[前回] AWS公式資料で挑むMLS認定(13)-機械学習レンズ(AWS Well-Architectedフレームワーク)
はじめに
今回は、機械学習ワークフローのデータ準備フェーズに含まれる、
データラベリングを勉強します。
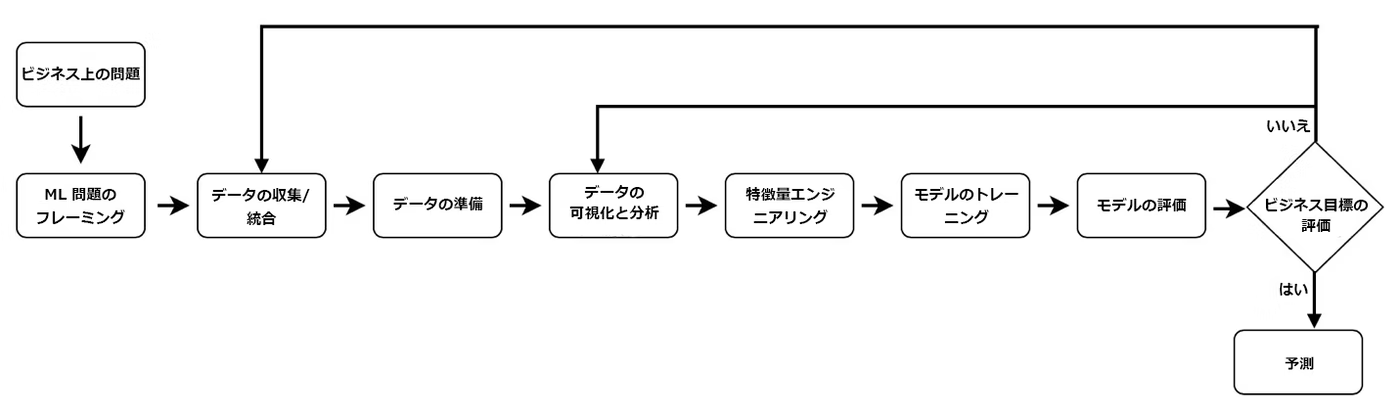
おさらい: 機械学習(ML)ワークロードのフェーズ
※ 引用元: AWS Well-Architectedフレームワーク
データラベリングとは
- データラベリングとは
- ドキュメント、テキストおよびイメージのプロパティを識別し、プロパティに注釈を付けるプロセス
- データラベリングの必要性
- 機械学習モデルのトレーニングに、大規模で高品質なラベリングデータセットが必要
- データラベルの例
- ニュース記事
- ツイートのセンチメント(市場や商品などに対する消費者の感想や感情)
- 画像のキャプション(説明文)
- 音声録音で話される重要な言葉
- ビデオのジャンル
Amazon SageMaker Ground Truth
-
Amazon SageMaker Ground Truthとは
- 機械学習モデル用の高品質のトレーニングデータセットを構築
- Ground Truth拡張データラベリング機能
- 自動データラベリングや注釈統合など
- データラベルの精度を向上させ
- データラベリングにかかる総コストを削減
-
機能と特徴
- ラベリングデータセット作成を、ラベリングワーカーに依頼可能
- Amazon Mechanical Turkでベンダー企業を選択
- Amazon Mechanical Turkとは
- リクエスターが、タスクをワーカーに依頼する、アマゾンウェブサービス
- コンピュータプログラムを人間の知能と組み合わせて、コンピュータだけでは不可能な仕事を処理
- Amazon Mechanical Turkとは
- 社内のプライベートワーカーを使用
- Amazon Mechanical Turkでベンダー企業を選択
- 出力されたラベリングデータセットの使用
- Amazon SageMakerモデルのトレーニングデータセットとして使用可能
- 独自のモデルをトレーニング可能
- ラベリングデータセット作成を、ラベリングワーカーに依頼可能
ラベリングワークフロー
- Ground Truth組み込みタスクタイプのワーカータスクテンプレートを使用
- データラベリング自動化をサポート
- 以下特定タイプのラベル生成を、ワーカーに依頼可能
- イメージラベリング
- テキストラベリング
- 動画/動画フレームラベリング
- 3D点群ラベリング
- カスタムラベリングワークフローを使用
- データラベリングワーカーに独自のUIとツールを提供
- 処理手順
- ステップ1: ワークフォースのセットアップ
- ステップ2: カスタムワーカータスクテンプレートの作成
- ステップ3: AWS Lambdaを使用し処理
Amazon SageMaker Ground Truthの使用手順
- ステップ1: 前準備としてデータセットをセットアップ
- 公開HTTP URLで2つのイメージを保存
- ラベリングタスク完了指示書の作成用
- イメージのアスペクト比はおよそ2:1とする
- Amazon S3バケットを作成
- 入力ファイルと出力ファイルを保持
- バケットは、Ground Truth実行リージョンと同じリージョンに存在する必要あり
- Ground TruthのすべてのS3バケットにCORSポリシーがアタッチされている必要あり
- ラベリングジョブ作成ユーザーに必要なアクセス許可ポリシー
{ "Version": "2012-10-17", "Statement": [ { "Sid": "sagemakergroundtruth", "Effect": "Allow", "Action": [ "cognito-idp:CreateGroup", "cognito-idp:CreateUserPool", "cognito-idp:CreateUserPoolDomain", "cognito-idp:AdminCreateUser", "cognito-idp:CreateUserPoolClient", "cognito-idp:AdminAddUserToGroup", "cognito-idp:DescribeUserPoolClient", "cognito-idp:DescribeUserPool", "cognito-idp:UpdateUserPool" ], "Resource": "*" } ] } - 公開HTTP URLで2つのイメージを保存
- ステップ2: ラベリングジョブの作成
- Ground Truthにマニフェストファイルが保存されているS3バケットを指示
- ジョブ用のパラメータを設定
- IAMロールとして、AmazonSageMakerFullAccessポリシーがアタッチされているIAMロールを選択または作成
- ステップ3: ワーカーの選択
- データセットのラベリングを対応するワークフォースを選択
- ワークフォースとは、ラベリングのため選択したワーカーのグループ
- 種類
- Amazon Mechanical Turkワークフォース
- ベンダーが管理するワークフォース
- 独自のプライベートワークフォース
- 下記特定ジョブに割り当てられる作業チームも作成
- Amazon SageMaker Ground Truthのラベリングジョブ
- Amazon Augmented AIの人間によるレビュータスク
- Amazon Cognitoを使用し、プライベートワークフォースとワークチームを管理可能
- または、独自のOpenID Connect(OIDC)のアイデンティティプロバイダー(IdP)を使用可能
- 下記特定ジョブに割り当てられる作業チームも作成
- 種類
- ワークフォースとは、ラベリングのため選択したワーカーのグループ
- データセットのラベリングを対応するワークフォースを選択
- ステップ4: 境界ボックスツールの設定
- ワーカーに指示書を提供
- タスクの内容がわかるタイトルタスクを設定し、ワーカーに高レベルの指示書を提供可能
- クイック指示書と詳細指示書両方を指定可能
- 詳細指示書には、タスク完了のため詳細指示が含まれている
- ワーカーに指示書を提供
- ステップ5: ラベリングジョブの監視
- ラベリングジョブを作成したら、すべてのジョブリストが一覧表示される
- このリストを使用し、ラベリングジョブのステータスを監視可能
- リストのフィールド
- Name: ジョブの名前
- Status: [完了]、[失敗]、[進行中]、[停止]
- Labeled objects/total: ラベリングジョブのオブジェクト数と、ラベリング済みオブジェクト数
- Creation time(作成日時) –ジョブ作成日付と時刻
- ジョブに対し以下操作が可能
- クローン作成
- 連鎖
- 停止
イメージラベリング
Ground Truthを使用し、イメージにラベリング。
使用可能な組み込みタスクタイプ:
-
境界ボックス
- 機械学習モデルのトレーニングに使用するイメージ内には複数オブジェクトが存在
- イメージ内の1つ以上のオブジェクトを分類およびローカライズ
- ローカライズとは、境界ボックスのピクセル位置を意味
- タスクタイプとしてAmazon SageMaker Ground Truth境界ボックスのラベリングジョブを使用

※ 引用元: 境界ボックスラベル付けジョブの作成
-
イメージセマンティックセグメンテーション
- ピクセルレベルでイメージ内容の識別に、セマンティックセグメンテーションのラベリングタスクを使用
- ワーカーはイメージ内のピクセルを定義済みのラベルまたはクラスのセットに分類
- Ground Truthは、単一および複数クラスのセマンティックセグメンテーションのラベリングジョブをサポート
-
自動セグメンテーションツール
- イメージのセグメンテーションとは
- イメージを複数セグメント、またはラベリングピクセルのセットに分割するプロセス
- ピクセルへの色付きフィラ(マスク)適用
- 特定ラベルに該当するすべてのピクセルを識別するプロセスに必要
- イメージのセグメンテーションとは
-
イメージ分類(単一ラベル)
- イメージ分類のラベリングタスクを使用し、イメージごとに1つのラベルを選択
-
イメージ分類(マルチラベル)
- マルチラベルのイメージ分類ラベリングタスクを使用し、イメージ内の複数のオブジェクトを分類
-
イメージラベルの検証
- 高精度のトレーニングデータセットの構築は反復プロセス
- ラベルがグランドトゥルース(実世界で直接観察できるもの)を正確に表すようになるまで
- ラベルを確認し、継続的に調整
テキストラベリング
Ground Truthを使用し、テキストをラベリング。
使用可能な組み込みタスクタイプ:
-
固有表現認識
- 非構造化テキストから情報を抽出し、事前定義されたカテゴリに分類
- Ground Truth固有表現認識(NER)のラベリングタスクを使用
- NERはテキストデータを調べ、名前付きエンティティと呼ばれる名詞句を見つけ、以下にラベルで分類
- person(人)
- organization(組織)
- brand(ブランド)
- タスク対象をテキストのより長いスパンに広げ、指定した定義済みのラベルでシーケンスを分類可能
-
テキスト分類(単一ラベル)
- 記事とテキストを定義済みのカテゴリに分類
- Ground Truthテキスト分類を使用し、独自に定義したカテゴリにテキストを分類可能
-
テキスト分類(マルチラベル)
- 記事とテキストを複数の定義済みカテゴリに分類するには、マルチラベルのテキスト分類タスクタイプを使用
動画/動画フレームラベリング
- Ground Truth動画分類ラベリングタスクを使用
- 指定した定義済みラベルを使用し、ワーカーが動画を分類
- 動画フレーム(動画から抽出された静止画像)に注釈を付ける
- 以下を使用し、動画フレームラベリングジョブの作成プロセスを効率化
- Amazon SageMakerコンソール
- API
- 言語固有のSDK
- 動画フレームのラベリング
- 動画フレームは、動画から抽出された一連のイメージ
- Ground Truth組み込みの動画フレームタスクタイプを使用
- ワーカーが以下使用し、動画フレームに注釈を付けることが可能
- 境界ボックス、ポリライン、ポリゴン、または特徴点
- 動画フレームオブジェクト検出
- 一連の動画フレーム内のオブジェクトを特定し検索
- 動画フレームオブジェクト追跡
- 一連の動画フレーム内のオブジェクトの動きを追跡
3D点群ラベリング
-
3D点群とは
- 点からなる3次元(3D)のビジュアルデータで構成される
- それぞれの点は、通常、x、y、zの3つの座標で示される
- 追加の属性を使用し、点群に色や点の反射強度の違いを追加
- 反射強度
- r(赤)、g(緑)、b(青)の8ビットのカラーチャネルの値
- 3D点群のラベリングジョブを作成時は、点群データと必要に応じてセンサーフュージョンデータを指定
- 点からなる3次元(3D)のビジュアルデータで構成される
-
3D点群ラベリングジョブで、処理可能な3D点群オブジェクト
- 3Dセンサーから作成した3D点群オブジェクト
- LiDAR(Light Detection and Ranging)センサー
- 深度カメラ
- 3D再構成によって作成した3D点群オブジェクト
- ドローンなどエージェントで収集した画像を組み合わせる
- 3Dセンサーから作成した3D点群オブジェクト
データセットの保存場所
Amazon S3バケットに保存される。
- ラベリング対象データ
- Ground Truthがデータファイルの読み取りに使用する入力マニフェストファイル
- 出力マニフェストファイル
- 出力ファイルには、ラベリングジョブの結果が含まれる
ラベリングジョブのイベント
Amazon CloudWatchの/aws/sagemaker/LabelingJobsグループに表示される。
CloudWatchは、ラベリングジョブ名をログストリームの名前として使用。
ラベリングの自動化
- オプションで
自動データラベリングを使用- 人間によるラベリングが必要なデータを、Ground Truthで機械学習を使用し決定するプロセス
- 自動データラベリングにより、ラベリング時間と手作業を減らせる
おわりに
データ準備フェーズに含まれる、データラベリングを勉強しました。
次回も続きます。お楽しみに。