👀 概要
この記事は、AWS Batchを活用したバッチ処理を実装した際の記録です。
👦 対象読者
- AWS Batchを利用したバッチ処理に興味のある方
- AWS Bedrockを利用した推薦理由のコメント化に興味のある方
📌関連リンク
- TECH DOOR: CoEの内製開発エンジニアチームとは?
- TECH DOOR: エンジニアが自らつくる、エンジニアがはたらきやすい環境づくり―「Tech Harbor」プロジェクトとは?
- 日本最大級のエンジニアコミュニティ「Qiita」が、パーソルホールディングス株式会社と「HR業界 × AI」をテーマにオンラインイベントを開催!
課題
要件概要
パーソルでのプロジェクト「マッチングプロセス改善」では、求人と求人に応募していただいた方のマッチング業務を改善するためのシステム開発を行いました。
プロジェクトの都合上、基盤システムからのデータ連携と学習済みモデルを利用したマッチ度の算出を実装しました。
データ連携/モデル運用は定期バッチでの処理となりパフォーマンス等で様々な問題に遭遇しましたが、この記事では課題の概要と解決までの道のりを記しておきます。
機能的要件
- テーブルの取り込み処理
- 学習済みモデル実行処理
- 推薦理由の生成
非機能的側面
- 時間
- バッチは業務時間外に実行。前日に連携されたデータを全て学習済みモデル実行処理を行う。
- 朝6時にCSV形式のデータが転送されてくるので、朝8時までの処理を行う。
- データ
- 送られてくるデータは 1テーブルにつき1CSV。ファイル数は64個なのでテーブル数も64個。
- S3ファイルの特定のディレクトリが洗い替えされる。(差分ではなく洗い替え。)
- 一つでもテーブルの取り込み処理に失敗した場合、すべてのテーブルが前日の状態まで戻す。
- 処理
- 学習済みモデル実行処理はGPUの利用が必須。
実装
主要技術
- 言語 : Python3
- コンピューティング環境 : AWS Batch (Fargate/EC2 双方利用)
- データベース : Amazon Aurora Serverless PostgreSQL
- 機械学習モデル : LightGBM
- LLM : AWS Bedrock
ポンチ絵
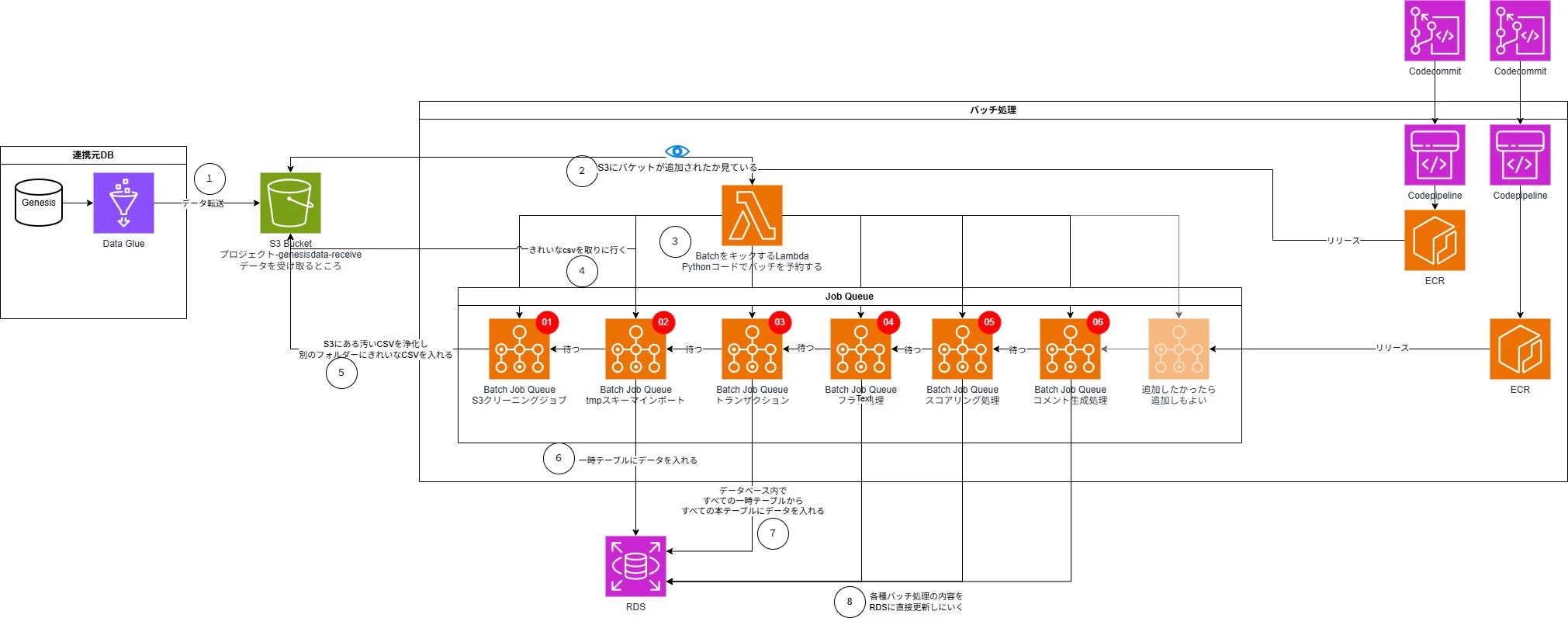
データ処理
フェーズ1 : CSVファイルのクリーニング処理
- 基本情報
- 1CSVファイル = 1子ジョブとして追加される(CSVのファイル数分の子ジョブが追加される)
- S3に連携されたCSVを
genesisdataディレクトリからダウンロードする - CSVデータのクレンジング(0x00(NULLバイト)の除去)
- 綺麗にしたデータを
genesisdata_cleanディレクトリにアップロードする
工夫ポイント
受け取ったCSVファイルはOracleから出力されたものでしたが、取り込み先のデータベースはPostgreSQLでした。
テーブルへの入力値が異なりcsvのクリーニング処理が必須となりますが、pythonでの実装した際の処理速度は不十分でした。そこで、pythonでの置換処理をやめ、
sedコマンドでの置換処理に変更し、処理速度の改善を行いました。
- 元コード
input_file = "input.txt"
output_file = "output.txt"
with open(input_file, "rb") as fin, open(output_file, "wb") as fout:
for line in fin:
line = line.replace(b"\x00", b"")
line = line.replace(b"0001-02-29", b"0001-02-28")
fout.write(line)
- 改善コード
mawk '{
gsub(/\x00/, "")
gsub(/0001-02-29/, "0001-02-28")
print
}' "$input_file" > "$output_file"
フェーズ2 : 一時テーブルへのDUMP : 並列処理の実装
- 基本情報
- 1CSVファイル = 1子ジョブとして追加される(CSVのファイル数分の子ジョブが追加される)
- CSVファイル名をテーブル名として、仮 スキーマの該当テーブルに対し以下の処理をする
- TRUNCATEする
- データベースで利用設定をしている
aws_s3の拡張機能を利用し、S3のgenesisdata_cleanディレクトリのCSVデータをテーブルにインサートする
- ※この時点で、仮 スキーマには一切影響せず、本 スキーマのみを利用
AWS S3の拡張機能を使って、テーブルの取り込み処理を行う。
SELECT aws_s3.table_import_from_s3(
'テーブル名',
'カラムリスト', --空文字の場合、テーブルのカラムと一致
'PostgreSQL', --COPYの引数・フォーマット
'S3バケット名',
'S3キー',
'S3リージョン'
);
工夫ポイント:並列処理
フェーズ1も並列処理だが、より効果が大きいのはフェーズ2でした。
S3ファイルからテーブルへのDUMP対象はテーブルの数分あり、テーブル数が増えれば増えるほど並列処理は威力を増します。
本構成では64テーブル分の子ジョブをAWS Batchの配列ジョブとして並列実行し、テーブルごとに独立してS3→PostgreSQLへの取り込みを行いました。直列で実行した場合と比較し、処理時間を大幅に短縮できました。
なお、並列数を増やしすぎるとデータベースへの同時接続数が増え、Aurora Serverlessのスケールアウトや接続上限に影響する可能性がありますが、ここはACUの上限を多めにとっております。
フェーズ3 : 本テーブルへのコピー : INDEXのつけ直し
- 基本情報
- 1ジョブとして追加される
- 本 スキーマのINDEXを全削除する
- 本 スキーマのテーブルを
TRUNCATEする - 仮 スキーマのテーブルの内容を 本 スキーマに全投入する
- 本 スキーマにINDEXを設定する
フェーズ3では 一時テーブルに格納されたテーブルを、本テーブルに移動させる処理を行います。
気をつけたこと:同一トランザクションで実装
このフェーズでは同一のトランザクションでテーブルコピーを行うため、万が一エラーが発生した際にはロールバックされます。
そのため、「テーブルAは最新だが、テーブルBは古い」という事態は発生しません。ごく当たり前の内容かもしれませんが、整合性を保つためには重要なことでした。
工夫ポイント:INDEXの削除/再作成
このフェーズのパフォーマンスで工夫したことは、 このフェーズでのテーブルのコピーの前にはINDEXを一度削除した ということでした。
本作業に取り組むきっかけは、INDEX が設定されたテーブルをコピーした際に想定以上の時間を要したことに違和感を覚えたためです。
ここの違和感には数値的根拠があるわけではなく、「なんとなく思っていたより速度が出ないな」と思った程度でした。(今思えばクエリの実行計画を確認すれば良かったのですが、当時はそれを発想する時間的/精神的余力がなかったです。)
この違和感を覚えた後、「試しにCOPY前にINDEXを削除してみよう」とトライアル的に実験したところCOPY速度が向上したのです。
この実験で驚いたのは、INDEXの削除/再作成時間を足しても、 INDEXがないテーブルへのCOPY時間の方が少なく済んだのです。
INDEXが貼られたままのテーブルへのCOPY < (INDEXの削除 + INDEXがないテーブルへのCOPY + INDEXの再作成)の速度
フェーズ4
- 特に語ることがないので省略
フェーズ5 : 学習済みモデル実行処理
- 基本情報
- 1ジョブとして追加される
- 1求人に対する応募者のマッチ度をすべて算出
- 算出されたマッチ度を再度テーブルへ挿入
- マッチ度算出のアルゴリズムにはLightGBMを使用
- 学習済みモデルの運用のために、GPUインスタンスを活用
気を付けたこと:GPUインスタンスの利用
学習済みモデル実行処理のためにGPUの利用は必須でしたが、その際にはFargateでのコンピューティングをあきらめ、EC2インスタンス形式でのコンピューティングに変える必要がありました。
そしてEC2インスタンスタイプg4dn.2xlargeを活用してマッチング処理の実装を開始しましたが、一つ問題が発生します。指定したインスタンスタイプ
g4dn.2xlargeが枯渇しているのです。これはプロジェクト側で起きた事象というよりプロバイダー全体で枯渇している事象のようでした。
対策としては「リザーブドインスタンスの活用」を行いましたが、これはメンテナンスコスト/導入コストが発生するため対応でした。
開発チームにとっては苦渋の選択でしたが、気合と根性で乗り切りました。
フェーズ6 : コメント処理
- 基本情報
- 1ジョブとして追加される
- マッチ度の結果に応じて、「具体的にどのような部分がマッチしているのか」の理由をAWS Bedrockによってコメント出力する
- 生成されたコメントは、再度テーブルへ挿入
気を付けたこと:トークン制限
当時のAWS Bedrock Haiku にはトークン制限があり、コメント生成できる数に限りがありました。
そもそも、バッチ処理でコメント生成せずにユーザーがマッチ度の算出理由ボタンを押下した時にコメント生成する案もありましたが、
「コメント生成にはユーザー視点で時間をかけたくない」という理由でバッチ処理に入れざるを得ませんでした。制限引き上げについてはAWSサポートへの相談も行いましたが、
「特別・正当な理由があればAWSで検討」という形で、相当ハードルが高かったです...。そのうえでAWSサポートからもらった代替手段が複数アカウント案でした。
AWSのアカウントを複数用意して、1アカウント当たりのトークン数制限を疑似的に増加させる方法です。
この対応もメンテナンスコスト/導入コストが高いため、開発チームとしては苦渋の選択でしたが、ここも気合と根性で乗り切りました。
まとめ
ここまで記事を読んでくださりありがとうございます。
本プロジェクト「マッチングプロセス改善」のバッチ処理では様々な困難に遭遇しました。
技術的に解決可能な課題でも解決のためには気合と根性も必要だったと思います...。
本記事がAWS Batchを利用したバッチ処理を実装する方への一助となれば幸いです。