2章 PostgreSQL・SQL入門
目次
- 2.1 リレーショナルデータベースとは
- 2.2 SQLとは
- 2.3 PostgreSQLとは
- 2.4 PostgreSQLの環境準備
- 2.5 データベースクライアントツールの導入
- 2.6 データベースの作成とテーブルの定義
- 2.7 SQLの基本的な構文
- 2.8 GROUP BYと集約関数
- 2.9 結合
- 2.10 トランザクション
2.1 リレーショナルデータベースとは
リレーショナルデータベース(RDB) はデータ構造の一種であり、表のような形でデータを管理するシステムです。例えば以下ようなものです。
| 学籍番号 | 学科 | 氏名 |
|---|---|---|
| 241004 | 化学 | ヒソカ モロウ |
| 242021 | 生物科学 | ゴン フリークス |
| 241015 | 電気電子 | キルア ゾルディック |
この表では、学籍番号に対して、学科や氏名というデータが結び付けられています。このように、データとデータに関係が定義されているのが、リレーショナルデータベース(RDB)です。
RDBを構成する基本的な概念として、 テーブル、レコード(行)、カラム(列)、フィールド があります

-
テーブル
データベースにおける構成要素で、何らかのデータのまとまり。
上の例では表全体のことを指し、学籍番号、学科、氏名をひとまとめにしたデータの集まりである。 -
レコード(行)
表における横方向の値のまとまり。特定のデータ。 -
カラム(列)
表における縦方向の値のまとまり。データの属性。 -
フィールド
表における特定の値。特定のカラムの特定のレコード。
2.2 SQLとは
RDBを使う上で欠かせないのが SQL です。
SQLはRDB上のデータを取得、作成、変更、削除するための言語です。
SQLを使用することで、様々なデータ処理を実現できます。
2.3 PostgreSQLとは
RDBを作成し、管理・更新するためのシステムが リレーショナル データベース管理システム (RDBMS) です。これまで様々なRDBMSが開発されており、その一つが PostgreSQL です
PostgreSQLは強力なオープンソースのオブジェクトリレーショナルデータベースシステムで、35年以上にわたる活発な開発により、信頼性、機能の堅牢性、パフォーマンスにおいて高い評価を得ています。
PostgreSQLのインストール方法や使用方法については、公式ドキュメントに豊富な情報があります。オープンソースコミュニティは、PostgreSQLに精通し、どのように動作するかを発見し、キャリアの機会を見つけるのに役立つ多くの場所を提供しています。コミュニティに参加する方法についてはこちらを参照してください。
PostgreSQL(https://www.postgresql.org/)
2.4 PostgreSQLの環境準備
前回の記事で紹介したDockerを使って開発環境を構築します。前回の記事を読んでいない人も、手順に従えば環境構築が可能ですし、ついでにDockerの簡単な使い方もつかめると思います。あらかじめインストールだけ行ってください。(インストール手順)
1.Dockerfileの作成
新たにのフォルダを作成し、その中に以下の2つのファイルを作成します。
FROM postgres:16.0-bullseye
version: "3.8"
services:
postgres:
container_name: postgres
build:
context: .
dockerfile: Dockerfile
image: postgres
volumes:
- ./data:/var/lib/postgresql/data
ports:
- 5432:5432
tty: true
stdin_open: true
env_file:
- ./.env
2.設定ファイルの作成
PostgreSQLの設定のために、.envファイルをdockerから読み込んで環境変数を設定します。
ユーザー名とパスワードは適宜変更してください。
PGHOST=0.0.0.0 #すべてのネットワークインタフェースにバインドする
POSTGRES_USER=test_user #データベースにアクセスするためのユーザー名
POSTGRES_PASSWORD=test_password #データベースにアクセスするためのパスワード
PGPORT=5432
3.コンテナの立ち上げ
docker-compose up
2.5 データベースクライアントツールの導入
DBeaverの公式サイトからインストーラダウンロードして、セットアップガイドに沿ってインストールしてください。
インストールして初めてDBeaverを起動すると、以下のような画面が出ると思います。この画面でPostgreSQLをクリックして、新しい接続を作成してください。

接続の設定画面が出ます。
Host: localhost, port: 5432
Database: test_user
ユーザー名: test_uset(設定ファイルで設定したユーザー名)
パスワード: test_password(設定ファイルで設定したパスワード)
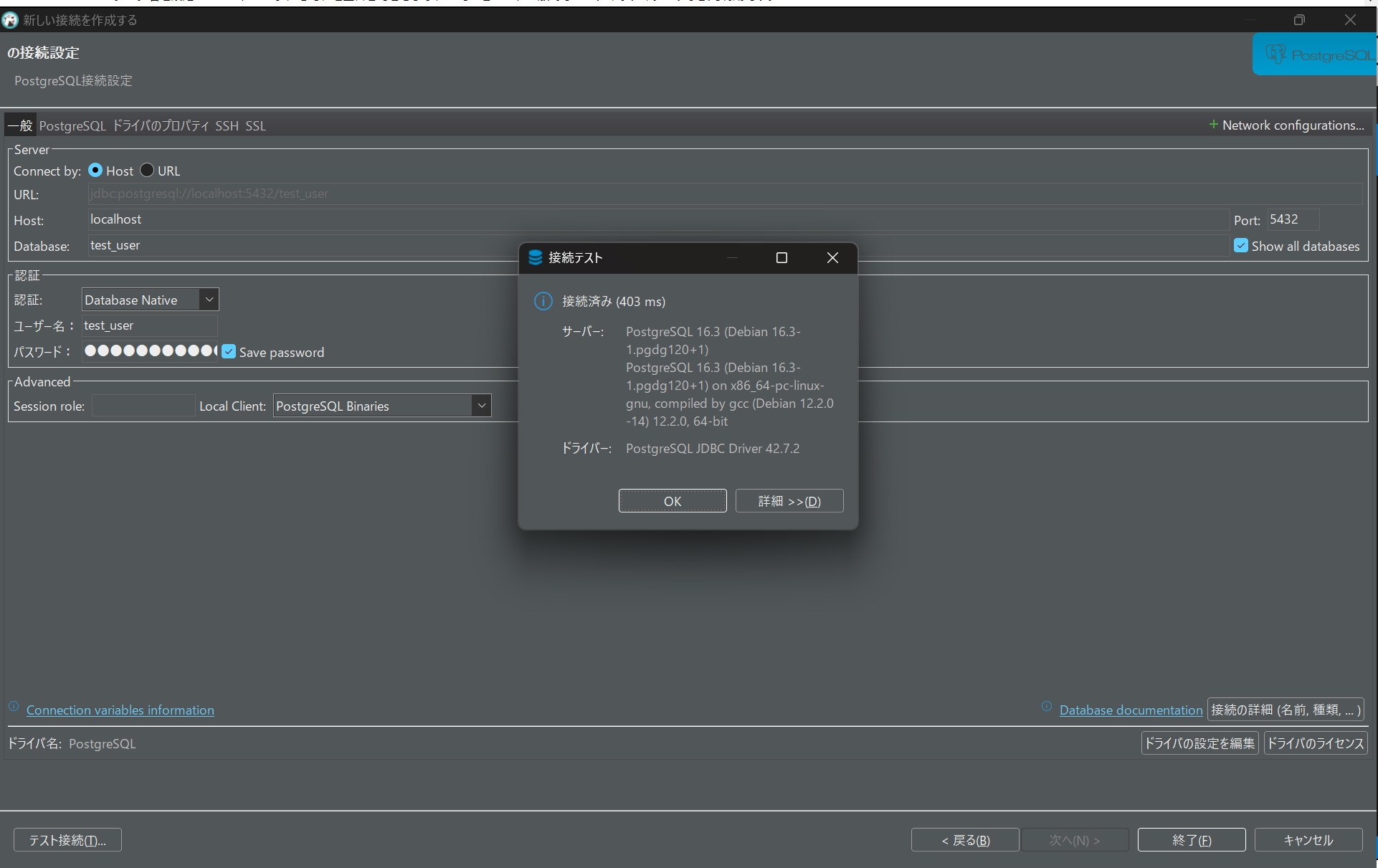
と設定して、左下のテスト接続ボタンをクリックしてください。

以下の表示が出れば接続成功です。
OKをクリックして右下の終了から設定画面を閉じてください。
接続を完了した後の画面がこちらになります。
左側のパネルに接続したホストの一覧が表示されます。

2.6 データベースの作成とテーブルの定義
メニュバーから SQLエディタ -> SQLコンソールを開く をクリックします

SQLコンソールが開きます。
ここにSQLを入力し、実行できます。

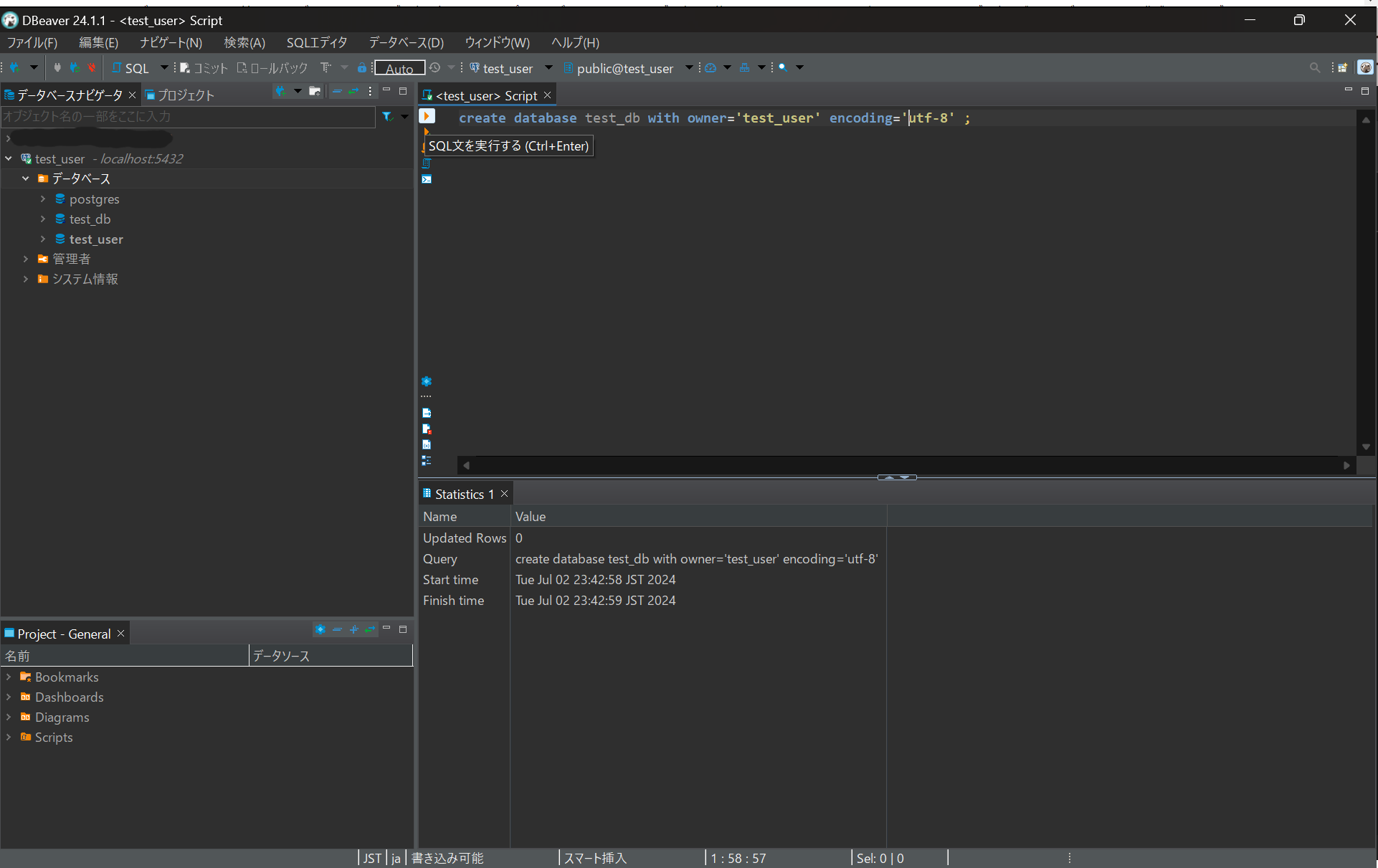
以下のSQL文をコピー&ペーストしてください
create database test_db with owner='test_user' encoding='utf-8';
SQLコンソール左上の SQL文を実行する をクリックしてください
右側のパネルの項目 データベース を右クリックして一番下の 更新 をクリックします

新しくデータベース test_db が作成されています

同じ要領で以下のSQLを実行し、テーブルを作成します。
CREATE TABLE test_db.public.test_table (
id int8 NOT NULL,
"name" varchar NOT NULL,
age int8,
CONSTRAINT test_table_pk PRIMARY KEY (id)
);
テーブル を右クリックして 更新 からテーブルの表示を更新します。

新しくテーブルが作成されています

テスト用データの読み込み
-
以下のリンクを 右クリック -> 名前を付けてリンク先を保存 をクリックしてCSVファイルをダウンロードします
ダウンロードリンク -
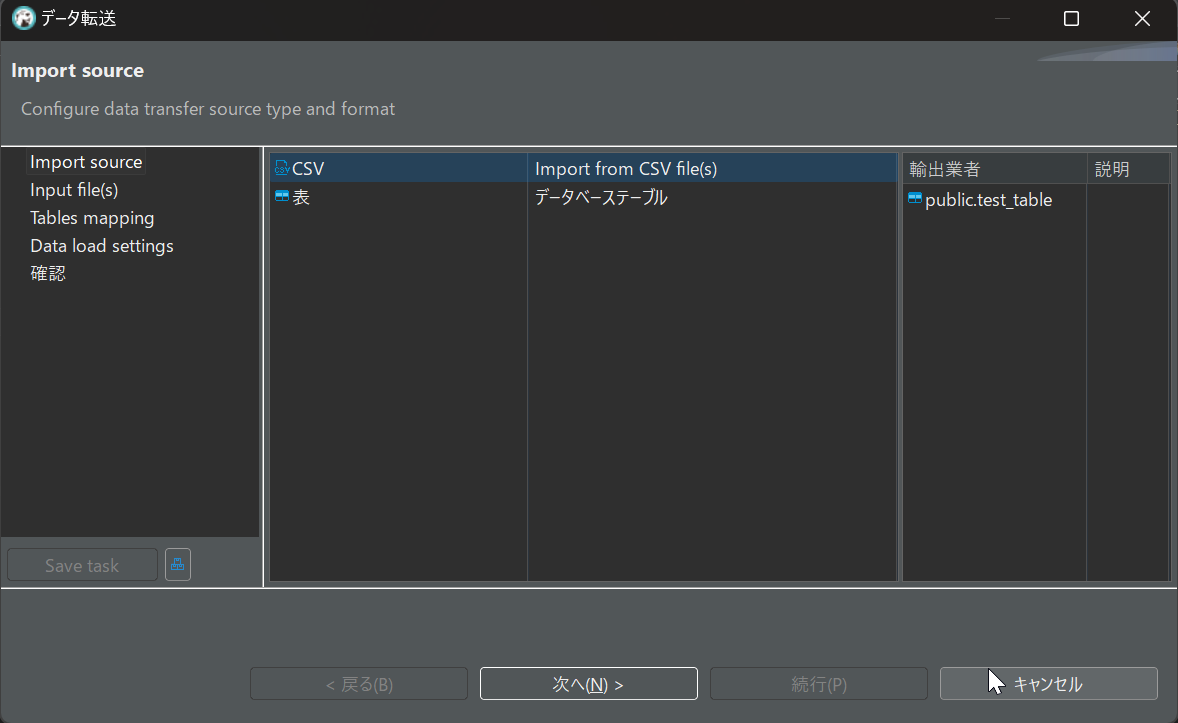
test_tableを右クリック -> データのインポート をクリックします

-
source typeからCSVを選択して、次へを押してダウンロードしたCSVファイルを選択します。
-
そのまま次へ -> 次へ -> 続行と押していくと、このようにデータが読み込まれます

2.7 SQLの基本的な構文
取得
データの取得にはSELECT文を使います
SELECT [カラム名1], [カラム名2], ... FROM [テーブル名]
先程と同じく、メニュバーから SQLエディタ -> SQLコンソールを開く をクリックしてSQLコンソールを開き、それぞれ実行して結果を確認してみてください。
SELECT * FROM test_table;
SELECT name, age FROM test_table;
また、WHERE句を用いて取得するデータの条件を検索することができます
SELECT [カラム名1], [カラム名2], ... FROM [テーブル名] WHERE [条件]
条件には= < <= > >= <> !=の比較演算子、AND OR NOTの論理演算子が使えます。
SELECT * FROM test_table WHERE age >= 20;
SELECT * FROM test_table WHERE age >= 20 AND age < 30;
値が NULL である/でないレコードを抽出するには、IS NULL/IS NOT NULLを使います。
SELECT * FROM test_table WHERE age IS NULL;
SELECT * FROM test_table WHERE age IS NOT NULL;
ORDER BYを使えば、結果をソートすることができます
末尾にdescを指定すれば降順に、未指定もしくはascで昇順になります。
SELECT * FROM test_table WHERE age IS NOT NULL ORDER BY age;
SELECT * FROM test_table WHERE age IS NOT NULL ORDER BY age desc;
追加
新しいデータをテーブルに追加するには INSERT 文を使います。
INSERT INTO [テーブル名] ([カラム名1], [カラム名2], ...) VALUES ([値1], [値2], ...);
INSERT INTO test_table (id, name, age) VALUES (29, '夏油傑', 27);
左側のパネルからテーブルをダブルクリックしてテーブルを確認してください。

更新
既存のレコード、フィールドを更新するには UPDATE 文を使います。WHERE 句で更新対象を絞り込むことができます。
UPDATE [テーブル名] SET [カラム名1] = [値1], [カラム名2] = [値2], ... WHERE [条件];
UPDATE test_table SET name = '究極 メカ丸' WHERE name = '与 幸吉';
削除
データを削除するには DELETE 文を使います。こちらも WHERE 句で削除対象を絞り込むことができます。
DELETE FROM [テーブル名] WHERE [条件];
DELETE FROM test_table WHERE id = 29;
2.8 GROUP BYと集約関数
GROUP BY 句は、指定したカラムの値でカラムをグループ化し、集約関数と共に使用することで、グループごとの集計結果を得ることができます。
SELECT [カラム名], [集約関数]([カラム名]) FROM [テーブル名] GROUP BY [カラム名];
PostgreSQLで利用できる代表的な集約関数は以下の通りです。
-
COUNT: レコード数 -
SUM: 合計値 -
AVG: 平均値 -
MAX: 最大値 -
MIN: 最小値
SELECT age, COUNT(id) FROM test_table GROUP BY age;
2.9 結合
SQLでは、複数のテーブルを結合してデータを取得することができます。
まず、新しいテーブルを作成します。
CREATE TABLE public.char_organization (
char_id int8 NOT NULL,
organization varchar NOT NULL,
CONSTRAINT char_organization_unique UNIQUE (char_id,organization),
CONSTRAINT char_organization_test_table_fk FOREIGN KEY (char_id) REFERENCES public.test_table(id) ON DELETE CASCADE ON UPDATE CASCADE
);
以下のリンクからCSVをダウンロードし、新しいテーブルにデータをインポートしてください。
ダウンロードリンク
結合を行うには、JOIN を使用します。
SELECT [カラム名] FROM [テーブル名1] JOIN [テーブル名2] ON [テーブル名1].[カラム名] = [テーブル名2].[カラム名];
実際に先ほど作成したテーブルと結合を行ってみましょう
SELECT * FROM test_table JOIN char_organization ON test_table.ID = char_organization.char_id;
JOIN では指定したキー(ここではtest_tableのIDとchar_organizationのchar_id)が一致するレコード同士が結合されて抽出されます。
PostgreSQLの JOIN は正確には INNER JOIN であり、SQLには以下の4つの結合方法があります。
-
INNER JOIN: 両方のテーブルに一致するレコードのみを取得 -
LEFT JOIN: 左側のテーブルのすべてのレコードと、それに一致する右側のレコードを結合したものを取得 -
RIGHT JOIN: 右側のテーブルのすべてのレコードと、それに一致する左側のレコードを取得 -
FULL JOIN: 両方のテーブルのすべてのレコードを取得 -
CROSS JOIN: 一致不一致にかかわらずすべての組み合わせを取得
詳細はこちらを参考
2.10 トランザクション
トランザクションとは、複数のSQL文をひとまとまりの処理として実行する仕組みです。実行結果は失敗か成功のどちらかで、処理の途中で終了することはありません。
トランザクションを利用することで、データの整合性を保つことができます。
わかりやすい解説↓
BEGIN;
INSERT INTO test_table (id, name, age) VALUES (30, '禪院直毘人', 71);
INSERT INTO char_organization (char_id, organization) VALUES (30, '禪院家');
COMMIT;
左側のSQLスクリプトを実行するをクリックして、SQL全体を実行してください

トランザクション中に問題が発生した場合は、ROLLBACK で処理をキャンセルすることができます。
ROLLBACK;
参考文献・引用元
-
[1] PostgreSQL Global Development Group.
PostgreSQL: The World's Most Advanced Open Source Relational Database. PostgreSQL. https://www.postgresql.org/ -
[2] 日本テレビ「HUNTER×HUNTER|日本テレビ」(最終閲覧: 2024/07/03)
https://www.ntv.co.jp/hunterhunter/character/index.html -
[3] 呪術部「呪術廻戦年齢一覧!誕生日も見てみる」(最終閲覧: 2024/07/03)
https://jujutsu-bu.com/character-age-birthday/ -
[4] 日本PostgreSQLユーザ会「PostgreSQL 16.0文書」(最終閲覧: 2024/07/03)
https://www.postgresql.jp/document/16/html/ -
[5] 「分かりそう」で「分からない」でも「分かった」気になれるIT用語辞典「トランザクションとは」(最終閲覧: 2024/07/03)
https://wa3.i-3-i.info/word142.html