はじめに

こんばんは、mirukyです。
Amazon Comprehend シリーズ第1回です。
これまでAmazon ConnectシリーズやAmazon Bedrockシリーズ、Amazon Lexシリーズをお届けしてきましたが、今回からは Amazon Comprehend を主役にしたシリーズを始めます。
「大量のテキストデータから有益な情報を自動で抽出したいけど、自然言語処理(NLP)って専門知識が必要そう…」と思っている方は多いと思います。
Amazon Comprehendは、この悩みをまるっと解決してくれるAWSの フルマネージド自然言語処理(NLP)サービス です。機械学習の知識がなくても、テキストから 感情・エンティティ・キーフレーズ・言語 などを瞬時に抽出できます。
第1回となる今回は、Amazon Comprehendの 概要・主要機能・料金体系・対応言語・最新動向 を一気に解説します。2026年4月時点の情報をもとにしており、料金やリージョン対応状況など変更される可能性がありますので、 必ず公式ドキュメントも併せてご確認ください 。
目次
- Amazon Comprehendとは
- 主要機能の全体像
- 組み込みNLP機能
- カスタム機能
- 信頼と安全機能
- 料金体系
- 対応言語とリージョン
1. Amazon Comprehendとは
Amazon Comprehend は、AWSが提供する フルマネージドの自然言語処理(NLP)サービス です。
一言でいうと、 「テキストデータの内容を深層学習で自動分析し、構造化されたインサイトとして返してくれるプラットフォーム」 です。
APIにテキストを送信するだけで、エンティティ(人名・組織名・日付など)、感情(ポジティブ/ネガティブ)、キーフレーズ、言語などを JSON形式で取得 できます。機械学習モデルのトレーニングやインフラ管理は一切不要です。
1-1. 従来のテキスト分析の課題
大量のテキストデータ(カスタマーレビュー、サポートチケット、SNS投稿など)を分析しようとすると、通常は以下のような課題に直面します。
- NLPモデルの選定・トレーニングに専門知識が必要
- 大量のトレーニングデータの準備が必要
- モデルの精度チューニングに時間がかかる
- スケーラブルな推論インフラの構築・運用が必要
- 複数言語への対応が困難
1-2. Comprehendが解決すること
Amazon Comprehendを使えば、これらの課題を以下のように解決できます。
| 課題 | Comprehendによる解決 |
|---|---|
| NLPモデルの構築 | 事前トレーニング済みモデル がすぐに利用可能。API呼び出しのみ |
| トレーニングデータの準備 | 組み込み機能は データ不要 。カスタムモデルもAutoMLで少量データから学習 |
| 精度チューニング | AWSが 継続的にモデルを改善 。利用者側の作業不要 |
| 推論インフラの運用 | フルマネージド で自動スケール。インフラのプロビジョニング不要 |
| 多言語対応 | 100以上の言語を自動検出 。日本語を含む主要7言語でNLP分析可能 |
Amazon Comprehend Medical について
医療テキストに特化した Amazon Comprehend Medical という姉妹サービスも存在します。医薬品名・疾患名・処置名などの医療エンティティを抽出でき、ICD-10-CMやRxNormなどの医療コード体系へのリンクも可能です。本シリーズでは汎用のAmazon Comprehendに焦点を当てます。
2. 主要機能の全体像
Amazon Comprehendの機能は、大きく3つのカテゴリに分類できます。
【組み込みNLP】
【カスタム】

【信頼と安全】

2026年4月30日以降の機能終了について
イベント検出、トピックモデリング、プロンプト安全性分類の3機能は、2026年4月30日以降、新規アカウントへの提供が終了予定です。過去12か月以内にこれらの機能を使用したアカウントは引き続き利用できます。
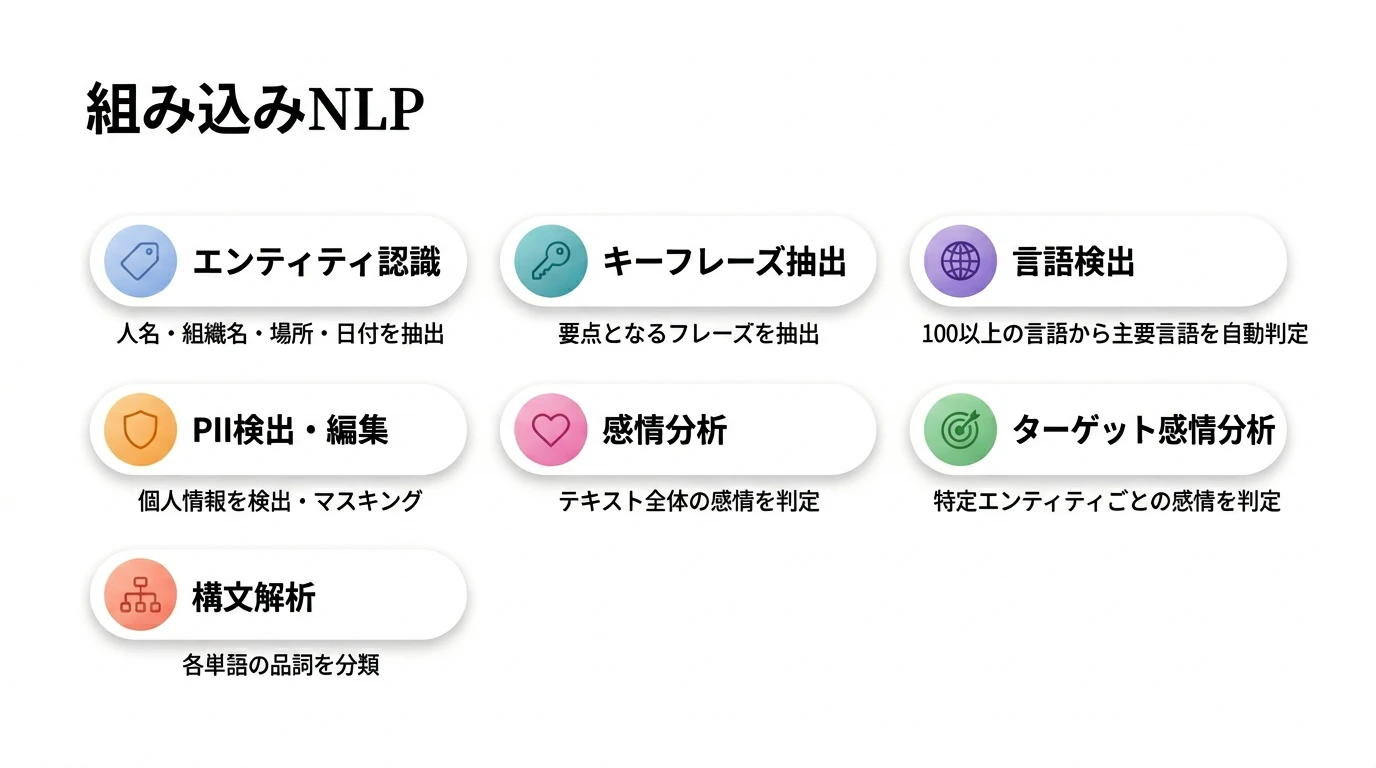
3. 組み込みNLP機能
3-1. エンティティ認識(Entity Recognition)
テキスト内の固有表現(Named Entity)を自動的に検出・分類します。
| エンティティタイプ | 例 |
|---|---|
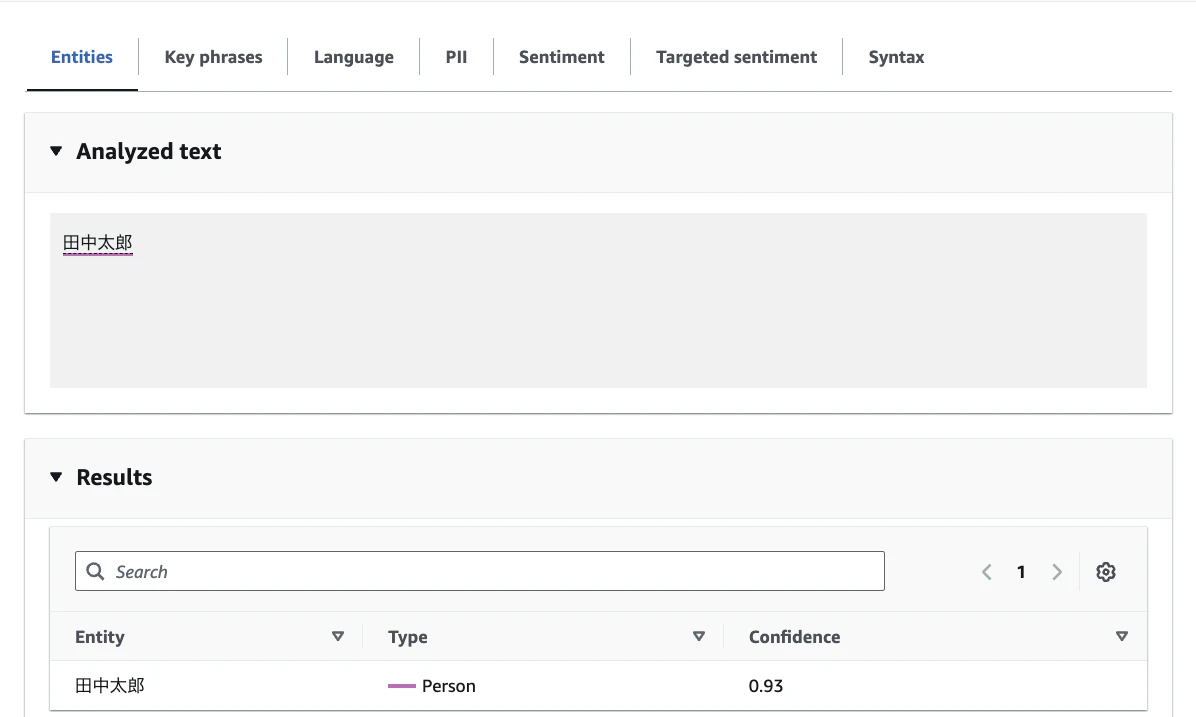
| PERSON | 田中太郎、Jeff Bezos |
| ORGANIZATION | Amazon、トヨタ自動車 |
| LOCATION | 東京、シアトル |
| DATE | 2026年3月、昨日 |
| QUANTITY | 100個、3.5キログラム |
| EVENT | オリンピック、re:Invent |
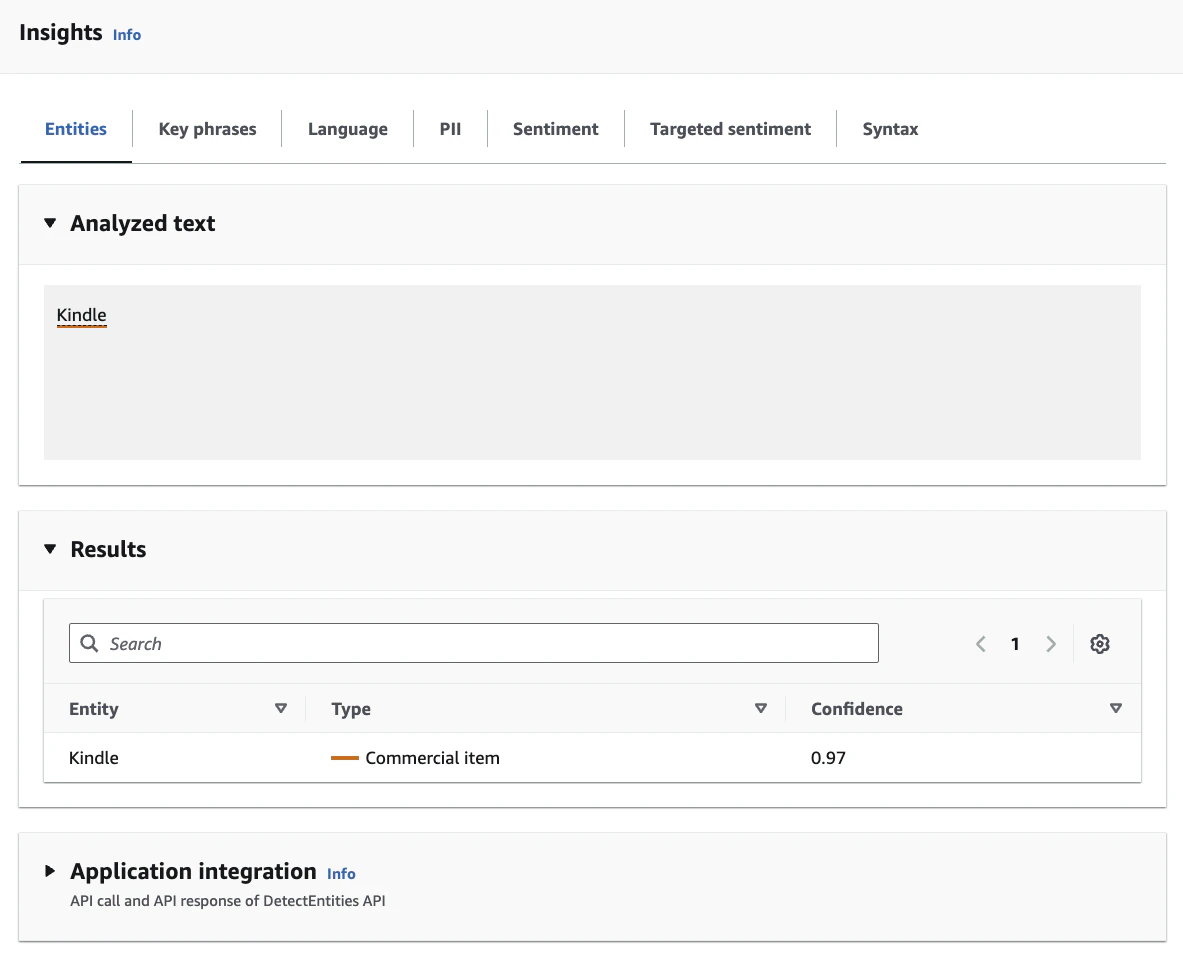
| COMMERCIAL_ITEM | Kindle、iPhone |
| TITLE | CEO、部長 |
| OTHER | その他 |
田中太郎の例
kindleの例
3-2. キーフレーズ抽出(Key Phrase Extraction)
テキストの 要点となるフレーズ を自動抽出します。ドキュメントの要約やタグ付けに活用できます。
入力例
Amazon Comprehendは自然言語処理サービスで、テキストから感情やエンティティを抽出できます。
出力例
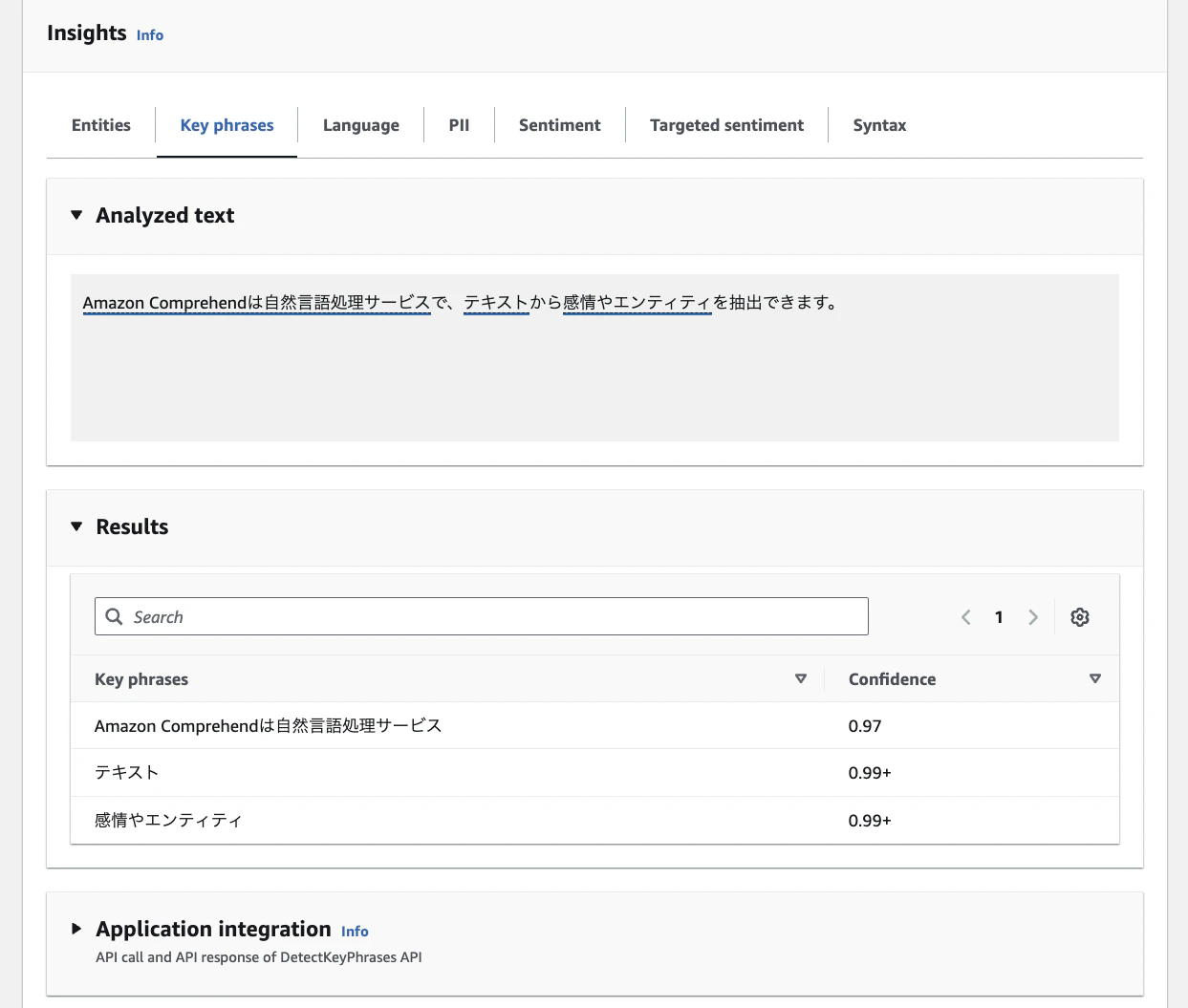
| キーフレーズ | スコア |
|---|---|
| Amazon Comprehendは自然言語処理サービス | 0.97 |
| テキスト | 0.99+ |
| 感情やエンティティ | 0.99+ |
3-3. 言語検出(Language Detection)
テキストの 主要言語を100以上の言語から自動判定 します。多言語コンテンツの振り分けに有用です。
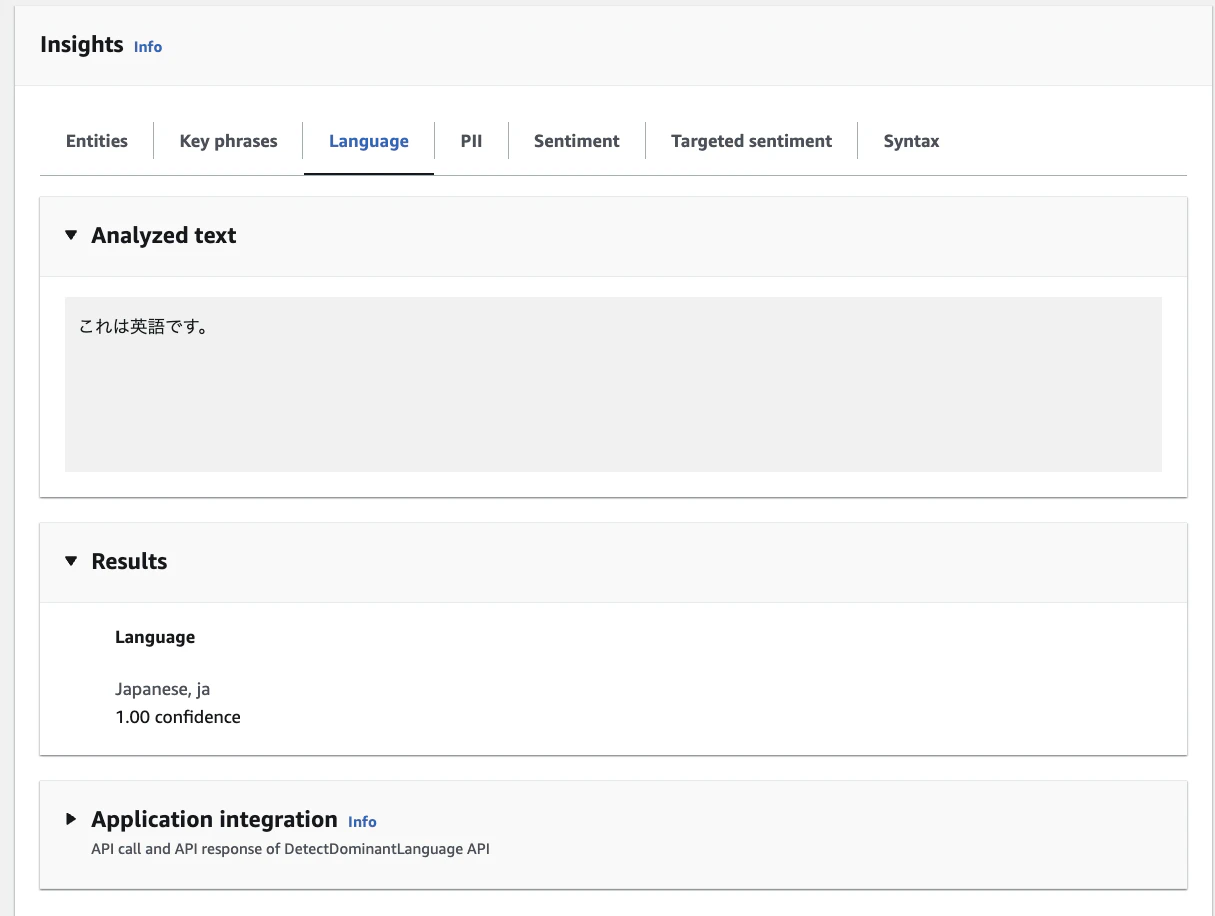
100%日本語だと判定してくれました、笑。
3-4. PII検出・編集(PII Detection & Redaction)
テキスト内の 個人を特定できる情報(PII) を検出し、編集(マスキング)できます。英語とスペイン語のみ対応なので、デフォルトで入力されている英語で試してみました。
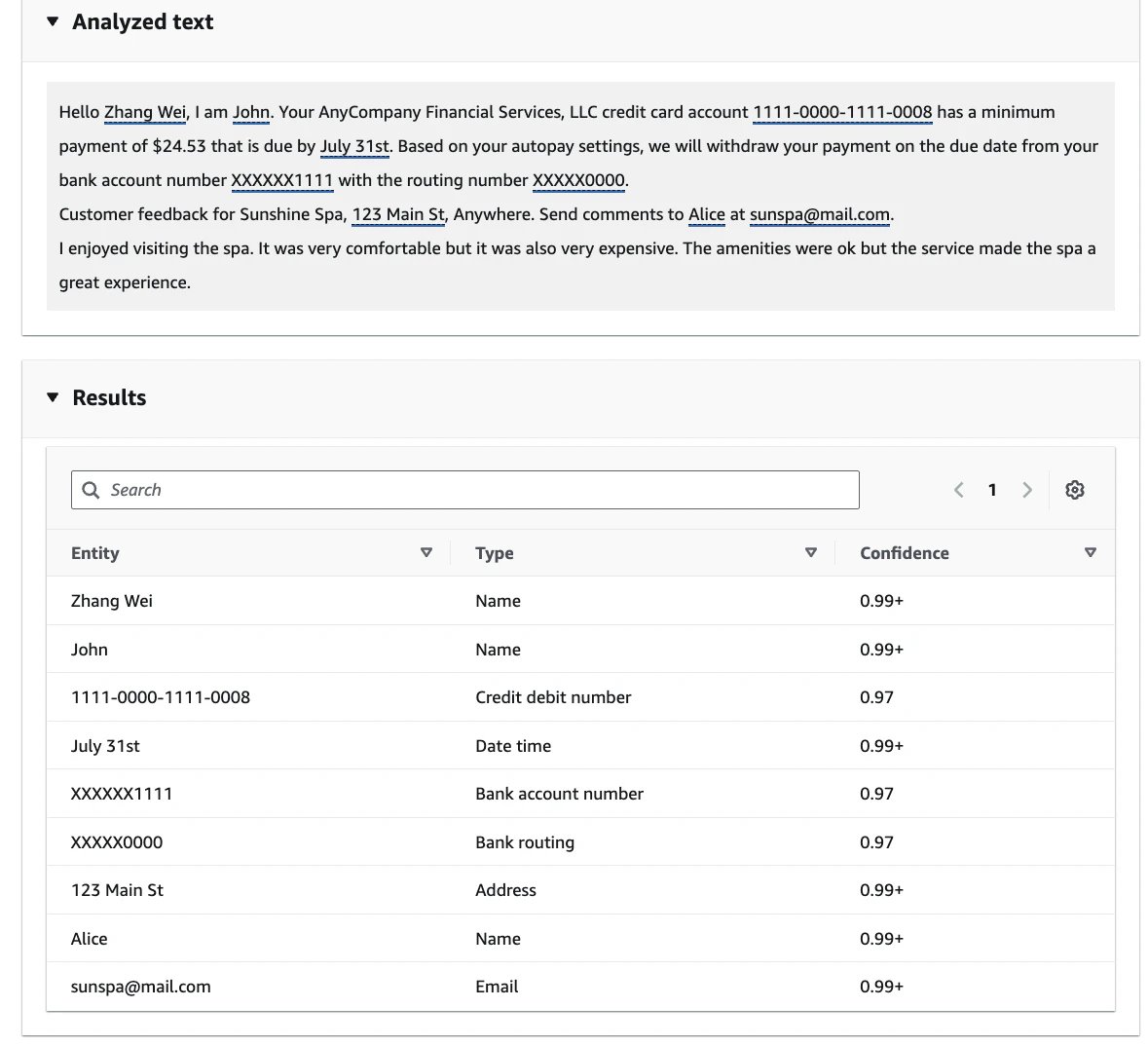
| API | 用途 |
|---|---|
| ContainsPII | ドキュメントにPIIが含まれているか(Yes/No)を判定 |
| DetectPII | PII エンティティの位置を特定し、 編集済みテキスト を生成 |
PII検出の活用シーン
- カスタマーサポートのチケットを検索用にインデックス化する前に、PIIを自動マスキング
- チャットログをデータ分析に使用する前に、個人情報を除去
- GDPRやAPPIなどの プライバシー規制への準拠 を支援
3-5. 感情分析(Sentiment Analysis)
テキスト全体の感情を 4つのカテゴリ に分類し、各カテゴリの信頼度スコアを返します。
| カテゴリ | 説明 |
|---|---|
| POSITIVE | 肯定的な感情 |
| NEGATIVE | 否定的な感情 |
| NEUTRAL | 中立的 |
| MIXED | 肯定と否定が混在 |
入力例
注文した商品の品質は素晴らしかったですが、配送に3週間もかかりました。
出力例
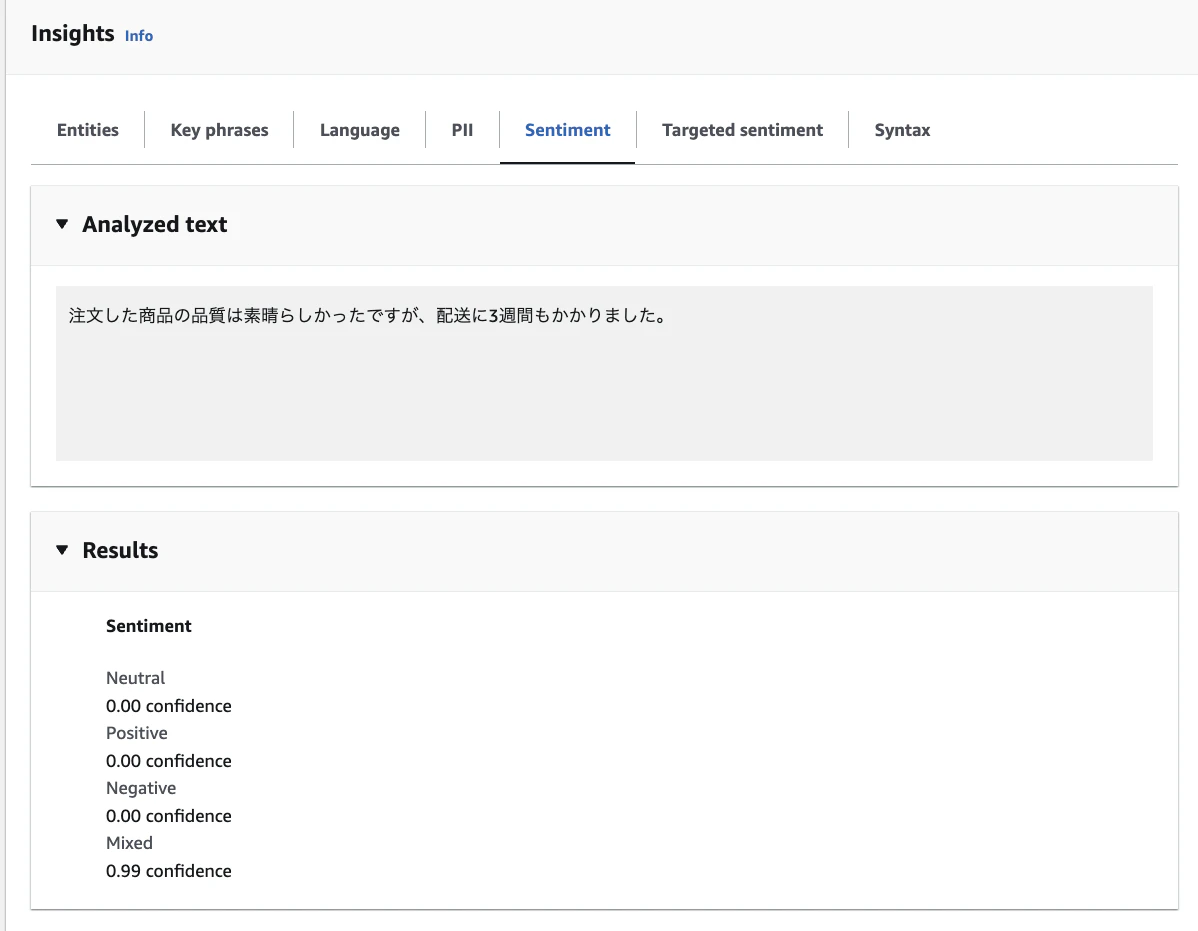
| 感情 | 信頼度スコア |
|---|---|
| MIXED | 0.99 |
| POSITIVE | 0.00 |
| NEGATIVE | 0.00 |
| NEUTRAL | 0.00 |
褒めつつも配送に時間がかかったと言っているので、まさしくMIXEDな例だと思いますが、正常に分析を行ってくれました。
3-6. ターゲット感情分析(Targeted Sentiment)
ターゲット感情分析は日本語に対応しておらず、日本語で行おうとすると下記のようになります。
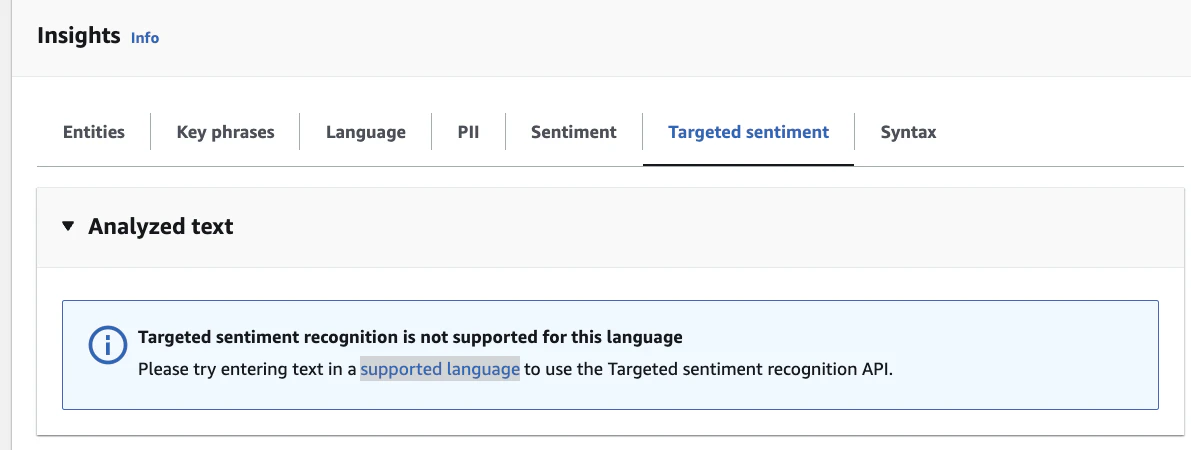
リンク先で対応言語をみると、ターゲット感情分析は英語のみ対応になっているようです。

https://docs.aws.amazon.com/comprehend/latest/dg/supported-languages.html
テキスト内の 個々のエンティティに対する感情 を分析できます。通常の感情分析がテキスト全体を対象とするのに対し、ターゲット感情分析は 「何に対して」 ポジティブ/ネガティブかを特定します。
入力例
The hamburger was great, but the service was slow.
(日本語訳:ハンバーガーは最高だったけど、接客が遅かった。)
出力例
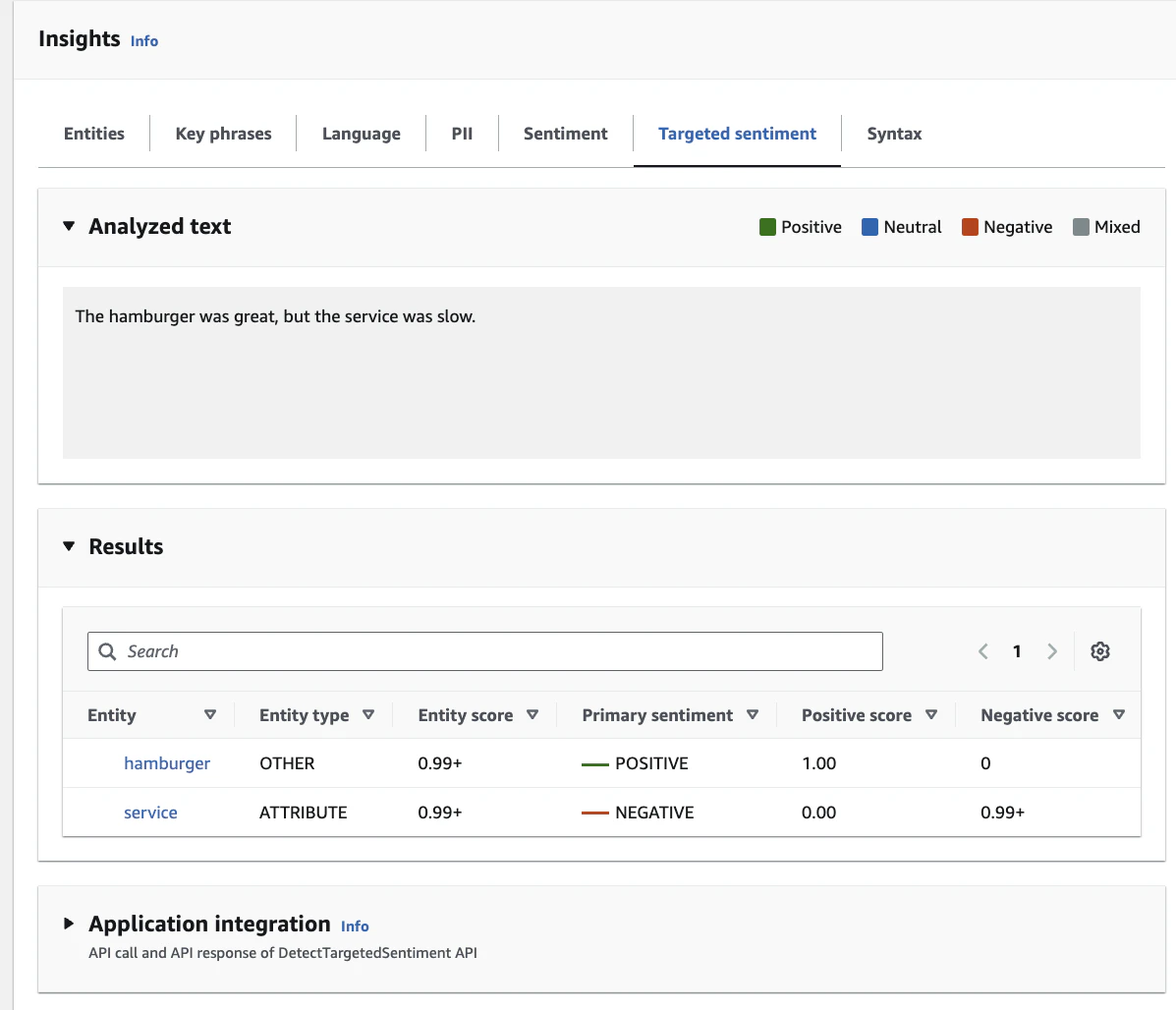
| エンティティ | タイプ | スコア | 感情 |
|---|---|---|---|
| hamburger | OTHER | 0.99+ | POSITIVE |
| service | ATTRIBUTE | 0.99+ | NEGATIVE |
感情分析 vs. ターゲット感情分析の使い分け
- 感情分析: レビュー全体が肯定的か否定的かをざっくり判定したい場合
- ターゲット感情分析: 「商品は良いけどサービスが悪い」のように、 具体的にどの要素が良い/悪いか を知りたい場合
3-7. 構文解析(Syntax Analysis)
各単語を 品詞(Part of Speech) に分類します。
これも日本語対応していないので、デフォルトの英語でやってみます。
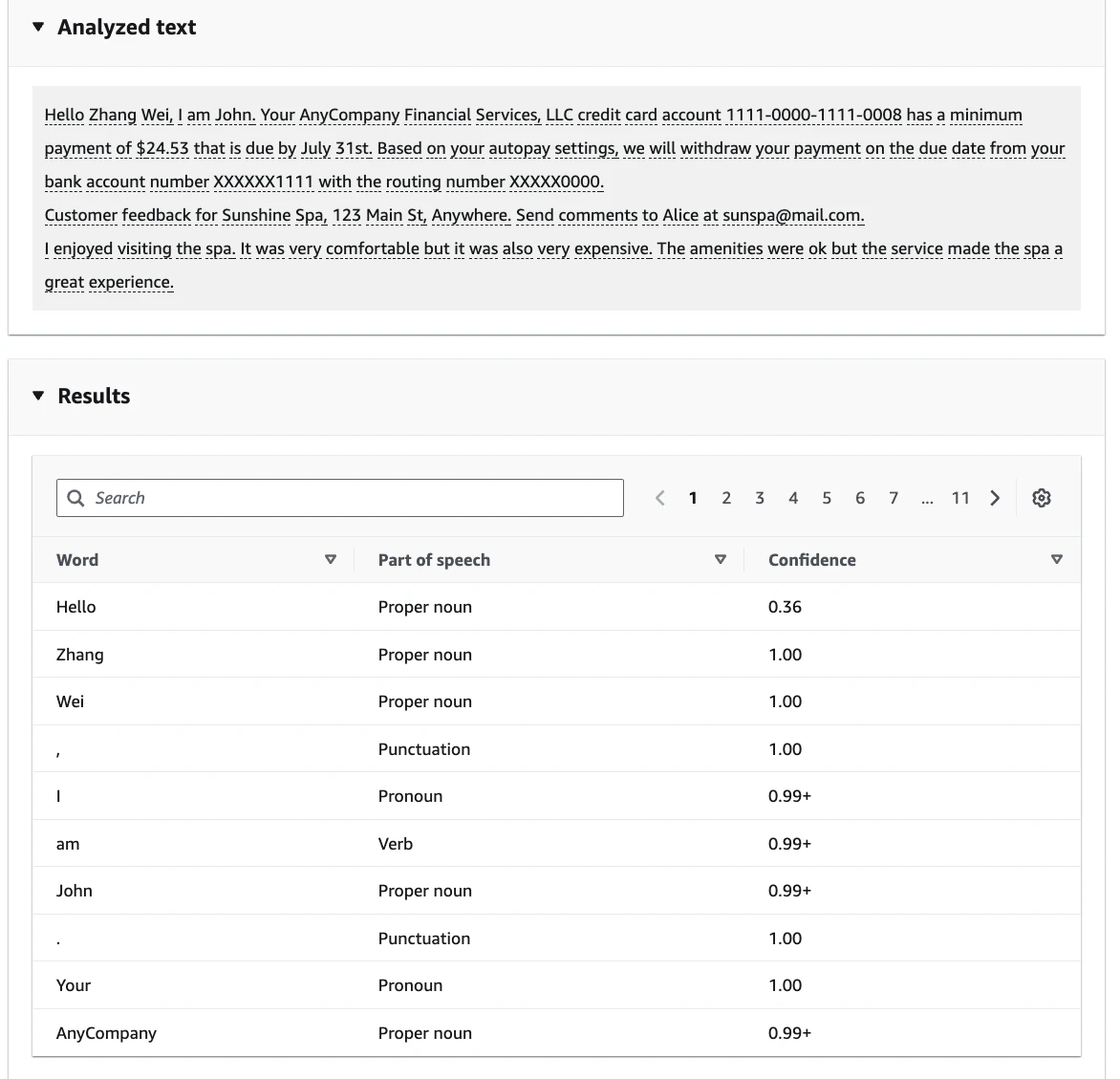
| 品詞タグ | 説明 |
|---|---|
| Proper noun | 固有名詞 |
| Verb | 動詞 |
| Adjective | 形容詞 |
| Pronoun | 代名詞 |
| Punctuation | 句読点 |
4. カスタム機能
4-1. カスタム分類(Custom Classification)
事前定義されたカテゴリにドキュメントを 自動分類するカスタムモデル を構築できます。
ユースケース例
| 業界 | 分類内容 |
|---|---|
| カスタマーサポート | 問い合わせを「アカウント」「払い戻し」「苦情」に分類 |
| 法務 | 契約書を「秘密保持契約」「業務委託契約」「売買契約」に分類 |
| メディア | ニュース記事を「政治」「経済」「スポーツ」「テクノロジー」に分類 |
トレーニングデータの形式
CSV形式でラベルとテキストのペアを用意します。
ACCOUNT_QUESTION,"パスワードをリセットしたいのですが、どうすればいいですか?"
TICKET_REFUND,"先日購入したチケットをキャンセルしたいです。返金は可能ですか?"
COMPLAINT,"サービスの対応が遅すぎます。改善してください。"
AutoMLによる自動モデル構築
カスタム分類ではAutoML(自動機械学習)が使用されます。利用者がトレーニングデータを提供するだけで、最適なモデルが自動的に構築されます。機械学習の専門知識は不要です。
4-2. カスタムエンティティ認識(Custom Entity Recognition)
ドメイン固有の用語やコードを カスタムエンティティ として抽出するモデルを構築できます。
| 業界 | カスタムエンティティの例 |
|---|---|
| 保険 | 保険証券番号(例:456-YQT) |
| 製造 | 部品番号(例:PART-A0012) |
| 金融 | ローン申請番号 |
| ヘルスケア | 患者ID |
4-3. トピックモデリング(Topic Modeling)
Amazon S3に保存された 大量のドキュメントをトピック(話題)ごとに自動クラスタリング します。非同期のバッチ処理として実行されます。なお、トピックモデリングは2026年4月30日以降、新規アカウントへの提供が終了予定です。
| 出力 | 説明 |
|---|---|
| トピックグループ | 関連キーワードのグループ(各キーワードに重みスコア付き) |
| ドキュメント-トピック対応 | 各ドキュメントがどのトピックに属するかのマッピング |
4-4. フライホイール(Flywheel)
カスタムモデルの バージョン管理とトレーニングプロセスを自動化 する仕組みです。新しいデータが蓄積されるたびに、モデルの再トレーニング・評価を効率的に実行できます。
5. 信頼と安全機能
5-1. 毒性検出(Toxicity Detection)
テキスト内の 有害コンテンツ を検出します。オンラインプラットフォームのコンテンツモデレーションに活用できます。
5-2. プロンプト安全性分類(Prompt Safety Classification)
生成AI(LLM)への入力プロンプトが 安全かどうかを二値分類(安全/安全でない) するAPIです。Bedrockなどの生成AIサービスと組み合わせて、 不正なプロンプトをフィルタリング する用途に使えます。なお、プロンプト安全性分類は2026年4月30日以降、新規アカウントへの提供が終了予定です。
6. 料金体系
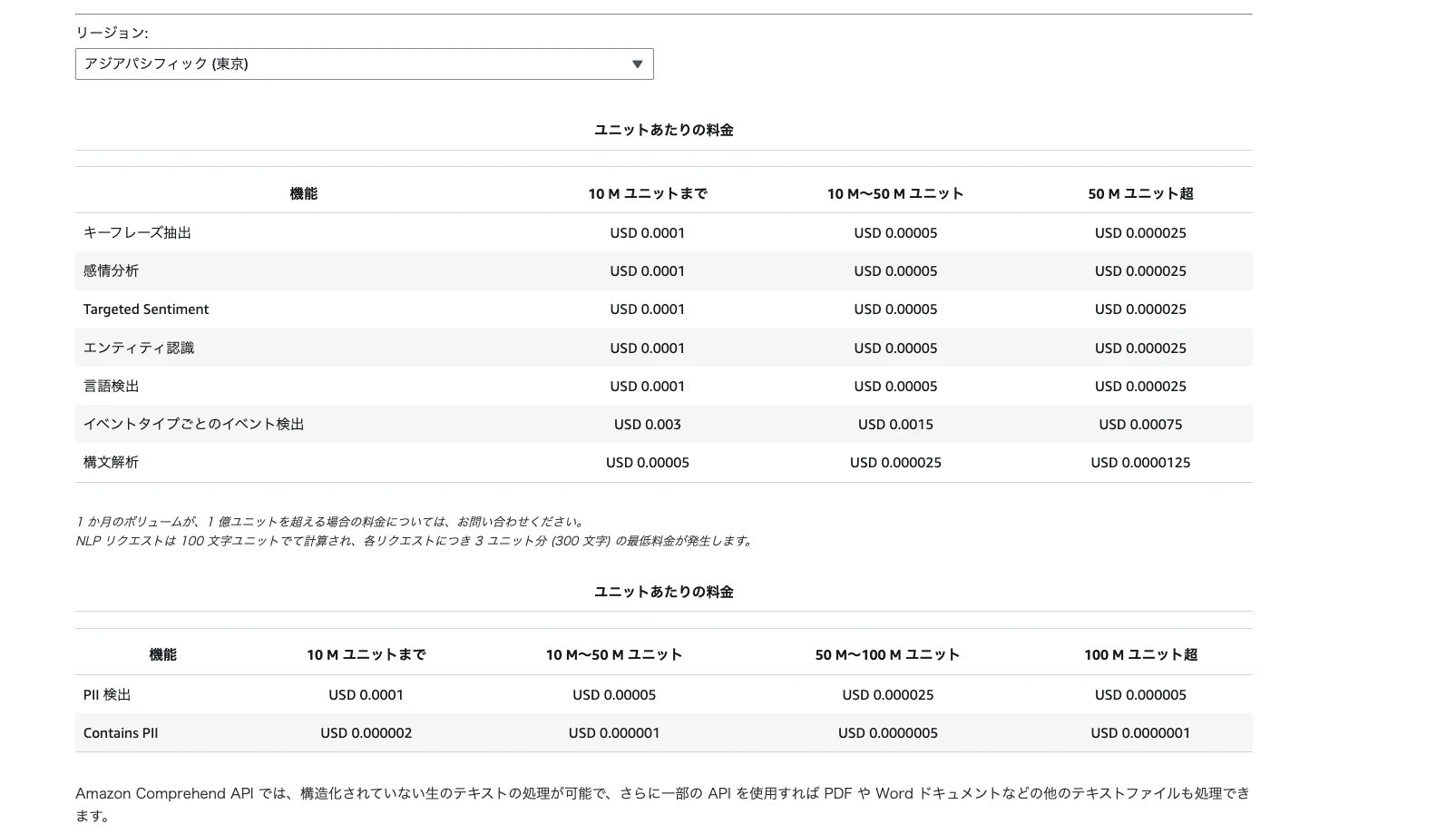
6-1. 料金の計算単位
Amazon Comprehendの料金は、 ユニット単位 で計算されます。
| 項目 | 値 |
|---|---|
| 1ユニット | 100文字 |
| 最低課金 | 1リクエストあたり3ユニット(300文字) |
つまり、550文字のテキストを分析する場合は 6ユニット (550 ÷ 100 = 5.5 → 切り上げて6)として課金されます。
6-2. 組み込みNLP APIの料金
| API | 料金(1ユニットあたり) |
|---|---|
| キーフレーズ抽出 | $0.0001 |
| 感情分析 | $0.0001 |
| ターゲット感情分析 | $0.0001 |
| エンティティ認識 | $0.0001 |
| 言語検出 | $0.0001 |
| 構文解析 | $0.00005 |
料金の具体例
10,000件のカスタマーレビュー(各550文字)に感情分析を実行する場合:
- リクエストあたりのユニット数:6
- 合計ユニット数:10,000 × 6 = 60,000
- 合計コスト:60,000 × $0.0001 = $6.00
6-3. PII関連APIの料金
| API | 料金(1ユニットあたり) |
|---|---|
| PII検出(DetectPII) | $0.0001 |
| PII有無判定(ContainsPII) | $0.000002 |
6-4. 信頼と安全APIの料金
| API | 料金(1ユニットあたり) |
|---|---|
| 毒性検出 | $0.0001 |
| プロンプト安全性分類 | $0.0001 |
6-5. カスタム機能の料金
| 項目 | 料金 |
|---|---|
| 非同期推論 | $0.0005 / ユニット |
| 同期推論(エンドポイント) | $0.0005 / 秒 / 推論ユニット(IU) |
| モデルトレーニング | $3.00 / 時間 |
| モデル管理(ストレージ) | $0.50 / 月 |
同期推論エンドポイントの注意
リアルタイム推論用のエンドポイントは、 起動してから削除するまで継続的に課金されます。リクエストの有無に関わらず料金が発生するため、使用しない時間帯はエンドポイントを削除しましょう。1推論ユニット(IU)で100文字/秒のスループットが提供されます。
6-6. トピックモデリングの料金
| 項目 | 料金 |
|---|---|
| 最初の100MB | $1.00(均一料金) |
| 100MBを超える分 | $0.004 / MB |
6-7. 無料利用枠
| 項目 | 無料枠 |
|---|---|
| 組み込みNLP API | 1 APIあたり月 50,000ユニット(500万文字) |
| トピックモデリング | 1MBまでのジョブ5件 |
| 対象期間 | 初回リクエストから 12か月間 |
| カスタム機能 | 無料利用枠 なし |
7. 対応言語とリージョン
7-1. 対応言語
| 機能カテゴリ | 対応言語 |
|---|---|
| エンティティ認識・キーフレーズ抽出・感情分析 | 英語、スペイン語、フランス語、ドイツ語、イタリア語、ポルトガル語、日本語、韓国語、ヒンディー語、アラビア語、中国語(簡体字)、中国語(繁体字) |
| 言語検出 | 100以上の言語 |
| PII検出 | 英語、スペイン語 |
| ターゲット感情分析 | 英語のみ |
| 構文解析 | 英語、スペイン語、フランス語、ドイツ語、イタリア語、ポルトガル語(6言語) |
| カスタム分類・エンティティ | 英語、スペイン語、フランス語、ドイツ語、イタリア語、ポルトガル語(プレーンテキスト) |
日本語対応の注意点
日本語は感情分析・エンティティ認識・キーフレーズ抽出に対応していますが、 構文解析 と カスタム分類・エンティティ認識 は欧米6言語のみの対応です(2026年4月時点)。 ターゲット感情分析 は英語のみ、 PII検出 は英語とスペイン語のみです。日本語テキストのPII処理が必要な場合は、正規表現や他のNLPツールとの併用を検討してください。
7-2. 利用可能リージョン
Amazon Comprehendは主要リージョンで利用可能です。
| リージョン |
|---|
| 米国東部(バージニア北部)us-east-1 |
| 米国東部(オハイオ)us-east-2 |
| 米国西部(オレゴン)us-west-2 |
| 欧州(アイルランド)eu-west-1 |
| 欧州(ロンドン)eu-west-2 |
| 欧州(フランクフルト)eu-central-1 |
| アジアパシフィック(シドニー)ap-southeast-2 |
| アジアパシフィック(東京)ap-northeast-1 |
| アジアパシフィック(ソウル)ap-northeast-2 |
| アジアパシフィック(ムンバイ)ap-south-1 |
| カナダ(中部)ca-central-1 |
東京リージョン対応
Amazon Comprehendは 東京リージョン(ap-northeast-1) で利用可能です。日本語テキストの分析もレイテンシーの低い環境で実行できます。
おわりに
ここまでお読みいただきありがとうございます。
今回は、Amazon Comprehendの 概要・主要機能・料金体系・対応言語を解説しました。
次回#2では、実際に AWS CLIとPython(boto3)を使ってComprehendのテキスト分析を実行します。感情分析・エンティティ抽出・キーフレーズ抽出をハンズオン形式で体験しましょう。
ではまた、お会いしましょう。