Jetson TX1のGPUを使用した効能を調査その2として、
Chainerのサンプルに用意されているMNISTの数字認識を実施しました。
コードはこちら(GitHubで公開されてるChainerのサンプルコード)
https://github.com/pfnet/chainer/blob/master/examples/mnist/train_mnist.py
調査内容
計算時間を下記のテスト1~4に対してプログラムの処理時間を測定する
※Jetson TX1の場合の処理時間です
テスト1 CPUとGPUの比較
- Jetson TX1のCPUでMNIST
- Jetson TX1のGPUでMNIST
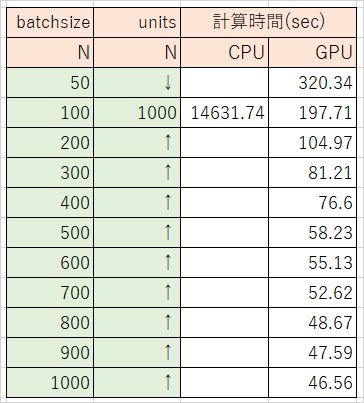
テスト2 バッチサイズ(batchsize)を変化
- GPUを使用
- デフォルト: 100
- 条件: 50, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000
テスト3 中間層のノード数(units)を変化
- GPUを使用
- デフォルト: 1000
- 条件: 100, 500, 1000, 1500, 2000
テスト4 batchsizeとunitsの組み合わせを変化
- GPUを使用
- バッチサイズ: 100, 1000
- 中間層のノード数: 500, 1000, 2000
調査方法
計算時間の測定方法
pythonコードを呼び出す際、コマンドラインから以下を実行する
$ time python train_mnist.py
すると、こんな感じで結果が出力される
$ time python test.py
real 1m2.345s
user 1m1.111s
sys 0m0.003s
今回は「プログラム自体の処理時間」に注目したいのでuserで示された時間を評価指標とします。
(参考)timeコマンドでプログラムの実行時間を知る:http://qiita.com/tossh/items/659e5934e52b38183200
測定条件の変更方法
「train_mnist.py」の31~43行目で、本プログラムを呼び出す際のオプション(追加の引数)についての説明が記載されている。
デフォルトの値を使用するときはオプションを指定しなくてもいい。
- (例)バッチサイズ(batchsize)を1000、中間層のノード数(units)を200としたいとき
- コマンドラインにて「python train_mnist.py -b 1000 -u 200」として実行
# 省略
# ↓31~43行目
parser.add_argument('--batchsize', '-b', type=int, default=100,
help='Number of images in each mini-batch')
parser.add_argument('--epoch', '-e', type=int, default=20,
help='Number of sweeps over the dataset to train')
parser.add_argument('--gpu', '-g', type=int, default=-1,
help='GPU ID (negative value indicates CPU)')
parser.add_argument('--out', '-o', default='result',
help='Directory to output the result')
parser.add_argument('--resume', '-r', default='',
help='Resume the training from snapshot')
parser.add_argument('--unit', '-u', type=int, default=1000,
help='Number of units')
args = parser.parse_args()
# 省略
CPUとGPUの切り替え
- CPUを使用する場合
- コマンド「python train_mnist.py -g -1」=> 「GPU使いません」宣言
- (デフォルトがGPUを使用しない設定なので、「time python train_mnist.py」でいい)
- GPUを使用する場合
- コマンド「python train_mnist.py -g 0」=> 「GPU使います」宣言
バッチサイズの変更
- コマンド「python train_mnist.py -b 1000」
- デフォルトのバッチサイズは100
中間層のノード数の変更
- コマンド「python train_mnist.py -u 2000」
- デフォルトの中間層のノード数は1000
調査結果
GPUを使うとNMINSTの学習はすごく速くなる。
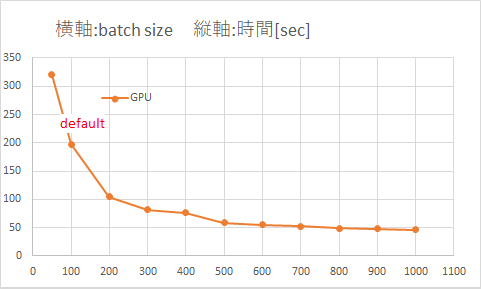
バッチサイズを大きくすると計算時間は速くなりますが、ある程度大きくするとそれ以降は劇的な変化はない。
(おそらく中間層のノード数に近づくに連れ軽減率が小さくなっている)
中間層のノードを2倍に増やしても計算時間は10%しか増加しない。
※Jetson TX1の場合の処理時間です
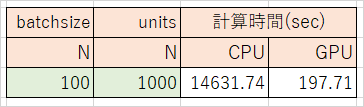
テスト1 CPUとGPUの比較
CPUに対しGPUを使用すると74倍速い、凄い!!
(デフォルトの条件で測定)
テスト2 バッチサイズ(batchsize)を変化
テスト3 中間層のノード数(units)を変化
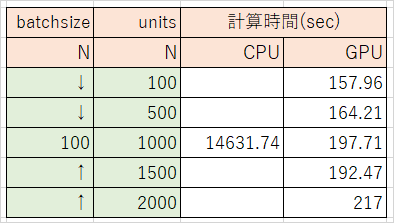

テスト4 batchsizeとunitsの組み合わせを変化
(全てGPUを使用)
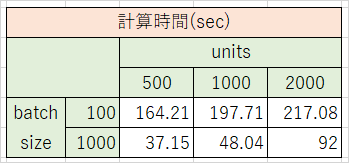
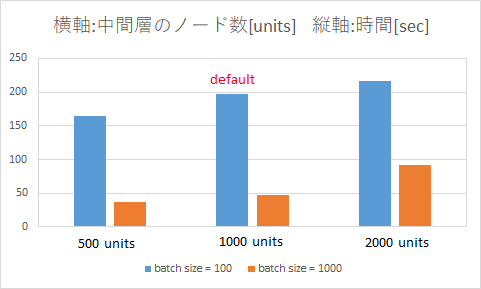
(おまけ)Windows PCでMNIST
- デフォルトの条件で約30分
- GPU: なし、CPU:Core i7 2.4GHz 4コア、RAM: 8GB
おわりに
なかなか面白い結果となった気がします。
中間層の数が20倍(units=100と2000で比較)の大きなネットワークでも計算時間は30%程度しか変わらないのも衝撃でした。