Stereo CameraによるDepth(Disparity)推定についてざっくりと流れをまとめて見ました!
一般的なstereo matchingについては前の記事をどうぞ
https://qiita.com/minh33/items/55717aa1ace9d7f7e7dd
Depth Estimationのプロセス
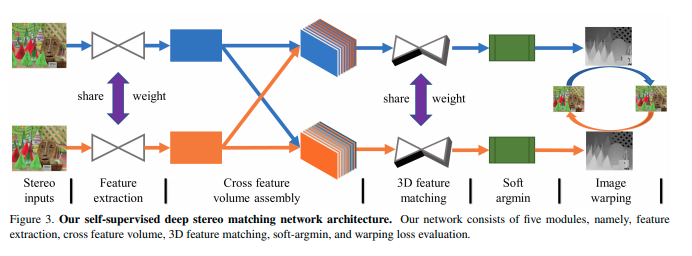
1. Feature Extraction =>左右同じNetwork,同じweightを使って特徴取り出す(WxHxC)。ex)intensity, shape, .....etc 2. Cost Volume =>Pixelをshiftする事でDisparity Channelを作る(DxWxHxC)。 Dは任意の値で、取り得る最大Disparity(pixel)を自分で決める。大きすぎると重くなるし、小さすぎると近い物体のマッチングがされない。 3. 3D Feature Matching =>求めた特徴量を(DxWxHxC)を畳み込む事で右と左の特徴量が近い所に大きな値が出るよう学習する(DxWxHx1) 4. Disparity Regression =>(DxWxH)から(1xWxH)に変換して最終的なDisparityを求める 5. Lossを計算する =>Ground TruthにLiDARを使うか左と右の画像をwarpすることでLossを計算する。最近では画像のみで学習するのが多く見られる。
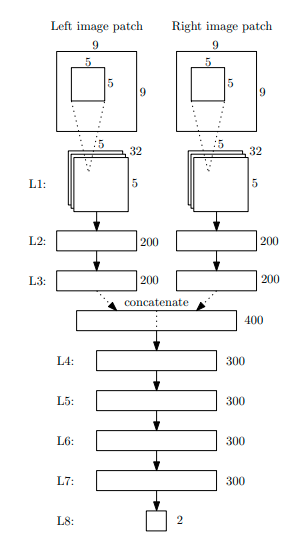
Computing the Stereo Matching Cost with a Convolutional Neural Network(2015)
右と左の画像の特徴量をintensityの代わりにconvolutionすることによって、多チャンネルの特徴量に代替することによって精度を向上
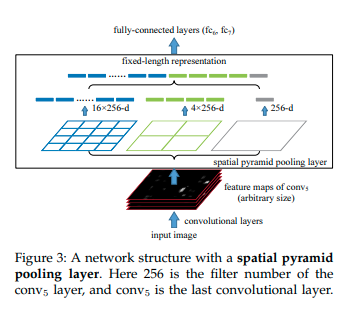
Spatial Pyramid Pooling in Deep Convolutional
Networks for Visual Recognition(2015)
近くの物体をmatchingさせるためにはより広範囲のpixelを参照しなければいけない。その解決方法として特徴量マップの解像度を細かいものと粗いものを結合させることにより解決
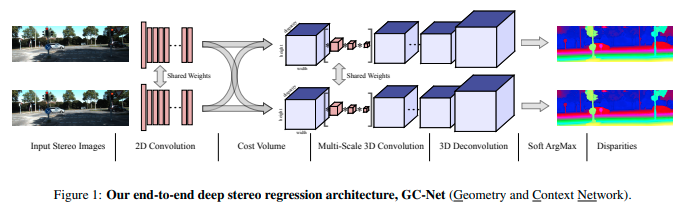
End-to-End Learning of Geometry and Context for Deep Stereo Regression(2017)
今までと同じように右と左の画像をそれぞれに同じweightを使って畳込み特徴量マップ(WxHxC)を生成。右の画像に対して左の画像のpixelを0~maxDisparity(任意)まで横にshiftさせた特徴量マップ(DxWxHxC)を作る。単純にpixelを横(width方向)にシフトするだけ。3D Convolutionと3D Deconvolutionを1/2,1/4,1/8,1/16,1/32で行う事によって大まかな特徴と細かい特徴を学習できる。ここでの出力が(DxHxW)となる。1次元になったmatchingの値にDisparityを掛けて重み付け平均を取ることで最終的なDisparityを出力する。softArgMinによりsub-pixel accuracyでDisparityを求めることが可能になった。
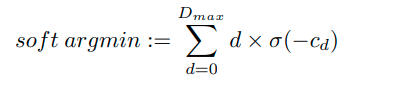
Self-Supervised Learning for Stereo Matching with Self-Improving Ability(2017)
今までLossを求めるのにDisparityまたはDepthをLiDARから得ていた。LiDARの密度は画像よりも粗く、LiDARを用いないシステムでもTrainingをする為、右の画像を推定した右のDisparityだけpixelをshiftすることによって、左の画像を擬似的に生成する。生成された左の画像と、元の左の画像をSAD(intensityまたはRGBの差)やSSIM(構造的類似性)を見ることで、Lossを定義出来る。Disparityが正しく推定出来ているのであれば、warpをした画像はほぼ反対の画像と同じになる。