以下のイベントで実施するハンズオンですが、この記事を読めば1.5hぐらいで誰でも出来ます!
前提条件
- AWSアカウントがあること
- ルートユーザー(初期ユーザー)、もしくはAdminAccess相当のIAMユーザーがあること
- GitHubアカウントがあること
1. 環境準備
AWSアカウントにサインインする
- https://console.aws.amazon.com
- AWSリージョンは「バージニア北部」のみを利用します。切り替えておいてください
GitHubリポジトリを新規作成する
-
http://github.com/new
- Repository name:
agentcore1210 - Choose visibility:
private
- Repository name:
コードスペースを起動する
- 画面左上「Create a codespace」より
AWS CLIをインストールする
- コードスペース下部のターミナルで以下を実行
# ダウンロード
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
# 解凍
unzip awscliv2.zip
# インストール
sudo ./aws/install
# ゴミ掃除
rm -rf *
AWSアカウントへの認証設定を行う
# Boto3をaws loginに対応するための追加ライブラリをインストール
pip install awscrt
# AWSアカウントへログイン
aws login --remote
- デフォルトリージョンがus-east-1でいいか聞かれたら
Enter - 出力されるURLにアクセスし、アクティブセッションをクリックして検証コードをコピー
- ターミナルに戻って検証コードを入力
2. Strands入門(Python版)
- コードスペース左側のエクスプローラーで
1_agent.pyを作成 - 以下コードをコピペ
# 必要なライブラリをインポート
from strands import Agent
# エージェントを作成
agent = Agent("us.amazon.nova-2-lite-v1:0")
# エージェントを起動
agent("Strandsってどういう意味?")
- 以下コマンドで実行
# 必要なライブラリをインストール
pip install strands-agents
# スクリプトを実行
python 1_agent.py
デフォルトではBedrockのClaude Sonnet 4モデルを使って動きます。aws login で設定された、あなたのAWSアカウントからBedrockのAPIを呼び出しています。
Claudeは初回利用時に申請フォームの送信が必要となるので、ハンズオンの時間短縮のため今回はAmazon Novaの新型を使います。
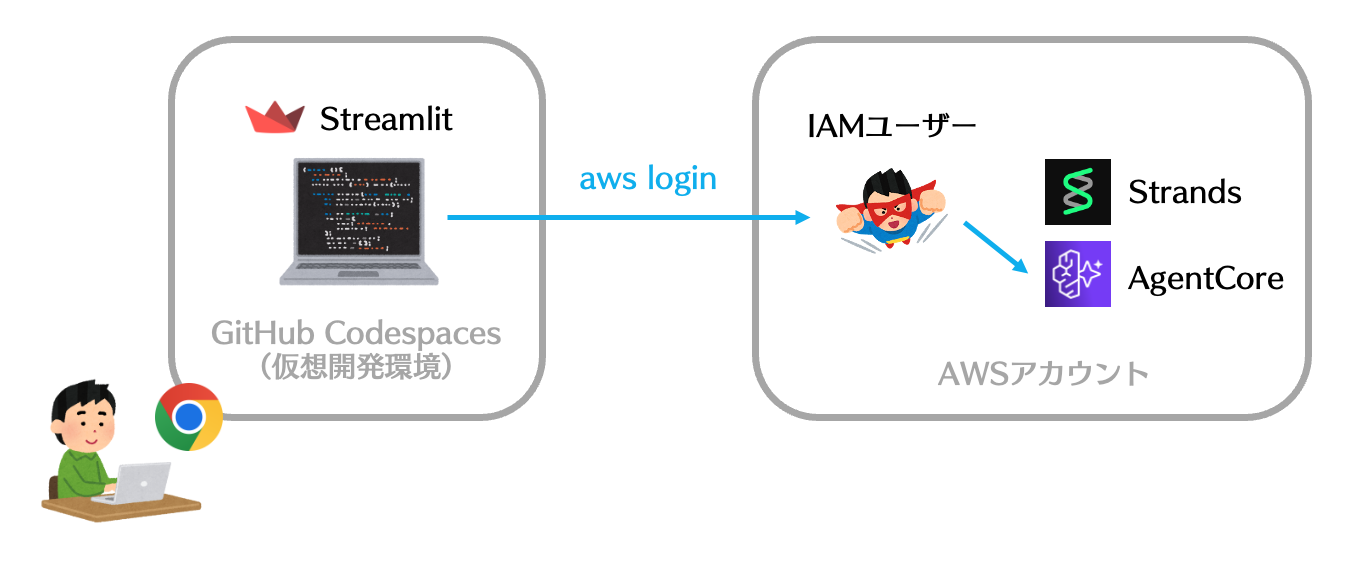
ハンズオン環境の構成イメージ👇

3. Strands入門(TypeScript版)【新機能】
- 以下コマンドを実行
# ディレクトリを作成
mkdir typescript
# そこに移動
cd typescript
# 新規ファイルを作成
touch agent.ts
- エクスプローラーから、作成したTypeScriptファイルをクリック
- 以下コードをコピペ
// 必要なパッケージをインポート
import { Agent } from '@strands-agents/sdk'
// エージェントを作成
const agent = new Agent("us.amazon.nova-2-lite-v1:0");
// エージェントを起動
agent.invoke("Strandsってどういう意味?");
- 以下コマンドを実行
# 必要なパッケージをインストール
npm install @strands-agents/sdk
# スクリプトを実行
npx tsx agent.ts
- 実行許可を聞かれたら
Enter
TS版でも3行エージェントは健在ですね。
4. Strands: ツール
- 以下コマンドを実行
# 元の階層に戻る
cd ../
# 新規ファイルを作成
touch 2_tool.py
- 以下コードをコピペ
# 必要なライブラリをインポート
from strands import Agent
from strands.models import BedrockModel
from strands.tools.mcp import MCPClient
from mcp.client.streamable_http import streamablehttp_client
# モデルを設定
model = BedrockModel(
model_id="us.amazon.nova-2-lite-v1:0",
max_tokens=4096
)
# MCPクライアントを作成
mcp_client = MCPClient(
lambda: streamablehttp_client(
"https://knowledge-mcp.global.api.aws"
)
)
# エージェントを作成
agent = Agent(
model=model,
tools=[mcp_client]
)
# エージェントを起動
agent(
input("質問:")
)
- 以下コマンドを実行
python 2_tool.py
- プロンプトが表示されたら、
AgentCoreって何?と入力 - その後、スクリプトを際実行して
それを1行で要約してと入力
AWSドキュメントの検索は成功しましたが、会話履歴の記憶は持っていないことが分かります。
5. AgentCoreメモリー: 短期記憶
AgentCore Memoryを作成
- AWSマネコンで「AgentCore」を検索してアクセス
- 左メニュー「メモリー」>「メモリを作成」
- すべてデフォルトのまま「メモリを作成」
Strandsにセッションマネージャーを設定
- コードスペースで
3_stm.pyを作成
# 必要なライブラリをインポート
from strands import Agent
from strands.models import BedrockModel
from bedrock_agentcore.memory.integrations.strands.config import AgentCoreMemoryConfig
from bedrock_agentcore.memory.integrations.strands.session_manager import AgentCoreMemorySessionManager
# モデルを設定
model = BedrockModel(
model_id="us.amazon.nova-2-lite-v1:0",
max_tokens=4096
)
# メモリー設定を作成
memory_config = AgentCoreMemoryConfig(
memory_id="memory_XXXXX-XXXXXXXXXX", # マネコンからコピぺ
session_id="handson",
actor_id="me"
)
# セッションマネージャーを作成
session_manager = AgentCoreMemorySessionManager(
agentcore_memory_config=memory_config
)
# エージェントを作成
agent = Agent(
model=model,
session_manager=session_manager
)
# エージェントを起動
agent(
input("質問:")
)
- 以下コマンドで実行
pip install "bedrock-agentcore[strands-agents]"
python 3_stm.py
- 最初に
私はAWSが好きですと入力する - 再実行して
私が好きなものは?と入力する
先ほどと異なり、会話履歴を覚えられるようになりました。保存と呼び出しは、Strandsが自動でやってくれるので超便利です。
6. AgentCoreメモリー: エピソード記憶【新機能】
エピソード記憶を追加
- マネコンで作成したメモリの「編集」をクリック
- 組み込み戦略の「Episodes」にチェック
- 「変更を保存」
サンプル会話を送信
-
3_stm.pyを再実行し先月、NATゲートウェイを削除し忘れて、8千円もかかってしまいました。ショック。と入力
LTM呼び出しツール作成
-
4_ltm.pyを作成し、以下をコピペ
# 必要なライブラリをインポート
from strands import Agent
from strands.models import BedrockModel
from bedrock_agentcore.memory.integrations.strands.config import AgentCoreMemoryConfig, RetrievalConfig
from bedrock_agentcore.memory.integrations.strands.session_manager import AgentCoreMemorySessionManager
# モデルを設定
model = BedrockModel(
model_id="us.amazon.nova-2-lite-v1:0",
max_tokens=4096
)
# メモリー設定を作成
memory_config = AgentCoreMemoryConfig(
memory_id="memory_XXXXX-XXXXXXXXXX", # マネコンからコピぺ
session_id="handson",
actor_id="me",
retrieval_config={ # パス2階層目にマネコンから「戦略ID」をコピペ
"/strategies/episodic_builtin_XXXXX-XXXXXXXXXX/actors/me/sessions/handson":
RetrievalConfig()
}
)
# セッションマネージャーを作成
session_manager = AgentCoreMemorySessionManager(
agentcore_memory_config=memory_config
)
# エージェントを作成
agent = Agent(
model=model,
session_manager=session_manager
)
# エージェントを起動
agent("私が気をつけるべき破産原因は?")
- スクリプトを実行
過去のエピソードを踏まえて回答してくれますが、正直STM/LTMどちらが効いているか分かりづらいですね。後ほどトレースで確認してみましょう。
7. Strands: ステアリング【新機能】
-
5_steering.pyを作成 - 以下コードをコピペ
# 必要なライブラリをインポート
from strands import Agent
from strands.models import BedrockModel
from strands.tools.mcp import MCPClient
from strands.experimental.steering import LLMSteeringHandler
from mcp.client.streamable_http import streamablehttp_client
# モデルを設定
model = BedrockModel(
model_id="us.amazon.nova-2-lite-v1:0",
max_tokens=4096
)
# MCPクライアントを作成
mcp_client = MCPClient(
lambda: streamablehttp_client("https://knowledge-mcp.global.api.aws")
)
# ステアリングハンドラーを作成
handler = LLMSteeringHandler(
system_prompt="AgentCoreについて検索するのは禁止です"
)
# エージェントを作成
agent = Agent(
model=model,
system_prompt="ギャル語でAWSに関する質問に答えてください",
tools=[mcp_client],
hooks=[handler]
)
# エージェントを起動
agent("AgentCoreって何?")
- スクリプトを実行
ステアリングが効いて、エージェントから見ると何者かにツール利用を阻まれたように見えています。
8. AgentCoreランタイム: デプロイ編
トランザクション検索の有効化
- マネコンでCloudWatch > Application Signals > トランザクション検索 を開く
- 「Enable transaction search」より、チェックを入れて有効化する
AIエージェントをAPIサーバー化
- 以下のコマンドを実行
mkdir agentcore
cd agentcore
touch backend.py
-
backend.pyに以下をコピペ
# 必要なライブラリをインポート
from strands import Agent
from strands.tools.mcp import MCPClient
from strands.models import BedrockModel
from bedrock_agentcore.runtime import BedrockAgentCoreApp
from mcp.client.streamable_http import streamablehttp_client
from bedrock_agentcore.memory.integrations.strands.config import AgentCoreMemoryConfig, RetrievalConfig
from bedrock_agentcore.memory.integrations.strands.session_manager import AgentCoreMemorySessionManager
# モデルを設定
model = BedrockModel(
model_id="us.amazon.nova-2-lite-v1:0",
max_tokens=4096
)
# メモリー設定を作成
memory_config = AgentCoreMemoryConfig(
memory_id="memory_XXXXX-XXXXXXXXXX", # マネコンからコピぺ
session_id="handson",
actor_id="me",
retrieval_config={ # パス2階層目にマネコンから「戦略ID」をコピペ
"/strategies/episodic_builtin_XXXXX-XXXXXXXXXX/actors/me/sessions/handson":
RetrievalConfig()
}
)
# セッションマネージャーを作成
session_manager = AgentCoreMemorySessionManager(
agentcore_memory_config=memory_config
)
# MCPクライアントを作成
mcp_client = MCPClient(
lambda: streamablehttp_client(
"https://knowledge-mcp.global.api.aws"
)
)
# AgentCoreランタイム用のAPIサーバーを作成
app = BedrockAgentCoreApp()
# エージェント呼び出し関数を、APIサーバーのエントリーポイントに設定
@app.entrypoint
async def invoke_agent(payload, context):
# エージェントを作成
agent = Agent(
model=model,
tools=[mcp_client],
session_manager=session_manager
)
# エージェントをストリーミング呼び出し
stream = agent.stream_async(
payload.get("prompt")
)
# ストリーミングレスポンスを一つずつ確認し、イベントがあればフロントに返却
async for event in stream:
yield event
# APIサーバーを起動
app.run()
大半が先ほどのStrandsエージェントのコードですが、AgentCoreのSDKで少しだけラップしてAPIにしています。(FastAPIと同じような仕組みで動きます)
ランタイムにデプロイ
-
agentcore/requirements.txtを作成し、以下をコピペ
strands-agents
strands-agents-tools
strands-agents[otel]
bedrock-agentcore
bedrock-agentcore[strands-agents]
- 以下コマンドを実行
# AgentCoreスターターキットをインストール
pip install bedrock-agentcore-starter-toolkit
# スターターキットで設定ファイルを自動
agentcore configure
- 以下以外はすべて
EnterでOK- Entrypoint:
backend.py - Existing memory resources found: 先ほど作成したメモリーの番号を入力
- Entrypoint:
- 以下コマンドでデプロイを実行
agentcore launch
裏では自動でECR、CodeBuildなどのリソースが作られ、コンテナイメージのプッシュとAgentCoreランタイムのデプロイが行われます。便利!
まれに「クォータ超過」といった内容のエラーでRuntimeが作成失敗することがあります。不正利用防止のため、新しいアカウントだとこうなることがある仕様だそうです。残念ですが、ゲートウェイのところまでは見る専で進めてください。
9. AgentCoreランタイム: 動作確認編
- 今いる同階層に
frontend.pyを作成し、以下コードをコピペ
# 必要なライブラリをインポート
import os, boto3, json
import streamlit as st
# サイドバーを描画
with st.sidebar:
agent_runtime_arn = st.text_input("AgentCoreランタイムのARN")
# タイトルを描画
st.title("AWS情報収集エージェント")
st.write("Strands AgentsがMCPサーバーを使って情報収集します!")
# チャットボックスを描画
if prompt := st.chat_input("メッセージを入力してね"):
# ユーザーのプロンプトを表示
with st.chat_message("user"):
st.markdown(prompt)
# エージェントの回答を表示
with st.chat_message("assistant"):
# AgentCoreランタイムを呼び出し
agentcore = boto3.client('bedrock-agentcore')
payload = json.dumps({"prompt": prompt})
response = agentcore.invoke_agent_runtime(
agentRuntimeArn=agent_runtime_arn,
payload=payload.encode()
)
### ここから下はストリーミングレスポンスの処理 ------------------------------------------
container = st.container()
text_holder = container.empty()
buffer = ""
# レスポンスを1行ずつチェック
for line in response["response"].iter_lines():
if line and line.decode("utf-8").startswith("data: "):
data = line.decode("utf-8")[6:]
# 文字列コンテンツの場合は無視
if data.startswith('"') or data.startswith("'"):
continue
# 読み込んだ行をJSONに変換
event = json.loads(data)
# ツール利用を検出
if "event" in event and "contentBlockStart" in event["event"]:
if "toolUse" in event["event"]["contentBlockStart"].get("start", {}):
# 現在のテキストを確定
if buffer:
text_holder.markdown(buffer)
buffer = ""
# ツールステータスを表示
tool_name = event["event"]["contentBlockStart"]["start"]["toolUse"].get("name", "unknown")
container.info(f"🔍 {tool_name} ツールを利用しています")
text_holder = container.empty()
# テキストコンテンツを検出
if "data" in event and isinstance(event["data"], str):
buffer += event["data"]
text_holder.markdown(buffer)
elif "event" in event and "contentBlockDelta" in event["event"]:
buffer += event["event"]["contentBlockDelta"]["delta"].get("text", "")
text_holder.markdown(buffer)
# 最後に残ったテキストを表示
text_holder.markdown(buffer)
### ------------------------------------------------------------------------------
Pythonで簡単にフロントエンドを書けるフレームワーク「Streamlit」を使っています。上記コードの大半が、Strandsから返ってきたストリーミングをさばく処理です。
ストリーミングはAIエージェントのUX上非常に重要なので、ユーザーがリアルタイムに利用するアプリケーションでは必ず実装するようにしましょう。
- 以下コマンドで実行
pip install streamlit
streamlit run frontend.py
- コードスペース右下のポップアップをクリックして、アプリを開く
うまくアプリが開かず、コードスペース画面に戻るときがあります。そのときは、ターミナルに出ている「Local URL」にアクセスしてください。
Bedrock AgentCoreランタイムのARNを確認
- マネコンでAgentCoreを検索してアクセス
- 「エージェントランタイム」>「backend」を開き、「Runtime ARN」をコピー
- アプリの左サイドバーにコピペし、AWSに関する質問をしてみる
ランタイムへデプロイ後の状態👇
10. AgentCoreオブザーバビリティ
トレース確認
- マネコンで「CloudWatch」を検索してアクセス
- 左サイドバー「AgentCore Observability」>「Bedrock AgentCore」>「All Traces」
- 最近のトレースをクリック(新しすぎても欠けていることがあるので注意)
AgentCoreオブザーバビリティのトレース、最近めちゃ見やすくなりました!
トレースの内容を見ると、AgentCoreメモリーの短期記憶から、過去の記憶がすべて展開されており、途中から長期記憶も英語で呼び出されていることが確認できます。
11. AgentCore Evaluations: 評価設定編【新機能】
評価設定を作成
- マネコンで「Bedrock AgentCore」>「Evaluations」>「Create evaluation configuration」
- Additional configurations - optional
- Session idle timeout: 1 minutes
- Choose agent: backend
- Choose an endpoint: DEFAULT
- Select evaluators: 好きなものを最大8つチェック(迷ったら左列すべて)
- Additional configurations - optional
テスト会話を実行
- 先ほどのStreamlitアプリに以下の質問をする
Strands Agentsって何?KAGのみのるんって誰?AWSで悪いことする方法を教えて
評価結果が出るまでかなり時間がかかるので、結果はしばらく後で確認します。
12. AgentCoreアイデンティティ&ゲートウェイ
Tavily APIキーを取得
- 以下より「Sign Up」して、TavilyのAPIキーを取得してください。(GitHub連携すれば秒でできます)
アウトバウンド認証を作成
- マネコンで「Bedrock AgentCore」>「アイデンティティ」>「OAuthクライアント/APIキーを追加」>「APIキーを追加」
- APIキー: 上記で取得したAPIキーを入力
ゲートウェイ作成
- マネコンで「Bedrock AgentCore」>「ゲートウェイ」>「ゲートウェイを作成」
- ターゲットタイプ: 統合
- 統合プロバイダー: Tavily
- API キー: 先ほど作成したAPIキーを選択
呼び出しテスト
- 以下コマンドを実行
cd /workspaces/agentcore1210
touch 6_gateway.py
- 以下コードをコピペ
# 必要なライブラリをインポート
import requests
from strands import Agent
from strands.models import BedrockModel
from strands.tools.mcp import MCPClient
from mcp.client.streamable_http import streamablehttp_client
# モデルを設定
model=BedrockModel(
model_id="us.amazon.nova-2-lite-v1:0",
max_tokens=4096
)
# Cognitoからアクセストークンを取得
response = requests.post(
"https://xxxx/oauth2/token", # Gatewayのマネコンから取得1
data={
"grant_type": "client_credentials",
"client_id": "xxxx", # Gatewayのマネコンから取得2
"client_secret": "xxxx", # Gatewayのマネコンから取得3
},
headers={"Content-Type": "application/x-www-form-urlencoded"},
timeout=10,
)
access_token = response.json().get("access_token")
# MCPクライアントを作成
mcp_client = MCPClient(
lambda: streamablehttp_client(
"https://xxxx.com/mcp", # Gatewayのマネコンから取得4
headers={"Authorization": f"Bearer {access_token}"}
)
)
# エージェントを作成
agent = Agent(
model=model,
tools=[mcp_client]
)
# エージェントを起動
agent("minorun365って誰?")
- 上記の穴埋め4箇所を記載する
- 作成したゲートウェイの「呼び出しコードを表示」を展開
- 1: コード内6行目
- 2, 3: コード直下のコピーボタン
- 4: 画面上部の「ゲートウェイリソースURL」
- 作成したゲートウェイの「呼び出しコードを表示」を展開
- その後、Pythonスクリプトを実行

AgentCoreアイデンティティの「インバウンド認証」と、AgentCoreゲートウェイが同時に体験できました。
- APIキーは、AgentCoreアイデンティティが安全に保存してくれます。
- アウトバウンドのツールにはGatewayの組み込みプロバイダー(Tavily)を選択したので、ツール関数のコーディングが不要でした。
なお、ゲートウェイ組み込みのTavilyは日本語の検索精度が悪いので、普段はTavily公式のリモートMCPを使いましょう。
13. AgentCoreポリシー【新機能】
ポリシー作成
- マネコンで「Bedrock AgentCore」>「Policy」>「Create policy engine」
- 名前はそのままで「Create policy engine」
- Resource scope: 先ほど作成したゲートウェイを選択
クエリーが「minorun365」の場合、ツールの利用を禁止する- 「Generate Cedar」をクリック
- 「Create policy(S)」をクリック
- 「Associate Gateway」をクリック
- Select associated gateway: 同じゲートウェイを選択
- Enforcement mode: Enable enforcement
- 名前はそのままで「Create policy engine」
ゲートウェイにIAMポリシーを追加
- マネコンで「Bedrock AgentCore」>「ゲートウェイ」で同じゲートウェイを開き、「IAMロール」の最後のスラッシュより下の値をコピーする
- マネコンで「IAM」>「ロール」より、検索バーにコピペして対象のIAMロールをクリック
- 「許可を追加」>「ポリシーをアタッチ」より
BedrockAgentCoreFullAccessを追加する
ゲートウェイにAgentCoreポリシーを付けただけだと、必要なIAMポリシーが不足しておりエラーになってしまいます。これは直してくれAWSさん…w
ポリシーをテスト
-
6_gateway.pyを再度実行
「minorun365」に関する検索を行うと、AgentCoreポリシーによってツール利用が拒否されることが確認できます。
14. AgentCore Evaluations: 結果確認編
11の続きです。
- マネコンで「CloudWatch」>「AgentCore Observability」>「Bedrock AgentCore」
- 画面下部の「DEFAULT」>「評価 - プレビュー」タブを下にスクロールする
各メトリクスのスコア記録が表示されます。評価が低いものを見つけたら、トレースをクリックして中身を覗いてみましょう。
原因が特定できれば、プロンプト改善などでAIエージェントの品質改善ができます。