はじめに
こんばんは、mirukyです。
Amazon Bedrock シリーズ第3回です。
今回はいよいよ、Bedrockの中でも特に実務での活用頻度が高いKnowledge Bases(ナレッジベース) を使って、社内データに基づいたAIチャットシステム(RAG) を構築します。
RAG(Retrieval-Augmented Generation:検索拡張生成)とは、AIが回答を生成する前に、まず社内文書やFAQなどのデータソースから関連情報を検索し、その情報を根拠にして回答する仕組みです。これにより、AIが学習していない社内固有の情報にも正確に回答できるようになります。
Amazon Connectシリーズ#3でもKnowledge Basesを使いましたが、今回はBedrock単体でより詳しく構築手順を解説します。
出典:Amazon Bedrock でデータソースに接続してナレッジベースを作成する - AWS
目次
- RAGとKnowledge Basesの仕組み
- 今回のシステム構成
- S3バケットの作成とドキュメントの準備
- ナレッジベースの作成
- チャンク戦略の選択
- コンソールでのテスト
- APIからナレッジベースを呼び出す
- 料金について
- おわりに
1. RAGとKnowledge Basesの仕組み
1-1. RAGの処理フロー
RAGは以下の流れで動作します。

1-2. Knowledge Basesが自動化してくれること
従来、RAGを構築するには「ドキュメントの前処理」「チャンク分割」「ベクトル化」「ベクトルストアの管理」「検索ロジックの実装」をすべて自力で行う必要がありました。
Knowledge Basesは、これらの処理をフルマネージドで自動化します。
| 処理 | 従来(手動構築) | Knowledge Bases |
|---|---|---|
| ドキュメントの取り込み | S3からの読み取り処理を自前実装 | S3と自動連携 |
| テキスト抽出 | PDF/Word等のパーサーを自前実装 | 自動抽出 |
| チャンク分割 | 分割ロジックを自前実装 | 複数戦略から選択するだけ |
| ベクトル化 | 埋め込みモデルの呼び出しを自前実装 | 自動実行 |
| ベクトルストア管理 | OpenSearch等の構築・運用 | マネージド(S3 Vectors等) |
| 検索 + 回答生成 | 検索→プロンプト構築→LLM呼び出しを自前実装 | RetrieveAndGenerate APIで一発 |
2. 今回のシステム構成

| サービス | 役割 |
|---|---|
| Amazon S3 | ドキュメントの格納 |
| Amazon Bedrock Knowledge Bases | RAG基盤(チャンク分割・ベクトル化・検索・回答生成) |
| Titan Text Embeddings V2 | ドキュメントのベクトル化 |
| S3 Vectors | ベクトルデータの格納・検索 |
| Claude Opus 4.6 | 検索結果をもとに回答を生成 |
ベクトルストアの選択肢
Knowledge Basesでは以下のベクトルストアが選択可能です。
| ベクトルストア | 特徴 | 向いている用途 |
|---|---|---|
| S3 Vectors(今回使用) | マネージド・低コスト・運用負担最小 | PoC、中小規模、運用コスト重視 |
| OpenSearch Serverless | 高速・ハイブリッド検索対応 | 大規模・リアルタイム要件 |
| Aurora PostgreSQL | RDBとの統合 | 既存DB活用 |
| Pinecone | 外部SaaS | マルチクラウド |
今回は最もシンプルなS3 Vectorsを使用します。
3. S3バケットの作成とドキュメントの準備
3-1. S3バケットの作成
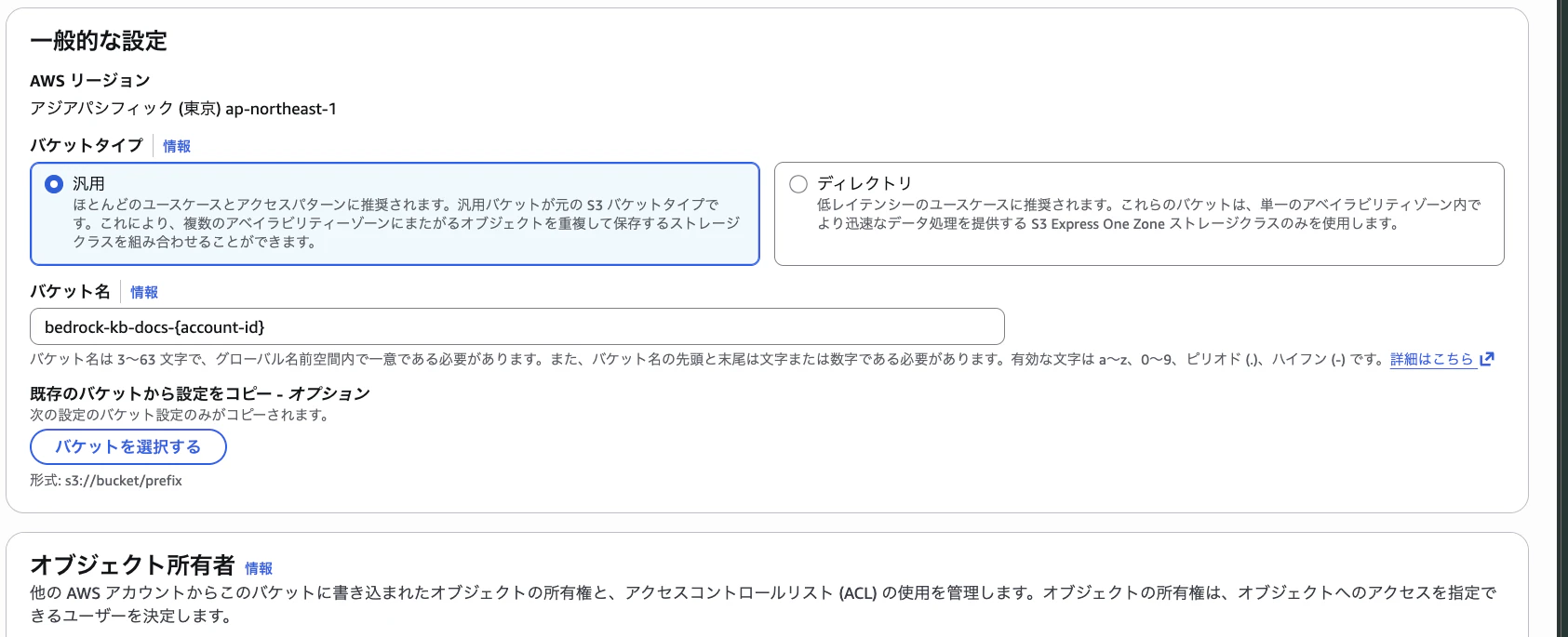
- AWSマネジメントコンソール(東京リージョン)で S3 を開く
- 「バケットを作成」 をクリック
| 設定項目 | 値 |
|---|---|
| バケット名 |
bedrock-kb-docs-{account-id}(一意な名前) |
| リージョン | アジアパシフィック(東京) |
| その他 | デフォルトのまま |
3.「バケットを作成」 をクリック
3-2. サンプルドキュメントの作成
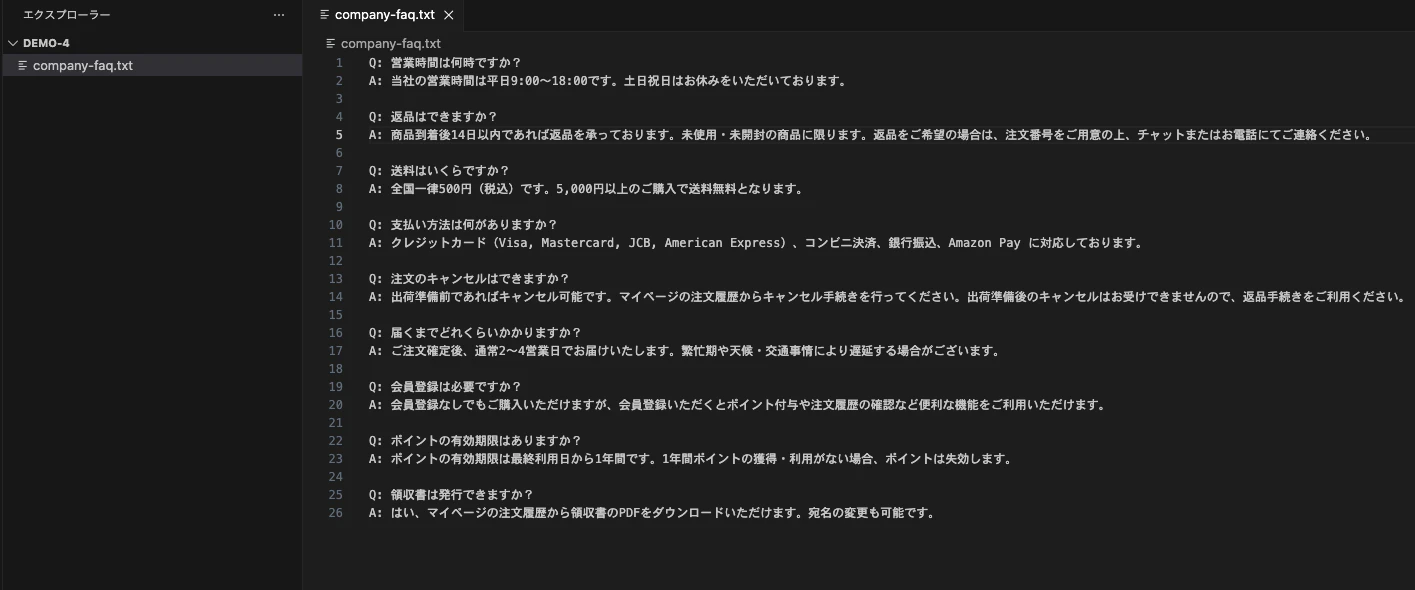
AIが参照するFAQドキュメントを作成します。以下の内容でテキストファイルを作成してください。
ファイル名:company-faq.txt
Q: 営業時間は何時ですか?
A: 当社の営業時間は平日9:00〜18:00です。土日祝日はお休みをいただいております。
Q: 返品はできますか?
A: 商品到着後14日以内であれば返品を承っております。未使用・未開封の商品に限ります。返品をご希望の場合は、注文番号をご用意の上、チャットまたはお電話にてご連絡ください。
Q: 送料はいくらですか?
A: 全国一律500円(税込)です。5,000円以上のご購入で送料無料となります。
Q: 支払い方法は何がありますか?
A: クレジットカード(Visa, Mastercard, JCB, American Express)、コンビニ決済、銀行振込、Amazon Pay に対応しております。
Q: 注文のキャンセルはできますか?
A: 出荷準備前であればキャンセル可能です。マイページの注文履歴からキャンセル手続きを行ってください。出荷準備後のキャンセルはお受けできませんので、返品手続きをご利用ください。
Q: 届くまでどれくらいかかりますか?
A: ご注文確定後、通常2〜4営業日でお届けいたします。繁忙期や天候・交通事情により遅延する場合がございます。
Q: 会員登録は必要ですか?
A: 会員登録なしでもご購入いただけますが、会員登録いただくとポイント付与や注文履歴の確認など便利な機能をご利用いただけます。
Q: ポイントの有効期限はありますか?
A: ポイントの有効期限は最終利用日から1年間です。1年間ポイントの獲得・利用がない場合、ポイントは失効します。
Q: 領収書は発行できますか?
A: はい、マイページの注文履歴から領収書のPDFをダウンロードいただけます。宛名の変更も可能です。
3-3. ドキュメントのアップロード

作成した company-faq.txt をS3バケットにアップロードします。
対応ファイル形式
Knowledge Basesでは、txt, md, html, doc, docx, csv, xls, xlsx, pdf 等に対応しています。PDFを使用する場合は、テキストレイヤーが含まれている(OCR済み)必要があります。最大ファイルサイズは50MBです。
4. ナレッジベースの作成
4-1. ナレッジベース作成画面を開く
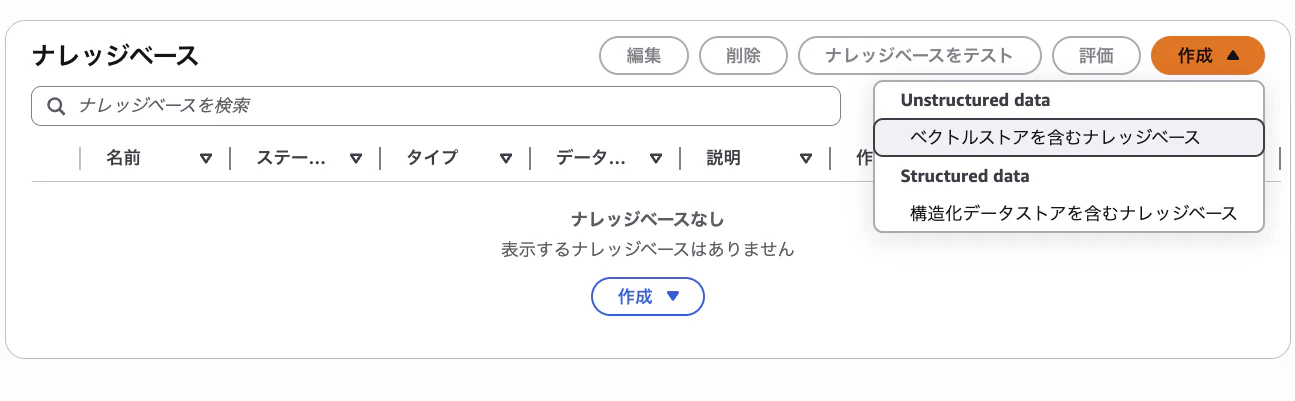
- AWSマネジメントコンソール(東京リージョン)で Amazon Bedrock を開く
- 左側ペインの 「ナレッジベース」 を選択
- 「作成」 → 「ベクトルストアを含むナレッジベース」 を選択
4-2. 基本設定
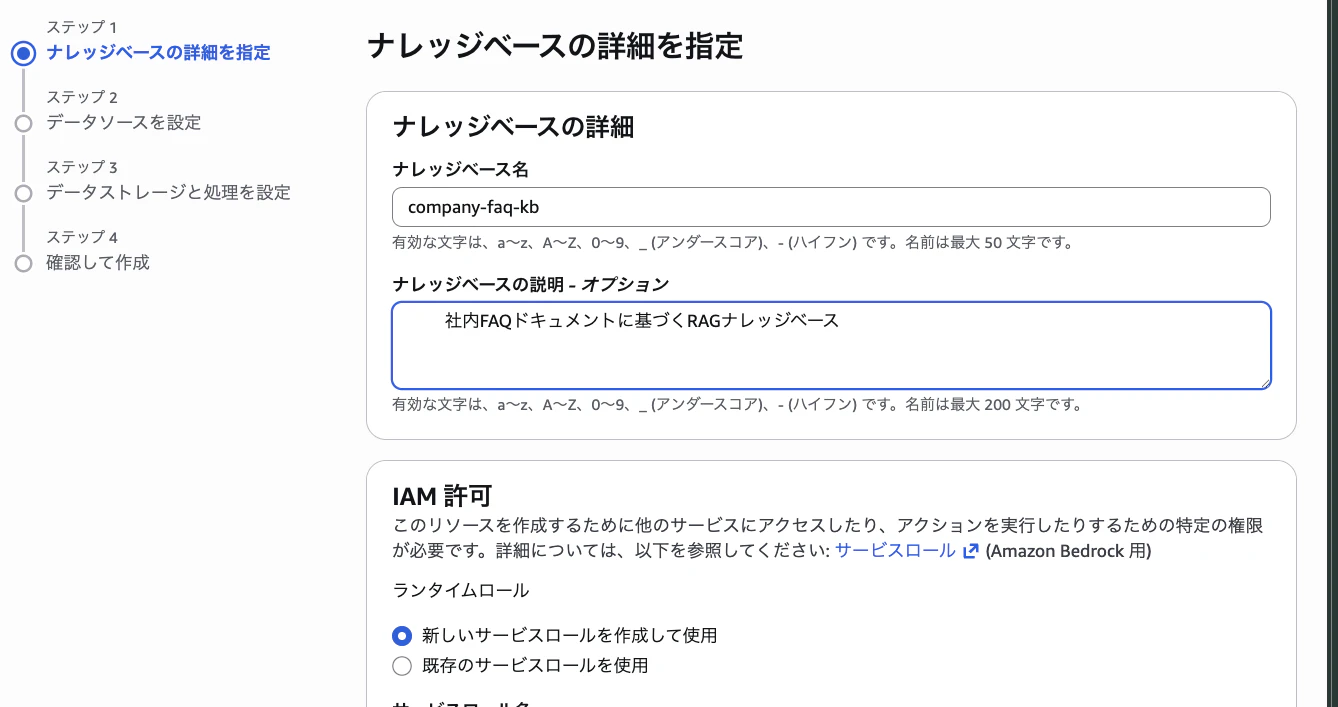
| 設定項目 | 値 |
|---|---|
| ナレッジベース名 | company-faq-kb |
| 説明 | 社内FAQドキュメントに基づくRAGナレッジベース |
| IAMロール | 新しいサービスロールを作成して使用 |
| データソースを選択 | Amazon S3 |
4-3. データソースの設定
| 設定項目 | 値 |
|---|---|
| データソース名 | faq-s3-source |
| S3 URI | 先ほど作成したバケットのURI(例:s3://bedrock-kb-docs-123456789012) |
S3 URIにはバケットのURIを指定してください
ファイル単体のURIではなく、バケットまたはプレフィックスのURIを指定します。
- ◯ :
s3://bedrock-kb-docs-123456789012 - ✕ :
s3://bedrock-kb-docs-123456789012/company-faq.txt
4-4. 埋め込みモデルとベクトルストアの設定
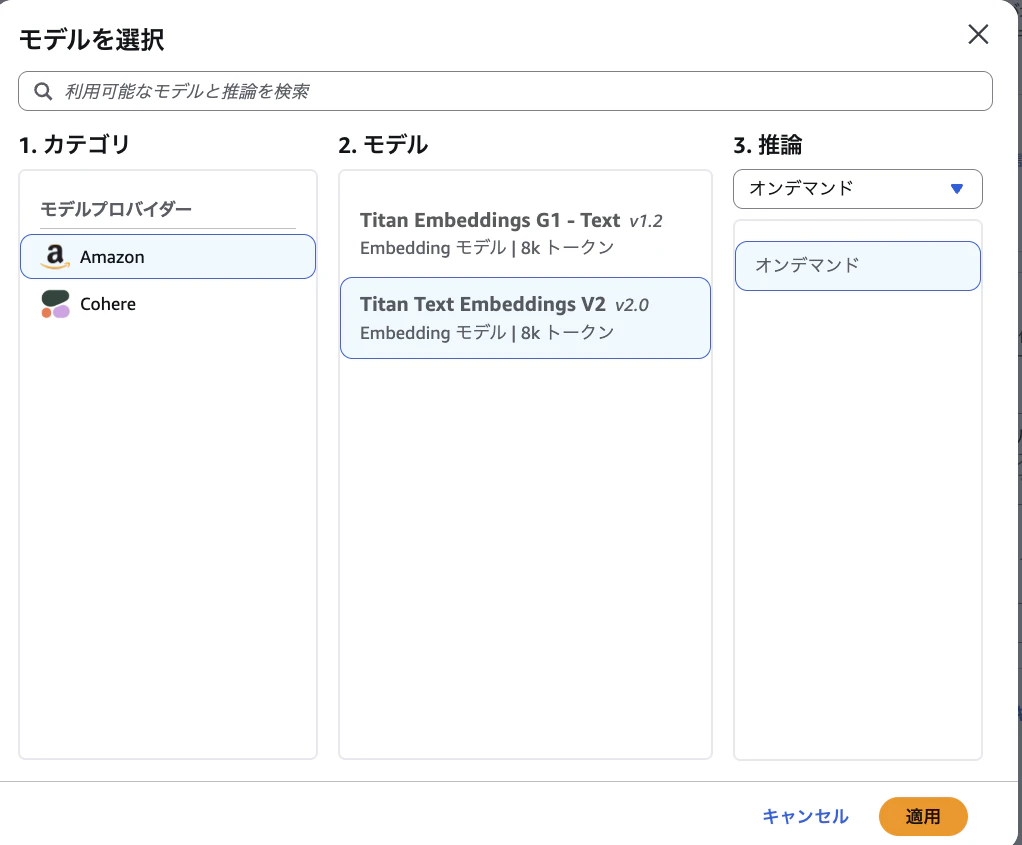
| 設定項目 | 値 |
|---|---|
| 埋め込みモデル | Titan Text Embeddings V2 |
| ベクトルストア | 新しいベクトルストアをクイック作成 |
| ベクトルストア - 新規 | Amazon S3 Vectors |
Titan Text Embeddings V2を選ぶ理由
東京リージョンで利用可能で、多言語(日本語含む)に対応した埋め込みモデルです。1024次元のベクトルを生成し、RAGの検索精度が高いことで評価されています。
4-5. ナレッジベースの作成と同期

- 設定完了後、「データソース」内のリンク をクリック
- データソースの 「同期」 をクリック
- 同期が完了するまで数分待ちます
同期処理では、内部的に以下が自動実行されます。
S3のドキュメント → テキスト抽出 → チャンク分割 → ベクトル化 → S3 Vectorsに保存
同期は手動で実行する必要があります
S3にドキュメントを追加・更新した場合は、再度「同期」を実行しないとナレッジベースに反映されません。
5. チャンク戦略の選択
ナレッジベース作成時に、ドキュメントの分割方法(チャンク戦略)を選択できます。
5-1. チャンク戦略の比較
| 戦略 | 説明 | 向いている用途 |
|---|---|---|
| デフォルト | 約300トークンごとに自動分割 | 一般的な用途(今回使用) |
| 固定サイズ | チャンクサイズとオーバーラップを指定 | 技術文書、契約書 |
| 階層型 | 親チャンク(広い文脈)と子チャンク(詳細)の2層構造 | FAQ、マニュアル |
| セマンティック | 意味的な類似度で分割箇所を判定 | 自然文が多い文書 |
| チャンキングなし | ドキュメントをそのまま1チャンクとして扱う | 短いドキュメント |
チャンク戦略は作成後に変更できません
チャンク戦略と埋め込みモデルはデータソース作成時のみ指定可能です。後から変更する場合は、データソースの再作成が必要になります。本番環境では事前に検証しておくことをおすすめします。
5-2. チャンク戦略の選び方
■ まず試したい → デフォルト(300トークン)
■ 精度を上げたい → 階層型 or セマンティック
■ 技術文書・長文 → 固定サイズ(オーバーラップ10〜20%推奨)
■ 短いFAQ → チャンキングなし or デフォルト
6. コンソールでのテスト
6-1. テスト画面を開く

- ナレッジベースの詳細画面で 「ナレッジベースをテスト」 をクリック
- 「取得と応答生成:データソースとモデル」 を選択
- 生成モデルとして Claude Opus 4.6(または利用可能なモデル)を選択
6-2. テスト①:FAQに回答がある質問
入力: 返品はできますか?
期待される回答:
商品到着後14日以内であれば返品を承っております。
未使用・未開封の商品に限ります。
返品をご希望の場合は、注文番号をご用意の上、チャットまたはお電話にてご連絡ください。
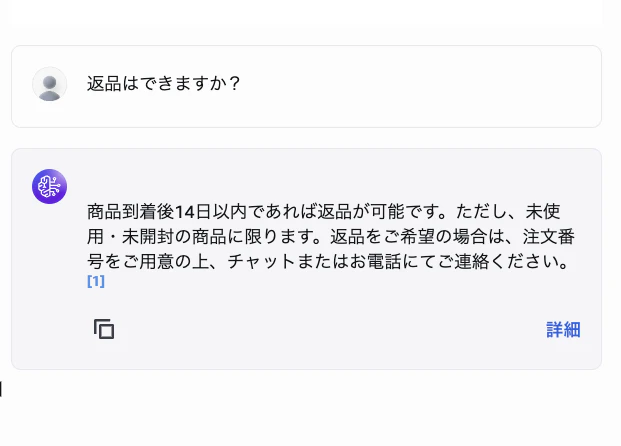
回答の下に参照元(ソース) が表示され、どのチャンクから情報を取得したかが確認できます。
6-3. テスト②:複合的な質問
入力: 返品したいのですが、送料はかかりますか?
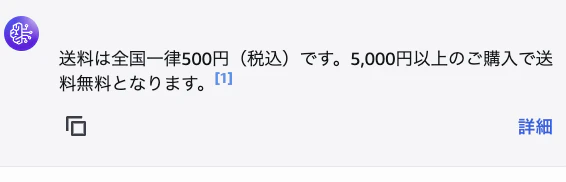
RAGにより、「返品」と「送料」の両方のチャンクが検索され、統合された回答が返ってきます。
6-4. テスト③:FAQにない質問
入力: 商品の在庫状況を教えてください。
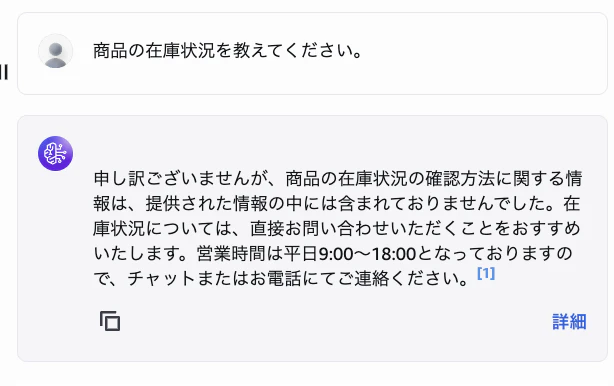
ナレッジベースに該当する情報がない場合、AIは「情報が見つかりません」といった旨の回答を返します。これがRAGの重要な特性で、ハルシネーション(事実と異なる回答の生成)を抑制します。
7. APIからナレッジベースを呼び出す
7-1. RetrieveAndGenerate API
検索と回答生成を1回のAPI呼び出しで実行できます。
import boto3
client = boto3.client("bedrock-agent-runtime", region_name="ap-northeast-1")
response = client.retrieve_and_generate(
input={"text": "返品はできますか?"},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": "XXXXXXXXXX", # ナレッジベースID
"modelArn": "arn:aws:bedrock:ap-northeast-1::foundation-model/anthropic.claude-opus-4-6",
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"numberOfResults": 5
}
}
}
}
)
print(response["output"]["text"])
# 参照元チャンクの確認
for citation in response.get("citations", []):
for ref in citation.get("retrievedReferences", []):
print(f" 参照元: {ref['location']['s3Location']['uri']}")
7-2. Retrieve API(検索のみ)
検索だけを実行し、回答生成は自前で行いたい場合に使います。
response = client.retrieve(
knowledgeBaseId="XXXXXXXXXX",
retrievalQuery={"text": "返品はできますか?"},
retrievalConfiguration={
"vectorSearchConfiguration": {
"numberOfResults": 5
}
}
)
for result in response["retrievalResults"]:
print(f"スコア: {result['score']}")
print(f"テキスト: {result['content']['text']}")
print("---")
RetrieveAndGenerate と Retrieve の使い分け
| API | 用途 |
|---|---|
| RetrieveAndGenerate | 検索+回答生成を一括で行いたい場合(一般的なRAGチャット) |
| Retrieve | 検索結果だけを取得し、プロンプトや回答生成を自分でカスタマイズしたい場合 |
独自のプロンプトテンプレートを使いたい場合や、検索結果のフィルタリングを行いたい場合はRetrieve APIが適しています。
8. 料金について
| サービス | 料金 | 備考 |
|---|---|---|
| S3 ストレージ | $0.025/GB/月 | ドキュメント格納 |
| S3 Vectors | ベクトル数に応じた従量課金 | ベクトルデータの格納・検索 |
| Titan Embeddings V2 | トークン数に応じた従量課金 | 同期時のベクトル化 |
| 生成モデル(Claude等) | トークン数に応じた従量課金 | 回答生成時 |
同期のたびに埋め込みモデルの料金が発生します
S3にドキュメントを追加・更新して再同期するたびに、変更分のベクトル化に対してTitan Embeddings V2の利用料金が発生します。大量のドキュメントを頻繁に更新する場合はコストに注意してください。
最新の料金は公式ページをご確認ください。
出典:Amazon Bedrock Pricing - AWS
ハンズオン終了後のリソース削除を忘れずに
・ナレッジベース
・S3バケット(ドキュメント用・ベクトル用)
・自動作成されたIAMロール
生成モデルの料金に注意
本記事で使用しているClaude Opus 4.6は、入力 $5.00 / 出力 $25.00(100万トークンあたり)とAnthropicの最上位モデルです。コストを抑えたい場合は、Claude Sonnet 4.6(入力 $3.00 / 出力 $15.00)やClaude 3 Haiku(入力 $0.25 / 出力 $1.25)への差し替えも検討してください。modelArn を変更するだけで切り替えられます。
9. おわりに
ここまでお読みいただきありがとうございます。
今回は、Amazon Bedrock Knowledge Basesを使って、社内FAQデータに基づくRAGチャットシステムを構築しました。
次回#4では、Bedrock Agentsを使って、ナレッジベース検索だけでなく外部APIやLambda関数を自律的に呼び出すAIエージェントを構築します。
ではまた、お会いしましょう。
参考リンク
Amazon Bedrock Knowledge Bases 公式ドキュメント
- Amazon Bedrock でデータソースに接続してナレッジベースを作成する - AWS
- ナレッジベースのコンテンツのチャンキングの仕組み - AWS
- S3 Vectors と Amazon Bedrock ナレッジベースを使用する - AWS
- Amazon Bedrock Pricing - AWS