[前回] 自然言語処理モデルBERTの検証(2)-MeCab+WordPiece
はじめに
今回は、GLUEベンチマークのタスクをBERTを使って解いてみます。
GLUEベンチマーク(General Language Understanding Evaluation)とは、英語圏における自然言語処理の標準ベンチマークです。
予め用意された自然言語理解タスクを使ってモデルの文章読解能力を測ることで、自然言語処理技術をスコアにて評価/比較するためのものです。

タスクには、GLUEとSuperGLUEの2種類があり、GLUEでAIのスコアが人間を超えたため、SuperGLUEが設計されたそうです。
評価対象の文章読解には、「構文チェック」、「同義言い換え」、「質疑応答」、「感情解析」などが含まれています。
例えば下記文章は構文エラーと判定されるべきです。
Max ate the apple and Sally the hamburgers.
検証シナリオ
TensorFlow Hub(TFHub)のチュートリアルを参考に、BERTを用いてGLUEタスクを解決してみます。
このチュートリアルでは、ColabのTPU上で高速学習を実現しています。
https://colab.research.google.com/github/tensorflow/text/blob/master/docs/tutorials/bert_glue.ipynb
いくつか用語の確認
- ファインチューニングとは、学習済みモデルの一部もしくはすべての層の重みを微調整する手法
- TensorFlow Hubは、トレーニング済み機械学習モデルのリポジトリで、簡単にファインチューニングしデプロイ可能
- TPUは、ディープラーニングを高速化するため、Googleが開発したプロセッサ
チュートリアルの処理フロー
- TensorFlow HubからBERTモデルをロード
- GLUEタスクの1つを選択し、データセットをダウンロード
- テキストを前処理
- BERTのファインチューニング
- トレーニング済みモデルを保存/使用
検証スタート
事前準備
Colabで、[Runtime]->[Change runtime type]を選択し、TPUを選択
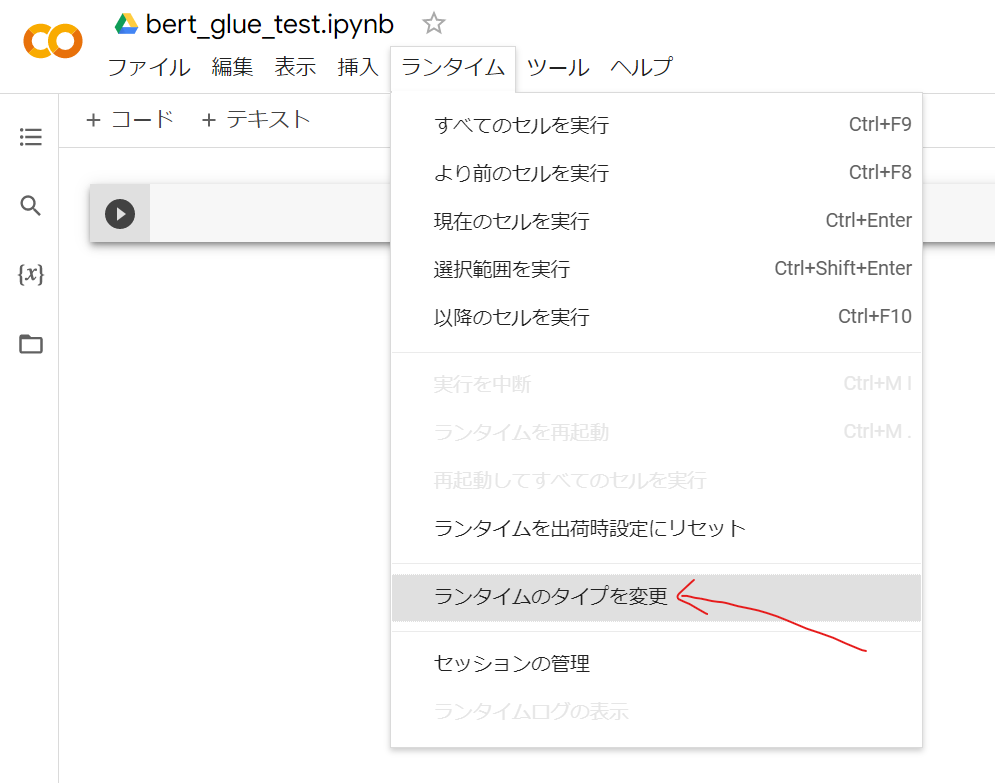
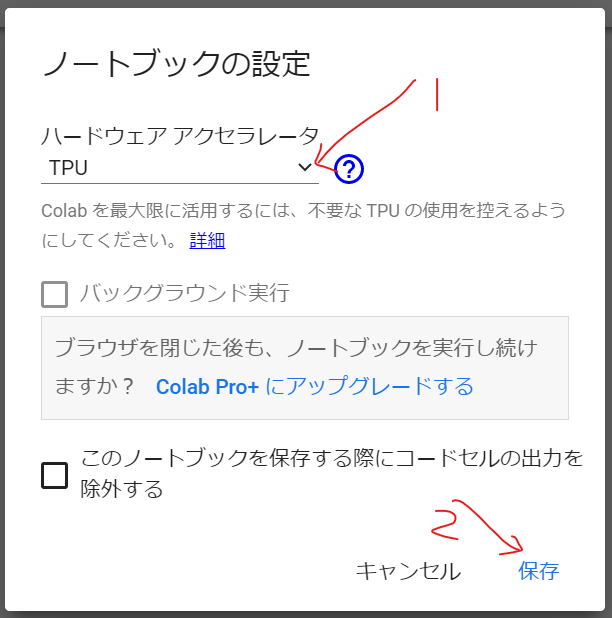
以下、Colabノートブックにコマンドを入力し、実行します。
設定
テキストのトークン化に使用する tensorflow/text をインストール
!pip install -q -U "tensorflow-text==2.8.*"
BERTをファインチューニングするため、tensorflow/models をインストール
!pip install -q -U tf-models-official==2.7.0
データセット tensorflow/datasets をインストール
!pip install -U tfds-nightly
モデル、学習セットを読み込む
import os
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
import tensorflow_text as text # A dependency of the preprocessing model
import tensorflow_addons as tfa
from official.nlp import optimization
import numpy as np
tf.get_logger().setLevel('ERROR')
TensorFlow HubのCloudStorageバケットからチェックポイントを直接読み取るように構成
os.environ["TFHUB_MODEL_LOAD_FORMAT"]="UNCOMPRESSED"
TPUワーカーに接続
TensorFlowのデフォルトデバイスをTPUワーカーのCPUデバイスに変更
import os
if os.environ['COLAB_TPU_ADDR']:
cluster_resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu='')
tf.config.experimental_connect_to_cluster(cluster_resolver)
tf.tpu.experimental.initialize_tpu_system(cluster_resolver)
strategy = tf.distribute.TPUStrategy(cluster_resolver)
print('Using TPU')
elif tf.config.list_physical_devices('GPU'):
strategy = tf.distribute.MirroredStrategy()
print('Using GPU')
else:
raise ValueError('Running on CPU is not recommended.')
TensorFlow Hubからモデルを読み込む
(折りたたみ)BERTモデルを選択し、ファインチューニング
#@title Choose a BERT model to fine-tune
bert_model_name = 'bert_en_uncased_L-12_H-768_A-12' #@param ["bert_en_uncased_L-12_H-768_A-12", "bert_en_uncased_L-24_H-1024_A-16", "bert_en_wwm_uncased_L-24_H-1024_A-16", "bert_en_cased_L-12_H-768_A-12", "bert_en_cased_L-24_H-1024_A-16", "bert_en_wwm_cased_L-24_H-1024_A-16", "bert_multi_cased_L-12_H-768_A-12", "small_bert/bert_en_uncased_L-2_H-128_A-2", "small_bert/bert_en_uncased_L-2_H-256_A-4", "small_bert/bert_en_uncased_L-2_H-512_A-8", "small_bert/bert_en_uncased_L-2_H-768_A-12", "small_bert/bert_en_uncased_L-4_H-128_A-2", "small_bert/bert_en_uncased_L-4_H-256_A-4", "small_bert/bert_en_uncased_L-4_H-512_A-8", "small_bert/bert_en_uncased_L-4_H-768_A-12", "small_bert/bert_en_uncased_L-6_H-128_A-2", "small_bert/bert_en_uncased_L-6_H-256_A-4", "small_bert/bert_en_uncased_L-6_H-512_A-8", "small_bert/bert_en_uncased_L-6_H-768_A-12", "small_bert/bert_en_uncased_L-8_H-128_A-2", "small_bert/bert_en_uncased_L-8_H-256_A-4", "small_bert/bert_en_uncased_L-8_H-512_A-8", "small_bert/bert_en_uncased_L-8_H-768_A-12", "small_bert/bert_en_uncased_L-10_H-128_A-2", "small_bert/bert_en_uncased_L-10_H-256_A-4", "small_bert/bert_en_uncased_L-10_H-512_A-8", "small_bert/bert_en_uncased_L-10_H-768_A-12", "small_bert/bert_en_uncased_L-12_H-128_A-2", "small_bert/bert_en_uncased_L-12_H-256_A-4", "small_bert/bert_en_uncased_L-12_H-512_A-8", "small_bert/bert_en_uncased_L-12_H-768_A-12", "albert_en_base", "albert_en_large", "albert_en_xlarge", "albert_en_xxlarge", "electra_small", "electra_base", "experts_pubmed", "experts_wiki_books", "talking-heads_base", "talking-heads_large"]
map_name_to_handle = {
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/3',
'bert_en_uncased_L-24_H-1024_A-16':
'https://tfhub.dev/tensorflow/bert_en_uncased_L-24_H-1024_A-16/3',
'bert_en_wwm_uncased_L-24_H-1024_A-16':
'https://tfhub.dev/tensorflow/bert_en_wwm_uncased_L-24_H-1024_A-16/3',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_L-12_H-768_A-12/3',
'bert_en_cased_L-24_H-1024_A-16':
'https://tfhub.dev/tensorflow/bert_en_cased_L-24_H-1024_A-16/3',
'bert_en_wwm_cased_L-24_H-1024_A-16':
'https://tfhub.dev/tensorflow/bert_en_wwm_cased_L-24_H-1024_A-16/3',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_L-12_H-768_A-12/3',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-128_A-2/1',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-256_A-4/1',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-512_A-8/1',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-768_A-12/1',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-128_A-2/1',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-256_A-4/1',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-768_A-12/1',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-128_A-2/1',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-256_A-4/1',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-512_A-8/1',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-768_A-12/1',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-128_A-2/1',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-256_A-4/1',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-512_A-8/1',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-768_A-12/1',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-128_A-2/1',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-256_A-4/1',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-512_A-8/1',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-768_A-12/1',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-128_A-2/1',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-256_A-4/1',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-512_A-8/1',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-768_A-12/1',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_base/2',
'albert_en_large':
'https://tfhub.dev/tensorflow/albert_en_large/2',
'albert_en_xlarge':
'https://tfhub.dev/tensorflow/albert_en_xlarge/2',
'albert_en_xxlarge':
'https://tfhub.dev/tensorflow/albert_en_xxlarge/2',
'electra_small':
'https://tfhub.dev/google/electra_small/2',
'electra_base':
'https://tfhub.dev/google/electra_base/2',
'experts_pubmed':
'https://tfhub.dev/google/experts/bert/pubmed/2',
'experts_wiki_books':
'https://tfhub.dev/google/experts/bert/wiki_books/2',
'talking-heads_base':
'https://tfhub.dev/tensorflow/talkheads_ggelu_bert_en_base/1',
'talking-heads_large':
'https://tfhub.dev/tensorflow/talkheads_ggelu_bert_en_large/1',
}
map_model_to_preprocess = {
'bert_en_uncased_L-24_H-1024_A-16':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'bert_en_wwm_cased_L-24_H-1024_A-16':
'https://tfhub.dev/tensorflow/bert_en_cased_preprocess/3',
'bert_en_cased_L-24_H-1024_A-16':
'https://tfhub.dev/tensorflow/bert_en_cased_preprocess/3',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_preprocess/3',
'bert_en_wwm_uncased_L-24_H-1024_A-16':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_preprocess/3',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_preprocess/3',
'albert_en_large':
'https://tfhub.dev/tensorflow/albert_en_preprocess/3',
'albert_en_xlarge':
'https://tfhub.dev/tensorflow/albert_en_preprocess/3',
'albert_en_xxlarge':
'https://tfhub.dev/tensorflow/albert_en_preprocess/3',
'electra_small':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'electra_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'experts_pubmed':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'experts_wiki_books':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'talking-heads_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'talking-heads_large':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
}
tfhub_handle_encoder = map_name_to_handle[bert_model_name]
tfhub_handle_preprocess = map_model_to_preprocess[bert_model_name]
print('BERT model selected :', tfhub_handle_encoder)
print('Preprocessing model auto-selected:', tfhub_handle_preprocess)
テキストを前処理
トレーニングと推論ともに、テキスト入力を受け付けられる
bert_preprocess = hub.load(tfhub_handle_preprocess)
tok = bert_preprocess.tokenize(tf.constant(['Hello TensorFlow!']))
print(tok)
BERTモデルで使用可能な形式で辞書が作成される
text_preprocessed = bert_preprocess.bert_pack_inputs([tok, tok], tf.constant(20))
print('Shape Word Ids : ', text_preprocessed['input_word_ids'].shape)
print('Word Ids : ', text_preprocessed['input_word_ids'][0, :16])
print('Shape Mask : ', text_preprocessed['input_mask'].shape)
print('Input Mask : ', text_preprocessed['input_mask'][0, :16])
print('Shape Type Ids : ', text_preprocessed['input_type_ids'].shape)
print('Type Ids : ', text_preprocessed['input_type_ids'][0, :16])
すべてのロジックをカプセル化した前処理モデルを作成
def make_bert_preprocess_model(sentence_features, seq_length=128):
"""Returns Model mapping string features to BERT inputs.
Args:
sentence_features: a list with the names of string-valued features.
seq_length: an integer that defines the sequence length of BERT inputs.
Returns:
A Keras Model that can be called on a list or dict of string Tensors
(with the order or names, resp., given by sentence_features) and
returns a dict of tensors for input to BERT.
"""
input_segments = [
tf.keras.layers.Input(shape=(), dtype=tf.string, name=ft)
for ft in sentence_features]
# Tokenize the text to word pieces.
bert_preprocess = hub.load(tfhub_handle_preprocess)
tokenizer = hub.KerasLayer(bert_preprocess.tokenize, name='tokenizer')
segments = [tokenizer(s) for s in input_segments]
# Optional: Trim segments in a smart way to fit seq_length.
# Simple cases (like this example) can skip this step and let
# the next step apply a default truncation to approximately equal lengths.
truncated_segments = segments
# Pack inputs. The details (start/end token ids, dict of output tensors)
# are model-dependent, so this gets loaded from the SavedModel.
packer = hub.KerasLayer(bert_preprocess.bert_pack_inputs,
arguments=dict(seq_length=seq_length),
name='packer')
model_inputs = packer(truncated_segments)
return tf.keras.Model(input_segments, model_inputs)
前処理モデルのデモンストレーション:
入力: 2つの文章(input1、input2)を使用しテストを作成
出力: BERTモデルの入力となる、input_word_ids、input_masks、input_type_ids
test_preprocess_model = make_bert_preprocess_model(['my_input1', 'my_input2'])
test_text = [np.array(['some random test sentence']),
np.array(['another sentence'])]
text_preprocessed = test_preprocess_model(test_text)
print('Keys : ', list(text_preprocessed.keys()))
print('Shape Word Ids : ', text_preprocessed['input_word_ids'].shape)
print('Word Ids : ', text_preprocessed['input_word_ids'][0, :16])
print('Shape Mask : ', text_preprocessed['input_mask'].shape)
print('Input Mask : ', text_preprocessed['input_mask'][0, :16])
print('Shape Type Ids : ', text_preprocessed['input_type_ids'].shape)
print('Type Ids : ', text_preprocessed['input_type_ids'][0, :16])
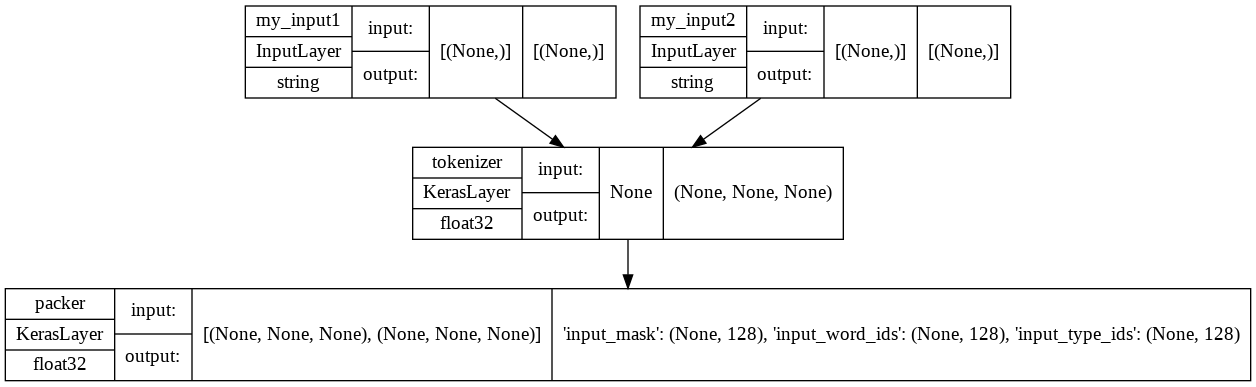
定義した2つの入力に注目しながらモデル構造を確認
tf.keras.utils.plot_model(test_preprocess_model, show_shapes=True, show_dtype=True)
データセットのマップ関数を使って、すべての入力に前処理を適用。
結果は、パフォーマンスのためキャッシュされます。
AUTOTUNE = tf.data.AUTOTUNE
def load_dataset_from_tfds(in_memory_ds, info, split, batch_size,
bert_preprocess_model):
is_training = split.startswith('train')
dataset = tf.data.Dataset.from_tensor_slices(in_memory_ds[split])
num_examples = info.splits[split].num_examples
if is_training:
dataset = dataset.shuffle(num_examples)
dataset = dataset.repeat()
dataset = dataset.batch(batch_size)
dataset = dataset.map(lambda ex: (bert_preprocess_model(ex), ex['label']))
dataset = dataset.cache().prefetch(buffer_size=AUTOTUNE)
return dataset, num_examples
モデルを定義
def build_classifier_model(num_classes):
class Classifier(tf.keras.Model):
def __init__(self, num_classes):
super(Classifier, self).__init__(name="prediction")
self.encoder = hub.KerasLayer(tfhub_handle_encoder, trainable=True)
self.dropout = tf.keras.layers.Dropout(0.1)
self.dense = tf.keras.layers.Dense(num_classes)
def call(self, preprocessed_text):
encoder_outputs = self.encoder(preprocessed_text)
pooled_output = encoder_outputs["pooled_output"]
x = self.dropout(pooled_output)
x = self.dense(x)
return x
model = Classifier(num_classes)
return model
前処理された入力でモデルを実行
test_classifier_model = build_classifier_model(2)
bert_raw_result = test_classifier_model(text_preprocessed)
print(tf.sigmoid(bert_raw_result))
GLUEからタスクを選択
(折りたたみ)今回はglue/colaタスクを選択
tfds_name = 'glue/cola'
tfds_info = tfds.builder(tfds_name).info
sentence_features = list(tfds_info.features.keys())
sentence_features.remove('idx')
sentence_features.remove('label')
available_splits = list(tfds_info.splits.keys())
train_split = 'train'
validation_split = 'validation'
test_split = 'test'
if tfds_name == 'glue/mnli':
validation_split = 'validation_matched'
test_split = 'test_matched'
num_classes = tfds_info.features['label'].num_classes
num_examples = tfds_info.splits.total_num_examples
print(f'Using {tfds_name} from TFDS')
print(f'This dataset has {num_examples} examples')
print(f'Number of classes: {num_classes}')
print(f'Features {sentence_features}')
print(f'Splits {available_splits}')
with tf.device('/job:localhost'):
# batch_size=-1 is a way to load the dataset into memory
in_memory_ds = tfds.load(tfds_name, batch_size=-1, shuffle_files=True)
# The code below is just to show some samples from the selected dataset
print(f'Here are some sample rows from {tfds_name} dataset')
sample_dataset = tf.data.Dataset.from_tensor_slices(in_memory_ds[train_split])
labels_names = tfds_info.features['label'].names
print(labels_names)
print()
sample_i = 1
for sample_row in sample_dataset.take(5):
samples = [sample_row[feature] for feature in sentence_features]
print(f'sample row {sample_i}')
for sample in samples:
print(sample.numpy())
sample_label = sample_row['label']
print(f'label: {sample_label} ({labels_names[sample_label]})')
print()
sample_i += 1
データセットのトレーニングのため、問題の種類(分類か回帰か)と損失関数を決定
def get_configuration(glue_task):
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
if glue_task == 'glue/cola':
metrics = tfa.metrics.MatthewsCorrelationCoefficient(num_classes=2)
else:
metrics = tf.keras.metrics.SparseCategoricalAccuracy(
'accuracy', dtype=tf.float32)
return metrics, loss
モデルのトレーニング
epochs = 3
batch_size = 32
init_lr = 2e-5
print(f'Fine tuning {tfhub_handle_encoder} model')
bert_preprocess_model = make_bert_preprocess_model(sentence_features)
with strategy.scope():
# metric have to be created inside the strategy scope
metrics, loss = get_configuration(tfds_name)
train_dataset, train_data_size = load_dataset_from_tfds(
in_memory_ds, tfds_info, train_split, batch_size, bert_preprocess_model)
steps_per_epoch = train_data_size // batch_size
num_train_steps = steps_per_epoch * epochs
num_warmup_steps = num_train_steps // 10
validation_dataset, validation_data_size = load_dataset_from_tfds(
in_memory_ds, tfds_info, validation_split, batch_size,
bert_preprocess_model)
validation_steps = validation_data_size // batch_size
classifier_model = build_classifier_model(num_classes)
optimizer = optimization.create_optimizer(
init_lr=init_lr,
num_train_steps=num_train_steps,
num_warmup_steps=num_warmup_steps,
optimizer_type='adamw')
classifier_model.compile(optimizer=optimizer, loss=loss, metrics=[metrics])
classifier_model.fit(
x=train_dataset,
validation_data=validation_dataset,
steps_per_epoch=steps_per_epoch,
epochs=epochs,
validation_steps=validation_steps)
推論のためエクスポート
前処理部分とファインチューニング済みBERTを含む、最終モデルを作成。
モデルをColabに保存し、後でダウンロードできるようにします。
main_save_path = './my_models'
bert_type = tfhub_handle_encoder.split('/')[-2]
saved_model_name = f'{tfds_name.replace("/", "_")}_{bert_type}'
saved_model_path = os.path.join(main_save_path, saved_model_name)
preprocess_inputs = bert_preprocess_model.inputs
bert_encoder_inputs = bert_preprocess_model(preprocess_inputs)
bert_outputs = classifier_model(bert_encoder_inputs)
model_for_export = tf.keras.Model(preprocess_inputs, bert_outputs)
print('Saving', saved_model_path)
# Save everything on the Colab host (even the variables from TPU memory)
save_options = tf.saved_model.SaveOptions(experimental_io_device='/job:localhost')
model_for_export.save(saved_model_path, include_optimizer=False,
options=save_options)
モデルをテスト
最後のステップとして、エクスポートされたモデル結果をテスト。
※ テストは、接続先のTPUワーカーではなく、Colabホストで実行される
with tf.device('/job:localhost'):
reloaded_model = tf.saved_model.load(saved_model_path)
#@title Utility methods
def prepare(record):
model_inputs = [[record[ft]] for ft in sentence_features]
return model_inputs
def prepare_serving(record):
model_inputs = {ft: record[ft] for ft in sentence_features}
return model_inputs
def print_bert_results(test, bert_result, dataset_name):
bert_result_class = tf.argmax(bert_result, axis=1)[0]
if dataset_name == 'glue/cola':
print('sentence:', test[0].numpy())
if bert_result_class == 1:
print('This sentence is acceptable')
else:
print('This sentence is unacceptable')
elif dataset_name == 'glue/sst2':
print('sentence:', test[0])
if bert_result_class == 1:
print('This sentence has POSITIVE sentiment')
else:
print('This sentence has NEGATIVE sentiment')
elif dataset_name == 'glue/mrpc':
print('sentence1:', test[0])
print('sentence2:', test[1])
if bert_result_class == 1:
print('Are a paraphrase')
else:
print('Are NOT a paraphrase')
elif dataset_name == 'glue/qqp':
print('question1:', test[0])
print('question2:', test[1])
if bert_result_class == 1:
print('Questions are similar')
else:
print('Questions are NOT similar')
elif dataset_name == 'glue/mnli':
print('premise :', test[0])
print('hypothesis:', test[1])
if bert_result_class == 1:
print('This premise is NEUTRAL to the hypothesis')
elif bert_result_class == 2:
print('This premise CONTRADICTS the hypothesis')
else:
print('This premise ENTAILS the hypothesis')
elif dataset_name == 'glue/qnli':
print('question:', test[0])
print('sentence:', test[1])
if bert_result_class == 1:
print('The question is NOT answerable by the sentence')
else:
print('The question is answerable by the sentence')
elif dataset_name == 'glue/rte':
print('sentence1:', test[0])
print('sentence2:', test[1])
if bert_result_class == 1:
print('Sentence1 DOES NOT entails sentence2')
else:
print('Sentence1 entails sentence2')
elif dataset_name == 'glue/wnli':
print('sentence1:', test[0])
print('sentence2:', test[1])
if bert_result_class == 1:
print('Sentence1 DOES NOT entails sentence2')
else:
print('Sentence1 entails sentence2')
print('BERT raw results:', bert_result[0])
print()
テスト
with tf.device('/job:localhost'):
test_dataset = tf.data.Dataset.from_tensor_slices(in_memory_ds[test_split])
for test_row in test_dataset.shuffle(1000).map(prepare).take(5):
if len(sentence_features) == 1:
result = reloaded_model(test_row[0])
else:
result = reloaded_model(list(test_row))
print_bert_results(test_row, result, tfds_name)
テスト結果です、英語文章に対し構文チェックが行われました。
sentence: [b'Max ate the apple and Sally the hamburgers.']
This sentence is unacceptable
BERT raw results: tf.Tensor([ 0.88702005 -1.0899425 ], shape=(2,), dtype=float32)
sentence: [b'Him was arrested by the police.']
This sentence is unacceptable
BERT raw results: tf.Tensor([ 1.7957013 -1.4417573], shape=(2,), dtype=float32)
sentence: [b'The king banished the army of the general.']
This sentence is acceptable
BERT raw results: tf.Tensor([-2.3608131 0.86971456], shape=(2,), dtype=float32)
sentence: [b'Kim gave a book to Sandy and a record to Dana.']
This sentence is acceptable
BERT raw results: tf.Tensor([-2.8122633 1.7039243], shape=(2,), dtype=float32)
sentence: [b'I only eat fish raw fresh.']
This sentence is acceptable
BERT raw results: tf.Tensor([-2.6713402 1.5533069], shape=(2,), dtype=float32)
おわりに
長編となりましたが、チュートリアルをほぼそのまま通しながら、GLUEタスクを解いてみました。
日本語未対応で腑に落ちませんが、日本語版GLUE(JGLUE)も有志たちが鋭意研究されているようです。
JGLUE: 日本語言語理解ベンチマーク
GLUEの他のタスク(感情解析など)も試してみます、欲を言うと日本語版GLUEで検証してみたいですね。
お楽しみに。