はじめに
先日ラズパイのSDカードが亡くなりました。寿命でした。
2017年10月にGoogle Home購入を機にIFTTT、Firebaseと連携したホームオートメーションをラズパイに構築し、3年以上毎日稼働してくれたSDカードでした。
過去に「Google Homeと暮らした1年間のログを分析してみた」という記事を書いていましたが、いいタイミングですので本記事では過去3年分のログを分析してみようと思います。
※集計結果はこちら
Google Assistantログのエクスポート
まずはGoogle Assistantログのエクスポートを行います。
これはGoogle データ エクスポートというページで行えます。
Google Assistantログだけでなく、Googleアカウント上のあらゆるデータをエクスポートできます。
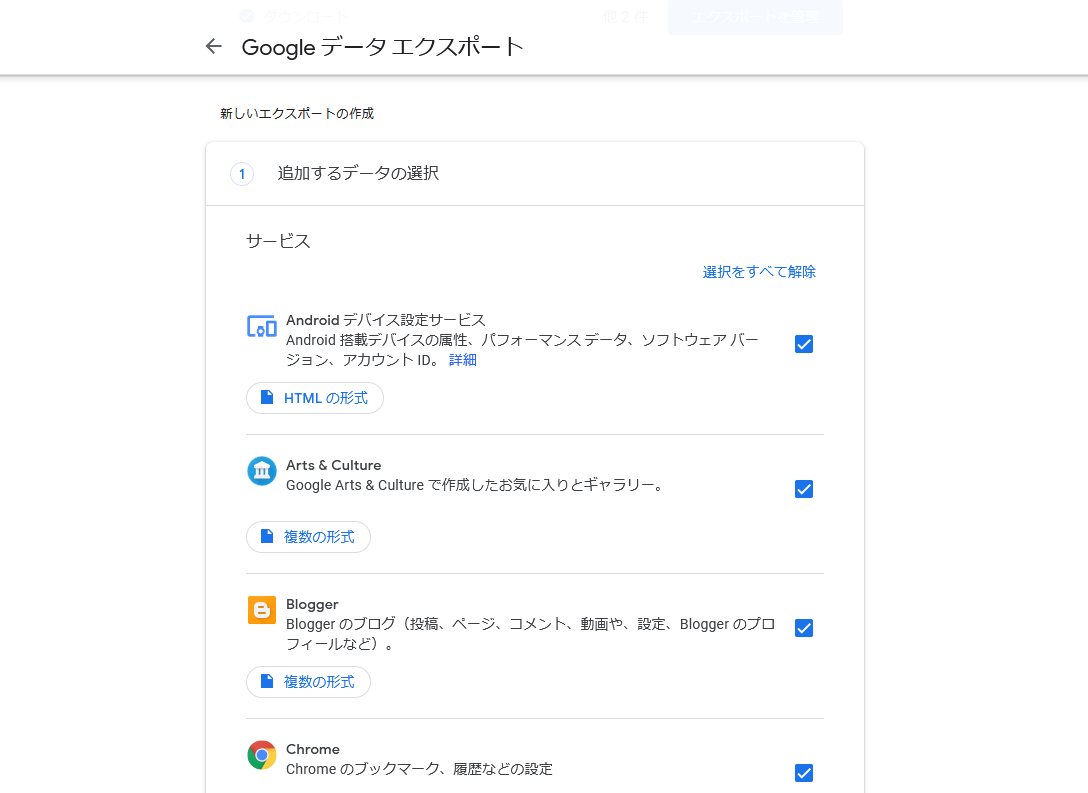
※音声録音設定がオフだとログが蓄積されません
参考:ウェブとアプリのアクティビティの音声録音を管理する
エクスポートの実行
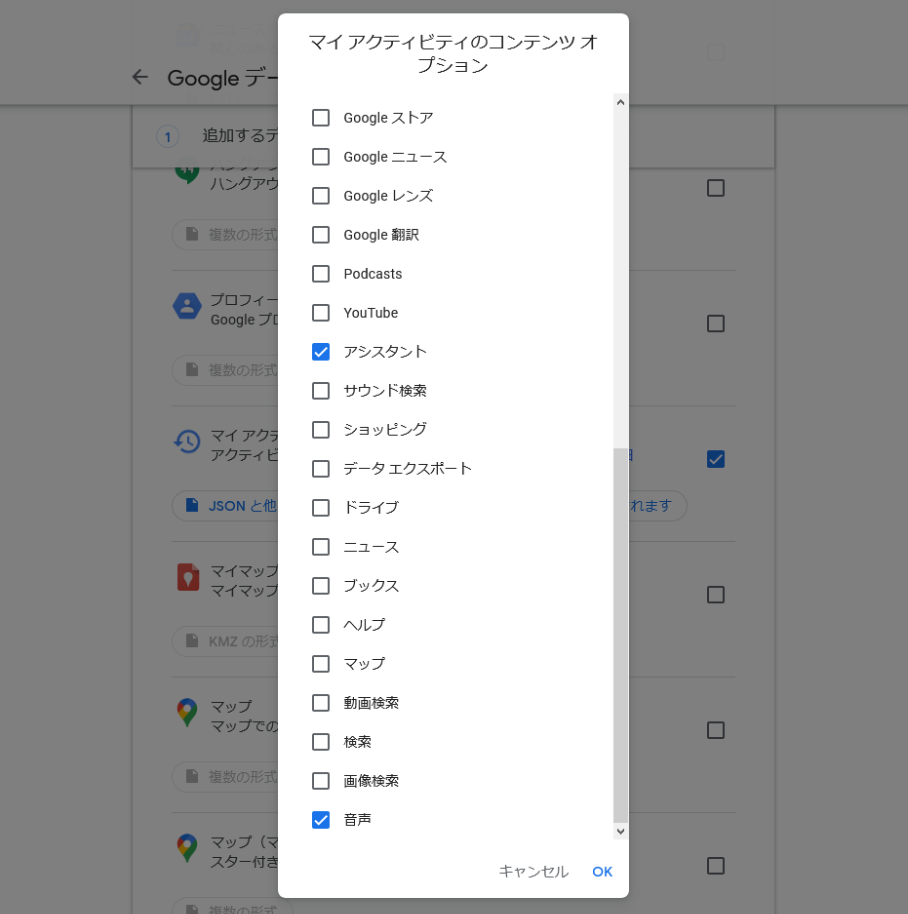
Google Assistantログは「マイ アクティビティ」内の「アシスタント」と「音声」の項目になります。
これらのみを選択し、アーカイブの形式をHTML→JSONとしてエクスポートを実行しました。
最初「アシスタント」の項目に気付かず「音声」のみをエクスポートしましたが、30分ほどで889.2 MBのデータをダウンロード可能な状態になりました。
そのあと「アシスタント」のみを追加でエクスポートしましたが、その際878.8 MBのデータがダウンロード可能になるまで30時間ほど要しました…
連続してエクスポートを実行すると2回目以降は優先度が下げられてしまうのかもしれません。
これを我が家のGoogle Homeメインユーザーである私と妻の2アカウント分行います。
昔はVoice Matchのバグか当時の仕様なのか、私と妻どちらの音声ログも私のアカウントのみに集約されていましたが、いつの間にかちゃんとアカウントごとになったようです。
エクスポートデータのファイル構造
エクスポートされたデータは1G近くあるZIPファイルですが、容量のほとんどが音声データ(MP3)です。
分析に必要なのはそれらがテキスト化されたデータであり、それはエクスポート時に選択したJSON形式で出力されています。
約10 MBほどのJSONです。
ダウンロードしたエクスポートデータのZIPよりそのJSONのみを引っこ抜きます。
Takeout
│ アーカイブ概要.html // 不要
│
└─マイ アクティビティ
├─アシスタント
│ yyyy-mm-dd_hh_mm_ss_xxx_UTC.mp3 // たくさんあるけど不要
│ マイアクティビティ.json // 引っこ抜く
│
└─音声
yyyy-mm-dd_hh_mm_ss_xxx_UTC.mp3 // たくさんあるけど不要
マイアクティビティ.json // 引っこ抜く
CSVへ変換
次にこのあとの処理のためにJSON形式のログデータをCSV形式に変換します。
ログデータにはテキスト化された発話情報やそれに対するレスポンス等さまざまな情報が含まれていますが、今回の分析に必要なのは日時とテキスト化された発話情報のみです。
この2つの情報のみをCSVで出力するプログラムをかきました。
大まかな処理としては以下のようになります。
- 複数のログJSONを読み込みマージ
- 音声ログとアシスタントログで分かれており、かつ私と妻それぞれのログがあるため
- JSON構造から
titleとtimeのみ抽出-
titleが発話情報、timeがUNIXタイムスタンプ
-
-
timeでソート - 重複削除
- csv化
"use strict"
const unique = array => array.filter((element1, index, self) =>
self.findIndex(element2 =>
element1.time === element2.time && element1.title === element2.title
) === index
)
const formatDate = unixTimestamp => {
const date = new Date(unixTimestamp)
const year = date.getFullYear()
const month = ('00' + (date.getMonth()+1)).slice(-2)
const day = ('00' + date.getDate()).slice(-2)
const hour = ('0' + date.getHours()).slice(-2)
const minute = ('0' + date.getMinutes()).slice(-2)
const second = ('0' + date.getSeconds()).slice(-2)
return `${year}/${month}/${day} ${hour}:${minute}:${second}`
}
const min = log => log.map(log => {
return {
title: log.title.replace(" と言いました", ""),
time: formatDate(log.time),
}
})
const log2csv = log => {
let csv = "time,title\n"
log.forEach(log => csv += `${log.time},${log.title}\n`)
return csv
}
// 引数判定
if (process.argv.length < 3) {
console.log("ログを引数に指定してください!")
process.exit(1)
}
// 引数からログJSON読み込み
const logs = []
for (let i = 2; i < process.argv.length; i++)
logs.push(require(`./${process.argv[i]}`))
// ログをマージ
const mergeLog = logs.flat()
// 要素を`title`と`time`だけにする
const minLog = min(mergeLog)
// `time`でソート
minLog.sort((a, b) => a.time > b.time ? 1 : -1)
// 重複削除
const uniqueLog = unique(minLog)
// csv化
const csv = log2csv(uniqueLog)
console.log(csv)
# ログJSONを引数にして実行
node log2csv.js マイアクティビティログ_アシスタント.json マイアクティビティログ_音声.json > log.csv
上記プログラムを通した我が家のCSVログは98,141レコードある4 MBほどのデータとなりました。
テキストマイニング
過去の記事ではこのあとCSVをExcelでこねこねしていましたが、つらいので今回はテキストマイニングツールを使ってみました。
テキストマイニングはやったことないので簡単にググって見つかった「KH Coder」というツールを使ってみました。
使い方はチュートリアルのスライドを見たらすぐ把握できます。
KH CoderにCSVを食わし、頻出単語のリストを取得します。
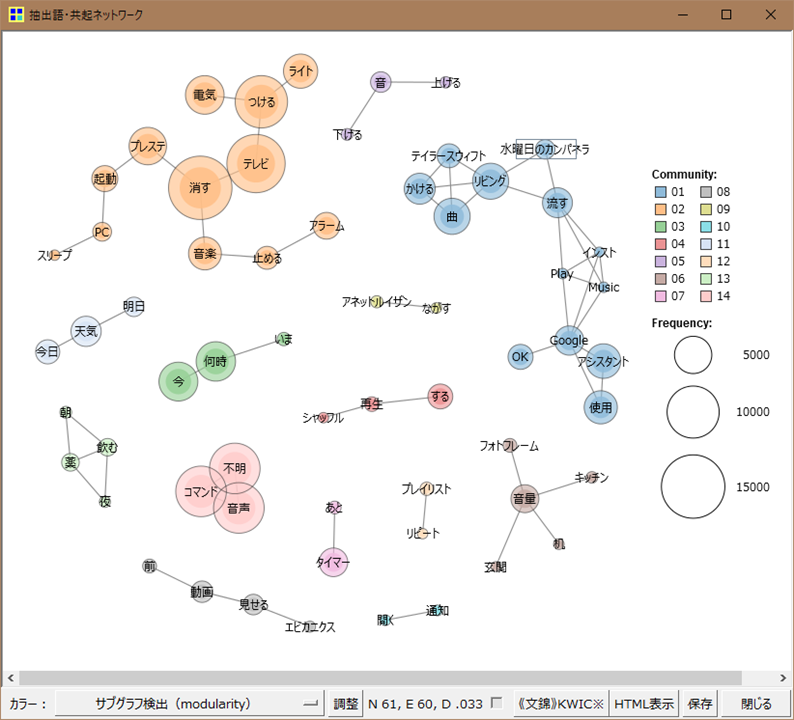
ついでに共起ネットワークを図にしてくれたりもしたのでなんとなくやってみました。
我が家のGoogle Assistantログの共起ネットワーク図はこんな感じです。
これを見るだけでどう使われているかがだいたい把握できます。
カテゴライズ
テキストマイニングにて出力した頻出単語のリストをチェックして大まかにカテゴライズします。
ここでは頻出単語TOP60ほどを手動でカテゴライズしました。
カテゴライズは各単語が意図する目的ごとに分類しました。
たとえば「曲」という単語の目的は音声再生ですし、「テレビ」という単語の目的は家電操作、という感じです。
過去の記事での分類をベースにし、基本的にこれらに収まりました。
それらに加えスキルやIFTTTで定義したオリジナル発話を「拡張機能」として分類しています。
また使われ方が多岐に渡る単語は除外しました。
たとえば「今」だと「今何時」や「今日の気温」どちらにもマッチしてしまうためです。
CSVへカテゴリー項目追加
次に発話データにカテゴリーを追加していきます。
上記のカテゴリーリストをもとにJSのリストデータを作成します。
このときに単語が動詞の場合は助動詞部を除外します。
たとえば「つける」という単語は実際には「つけて」と発話されているため、助動詞部を除外して「つけ」という単語にします。
リストはExcelで作業していたので、↓の式を貼り付けてオブジェクト配列化します。
="{ word: """&A2&""", category: """&B2&""" },"
あとはこのオブジェクト配列と先ほど出力したCSVを突き合わせて、カテゴリー付きのCSVを吐き出すプログラムを書くだけです。
"use strict"
const fs = require('fs')
// ここにカテゴリーのオブジェクト配列を記述
const categoryList = [
{ word: "曲", category: "音楽" },
{ word: "プレイリスト", category: "音楽" },
{ word: "テレビ", category: "家電" },
{ word: "プレステ", category: "家電" },
{ word: "見せ", category: "動画" },
...
]
categoryList.push({ word: "time,title", category: "category" })
if (process.argv.length < 3) {
console.log("ログを引数に指定してください!")
process.exit(1)
}
const csvPath = process.argv[2]
const csv = fs.readFileSync(csvPath).toString()
const lines = csv.split("\n")
const categorizeLines = lines.map(line => {
let category = "その他"
categoryList.some(data => {
if (line.match(data.word)) {
return category = data.category
}
})
return `${line},${category}`
})
console.log(categorizeLines.join("\n"))
# csvを引数にして実行
node addCategory.js log.csv > log.categorize.csv
上記のプログラムを通すと「日時」「発話テキスト」「カテゴリー」の3項目をもつCSVが吐き出されます。
あとはExcelで開けばピボットで簡単に集計できます。
集計結果
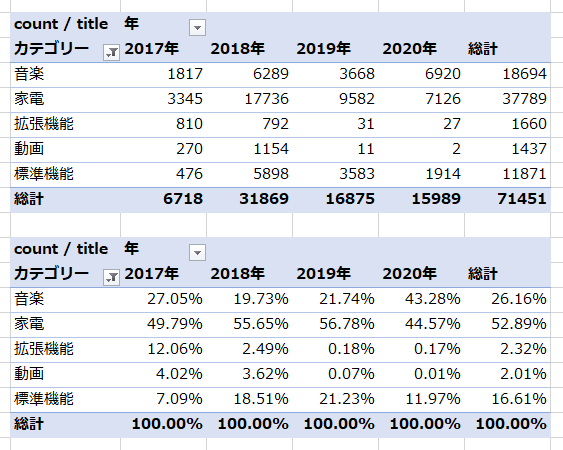
カテゴリーごとの集計結果は以下のようになりました。
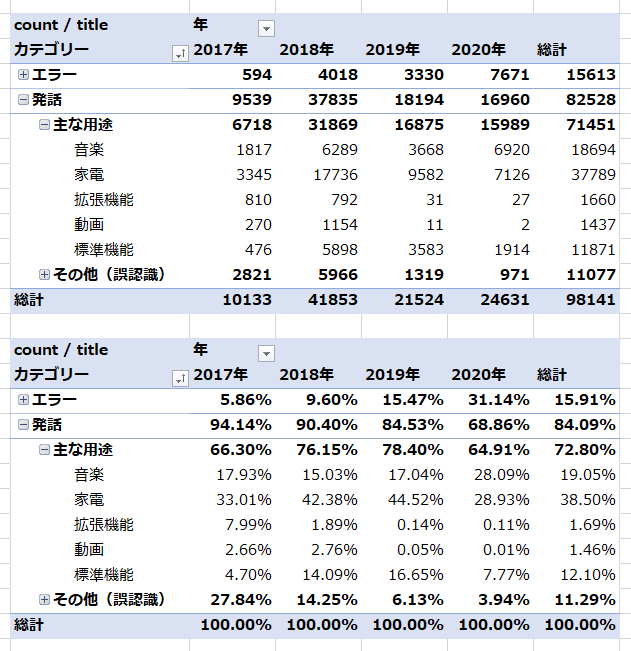
過去記事にならい、3段階で集計を行っています。
発話とエラー
まず発話とエラーで分類します。
エラーに分類されるものは「音声コマンドが不明です」といった認識エラーと思われるレコードや、発話の中に「OK Google」が含まれてしまっているレコードです。
エラー率は総計では約16%ですが、2020年は30%ほどあります。
原因は不明ですが「音声コマンドが不明です」というレコードが目立ちました。
正常認識と誤認識
発話の中で正常認識(主な発話)と誤認識(その他)で分類します。
「その他」に分類されるのは頻出単語TOP60外のものですが、詳細を見てみるとテレビの音を拾ったと思われるもの等誤認識と思われるレコードが多数でしたのでまるごと誤認識データとしました。
誤認識レコードは総計で約11%あり、エラーと合わせて27%となります。
2020年時点では合わせて35%ほどです。
今でも3回に1回はGoogle Assistantは発話をうまく聞き取れてないということでしょう。
※ただしここにはこちらが発話していないときに誤作動で起動したデータも含まれていると思われます
主な用途
意図した発話を正常に認識されている、主な用途のみの集計結果が以下になります。
家電操作
過去記事同様、家電操作が主な用途です。
照明、テレビはもちろん、我が家ではテレビ録画専用機であるプレステ4も音声操作できるようにしていてこれが便利です。
音楽再生
次に多いのが音楽再生ですが特に今年はリモートワーク化もあり、利用率があがりました。
ただ我が家はAmazonのEcho Showもあり、そちらとGoogle Homeを使い分けています。
Spotifyでランダム再生の場合はEcho Show、Google Play Musicでプレイリスト再生はGoogle Homeという使い分けです。
※最近はもっぱらSpotify & Echo Showですが、Alexaへ音声で指示しているわけではなく、Spotifyのアプリからつなぐ形です…
標準機能
あとはアラームやタイマー、天気や気温といった標準機能もよく使われています。
数字に表れるほどではなかったですが、今年はアラームセットをよく使いました。
ミーティングが決まったらすぐに音声でアラームをセットしていたのですが、これは結構便利だったと思います。
また妻は料理でよくタイマー設定をするのですがそれは基本的にEcho Showを使っています。
残り時間が画面上から確認できるためです。
※Nest Hubもあるのですがこちらはフォトフレームとしての利用がメインで子どもが目につくところへ置いています
拡張機能
拡張機能はスキルや薬ログといったレコードですが、もはやスキルは全然使っていませんし、薬ログも重度の腰のヘルニアで薬をちゃんと飲まないと大変なことになるという時期以外は使っていません。
動画(Chromecast)
動画に関しても2018年までChromecastで子ども向けのYouTubeをちょくちょく再生していましたが、今はnasneに録画した子ども向け番組をPlay Station 4で再生しています。
今回プレステは家電カテゴリーに分類してしまいましたが、過去記事だとこっちの分類だったかもです…
一日あたりの平均発話数
カウントを日数で割った一日あたりの平均発話数は以下のようになりました。
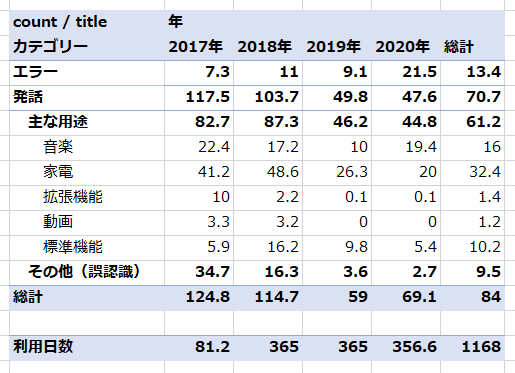
2020年時点でも意図した発話が日あたり平均で約45回ありました。
私と妻の総計となるので、単純に人数割してもひとりあたり20回強です。
まとめ
2020年ベースでの集計結果を振り返ったまとめです。
- Google Assistantは3回に1回はよくわかってない
- 一日あたり夫婦で平均45回Google Assistantに話しかけてる
- 家電操作と音楽再生がほぼ半々ずつ
- スキルは全然使わなくなってしまった…😢
- 標準機能もなんだかんだ便利
- リモートワークならミーティングのアラーム設定便利
過去記事とほぼほぼ同じまとめとなってしまいました…🥺
私の生活環境にアップデートがないのか、はたまたGoogle Assistantに便利なアップデートがないのか、発売された当初から使い方は大して変わらずといったところでした。