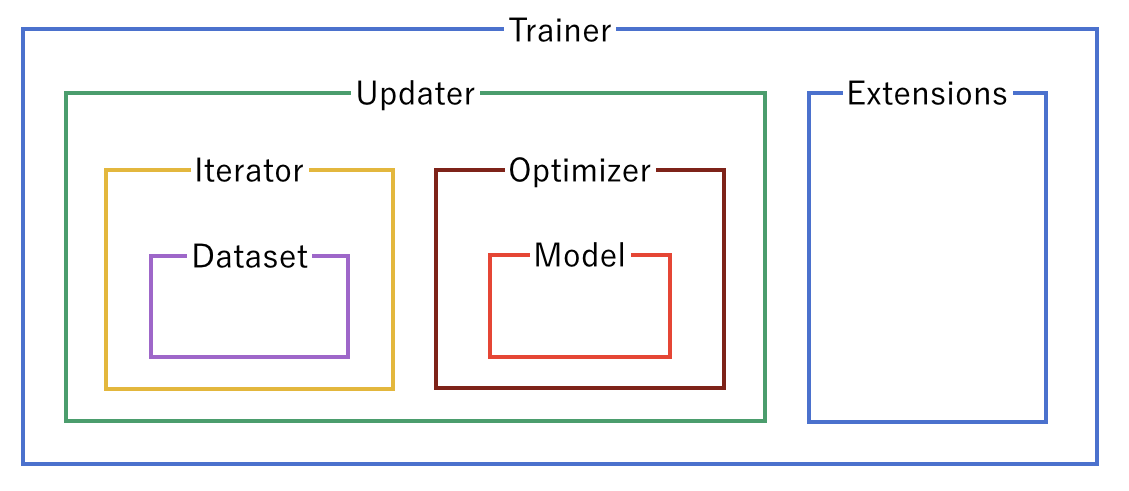
Trainerオブジェクトを作成するときに渡すのは基本的にUpdaterだけですが、Updaterは中にIteratorとOptimizerを持っています。Iteratorからはデータセットにアクセスすることができ、Optimizerは中でモデルへの参照を保持しているので、モデルのパラメータを更新することができます。つまり、Updaterが内部で
- データセットからデータを取り出し(Iterator)
- モデルに渡してロスを計算し(Model = Optimizer.target)
- Optimizerを使ってモデルのパラメータを更新する(Optimizer)
という一連の学習の主要部分を行うことができるということです。では、Updaterオブジェクトを作成してみます。
from chainer import optimizers
from chainer import training
max_epoch = 10
gpu_id = 0
# モデルをClassifierで包んで、ロスの計算などをモデルに含める
model = L.Classifier(model)
model.to_gpu(gpu_id) # CPUを使用する場合は、この行をコメントアウトして下さい。
# 最適化手法の選択
optimizer = optimizers.SGD()
optimizer.setup(model)
# UpdaterにIteratorとOptimizerを渡す
updater = training.StandardUpdater(train_iter, optimizer, device=gpu_id)
NOTE
ここで、上で定義したモデルのオブジェクトをL.Classifierに渡して、新しいChainにしています。L.ClassifierはChainを継承したクラスで、渡されたChainをpredictorというプロパティに保存します。()アクセサでデータとラベルを渡すと、中で__call__が実行され、まず渡されたデータの方をpredictorに通し、その出力yと、データと一緒に__call__に渡されていたラベルを、コンストラクタのlossfun引数で指定されたロス関数に渡して、その出力Variableを返します。lossfunはデフォルトでsoftmax_cross_entropyに指定されています。
StandardUpdaterは前述のようなUpdaterの担当する処理を遂行するための最もシンプルなクラスです。この他にも複数のGPUを用いるためのParallelUpdaterなどが用意されています。
5. Trainerの設定
最後に、Trainerの設定を行います。Trainerのオブジェクトを作成する際に必須となるのは、先程作成したUpdaterオブジェクトだけですが、二番目の引数stop_triggerに学習をどのタイミングで終了するかを表す(長さ, 単位)という形のタプルを与えると、指定したタイミングで学習を自動的に終了することができます。長さには任意の整数、単位には'epoch'か'iteration'のいずれかの文字列を指定できます。stop_triggerを指定しない場合、学習は自動的には止まりません。
# TrainerにUpdaterを渡す
trainer = training.Trainer(updater, (max_epoch, 'epoch'),
out='mnist_result')
out引数では、この次に説明するExtensionを使って、ログファイルやロスの変化の過程を描画したグラフの画像ファイルなどを保存するディレクトリを指定しています。
6. TrainerにExtensionを追加する
Trainerを使う利点として、
- ログを自動的にファイルに保存(
LogReport) - ターミナルに定期的にロスなどの情報を表示(
PrintReport) - ロスを定期的にグラフで可視化して画像として保存(
PlotReport) - 定期的にモデルやOptimizerの状態を自動シリアライズ(
snapshot/snapshot_object) - 学習の進捗を示すプログレスバーを表示(
ProgressBar) - モデルの構造をGraphvizのdot形式で保存(
dump_graph)
などなどの様々な便利な機能を簡単に利用することができる点があります。これらの機能を利用するには、Trainerオブジェクトに対してextendメソッドを使って追加したいExtensionのオブジェクトを渡してやるだけです。では実際に幾つかのExtensionを追加してみましょう。
from chainer.training import extensions
trainer.extend(extensions.LogReport())
trainer.extend(extensions.snapshot(filename='snapshot_epoch-{.updater.epoch}'))
trainer.extend(extensions.snapshot_object(model.predictor, filename='model_epoch-{.updater.epoch}'))
trainer.extend(extensions.Evaluator(test_iter, model, device=gpu_id))
trainer.extend(extensions.PrintReport(['epoch', 'main/loss', 'main/accuracy', 'validation/main/loss', 'validation/main/accuracy', 'elapsed_time']))
trainer.extend(extensions.PlotReport(['main/loss', 'validation/main/loss'], x_key='epoch', file_name='loss.png'))
trainer.extend(extensions.PlotReport(['main/accuracy', 'validation/main/accuracy'], x_key='epoch', file_name='accuracy.png'))
trainer.extend(extensions.dump_graph('main/loss'))
LogReport
epochやiterationごとのloss, accuracyなどを自動的に集計し、Trainerのout引数で指定した出力ディレクトリにlogというファイル名で保存します。
snapshot
Trainerのout引数で指定した出力ディレクトリにTrainerオブジェクトを指定されたタイミング(デフォルトでは1エポックごと)に保存します。Trainerオブジェクトは上述のようにUpdaterを持っており、この中にOptimizerとモデルが保持されているため、このExtensionでスナップショットをとっておけば、学習の復帰や学習済みモデルを使った推論などが学習終了後にも可能になります。
snapshot_object
しかし、Trainerごと保存した場合、しばしば中身のモデルだけ取り出すのが面倒な場合があります。そこで、snapshot_objectを使って指定したオブジェクト(ここではClassifierで包まれたモデル)だけを、Trainerとは別に保存するようにします。Classifierは第1引数に渡されたChainオブジェクトを自身のpredictorというプロパティとして保持してロスの計算を行うChainであり、Classifierはそもそもモデル以外にパラメータを持たないので、ここでは後々学習済みモデルを推論に使うことを見越してmodel.predictorを保存対象として指定しています。
dump_graph
指定されたVariableオブジェクトから辿れる計算グラフをGraphvizのdot形式で保存します。保存先はTrainerのout引数で指定した出力ディレクトリです。
Evaluator
評価用のデータセットのIteratorと、学習に使うモデルのオブジェクトを渡しておくことで、学習中のモデルを指定されたタイミングで評価用データセットを用いて評価します。
PrintReport
Reporterによって集計された値を標準出力に出力します。このときどの値を出力するかを、リストの形で与えます。
PlotReport
引数のリストで指定された値の変遷をmatplotlibライブラリを使ってグラフに描画し、出力ディレクトリにfile_name引数で指定されたファイル名で画像として保存します。
これらのExtensionは、ここで紹介した以外にも、例えばtriggerによって個別に作動するタイミングを指定できるなどのいくつかのオプションを持っており、より柔軟に組み合わせることができます。詳しくは公式のドキュメントを見てください:Trainer extensions。
7. 学習を開始する
学習を開始するには、Trainerオブジェクトのメソッドrunを呼ぶだけです。
trainer.run()
出力結果
epoch main/loss main/accuracy validation/main/loss validation/main/accuracy elapsed_time
1 1.6035 0.61194 0.797731 0.833564 2.98546
2 0.595589 0.856793 0.452023 0.88123 5.74528
3 0.4241 0.885944 0.368583 0.897943 8.34872
4 0.367762 0.897152 0.33103 0.905756 11.4449
5 0.336136 0.904967 0.309321 0.912282 14.2671
6 0.314134 0.910464 0.291451 0.914557 17.0762
7 0.297581 0.914879 0.276472 0.920985 19.8298
8 0.283512 0.918753 0.265166 0.923655 23.2033
9 0.271917 0.922125 0.254976 0.926523 26.1452
10 0.260754 0.925123 0.247672 0.927413 29.3136
初めに取り組んだ学習ループを自分で書いた場合よりもより短いコードで、リッチなログ情報とともに、下記で表示してみるようなグラフなども作りつつ、同様の結果を得ることができました。
さっそく保存されているロスのグラフを確認してみましょう。
from IPython.display import Image
Image(filename='mnist_result/loss.png')
* この部分はJupyter notebook上で実行しないと以下の結果は得られません。
出力結果
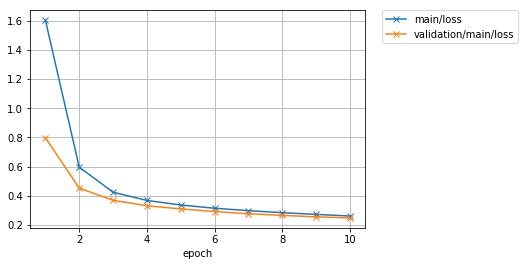
精度のグラフも見てみましょう。
Image(filename='mnist_result/accuracy.png')
出力結果
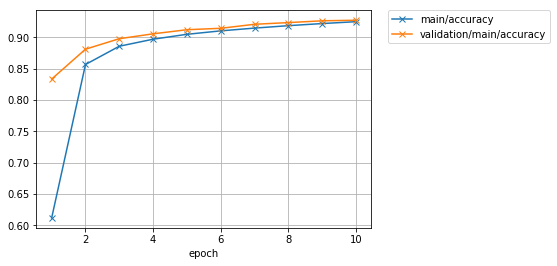
もう少し学習を続ければ、まだ多少精度の向上が図れそうな雰囲気がありますね。
ついでに、dump_graphというExtensionが出力した計算グラフを、Graphvizを使って画像化して見てみましょう。
%%bash
dot -Tpng mnist_result/cg.dot -o mnist_result/cg.png
* こちらではJupyter notebook上でbashコマンドを使うCell magicを使用しています。2行目のコマンド自体は通常のシェルコマンドです。
Image(filename='mnist_result/cg.png')
出力結果
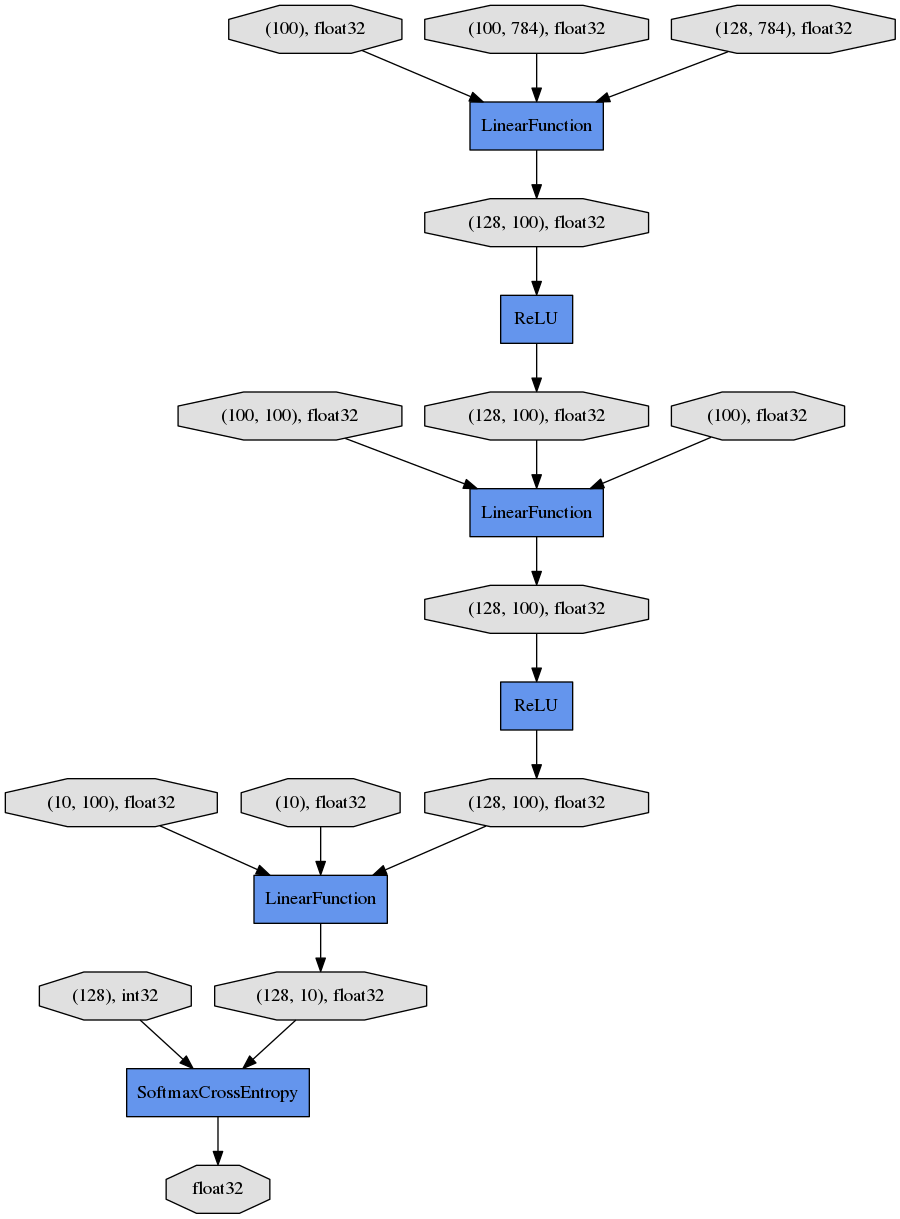
上から下へ向かって、データやパラメータがどのようなFunctionに渡されて計算が行われ、ロスを表すVariableが出力されたかが分かります。
8. 学習済みモデルで推論する
import numpy as np
from chainer import serializers
from chainer.cuda import to_gpu
from chainer.cuda import to_cpu
model = MLP()
serializers.load_npz('mnist_result/model_epoch-10', model)
model.to_gpu(gpu_id)
%matplotlib inline
import matplotlib.pyplot as plt
x, t = test[0]
plt.imshow(x.reshape(28, 28), cmap='gray')
plt.show()
print('label:', t)
x = to_gpu(x[None, ...])
y = model(x)
y = to_cpu(y.data)
print('predicted_label:', y.argmax(axis=1)[0])
出力結果
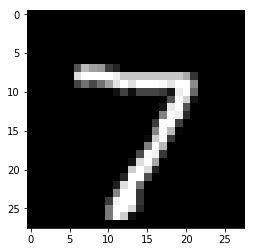
label: 7
predicted_label: 7
無事正解できました。
新しいネットワークを書いてみよう
ここでは、MNISTデータセットではなくCIFAR10という32x32サイズの小さなカラー画像に10クラスのいずれかのラベルがついたデータセットを用いて、いろいろなモデルを自分で書いて試行錯誤する流れを体験してみます。
| airplane | automobile | bird | cat | deer | dog | frog | horse | ship | truck |
|---|---|---|---|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
1. モデルの定義
モデルは、Chainクラスを継承して定義します。ここでは、さきほど試した全結合層だけからなるネットワークではなく、畳込み層を持つネットワークを定義してみます。このモデルは3つの畳み込み層を持ち、2つの全結合層がそのあとに続いています。
モデルの定義は主に2つのメソッドの定義によって行います。
-
__init__コンストラクタでモデルを構成するレイヤーを定義する- この際、親クラス(
Chain)のコンストラクタにsuperを用いてキーワード引数としてモデルを構成するLinkオブジェクトを渡すことでOptimizerから捕捉可能な最適化対象のパラメータを持つレイヤをモデルに追加することができます。
- この際、親クラス(
- データを受け取る
()アクセサで呼ばれる__call__メソッドに、Forward計算を記述する
import chainer
import chainer.functions as F
import chainer.links as L
class MyModel(chainer.Chain):
def __init__(self, n_out):
super(MyModel, self).__init__(
conv1=L.Convolution2D(None, 32, 3, 3, 1),
conv2=L.Convolution2D(32, 64, 3, 3, 1),
conv3=L.Convolution2D(64, 128, 3, 3, 1),
fc4=L.Linear(None, 1000),
fc5=L.Linear(1000, n_out)
)
def __call__(self, x):
h = F.relu(self.conv1(x))
h = F.relu(self.conv2(h))
h = F.relu(self.conv3(h))
h = F.relu(self.fc4(h))
h = self.fc5(h)
return h
2. 学習
ここで、あとから別のモデルも簡単に同じ設定で訓練できるよう、train関数を定義しておきます。これは、
- モデルのオブジェクト
- バッチサイズ
- 使用するGPU ID
- 学習を終了するエポック数
- データセットオブジェクト
を渡すと、内部でTrainerを用いて渡されたデータセットを使ってモデルを訓練し、学習が終了した状態のモデルを返してくれる関数です。
このtrain関数を用いて、上で定義したMyModelモデルを訓練してみます。
from chainer.datasets import cifar
from chainer import iterators
from chainer import optimizers
from chainer import training
from chainer.training import extensions
def train(model_object, batchsize=64, gpu_id=0, max_epoch=20, train_dataset=None, test_dataset=None):
# 1. Dataset
if train_dataset is None and test_dataset is None:
train, test = cifar.get_cifar10()
else:
train, test = train_dataset, test_dataset
# 2. Iterator
train_iter = iterators.SerialIterator(train, batchsize)
test_iter = iterators.SerialIterator(test, batchsize, False, False)
# 3. Model
model = L.Classifier(model_object)
if gpu_id >= 0:
model.to_gpu(gpu_id)
# 4. Optimizer
optimizer = optimizers.Adam()
optimizer.setup(model)
# 5. Updater
updater = training.StandardUpdater(train_iter, optimizer, device=gpu_id)
# 6. Trainer
trainer = training.Trainer(updater, (max_epoch, 'epoch'), out='{}_cifar10_result'.format(model_object.__class__.__name__))
# 7. Evaluator
class TestModeEvaluator(extensions.Evaluator):
def evaluate(self):
model = self.get_target('main')
model.train = False
ret = super(TestModeEvaluator, self).evaluate()
model.train = True
return ret
trainer.extend(extensions.LogReport())
trainer.extend(TestModeEvaluator(test_iter, model, device=gpu_id))
trainer.extend(extensions.PrintReport(['epoch', 'main/loss', 'main/accuracy', 'validation/main/loss', 'validation/main/accuracy', 'elapsed_time']))
trainer.extend(extensions.PlotReport(['main/loss', 'validation/main/loss'], x_key='epoch', file_name='loss.png'))
trainer.extend(extensions.PlotReport(['main/accuracy', 'validation/main/accuracy'], x_key='epoch', file_name='accuracy.png'))
trainer.run()
del trainer
return model
model = train(MyModel(10), gpu_id=0) # CPUで実行する場合は、`gpu_id=-1`を指定して下さい。
出力結果
epoch main/loss main/accuracy validation/main/loss validation/main/accuracy elapsed_time
1 1.53309 0.444293 1.29774 0.52707 5.2449
2 1.21681 0.56264 1.18395 0.573746 10.6833
3 1.06828 0.617358 1.10173 0.609773 16.0644
4 0.941792 0.662132 1.0695 0.622611 21.2535
5 0.832165 0.703345 1.0665 0.624104 26.4523
6 0.729036 0.740257 1.0577 0.64371 31.6299
7 0.630143 0.774208 1.07577 0.63953 36.798
8 0.520787 0.815541 1.15054 0.639431 42.1951
9 0.429535 0.849085 1.23832 0.6459 47.3631
10 0.334665 0.882842 1.3528 0.633061 52.5524
11 0.266092 0.90549 1.44239 0.635251 57.7396
12 0.198057 0.932638 1.6249 0.6249 62.9918
13 0.161151 0.944613 1.76964 0.637241 68.2177
14 0.138705 0.952145 1.98031 0.619725 73.4226
15 0.122419 0.957807 2.03002 0.623806 78.6411
16 0.109989 0.962148 2.08948 0.62281 84.3362
17 0.105851 0.963675 2.31344 0.617237 89.5656
18 0.0984753 0.966289 2.39499 0.624801 95.1304
19 0.0836834 0.970971 2.38215 0.626791 100.36
20 0.0913404 0.96925 2.46774 0.61873 105.684
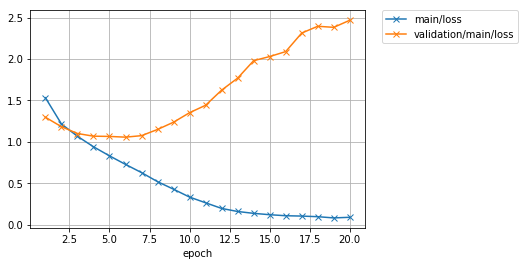
学習が20エポックまで終わりました。ロスと精度のプロットを見てみましょう。
Image(filename='MyModel_cifar10_result/loss.png')
Image(filename='MyModel_cifar10_result/accuracy.png')
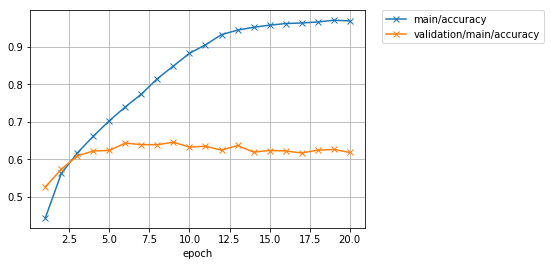
学習データでの精度(main/accuracy)は97%付近まで到達していますが、テストデータでのロス(validation/main/loss)はむしろIterationを進むごとに大きくなってしまっており、またテストデータでの精度(`validation/main/accuracy')も62%前後で頭打ちになってしまっています。学習データでは良い精度が出ているが、テストデータでは精度が良くないということなので、モデルが学習データにオーバーフィッティングしていると思われます。
3. 学習済みモデルを使った予測
テスト精度は62%程度でしたが、試しにこの学習済みモデルを使っていくつかのテスト画像を分類させてみましょう。
%matplotlib inline
import matplotlib.pyplot as plt
cls_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
def predict(model, image_id):
_, test = cifar.get_cifar10()
x, t = test[image_id]
model.to_cpu()
y = model.predictor(x[None, ...]).data.argmax(axis=1)[0]
print('predicted_label:', cls_names[y])
print('answer:', cls_names[t])
plt.imshow(x.transpose(1, 2, 0))
plt.show()
for i in range(10, 15):
predict(model, i)
出力結果
predicted_label: dog
answer: airplane

predicted_label: truck
answer: truck

predicted_label: bird
answer: dog

predicted_label: horse
answer: horse

predicted_label: truck
answer: truck

うまく分類できているものもあれば、そうでないものもありました。モデルの学習に使用したデータセット上ではほぼ百発百中で正解できるとしても、未知のデータ、すなわちテストデータセットにある画像に対して高精度な予測ができなければ、意味がありません2。テストデータでの精度は、モデルの汎化性能に関係していると言われます。
どうすれば高い汎化性能を持つモデルを設計し、学習することができるでしょうか?
4. もっと深いモデルを定義してみよう
では、上のモデルよりもよりたくさんの層を持つモデルを定義してみましょう。ここでは、1層の畳み込みネットワークをConvBlock、1層の全結合ネットワークをLinearBlockとして定義し、これをたくさんシーケンシャルに積み重ねる方法で大きなネットワークを定義してみます。
構成要素を定義する
まず、今目指している大きなネットワークの構成要素となるConvBlockとLinearBlockを定義してみましょう。
class ConvBlock(chainer.Chain):
def __init__(self, n_ch, pool_drop=False):
w = chainer.initializers.HeNormal()
super(ConvBlock, self).__init__(
conv=L.Convolution2D(None, n_ch, 3, 1, 1,
nobias=True, initialW=w),
bn=L.BatchNormalization(n_ch)
)
self.train = True
self.pool_drop = pool_drop
def __call__(self, x):
h = F.relu(self.bn(self.conv(x)))
if self.pool_drop:
h = F.max_pooling_2d(h, 2, 2)
h = F.dropout(h, ratio=0.25, train=self.train)
return h
class LinearBlock(chainer.Chain):
def __init__(self):
w = chainer.initializers.HeNormal()
super(LinearBlock, self).__init__(
fc=L.Linear(None, 1024, initialW=w))
self.train = True
def __call__(self, x):
return F.dropout(F.relu(self.fc(x)), ratio=0.5, train=self.train)
ConvBlockはChainを継承したモデルとして定義されています。これは一つの畳み込み層とBatch Normalization層をパラメータありで持っているので、コンストラクタ内でこれらの登録を行っています。__call__メソッドでは、これらにデータを渡しつつ、活性化関数ReLUを適用して、さらにpool_dropがコンストラクタにTrueで渡されているときはMax PoolingとDropoutという関数を適用するような小さなネットワークになっています。
Chainerでは、Pythonを使って書いたforward計算のコード自体がモデルの構造を表します。すなわち、実行時にデータがどのような層をくぐっていったか、ということがネットワークそのものを定義します。これによって、上記のような分岐などを含むネットワークも簡単に書け、柔軟かつシンプルで可読性の高いネットワーク定義が可能になります。これがDefine-by-Runと呼ばれる特徴です。
大きなネットワークの定義
次に、これらの小さなネットワークを構成要素として積み重ねて、大きなネットワークを定義してみましょう。
class DeepCNN(chainer.ChainList):
def __init__(self, n_output):
super(DeepCNN, self).__init__(
ConvBlock(64),
ConvBlock(64, True),
ConvBlock(128),
ConvBlock(128, True),
ConvBlock(256),
ConvBlock(256),
ConvBlock(256),
ConvBlock(256, True),
LinearBlock(),
LinearBlock(),
L.Linear(None, n_output)
)
self._train = True
@property
def train(self):
return self._train
@train.setter
def train(self, val):
self._train = val
for c in self.children():
c.train = val
def __call__(self, x):
for f in self.children():
x = f(x)
return x
ここで利用しているのが、ChainListというクラスです。このクラスはChainを継承したクラスで、いくつものLinkやChainを順次呼び出していくようなネットワークを定義するときに便利です。ChainListを継承して定義されるモデルは、親クラスのコンストラクタを呼び出す際にキーワード引数ではなく普通の引数としてLinkもしくはChainオブジェクトを渡すことができます。そしてこれらは、self.children()メソッドによって登録した順番に取り出すことができます。
この特徴を使うと、forward計算の記述が簡単になります。**self.children()**が返す構成要素のリストから、for文で構成要素を順番に取り出していき、そもそもの入力であるxに取り出してきた部分ネットワークの計算を適用して、この出力でxを置き換えるということを順番に行っていけば、一連のLinkまたはChainを、コンストラクタで親クラスに登録した順番と同じ順番で適用していくことができます。そのため、シーケンシャルな部分ネットワークの適用によって表される大きなネットワークを定義するのに重宝します。
それでは、学習を回してみます。今回はパラメータ数も多いので、学習を停止するエポック数を100に設定します。
model = train(DeepCNN(10), max_epoch=100)
出力結果
epoch main/loss main/accuracy validation/main/loss validation/main/accuracy elapsed_time
1 2.05147 0.242887 1.71868 0.340764 14.8099
2 1.5242 0.423816 1.398 0.48537 29.12
3 1.24906 0.549096 1.12884 0.6042 43.4423
4 0.998223 0.652649 0.937086 0.688495 58.291
5 0.833486 0.720009 0.796678 0.73756 73.4144
.
.
.
95 0.0454193 0.987616 0.815549 0.863555 1411.86
96 0.0376641 0.990057 0.878458 0.873109 1426.85
97 0.0403836 0.98953 0.849209 0.86465 1441.19
98 0.0369386 0.989677 0.919462 0.873905 1456.04
99 0.0361681 0.990677 0.88796 0.86873 1470.46
100 0.0383634 0.988676 0.92344 0.869128 1484.91
(ログが長いので途中を省略しています。)
学習が終了しました。ロスと精度のグラフを見てみましょう。
Image(filename='DeepCNN_cifar10_result/loss.png')

Image(filename='DeepCNN_cifar10_result/accuracy.png')
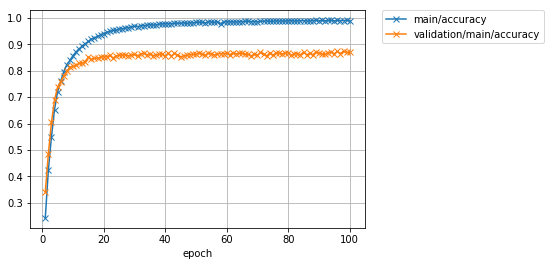
先程よりも大幅にテストデータに対する精度が向上したことが分かります。62%前後だった精度が、87%程度まで上がりました。しかし最新の研究成果では97%近くまで達成されています。さらに精度を上げるには、今回行ったようなモデルの改良ももちろんのこと、学習データを擬似的に増やす操作(Data augmentation)や、複数のモデルの出力を一つの出力に統合する操作(Ensemble)などなど、いろいろな工夫が考えられます。
データセットクラスを書いてみよう
ここでは、Chainerにすでに用意されているCIFAR10のデータを取得する機能を使って、データセットクラスを自分で書いてみます。Chainerでは、データセットを表すクラスは以下の機能を持っていることが必要とされます。
- データセット内のデータ数を返す
__len__メソッド - 引数として渡される
iに対応したデータもしくはデータとラベルの組を返すget_exampleメソッド
その他のデータセットに必要な機能は、chainer.dataset.DatasetMixinクラスを継承することで用意できます。ここでは、DatasetMixinクラスを継承し、Data augmentation機能のついたデータセットクラスを作成してみましょう。
1. CIFAR10データセットクラスを書く
import numpy as np
from chainer import dataset
from chainer.datasets import cifar
class CIFAR10Augmented(dataset.DatasetMixin):
def __init__(self, train=True):
train_data, test_data = cifar.get_cifar10()
if train:
self.data = train_data
else:
self.data = test_data
self.train = train
self.random_crop = 4
def __len__(self):
return len(self.data)
def get_example(self, i):
x, t = self.data[i]
if self.train:
x = x.transpose(1, 2, 0)
h, w, _ = x.shape
x_offset = np.random.randint(self.random_crop)
y_offset = np.random.randint(self.random_crop)
x = x[y_offset:y_offset + h - self.random_crop,
x_offset:x_offset + w - self.random_crop]
if np.random.rand() > 0.5:
x = np.fliplr(x)
x = x.transpose(2, 0, 1)
return x, t
このクラスは、CIFAR10のデータのそれぞれに対し、
- 32x32の大きさの中からランダムに28x28の領域をクロップ
- 1/2の確率で左右を反転させる
という加工を行っています。こういった操作を加えることで擬似的に学習データのバリエーションを増やすと、オーバーフィッティングを抑制することに役に立つということが知られています。これらの操作以外にも、画像の色味を変化させるような変換やランダムな回転、アフィン変換など、さまざまな加工によって学習データ数を擬似的に増やす方法が提案されています。
自分でデータの取得部分も書く場合は、コンストラクタに画像フォルダのパスとファイル名に対応したラベルの書かれたテキストファイルへのパスなどを渡してプロパティとして保持しておき、get_exampleメソッド内でそれぞれの画像を読み込んで対応するラベルとともに返す、という風にすれば良いことが分かります。
2. 作成したデータセットクラスを使って学習を行う
それではさっそくこのCIFAR10クラスを使って学習を行ってみましょう。先程使ったのと同じ大きなネットワークを使うことで、Data augmentationの効果がどの程度あるのかを調べてみましょう。train関数も含め、データセットクラス以外は先程使用したコードとほぼ同じになっています。異なるところはエポック数と、保存先ディレクトリ名だけです。
model = train(DeepCNN(10), max_epoch=100, train_dataset=CIFAR10Augmented(), test_dataset=CIFAR10Augmented(False))
出力結果
epoch main/loss main/accuracy validation/main/loss validation/main/accuracy elapsed_time
1 2.023 0.248981 1.75221 0.322353 18.4387
2 1.51639 0.43716 1.36708 0.512639 36.482
3 1.25354 0.554177 1.17713 0.586087 54.6892
4 1.05922 0.637804 0.971438 0.665904 72.9602
5 0.895339 0.701886 0.918005 0.706409 91.4061
.
.
.
95 0.0877855 0.973171 0.726305 0.89162 1757.87
96 0.0780378 0.976012 0.943201 0.890725 1776.41
97 0.086231 0.973765 0.57783 0.890227 1794.99
98 0.0869593 0.973512 1.65576 0.878981 1813.52
99 0.0870466 0.972931 0.718033 0.891421 1831.99
100 0.079011 0.975332 0.754114 0.892815 1850.46
(ログが長いので途中を省略しています。)
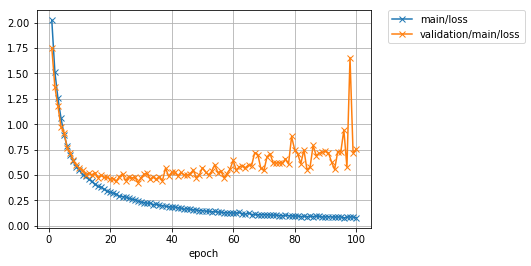
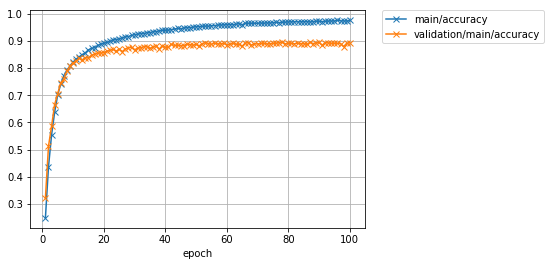
先程のData augmentationなしの場合は87%程度で頭打ちになっていた精度が、学習データにaugmentationを施すことで89%以上まで向上させられることが分かりました。2%強の改善です。
最後に、ロスと精度のグラフを見てみましょう。
Image(filename='DeepCNN_cifar10augmented_result/loss.png')
出力結果
Image(filename='DeepCNN_cifar10augmented_result/accuracy.png')
おわりに
本記事では、Chainerに関する
- Trainerを使わない学習ループの書き方
- Trainerの使い方
- 自作モデルの書き方
- 自作データセットクラスの書き方
を簡単に紹介しました。今後もHands-on形式で行うかどうかは分かりませんが、以下のようなものの解説をどこかに書いていきたいと思います。
- Trainerを構成するUpdaterやIteratorを自作する方法-
-
chainer.links.models.visionモジュール以下にあるVGG16LayersやResNet50LayersというPre-trainedモデルを特定のタスクに向けてFine-tuningする方法 - Extensionの作り方
また、Chainerの開発にコミットしてくれる方を歓迎します!Chainerはオープンソースソフトウェアですので、皆さんが自身で欲しい機能などを提案し、Pull requestを送ることで進化していきます。興味のある方は、こちらのContoribution Guideをお読みになった後、ぜひIssueを立てたりPRを送ったりしてみてください。お待ちしております。
pfent/chainer
https://github.com/pfnet/chainer
脚注
-
本記事では、Chainerの使い方の説明に主眼を置いているため、ValidationデータセットとTestデータセットを明確に区別していません。しかし実際にはこれらは区別されるべきです。普通、Trainingデータの一部をTrainingデータセットから取り除き、それらの取り除かれたデータでValidationデータセットを構成しておきます。その後、Trainingデータで訓練したモデルをまずValidationデータで評価し、Validationデータでの性能を向上させるようにモデルを改良していくというのが一般的な手順です。Testデータは全ての取り組みが終了したあとに、最終的なそのモデルの性能を(例えば他のモデルなどと比較する目的で)評価するためにだけ用いられます。偏ったデータを使ってモデル改良を行ってしまいオーバーフィッティングなどに陥ることを避けるなどの目的で、Training/Validationデータの構成を複数用意しておく場合もあります。 ↩
-
学習データに対する予測精度は、もし学習データから抜き出されたあるデータをクエリとし、それが含まれている学習データセットから検索して発見することが必ずできるならば、そのデータについているラベルを答えることで、100%になってしまいます。 ↩