はじめに

こんばんは、mirukyです。
2026年4月7日、Anthropicが新型AIモデル Claude Mythos Preview(ミトス プレビュー) を発表しました。サイバーセキュリティに特化した業界横断イニシアチブ Project Glasswing の一環として限定リリースされたこのモデルは、主要OSやWebブラウザのすべてからゼロデイ脆弱性を発見する能力を持ち、従来モデルとは次元の異なる性能を示しています。
この記事では、公式発表とFrontier Red Teamブログの一次ソースに基づき、Mythos Previewの性能データ、発見された脆弱性の具体例、そしてProject Glasswingの全体像をコンパクトにまとめます。
目次
- Claude Mythos Previewとは
- ベンチマークで見る「桁外れ」の性能
- 発見されたゼロデイ脆弱性
- Project Glasswingと限定リリースの背景
1. Claude Mythos Previewとは
1-1. モデルの概要

Claude Mythos Previewは、Anthropicが開発した最新のフロンティアモデルです。「Mythos」は古代ギリシャ語で「物語」「発話」を意味します。
| 項目 | 内容 |
|---|---|
| 発表日 | 2026年4月7日 |
| モデル名 | Claude Mythos Preview |
| モデルの位置づけ | フロンティアモデル(Opus上位) |
| 一般公開 | 予定なし(招待制リサーチプレビュー) |
| 料金(パートナー向け) | 入力 $25 / 出力 $125(100万トークンあたり) |
| 提供プラットフォーム | Claude API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry |
参考までに、現行のClaude Opus 4.6は入力 $5 / 出力 $25であり、Mythos Previewは 5倍の価格設定 となっています。
Mythos Previewはサイバーセキュリティに「特化して訓練」されたわけではありません。Anthropicによれば、コード、推論、自律性の汎用的な改善の結果として、セキュリティ能力が 自然に出現した とのことです。
1-2. コードネーム「Capybara」からの経緯
Mythos Previewの存在は、2026年3月にFortune誌のスクープで初めて明らかになりました。Anthropicが公開データレイク上のキャッシュにドラフトのブログ記事を残してしまい、セキュリティ研究者がこれを発見したのが発端です。
当時のコードネームは 「Capybara」 で、流出した文書には「Opusモデルよりも大規模かつ高性能な新しいモデル階層」「これまで開発した中で最も強力なAIモデル」と記載されていました(Fortune報道より)。
2. ベンチマークで見る「桁外れ」の性能
Anthropicは、Mythos PreviewとClaude Opus 4.6の比較ベンチマークを公開しています。
2-1. サイバーセキュリティ
| ベンチマーク | Mythos Preview | Opus 4.6 | Sonnet 4.6 |
|---|---|---|---|
| CyberGym(pass@1) | 83% | 67% | 65% |
| Cybench(pass@1) | 100% | — | — |
CyberGymは1,507件の実在するOSS脆弱性を対象とした再現評価で、CTF形式のCybenchよりも実践的とされています。Mythos PreviewはCybenchの全35問を pass@1で100%正解 し、完全に飽和しています。Anthropicは「CTFベンチマークではもはやフロンティアモデルの能力差を測れない」として、今後はCyberGymや実ソフトウェアへの適用で能力を評価する方針です。
2-2. エージェント型コーディング
| ベンチマーク | Mythos Preview | Opus 4.6 | 差分 |
|---|---|---|---|
| SWE-bench Verified | 93.9% | 80.8% | +13.1pt |
| SWE-bench Pro | 77.8% | 53.4% | +24.4pt |
| Terminal-Bench 2.0 | 82.0% | 65.4% | +16.6pt |
| SWE-bench Multimodal(内部) | 59.0% | 27.1% | +31.9pt |
| SWE-bench Multilingual | 87.3% | 77.8% | +9.5pt |
2-3. 推論
| ベンチマーク | Mythos Preview | Opus 4.6 | 差分 |
|---|---|---|---|
| GPQA Diamond | 94.5% | 91.3% | +3.2pt |
| HLE(ツールなし) | 56.8% | 40.0% | +16.8pt |
| HLE(ツールあり) | 64.7% | 53.1% | +11.6pt |
2-4. エージェント検索とコンピュータ操作
| ベンチマーク | Mythos Preview | Opus 4.6 | 差分 |
|---|---|---|---|
| BrowseComp | 86.9% | 83.7% | +3.2pt |
| OSWorld-Verified | 79.6% | 72.7% | +6.9pt |
Anthropicは「SWE-benchの暗記スクリーンを適用済みで、マージンは維持される」としていますが、HLEについては「一部暗記の可能性がある」と注記しています。また、SWE-bench Multimodalは内部ベンチマークであり、外部での検証が行われていない点に留意が必要です。
特に SWE-bench Multimodal では31.9ポイント差、 SWE-bench Pro では24.4ポイント差と、一部のベンチマークでは圧倒的な開きが生じています。BrowseCompでは、Mythos Previewが 4.9倍少ないトークン数 でOpus 4.6を上回っている点も注目に値します。
2-5. GPT-5.4・Gemini 3.1 Proとのクロスモデル比較
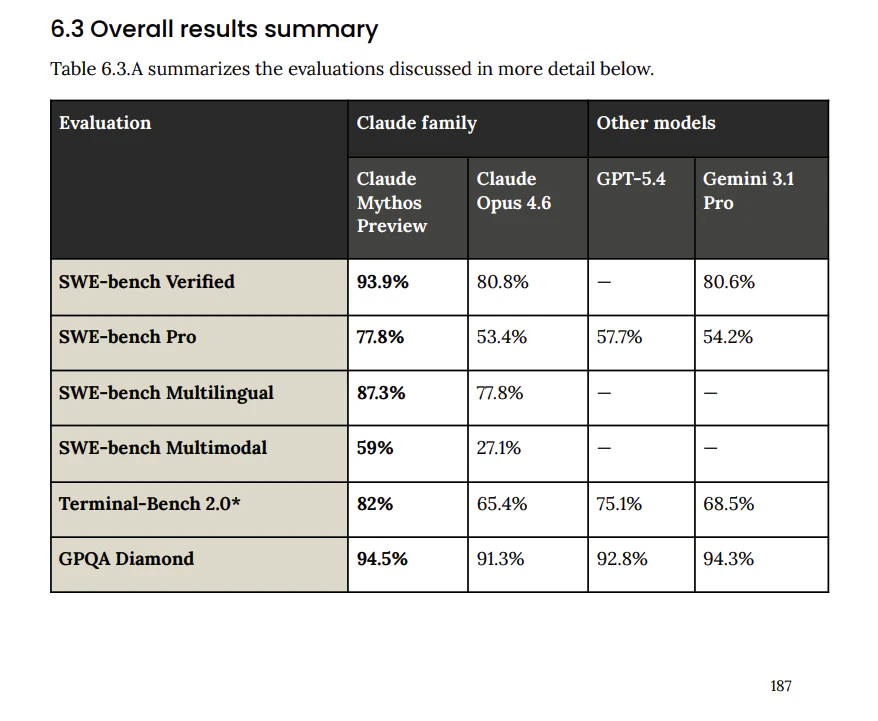
Anthropicが公開したシステムカード(全244ページ)には、OpenAIの GPT-5.4 およびGoogleの Gemini 3.1 Pro との直接比較データが含まれています。以下はシステムカードのTable 6.3.Aから抜粋した主要ベンチマークの結果です(「—」はデータ未公表)。
| ベンチマーク | Mythos Preview | Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Verified | 93.9% | 80.8% | — | 80.6% |
| SWE-bench Pro | 77.8% | 53.4% | 57.7% | 54.2% |
| Terminal-Bench 2.0 | 82.0% | 65.4% | 75.1%* | 68.5% |
| GPQA Diamond | 94.5% | 91.3% | 92.8% | 94.3% |
| MMMLU | 92.7% | 91.1% | — | 92.6%〜93.6% |
| USAMO 2026 | 97.6% | 42.3% | 95.2% | 74.4% |
| GraphWalks BFS(256K-1M) | 80.0% | 38.7% | 21.4% | — |
| HLE(ツールなし) | 56.8% | 40.0% | 39.8% | 44.4% |
| HLE(ツールあり) | 64.7% | 53.1% | 52.1% | 51.4% |
| OSWorld | 79.6% | 72.7% | 75.0% | — |
(*Terminal-Bench 2.0のGPT-5.4スコアはOpenAI独自のハーネスを使用しており、厳密な同条件比較ではない点に注意)
MMMUを除くほぼすべてのベンチマークで、Mythos Previewが首位を獲得しています。特筆すべきポイントを挙げます。
【数学(USAMO 2026)】
全米数学オリンピック2026で 97.6% を達成。GPT-5.4の95.2%を上回り、Opus 4.6の42.3%とは55ポイント以上の差が開いています。ただし、採点にはMathArenaの方法論に基づく3モデルの審査パネルが用いられ、うち2つがAnthropic製モデルであるため、バイアスの可能性がシステムカード内で言及されています。
【長文脈推論(GraphWalks BFS)】
256K〜1Mトークンのグラフ探索タスクで 80.0% を達成。GPT-5.4は21.4%にとどまり、約4倍の差が開いています。長大な文脈を正確に追跡する能力では圧倒的な優位性を示しています。
【科学推論(GPQA Diamond) 】
Mythos Previewの94.5%に対し、Gemini 3.1 Proが94.3%とわずか 0.2ポイント差 で肉薄しています。このベンチマークはモデル間の差が極めて小さく、飽和に近づいている可能性があります。
【多言語理解(MMMLU) 】
Gemini 3.1 Proが92.6%〜93.6%のレンジを示しており、Mythos Previewの92.7%と同等かそれ以上の可能性があります。Mythos Previewが明確に優位とは言い切れない数少ないベンチマークです。
マルチモーダル領域でも、CharXiv Reasoning(科学論文の図表推論)で 93.2% (Opus 4.6は78.9%)、LAB-Bench FigQA(生物医学図表読解)で 89.0% (Opus 4.6は75.1%)と大幅な改善を示しています。
競合モデルのスコアは各社が公開したシステムカードやベンチマークリーダーボードからの引用であり、評価条件が完全に統一されているわけではありません。また、MMMU-Pro(マルチモーダル推論)のスコアはデータ汚染の懸念からシステムカードでは意図的に省略されています。
3. 発見されたゼロデイ脆弱性
Frontier Red Teamブログによると、Mythos Previewは 主要OSとWebブラウザのすべて からゼロデイ脆弱性を発見し、その多くについてエクスプロイト(攻撃コード)の自律生成にも成功しています。
3-1. 代表的な発見事例

OpenBSD:27年前のSACK脆弱性(パッチ済み)
TCP SACKの実装に潜んでいた符号付き整数オーバーフローのバグです。1998年に導入されたコードに存在し、リモートからOpenBSDマシンをクラッシュさせることが可能でした。2つのバグを連鎖させることで、通常は到達不可能なコードパスを発動させるという巧妙な手法です。
FFmpeg:16年前のH.264脆弱性(パッチ済み)
世界で最も使われる動画処理ライブラリFFmpegのH.264デコーダで、16ビットスライスカウンタと32ビットスライス番号の不一致を利用した境界外書き込みを発見しました。自動テストツールがこのコード行を 500万回以上 実行しているにもかかわらず、見つけられなかったバグです。
FreeBSD:17年前のNFSリモートコード実行(CVE-2026-4747)
FreeBSDのNFSサーバ実装にスタックバッファオーバーフローを発見し、ROPチェーンを構築して未認証の攻撃者がインターネット経由でroot権限を奪取できるエクスプロイトを生成しました。脆弱性の発見からエクスプロイト作成まで、 初回のプロンプト以降、一切の人間の介入なし で完了しています。
Linuxカーネル:権限昇格エクスプロイトチェーン
複数の脆弱性を自律的に連鎖させ、一般ユーザからroot権限への昇格を実現しました。KASLRバイパス、ヒープスプレー、構造体の上書きなど高度な手法を組み合わせています。
Webブラウザ:JITヒープスプレーによるサンドボックス脱出
主要Webブラウザすべてで脆弱性を発見しています。あるケースでは、Webページにアクセスするだけで攻撃者がOSカーネルに直接書き込めるレベルのエクスプロイトチェーンを構築しました。未パッチのため詳細は非公開で、SHA-3ハッシュによるコミットメント(後日検証可能な暗号学的証明)のみが公開されています。
上記以外にも、暗号ライブラリ(TLS、AES-GCM、SSH)の脆弱性、Webアプリケーションの認証バイパス、メモリセーフなVMMのゲストからホストへのメモリ破壊、スマートフォンのロック画面バイパスなど、多岐にわたる発見が報告されています。
3-2. 従来モデルとの決定的な差
従来のOpus 4.6は脆弱性の「発見」には優れていましたが、エクスプロイト開発の成功率は ほぼ0% でした。Frontier Red Teamブログは、この差を以下の具体的データで示しています。
Firefoxエクスプロイト開発の比較:
Firefox JavaScriptエンジンの脆弱性に対するエクスプロイト開発で、Opus 4.6が数百回の試行で 2回 しか成功しなかったのに対し、Mythos Previewは 181回 成功し、さらに29回でレジスタ制御を達成しています。
OSS-Fuzzコーパスでのクラッシュテスト:
約1,000のOSSリポジトリに対する評価で、Opus 4.6がティア3(制御フロー操作)に1件しか到達できなかったのに対し、Mythos Previewはティア1〜2で595件、ティア5(完全な制御フロー乗っ取り)で 10件 を達成しています。
3-3. 脆弱性発見のコスト
| 対象 | 概算コスト | 内容 |
|---|---|---|
| OpenBSD(1,000回スキャン) | 約 $20,000 | 数十件の脆弱性発見 |
| FFmpeg(数百回スキャン) | 約 $10,000 | 複数のコーデック脆弱性発見 |
| Linux N-dayエクスプロイト | $1,000〜$2,000 | 完全な権限昇格エクスプロイト構築 |
脆弱性の人間によるトリアージでは、198件のレビュー済み報告のうち 89% でClaude Mythos Previewの重大度評価と人間の専門家の評価が完全一致し、 98% が1段階以内の差に収まりました。
4. Project Glasswingと限定リリースの背景
4-1. パートナーとコミットメント

Project Glasswingは、Mythos Previewを活用してソフトウェアエコシステムの防御を強化する業界横断イニシアチブです。
パートナー組織(12社): AWS、Apple、Broadcom、Cisco、CrowdStrike、Google、JPMorganChase、Linux Foundation、Microsoft、NVIDIA、Palo Alto Networks、Anthropic
TechCrunchの報道によると、パートナー12社以外にも合計 40の組織 がMythos Previewへのアクセス権を持つとされています。
| 項目 | 内容 |
|---|---|
| 使用クレジット | パートナーに 1億ドル分 を提供 |
| OSS寄付 | Alpha-Omega/OpenSSFに250万ドル、Apache Foundationに150万ドル(計 400万ドル ) |
| 情報公開 | 90日以内に調査結果を公開レポートとして報告 |
| 脆弱性開示 | 協調的脆弱性開示(CVD)プロセスに従い、人間のトリアージを経て開示 |
4-2. なぜ一般公開しないのか

Anthropicは「短期的には攻撃者が優位になるリスクがある」と明言しています。Frontier Red Teamブログでは、以下のように述べられています。
"In the short term, this could be attackers, if frontier labs aren't careful about how they release these models. In the long term, we expect it will be defenders who will more efficiently direct resources and use these models to fix bugs before new code ever ships."
(短期的には、フロンティアラボがリリースに慎重でなければ攻撃者が優位になり得る。長期的には、防御側がこれらのモデルを効率的に活用し、新しいコードが出荷される前にバグを修正するようになると予想している)
セキュリティの均衡が保たれるまで一般リリースは行わず、次期Claude Opusモデルにサイバーセキュリティ向けの新しいセーフガードを搭載したうえで段階的に展開する計画です。正規のセキュリティ専門家向けには 「Cyber Verification Program」 という申請制プログラムも予定されています。
おわりに
ここまでお読みいただきありがとうございます。
Claude Mythos Previewは、SWE-bench VerifiedやUSAMO 2026などの主要ベンチマークでOpus 4.6を大幅に上回るだけでなく、GPT-5.4やGemini 3.1 Proとのクロスモデル比較でもほぼすべての項目で首位を獲得しています。27年間検出されなかったOpenBSDの脆弱性や、500万回のテスト実行で見つからなかったFFmpegのバグを自律的に発見し、エクスプロイトの自律生成という従来モデルではほぼ不可能だった領域にまで踏み込んでいます。
一方で、GPQA DiamondではGemini 3.1 Proと0.2ポイント差、MMMUでは同等かやや劣る可能性もあり、すべてで圧勝しているわけではありません。ベンチマークの評価条件の差異やデータ汚染の懸念など、注意すべき点も残っています。
AIがソフトウェアの「攻め」と「守り」の両面で決定的な役割を持つ時代が、もう始まっています。
ではまた、お会いしましょう。
参考リンク
Anthropic 公式
- Project Glasswing - Anthropic
- Assessing Claude Mythos Preview's cybersecurity capabilities - Frontier Red Team
- Claude Mythos Preview System Card - Anthropic
- About Claude Models - Anthropic Docs
技術メディア
- Anthropic debuts preview of powerful new AI model Mythos in new cybersecurity initiative - TechCrunch
- A new Anthropic model found security problems 'in every major operating system and web browser' - The Verge