うまく説明出来てないかもしれませんが、ざっくりとニュアンスを組み取って頂けたら嬉しいです。
stereo depthについてもまとめたので、気になる方はどうぞ
https://qiita.com/minh33/items/55717aa1ace9d7f7e7dd
https://qiita.com/minh33/items/6b8d37ce08f85d3a3479
目次
1. Depth Estimation 2. Image warp 3. LossDepth Estimation
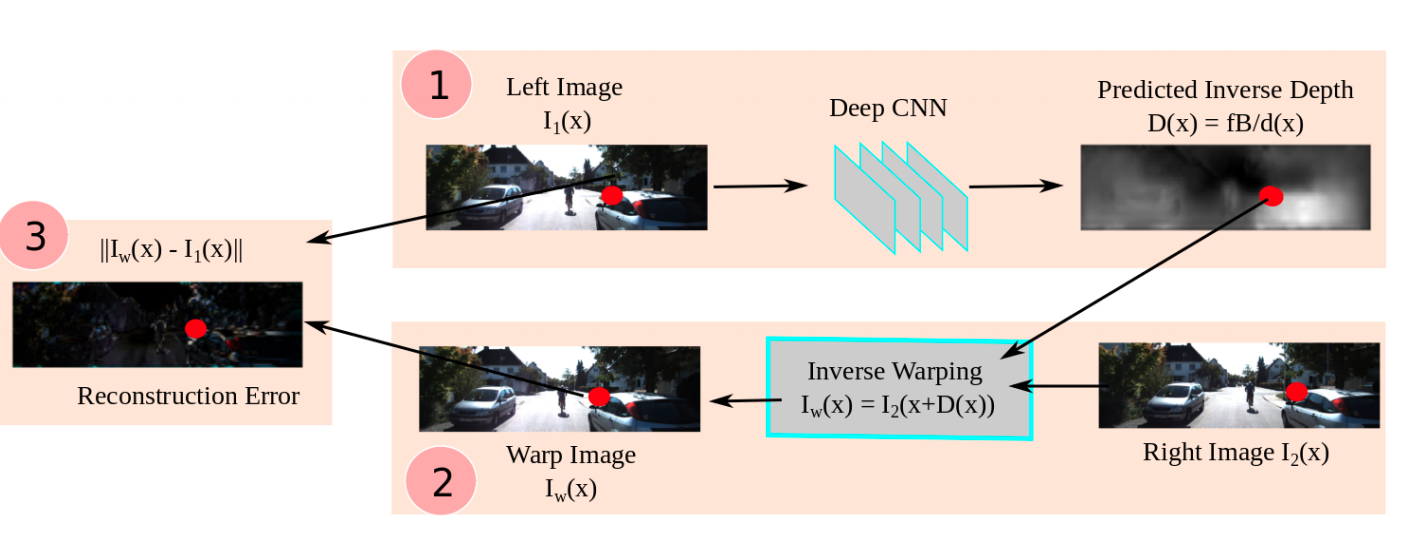
人が片目で物体の大まかな位置が分かるように単眼のカメラでも位置を推定することが出来ます。例えば、カメラの角度を固定しておけば、近い物は画像のしたの方に位置していて、遠いものは画像の上の方に位置しています。基本的に物体は地面の上にあるので、接地面の距離がわかれば物体の位置も推定出来ます。他には物体間の相対位置や物体の大きさなども情報として使えます。CNNを用いて学習しているので、実際どんな情報を得てモデルが推定してるかはわかりにくいのですが、実験をしたという面白い論文があったので興味のある人は是非Image warp
単眼の場合
カメラを載せた車が動く事によって、一つ前のフレームに変換することが出来ます。まずt=tの時の画像の距離をネットワークで推定します。距離を推定出来たので3次元のポイントクラウドを計算する事が出来ます。カメラを載せた車の移動量を自己位置推定を使い求めます。自己位置推定はVSLAM、オドメトリー、GPS、IMUなどが使えます。x,y,z,roll,pitch,yawの1フレームの変化量を先程計算した3次元ポイントクラウドをTransfomationする事によって、t=t-1の3次元ポイントクラウドを推測する事が出来ました。それをImage Viewに変換する事で、t=tの画像をt=t-1の画像にwarpさせる事が出来ます。ただし自分が動いていいないと学習出来ないのと、相手の物体が動いているとwarpしてもずれてしまうというデメリットもあります。
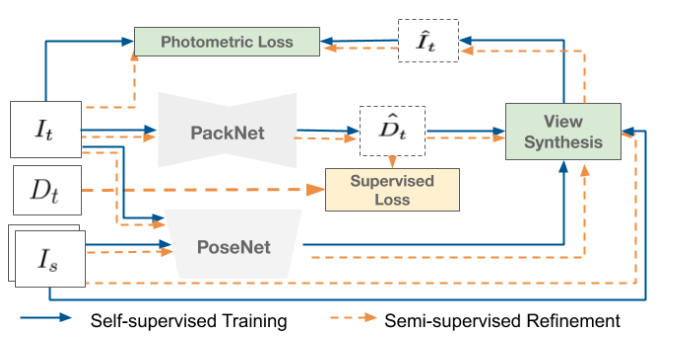
It=>target Image(t=t)
Is=>source Image(t=t-1)
Dt=>target Depth(LiDARを用いた距離のGround Truth)
D^t=>Estimated target Depth
I^t=>Estimated target Image
View Synthesis=>画像のReconstruction
Photometric Loss=>推定画像と実際の画像の比較
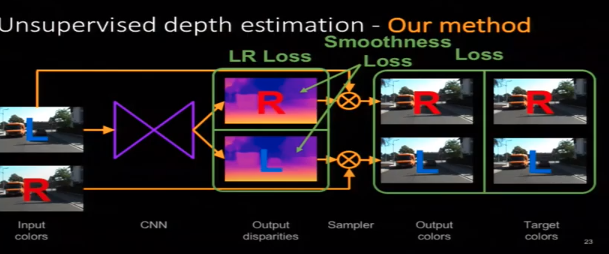
3番でLossを計算する為に使われるのですが、求めたDepthをDisparityに変換し、右の画像を左の画像にワープさせることが出来ます。ちなみにmono depthなのに双眼なのって?って思う人もいると思うんですが、距離推定は単眼で行い、学習のGround Truthとして反対のレンズを使います。
Lossの定義
[Unsupervised Monocular Depth Estimation with Left-Right Consistency(2017)
]( https://arxiv.org/pdf/1609.03677.pdf')monodepthで多分この論文が一番有名
・ Reconstruction Loss
右の画像を推定した左のDisparityを用いてwarpする事によって左のReconstruction画像が出来る。その画像と左の入力画像のSADとSSIMを計算する。逆も行う
・LR Consistency Loss
右のDisparity Mapを左のDisparity MapへとwarpさせてDisparityの絶対値の差を計算する。逆も行う
・Smoothness Loss
近傍のPixelのDisparity(Depth)は同一物体であればほぼ同じであるはずなので、Laplacian Smoothnessなどを用いてDisparityのSmoothnessを計算する。右と左のDisparityMapそれぞれで行う。