ー タダほど高いものはない まっくす
おはようございま数理工学!どうも、まっくす(@minux302)というものです。
こちらは創作+機械学習 Advent Calendar 2021 の24日目の記事です。
漫画翻訳システム「MANGA GLOBAL」を作りました。ハッカソンクオリティなのであしからず。
でもいくつかの問題が改善できれば普通に使えそう、という印象です。
リポジトリはこちらです。

1. あらすじ
自分は趣味で漫画を描きます。下記は Deep Learning フレームワークを擬人化した漫画です。
読んでいただけたらもうこの記事で伝え残すことはありません。対戦ありがとうございました。
上記の漫画は予想以上の反応をいただき大変嬉しかったです。
多くの人に自分の作品を見てもらえることがこんなに嬉しいことだとは思いませんでした。
この漫画がバズったのは正直たまたまのラッキーパンチです。これからも多くの人に自分の作品を見てもらうには何かしら工夫が必要でしょう。
多くの人に見てもらうためには色々な方法が考えられますが、一つに対象としている人の母数を増やすことがあります。近年、海外向けの動画を出しているじゅんやがヒカキンのYouTube登録者数を1年で追い抜いたことを見てわかる通り、母数の大きさは重要なファクターです。
海外向けに漫画を書くのであれば漫画を英語に翻訳することが必要です。
英語が苦手な私ですが、幸いなことに現代にはほんやくコンニャクという名のDeepLというツールがあります。これを使わない手はありません。
でも手作業で翻訳するのはいやです。
探してみると MANTRA ENGINE という自動漫画翻訳ツールがありますね。完!
https://mantra.co.jp/
と思ったのですがなんと企業向けっぽく個人では使えなさそうでした。
他にも似たような機能のツール、リポジトリもあったのですが精度、カスタマイズ性、操作性が微妙でした。
うーんじゃあ自分で作りましょう。
2. つくりたいものの概要
日本語の漫画画像を入力するとそれを英語に翻訳してくれるシステムを構築します。
OCR(Google Vision API) による文字認識 -> DeepL API を使った翻訳 -> GIMP(画像編集ソフト)形式で出力 です。
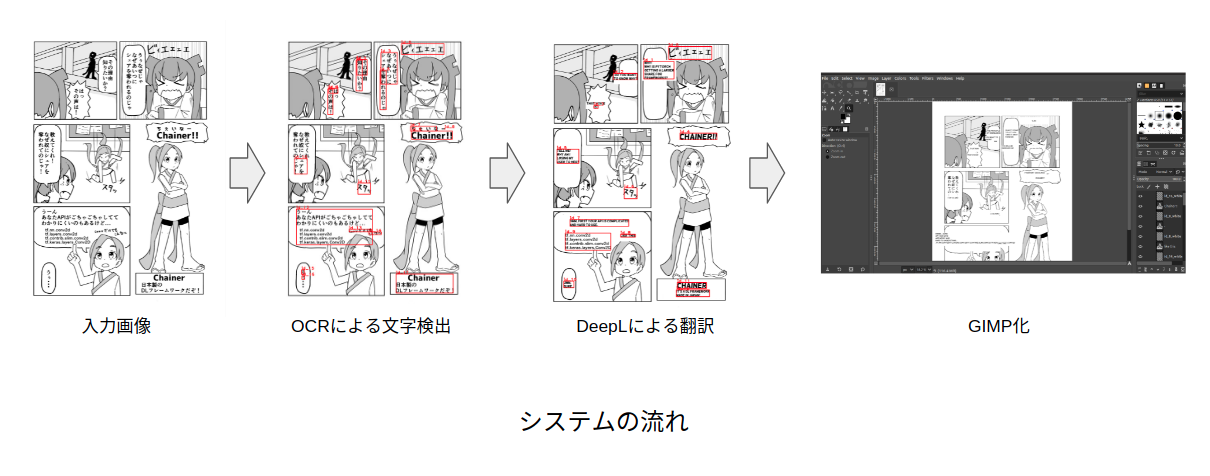
今回のシステムを作る上で気をつけたいのが、OCRと翻訳の部分が機械学習を使ったものになっていることです。
機械学習をつかっている以上、精度100%なんてことはありえません。手作業による修正を前提にしたシステムにしたいです。
今回で翻訳作業でいうと、特に翻訳の内容、セリフ位置の修正が必要になることが考えられます。
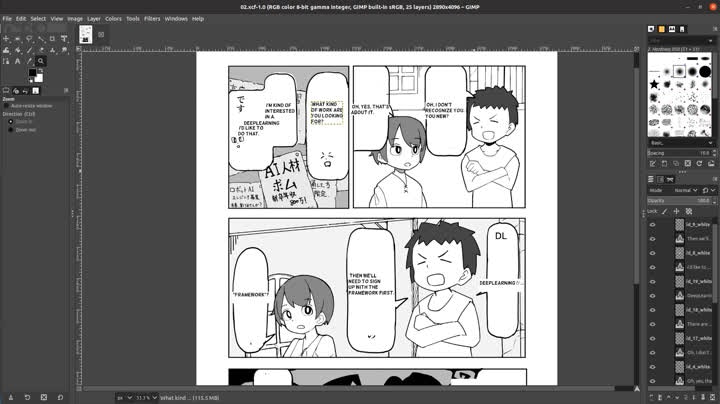
MANTRA ENGINE のように内容の修正を行う Web UI をつくるのは技術的にも工数的にも現実ではないので、今回は GIMP 形式で出力することにしました。GIMPで出力できれば、GIMPのUIを使って文字の内容、位置の修正が容易に行えます。
(本当のことをいうとツールの使い勝手の観点から psd 形式で出力したかったです。psd に書き込み可能なツールがなかった、GIMP 形式と psd 形式ではレイヤーの互換性がなかった、などの理由で GIMP を採用しました。)
3. システム詳細
3.1 OCR
ー 近年のOCR性能高いし行けるやろ!!! そして、、死。 まっくす
ということで失敗しました。近年は日本語の OCR の性能は高いかなーと思ってたのですが縦書きにはめっぽう弱いということがわかりました。
結構性能が高く日本語にも対応している OCR である PaddleOCR を試して見たのですが惨敗。縦書きの性能が壊滅です。横書き部分は結構性能が高いので、学習時に考慮されてないのかもしれませんね。
他にもいくつか試してみたのですが、無料で使えるものの中では Google Vision API の OCR は結構縦書きにも対応できて良さそうな印象でした。今回はこれを採用することにしました。
今回は使えなかったのですが LINE の OCR は最強すぎます。縦書きでも性能バッチバチです。他のものとは一線を画しているような気がします。下の画像は LINE のアプリについている OCR の機能で認識した結果です。かなり認識精度高いです。
APIで使うに法人向けの CLOVA OCR になるのでしょうか。今回は使えなさそうなので残念。(がんばってたら LINE のアプリと連携して使うこととかできるのかな??)

3.2 OCR 結果の修正GUI
ー え、これなんか手間増えてないですか? まっくす
ここの部分は本来作る予定ではなかったのですが、縦書き日本語に対する OCR の性能が当初の想定よりかなり低かったために作成しました。
OCR を実際に動かしてみると次の2つの課題がありました。
- 文字がないところを文字として認識するケースが多い
- 検出位置はあっているが認識した文字の内容が間違っている
これらを修正するような GUI ツールを作成しました。作成には kivy を使いました。
やっていることとしては、OCR による検出ボックスにIDをふり、検出位置を左に、検出文字内容を右に表示します。
文字がかかれていない部分を検出している場合はそれを削除、検出した日本語の内容が間違っている場合は翻訳にいれる前に修正します。
保存をするとデータが書き換えられ、表示内容が更新されます。
この部分は OCR の性能が LINE OCR くらいあればいらないと思います。人手での作業が結構発生するのでできれば最終的にはなくしたい作業ですね。
3.3 DeepL API を使った翻訳
ー お前だけは、信じていいか...? まっくす
DeepL の API は python から簡単に使うことができます。
1ヶ月に50万字まで無料です。今回は個人用、しかも漫画の翻訳なので実質無料です。
必要なコードもとても短いです。すばらしい。
3.4 GIMPへの出力
ー うごいたのでヨシ!! まっくす
GIMP には Python-Fu と呼ばれる拡張機能があり、python で GIMP で行える様々な機能(レイヤーの作成、移動、明るさの調整など)を使うことができます。
今回やることとしては、翻訳したテキストをテキストレイヤーとして貼り付ける作業になります。
前処理として、元のテキスト(日本語)を白塗りで削除、翻訳したテキストを適宜改行します。
翻訳後のテキストの文字サイズ、改行位置などは今回は固定の値を使いました。検出したテキストボックスの大きさが既知なので、それに合わせて文字サイズと改行位置を変えることもできます。
検出した日本語テキストの中心と翻訳したテキストの中心がそろうようにレイヤーを配置します。
翻訳したテキストの後ろに絵があると嫌なので別レイヤーで翻訳テキストと同じ大きさの白塗りボックスも配置しています。
Python-Fu での処理は下記のようになりました。シンプルで良いですね。
# 翻訳テキスト情報のロード
with open(json_path, 'r') as f:
words_info = json.load(f)
image = pdb.gimp_file_load(input_img_path, 'base')
for words_id in words_info.keys():
content = words_info[words_id]['content'] # 翻訳テキスト(改行済み)
left_up = words_info[words_id]['bbox'][0]
bottom_down = words_info[words_id]['bbox'][1]
# 翻訳テキストレイヤーの作成
text_layer = pdb.gimp_text_layer_new(image, content, TARGED_FONT_NAME, WORD_SIZE, 0)
# 翻訳テキストの後ろに同じ大きさの白いボックスのレイヤーを作成
center_x = int((left_up[0] + bottom_down[0]) / 2)
center_y = int((left_up[1] + bottom_down[1]) / 2)
new_left_up_x = center_x - text_layer.width // 2
new_left_up_y = center_y - text_layer.height // 2
white_layer = pdb.gimp_layer_new(image, text_layer.width, text_layer.height, 0, words_id + "_white", 100, 0)
white_layer.set_offsets(new_left_up_x, new_left_up_y)
white_layer.fill(1)
image.add_layer(white_layer)
# 翻訳テキストの配置
text_layer.set_offsets(new_left_up_x, new_left_up_y)
image.add_layer(text_layer)
pdb.gimp_xcf_save(0, image, text_layer, save_path, save_path)
Python-Fu はとても素晴らしい機能なのですが、python2系でしか動かない、APIドキュメントがなさすぎる、という問題があり結構劣悪な開発体験をすることになると思うので注意してください。
python-fu について記事をかいてくださっている方がいて非常に助かりました。この方が python-fu についての不満点を書いていてくださるのですがびっくりするくらい同じ感想を抱いております。GIMP version3 での改善に期待したいですね。
3.5 手作業での修正
ー CLIP STUDIO つ゛か゛い゛た゛い゛よ゛お゛お゛お゛! まっくす
適宜、テキストの内容、位置の修正をGIMPを使って行います。
テキストはレイヤー毎にテキストデータとして分かれているので修正できます。
OCRでの検出が失敗している場合は日本語テキストが残っているので、手作業で消し、DeepLを使って人力で翻訳します。
4. 結果
こちらが投稿した内容になります。
(注意してほしいのが全自動ではなく、かなり自分の手による修正が入っています)
4.1 どれくらい工数を削減できました?
正直な話、あまり工数を削減できなかったように感じました。そこまで工数感変わってないような気もするし、体感で3~4割くらい減ったかな?という印象です。
以下が工数を削減できなかった要因です。
- OCR の検出性能が不十分で、検出できていないボックスが多かった
- GUI による OCR の結果修正が普通に手間
- DeepL の性能がちょっと足りない
- GIMP が使いにくい
OCR の検出性能が不十分
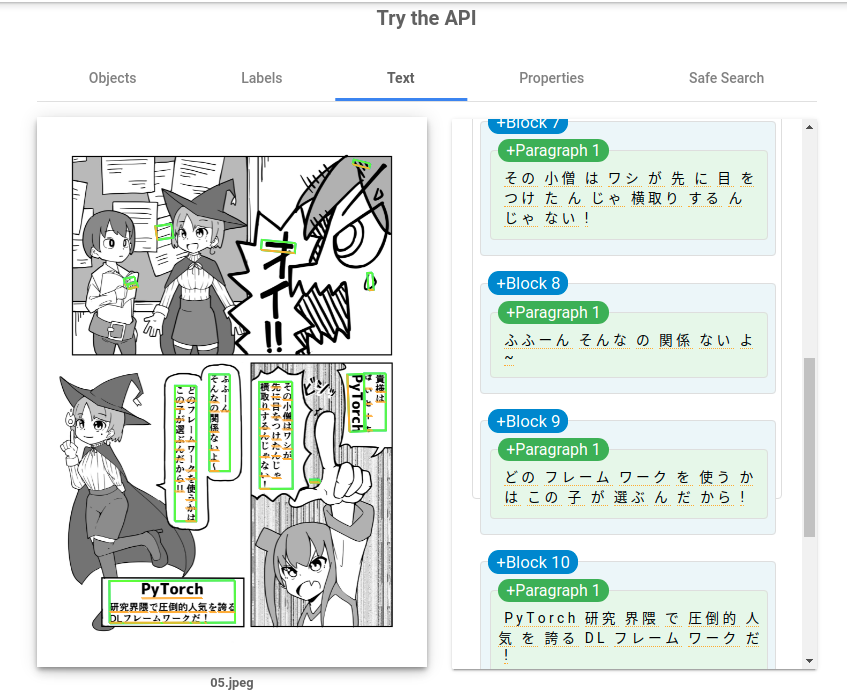
下の画像は検出の一例なのですが、縦書きの検出に結構失敗しています。
このページの場合だと縦書きのセリフ検出がほとんど失敗していますね。実際に翻訳するときはこのページはほとんど手作業になったような気がします。

実際にどの程度検出に成功していたか(大体の文字内容があっている)を数えてみたところセリフ100個中50~60個くらい、という印象でした。
半分くらいかぁ。。
GUI による OCR の結果修正が普通に手間
それは1工程増えているので手間が増えますよね。1ページあたり平均30秒数程度かかる気がします。
DeepL の性能がちょっと足りない
今回の翻訳をうけ、自分は思った以上に「DeepLが翻訳しやすいような日本語」を入力して翻訳していることに気づきました。
多分みなさんもそうだと思うのですが、DeepLで翻訳をするとき、訳したい文章を噛み砕いて、同じ意味だけど DeepL が訳しやすいような文章に変換していないでしょうか?自分はこれで DeepL の性能にちょっとバフをかけている節があります。
漫画のセリフだと、文章が口語調で情報が省略されていたりするので、そのまま訳すと不自然だったり、翻訳に失敗しているケースがいくつかあるような印象を受けました。あと "a" とか "the" とかは文脈が捉えられないので自分で修正する必要があります。すみません、僕もそこらへん全然わからないです。助けてください。
GIMP が使いにくい
GIMP の操作はちょっと癖があります。テキストレイヤーの選択が少しやりずらかったり、ペンタブとの相性がわるかったり。。
というか普段つかっている CLIP Studio (ペイントツール)が使いやすすぎるんですよね。後半は GIMP のショートカットを覚えたので多少早くはなりましたが、それでも CLIP Studio に比べると作業効率が落ちてしまいました。体感作業速度0.7倍くらいかな。
皮算用
地味にうれしかったのは元セリフの削除ですね。これは時短につながりました。
以上のことを踏まえてかなり雑な皮算用をしてみましょう。(普通に測ればいいのですが)
普通に作業すると1セリフあたり
- 文字消し:10秒
- セリフの翻訳:90秒
だとして1ページ平均セリフが10個だとすると1000秒(17分かからなくらい)ですね。体感だいたいそんな気がします。
次に翻訳した場合を考えて見ましょう。
セリフの検出率は60%ととします。検出されたもののうち、半分は微修正程度(10秒)、もう半分は全修正(90秒, ほぼ翻訳のみのため)としましょう(体感で割合を決定)。
- 検出が失敗(40%): 100秒/セリフ
- 検出が成功して微修正のもの(30%):10秒/セリフ
- 検出が成功したが翻訳が微妙で全修正したもの(30%):90秒/セリフ
- GUIによる操作:30秒/ページ
だとすると1ページあたりセリフが10個だとすると 30 + 4 * 100 + 3 * 10 + 3 * 90 = 730秒ですね。
何も考えず皮算用をしたのですが割と体感に近い値になりました。GIMPで作業効率落ちることも考慮するとトントンかもしれません涙。
所要時間はどの程度の翻訳精度を許容するか?などにより変動するので参考値として捉えていただけると幸いです。
4.2 翻訳したことによる効果
要するにバズるかバズらないかはインフルエンサーにRTされるかどうかなので、結果はお察しください。
あたりまえなんですが、姿の見えない海外の誰かに向けた作品を描くまえに、身近で、なにを考えているか想像できるフォロワーに楽しんで読んでもらえるような作品を作ることが大事だと思います。
5. 改善点
とにもかくにも OCR の性能が微妙なのが一番の誤算でした。そもそも検出できない、検出したとしてもテキストの内容がちょっと間違ってるなどでその修正に結構時間がかかってしまったように思います。
ただ LINE OCR を触った感じ、精度としては9割5分くらいは正確にできている印象があり、OCRの部分がそのくらい高精度がでれば有用なツールになる気がします。ということで LINE さん、よろしくお願いいたします。
6. 感想
もともとは全然別のことをする予定だったのですが、飲み会で翻訳システム作ってみたら?みたいなこと言われたので作ることにしました。
工数としては2〜3人日くらいでできました(ほとんどが kivy の勉強と python-fu との格闘な気がする。コードの量も実は全部で300行くらいです)。
ただやる前はもっと使えそうなものができるイメージでしたが OCR のところで詰まってしまいました。やっぱり機械学習は動かしてみてなんぼのところはありますね。精度悪すぎて急遽GUIツール作ろうと思ったり、修正を前提にGIMP形式で出力しようと設計したのは良かったと思います。
というか、こんなことをしている場合ではなく、原稿をするべき(2月末の技術書博がんばって出します)。

7. 宣伝
技術と創作の相互作用で界隈を活気づけることに関心があります。
創作から技術を盛り上げる例として漫画を描いています。先程の漫画の続きがこちらなので是非いただけると幸いです。
https://twitter.com/minux302/status/1428914733701210116
技術から創作を盛り上げる例として、写真をアニメ風に変換するモデルを会社で開発しました。遊んでみてください。
https://twitter.com/minux302/status/1420565746858426369