どうもmiyachi(@_38ch)です。
ちょっと仕事でネットワーク分析的な事が必要になり、Pythonで描くんであればどんなライブラリ使うのかなで調べたらnetworkxが多かったので自分でも軽く書いてみました。
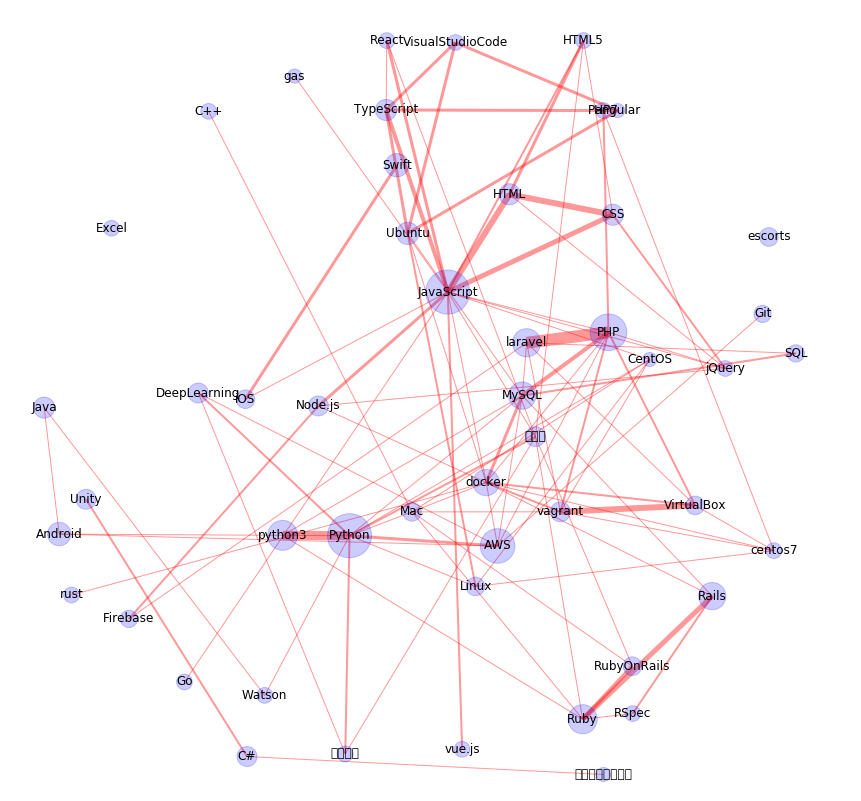
Qiitaにすでに出てる記事を参考にしながら、Qiitaのタグのネットワーク(どのタグとどのタグがセットで使われているか)を可視化してみます。先に結果を出しちゃうとこういうものを作りました。
環境
- Mac High Sierra 10.13.4
- Python 3.5.0
- Jupyter Notebook
データの準備
Qiitaの記事取得のAPIを叩いて、タグのデータだけ取得します。
import requests
import json
import collections
import itertools
import networkx as nx
%matplotlib inline
import matplotlib.pyplot as plt
params = {"page":1, "per_page":100}
for i in range(60):
print("fetching... page " + str(i + 1))
params["page"] = i + 1
res = requests.get("https://qiita.com/api/v2/items", params=params)
items.extend(json.loads(res.text))
いま、itemsにはタグ以外のデータも入ってしまっているので、タグだけを抽出。
tags_list = []
for item in items:
tags = [tag["name"] for tag in item["tags"]]
tags_list.append(tags)
これでtags_listには、記事ごとのタグのリストが入ってきます。
[['cli', 'ESP32', 'M5stack'],
['Wiki.js'],
['PHP', 'laravel', 'Eloquent'],
['Python', '初心者', '機械学習', 'gensim', 'word2vec'],
['Git', 'GitHub', 'バージョン管理'],
['HTTPメソッド'],
['文字コード', 'バイナリ'],
['Node.js', 'npm', 'anyenv', 'ndenv'],
['RHEL', 'ext4'],
['R', 'Pandoc', 'RMarkdown']...
]
すべてのタグをネットワークに入れるとカオスになるので、頻出タグを選別しておきましょう。今回はTOP50を取得。
tag_count = collections.Counter(itertools.chain.from_iterable(tags_list)).most_common(50)
[('JavaScript', 39),
('Python', 39),
('PHP', 27),
('AWS', 24),
('python3', 18),
('Ruby', 17),
('laravel', 16),
('Rails', 15),
('MySQL', 15),
('docker', 14)...
]
ネットワーク図の作成
それではnetworkxを使って、データの可視化を行なっていきます。
G = nx.Graph()
G.add_nodes_from([(tag, {"count":count}) for tag, count in tag_count])
まだこの時点では、ノード(ネットワーク図に置ける"丸")しか作成されていません。
ので、エッジ(丸と丸を繋ぐ線)を追加していきましょう。
for tags in tags_list:
for tag0, tag1 in itertools.combinations(tags, 2):
if not G.has_node(tag0) or not G.has_node(tag1):
continue
if G.has_edge(tag0, tag1):
G[tag0][tag1]["weight"] += 1
else:
G.add_edge(tag0, tag1, weight=1)
ここは少し複雑ですが、まず、tag_listから一つのリストを取得し、全ての組み合わせ(tag0, tag1)をみています。
例えば、['Git', 'GitHub', 'バージョン管理']というtag_listがあれば、(Git, GitHub), (Git, バージョン管理), (Github, バージョン管理)という3パターンがtag0, tag1に入ってきます。
その上で、すでに、GitとGitHubのノード間にエッジが追加されていた場合は、weight(線の太さ)を加算し、エッジが追加されていない場合は、エッジを追加します。
それではいよいよグラフを描画してみます。
plt.figure(figsize=(15,15)) # グラフのサイズを定義
pos = nx.spring_layout(G, k=1.5) # ノード間の反発力を定義。値が小さいほど密集する
node_size = [ d['count']*50 for (n,d) in G.nodes(data=True)] # ノードの大きさを調整
nx.draw_networkx_nodes(G, pos, node_color='b', alpha=0.2, node_size=node_size, font_weight="bold", font_family='VL Gothic') # ノードのスタイルを定義
nx.draw_networkx_labels(G, pos, fontsize=14)
edge_width = [ d['weight']*0.5 for (u,v,d) in G.edges(data=True)] # エッジの太さを調整
nx.draw_networkx_edges(G, pos, alpha=0.4, edge_color='r', width=edge_width) # エッジのスタイルを定義
plt.axis('off')
結果として以下のようなネットワークになります。
(日本語の出し方がわからないので、わかる方教えてください・・・)
考察
- 強いところでいうと、Python、JavaScript、PHP、AWSあたりでしょうか。
- 多分Pythonの真下にあるのは機械学習かな?
- Excelが孤立しているのがエモい。
参考記事
[Python]NetworkXでQiitaのタグ関係図を描く
宣伝
プライベートでWalicaという複雑な割り勘のサポートサービスを作っているのでもしよかったら、使ってみてください。
