[前回] AWS公式資料で挑むMLS認定(12)-Amazon SageMaker Studio
はじめに
Amazon SageMakerチュートリアルを2回実施し、MLモデル操作の感触を掴みました。
今回から、機械学習ワークフローの各フェーズに対し、細部を深掘りします。
その前に、AWS Well-Architectedフレームワークに含まれる機械学習レンズの勉強です。
ベストプラクティスに従って、機械学習ワークロードを確実に設計するための、
キーファクターが明記されているようです。熟読しなくちゃ。
機械学習レンズとは
※ 引用元: AWS Well-Architected
- AWS Well-Architectedとは
- アーキテクチャのベストプラクティスを使って、学習、測定、構築を行う
- クラウドアーキテクトがアプリケーションやワークロードで必要な、インフラストラクチャの構築を支援
- 安全性、性能、耐障害性、効率性を備えている
- アーキテクチャ評価、スケーラブル設計を実装するための一貫したアプローチを提供
- 6つの柱に基づく
- 運用効率
- セキュリティ
- 信頼性
- パフォーマンス効率
- コストの最適化
- 持続可能性
- AWS Well-Architected Frameworkとは
- クラウド上のワークロード設計と実行における
- 主要概念
- 設計原則
- アーキテクチャのベストプラクティス
- いくつかの基本的な質問に答えると
- アーキテクチャにおいて、クラウドベストプラクティスがどの程度実践できているかを把握できる
- 改善のためのガイダンスを得ることができる
- ドメイン別、下記固有内容が含まれている
- レンズ
- ハンズオンラボ
- AWS Well-Architected Tool
- クラウド上のワークロード設計と実行における
- AWS Well-Architectedレンズとは
- AWS Well-Architectedが提供するガイダンスを、特定業界やテクノロジー領域に広げる
- 機械学習(ML)、データ分析、サーバーレス、IoTなど
- ワークロードの完全評価には
- AWS Well-Architected Frameworkと6つの柱とともに、適切なレンズを使用
- AWS Well-Architectedが提供するガイダンスを、特定業界やテクノロジー領域に広げる
- 機械学習レンズとは
- AWSクラウド上の機械学習ワークロードに対し、下記ポイントに焦点を当てたベストプラクティスを提供
- デザイン
- デプロイ
- 設計方法
- AWSクラウド上の機械学習ワークロードに対し、下記ポイントに焦点を当てたベストプラクティスを提供
機械学習ワークロードの構築
評価対象となる領域
- 機械学習スタック
- MLワークロードのフェーズ
機械学習スタックとは
機械学習ワークロード構築で選択可能な抽象化レベル
- 人工知能(AI)サービスレベル
- APIコールを使用しワークロードにML機能をすばやく追加可能な、フルマネージドサービスが提供される
- MLの知識がなくても利用できる
- 事前トレーニング済み、または自動的にトレーニングされる機械学習モデルと深層学習モデルに基づいているため
- 強力でインテリジェントなアプリケーションを構築できる
- コンピュータビジョン
- 音声
- 自然言語
- チャットボット
- 予測
- レコメンデーション
- APIコールを用いてアプリケーションと統合できるAIサービス
- テキストコンテンツの翻訳やローカライズ: Amazon Translate
- テキストの読み上げ変換: Amazon Polly
- 対話型チャットボット: Amazon Lex
- 機械学習(ML)サービスレベル
- デベロッパー、データサイエンティスト、および研究者に対し、機械学習マネージドサービスとリソースが提供される
-
差別化につながらない重労働に相当するインフラストラクチャ管理は、クラウドベンダーによって管理される- データサイエンスチームは機械学習ワークフローの得意分野に集中できる
- Amazon SageMakerを使用することで
- デベロッパーとデータサイエンティストが任意規模のMLモデルを構築、トレーニング、およびデプロイできる
- Amazon SageMaker Ground Truth
- 高精度のMLトレーニングデータセットの構築支援
- Amazon SageMaker Neo
- デベロッパーがMLモデルを1度だけトレーニングし、
- クラウドの任意場所、またはエッジで実行できる
- Amazon SageMaker Ground Truth
- デベロッパーとデータサイエンティストが任意規模のMLモデルを構築、トレーニング、およびデプロイできる
- MLフレームワーク&インフラストラクチャレベル
- 機械学習プラクティショナーが対象
- 機械学習プラクティショナーとは、モデルトレーニングに必要なデータ使用におけるエキスパート
- モデルを構築/トレーニング/チューニング/デプロイするための、独自ツールとワークフロー設計をスムーズに行い
- フレームワークレベルとインフラストラクチャレベルでの作業に慣れている想定
- 利用可能なオープンソースMLフレームワーク
- TensorFlow
- PyTorch
- Apache MXNet
- 深層学習AMIと深層学習コンテナには、パフォーマンス最適化された複数MLフレームワークが事前インストールされている
- 強力かつML最適化されたコンピューティングインフラストラクチャ上でいつでも起動可能
- Amazon EC2 P3およびP3dnインスタンスなど
- 最適化により、機械学習ワークロードの速度と効率を高める
- 強力かつML最適化されたコンピューティングインフラストラクチャ上でいつでも起動可能
- 機械学習プラクティショナーが対象
- 上述三つのレベルの組み合わせ
- ワークロードで、複数レベルのMLスタックからのサービスを使用可能
- ビジネスユースケースに応じ、複数要件を満たし、複数ビジネス目標を達成するため
- 異なるレベルのサービスとインフラストラクチャを組み合わせる
MLワークロードのフェーズ
-
MLワークロードの構築と運用は反復的なプロセスで、複数フェーズで構成される
-
Cross Industry Standard Process Data Mining(CRISP-DM)のオープン標準プロセスモデルを基準する
- CRISP-DMをベースラインとする理由
- 業界で実証済みのツール
- アプリケーションに依存しない
- さまざまなMLパイプラインとワークロードに適用できる
- 使用しやすい手法である
- CRISP-DMをベースラインとする理由
-
MLワークロードのフェーズ
※ 引用元: AWS Well-Architectedフレームワーク
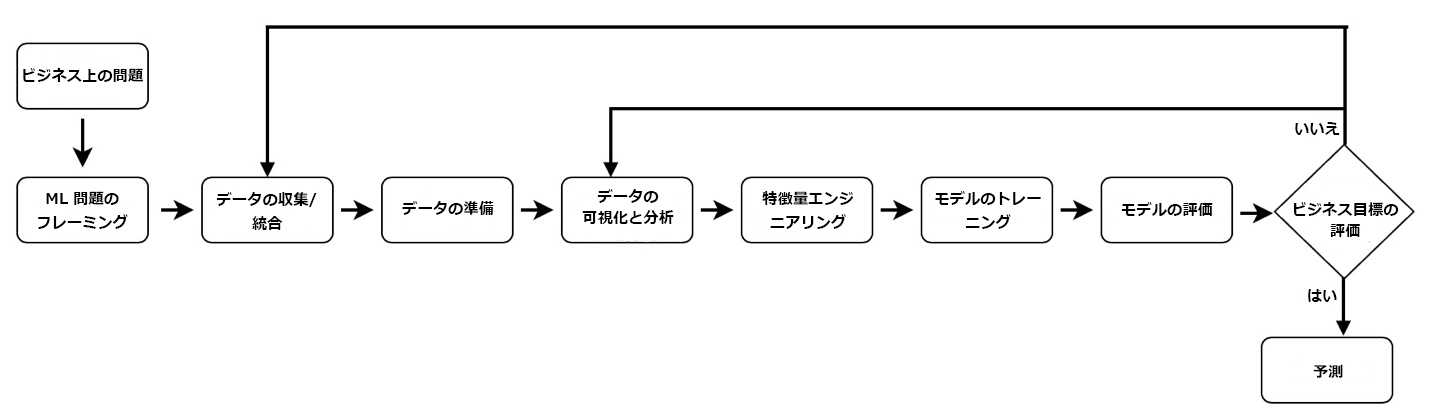
エンドツーエンド機械学習プロセスのフェーズ
- ビジネス目標の特定
- ミッション
- 最も重要なフェーズ
- 解決すべき問題と、その問題をMLで解決することで得られるビジネス価値を明確に把握する必要あり
- 具体的なビジネス目的や成功の基準に対し、ビジネス価値を測定/評価できることが求められる
- ベストプラクティス
- ビジネス要件を理解
- ビジネスに関する質問を形成
- プロジェクトにおけるML実行可能性とデータ要件を判断
- データ取得、トレーニング、推論、および誤った予測にかかるコスト評価
- 同様の分野における実証済み、または公開済みの業績をレビュー(利用できる場合)
- 許容可能なエラーを含む主要パフォーマンスメトリクスを決定
- ビジネスに関する質問に基づき機械学習タスクを定義
- 重要かつ必須の機能を特定
- ミッション
- ML問題のフレーミング(問題定義とアプローチ策定)
- ミッション
- ビジネス問題を機械学習問題として定義
- 観測/予測対象を決定(ラベルまたはターゲット変数)
-
パフォーマンス/エラーメトリクスを最適化する方法を決定 - 例:
- ビジネス目標: 利益を最大化する製品を特定したい
- 問題定義: 製品の将来の売上を予測
- アプローチ: MLを使用し問題解決
- ベストプラクティス
- プロジェクト成果に対する基準を定義
- 観測可能、数量化可能なパフォーマンスメトリクスを確立
- 精度、予測レイテンシー、インベントリ値(資産情報?)の最小化など
- 入力/出力、パフォーマンスメトリクスの最適化に関するML問題を策定
- MLが実現可能かつ適切なアプローチであるか評価
- データ収集/アノテーション目標の作成/達成のため戦略策定
- アノテーションとは、機械学習において極めて重要な
前処理- さまざまな形態のデータにタグ付けを行うプロセス
- タグ付けされたデータを教師データと呼ぶ
- アノテーションとは、機械学習において極めて重要な
- 解釈/デバッグ/処理可能なシンプルなモデルから始める
- ミッション
- データ収集
- データの三つの重要役割
- システム目標を定義: 出力の表現と、入力/出力ペアで入出力の関係性
- 入力と出力を関連付けるアルゴリズムのトレーニング
- トレーニングされたモデルのパフォーマンスを測定し、目標が達成されたか評価
- ベストプラクティス
- データ抽出に必要なソースとステップを詳述
- 数量と品質の両方について、データ可用性を確認
- ダウンストリームで使用するデータの準備前に、データを総合的に理解する
- データガバナンスを定義
- データ所有者
- アクセス権の保有者
- データの適切な使用方法
- オンデマンドで特定データにアクセスし削除可能か
- データ系列を追跡し、後続処理でその場所とデータソースを把握可能に
- データ収集と統合にAWSマネージドサービスを使用
- データ保存にデータレイクなど一元的なアプローチを使用する
- データの三つの重要役割
- データの準備
- ミッション
- MLモデルの善し悪しは、トレーニングに使用するデータに左右される
- データ収集後は、データ統合、アノテーション、準備、処理が重要
- 学習や汎化に最適なトレーニングデータを提供
- AWSは、大規模データのアノテーションとETL(抽出、変換、ロード)関連サービスを提供
- ベストプラクティス
- データ準備は、統計的に有効な小規模サンプルデータセットから始める
- 異なるデータ準備戦略を使って繰り返し実験する
- データクリーニングプロセスで、データ準備全般を通して異常に対するアラート機能
- データ整合性を継続的に強化
- マネージドETLサービスを活用
- ミッション
- データの視覚化と分析
- ミッション
- データ理解のため、パターン認識が重要
- 視覚化ツールを使用し、データ理解を深める
- 表やグラフを作成する前に、表示対象を決める
- 例えば、主要業績評価指標(KPI)、関係性、比較、分布、構成などの情報
- ベストプラクティス
- データのプロファイリングを行う(分類別 vs. 序数的 vs. 定量的視覚化)
- 序数とは、順番の中での位置、並ぶもの中での順序を指す
- 基数とは、どれくらいの数があるのか、その量を測ること
- ユースケース(データサイズ、データの複雑性、リアルタイム vs. バッチ)に適したツール、またはツールの組み合わせを選択
- データ分析パイプラインを監視
- データに関する仮定を検証
- データのプロファイリングを行う(分類別 vs. 序数的 vs. 定量的視覚化)
- ミッション
- 特徴量エンジニアリング
- ミッション
- データ固有の属性は、すべて特微と見なされる
- 例えば、顧客データには、住所、年齢、所得、購入履歴などの特微(属性)が存在
- 特徴量エンジニアリングとは、機械学習や統計的モデリングを用いて予測モデル作成時に、変数を選択して変換するプロセス
- 特徴量エンジニアリングの四つのプロセス
- 特徴作成: 問題と関連するデータセット内の特徴を特定
- 特徴変換: 欠落している特徴、または無効な特徴の置き換えを管理
- 使用される手法:
- 特徴デカルト積の形成
- 非線形変換(数値変数のカテゴリへのビン分割など)
- ドメイン固有特徴の作成
- 使用される手法:
- 特徴抽出: 既存の特徴から新しい特徴を作成
- 特徴の次元削減が目的
- 特徴選択: データセットから無関係な特徴、冗長な特徴をフィルタリング
- 分散または相関のしきい値を観察し、削除対象の特徴を判断
- データ固有の属性は、すべて特微と見なされる
- ベストプラクティス
- 内容領域専門家の力を借りて、特徴の実行可能性と重要性を評価
- 冗長な特徴と無関係な特徴を除去(データノイズと相関関係を減らすため)
- コンテキスト全体で汎化可能な特徴から始める
- モデルを構築しながら以下検討を繰り替えす
- 新しい特徴
- 特徴の組み合わせ
- 新しいチューニング目標
- ミッション
- モデルのトレーニング
- ミッション
- 問題に適した機械学習アルゴリズムを選択し、MLモデルをトレーニング
- 学習用トレーニングデータをアルゴリズムに提供し、トレーニングプロセスを最適化するためのモデルパラメータを設定
- トレーニングアルゴリズムにおける、トレーニングエラーや予測精度などメトリクスを計算
- メトリクスを用いて以下を判断
- モデルが効率的に学習しているか
- 未知データ予測のため適切な汎化を行っているか
- メトリクスを用いて以下を判断
- ベストプラクティス
- モデルトレーニング前にモデルのテスト計画を策定
- トレーニングに必要なアルゴリズムのタイプを明確に理解
- トレーニングデータがビジネス課題を表現可能か確認
- トレーニングのデプロイにマネージドサービスを使用
- 増分学習、または転移学習戦略を適用
- 増分学習(Incremental learning)とは、学習済みのモデルを追加で学習させる手法
- 転移学習(Transfer Learning)、ある領域の知識を別の領域の学習に適用させる技術
- 評価指標による測定結果、大幅に改善されていない場合
- 過学習を避け、コスト削減のため、早い時期にトレーニングジョブを中止
- モデルのパフォーマンスは時間の経過とともに劣化する可能性あり
- トレーニングメトリクスを注意深く監視する
- 自動モデルチューニングのマネージドサービスを活用
- ミッション
- モデル評価とビジネス評価
- ミッション
- モデルを評価し、そのパフォーマンスと精度がビジネス目標の達成を可能にするか判断
- 異なる方法で複数モデルを生成し、各モデルの有効性を比較評価
- モデルごとに異なるビジネスルールを適用し、各モデルの適合性を判断
- モデルに必要なのは特異度かまたは感度かを評価
- モデルの評価指標
- 感度(sensitivity)は、陽性のデータを正しく陽性と予測した割合
- 特異度(specificity)は、陰性のデータを正しく陰性と予測した割合
- 精度(accuracy)は、データ(陽性と陰性のデータに限定せず)を正しく予測できた割合
- 偽陽性(false positive rate)は、陰性データを間違って陽性と予測した割合
- 適合率(precision)は、陽性と予測したデータのち、本当に陽性データである割合
- モデルの評価指標
- マルチクラスモデルの場合、各クラスのエラー率を個別評価
- モデルは、履歴データ(オフライン評価)またはライブデータ(オンライン評価)を使用し評価
- 評価結果に基づき、データ、アルゴリズム、または両方を微調整
- データ微調整には、データクレンジング、準備、および特徴量エンジニアリングの概念を適用
- モデルを本番環境にデプロイし、モデルに対し推論(予測)を行う
- ベストプラクティス
- 成功の測定方法を明確に理解
- ビジネス面での期待に照ら合わせ、モデルメトリクスを評価
- 本番環境へのデプロイ(モデルのデプロイとモデルの推論)を計画し実行
- 本番環境でのモデルパフォーマンスを監視し、ビジネス面の期待と比較
- トレーニング中と本番環境におけるモデルパフォーマンスの違いを監視
- モデルパフォーマンスにおける変化が検出された場合、モデルを再トレーニング
- 例えば、売上の期待と今後の予測は、新しい競合他社の出現によって変化する可能性あり
- データセット全体の推論を取得したい場合、ホスティングサービスに代わるものとしてバッチ変換を使用
- Amazon SageMakerのホスティングサービスでは、モデルを独立してデプロイし、アプリケーションコードから分離
- Amazon SageMakerのバッチ変換機能は、ペタバイトのデータに対して非リアルタイムシナリオで予測を行う
- 本番環境バリアントを活用し、A/Bテストを使ってさまざまな新しいモデルをテスト
- バリアントとは、エンドポイントにデプロイするモデルのこと
- ミッション
機械学習ワークロードの設計原則
- 高品質データを使ったデータセットの可用性を用いて俊敏性を実現
- データサイエンスワークロードでは、デリバリーパイプラインの全フェーズにライブデータまたはバッチデータへのアクセスが必要
- データ検証と品質管理を用いたメカニズムを実装し、データへのアクセスを可能に
- シンプルなものから始め、実験を通して進化させる
- 少数の特徴から始める
- 複雑なモデルから開始し特徴の影響を見失う、ような失敗を回避できる
- シンプルなモデルを選択し、プロセス全体を通して一連の実験を実行
‐ モデルトレーニングと評価をモデルホスティングから分離
- モデルトレーニング、モデル評価、モデルホスティングを行うリソースを分離
- データサイエンスライフサイクルにおける特定フェーズに即したリソースを選択可能
- 少数の特徴から始める
- データドリフトを検出
- モデルが本番環境に移行した後も推論の精度を継続的に測定
- ML使用データは複数ソースから取得される
- データ型と意味は、アップストリームのシステムとプロセスの変更に伴って変化する可能性あり
- 適切な措置を講じるため、このような変化を検出するメカニズムを設定
- トレーニングと評価のパイプラインを自動化
- オートメーションにより、自動的なモデルトレーニングとアーティファクト作成をトリガー可能
- 複数のエンドポイント環境にコンスタントにデプロイ
- モデルの再トレーニングアクティビティをトリガーするオートメーション適用について
- 人為的ミスを低減し、モデルパフォーマンスの継続的な改善をサポート
- オートメーションにより、自動的なモデルトレーニングとアーティファクト作成をトリガー可能
- より高い抽象化を選ぶことで、より迅速に成果を達成
- AI/MLサービス選択は、まずはサービスの適切性を評価
- つぎ、ビジネス目的を満たし、開発コスト削減可能なメカニズムか評価
おわりに
機械学習レンズにより提供されるMLワークフローのベストプラクティス、および設計原則を理解しました。
次回も、Amazon SageMakerの勉強が続きます。お楽しみに。